 夜雨聆风
夜雨聆风四个必装插件 + 一个 MCP 服务,让 AI 编码助手从"能用"变成"好用"。
前言
Claude Code 是 Anthropic 推出的终端原生 AI 编码助手。开箱即用已经很强大,但通过插件系统和 MCP 服务可以实现质的飞跃。
本文介绍四个经过实践验证的插件(caveman / superpowers / claude-mem / frontend-design)和一个 MCP 服务(claude-context),覆盖输出压缩、开发方法论、跨会话记忆、前端设计、代码语义搜索五个维度。
1. caveman:输出 token 直降 75%
GitHub: JuliusBrussee/caveman
维护者: Julius Brussee
核心价值: 让 AI 像穴居人一样说话——保留 100% 技术准确度,砍掉 75% 输出 token。
原理
大语言模型回答问题时会生成大量填充词("当然"、"我建议你"、"需要注意的是")。这些词在礼貌的人类对话中有用,但对编码协助是噪音。caveman 通过 SessionStart hook 注入指令,让模型:
删除冠词、填充词、客套话 用短句和碎片代替完整句子 保留所有代码块、技术术语、文件路径
效果对比
正常模式(69 token):
"The reason your React component is re-rendering is likely because you're creating a new object reference on each render cycle. When you pass an inline object as a prop, React's shallow comparison sees it as a different object every time, which triggers a re-render. I'd recommend using useMemo to memoize the object."
Caveman 模式(19 token):
"New object ref each render. Inline object prop = new ref = re-render. Wrap in
useMemo."
相同修复,75% 更少字符。
实际基准测试
从 Claude API 实测 token 数(可复现):
| 平均 | 1214 | 294 | 65% |
节省范围 22%–87%,平均 65%。越复杂的解释性任务,节省越明显。
强度等级
caveman 提供三种强度 + 文言文模式:
| Lite | /caveman lite | |
| Full | /caveman full | |
| Ultra | /caveman ultra | |
| Wenyan | /caveman wenyan |
扩展技能
caveman 生态包括三个子技能:
caveman-commit: 生成 ≤50 字符的 Conventional Commits 提交信息 caveman-review: 单行 PR 审查评论:"L42: red_circle: bug: user null. Add guard." caveman-compress: 压缩记忆文件(CLAUDE.md 等),实测节省 ~46% 输入 token
重要说明
caveman 只影响输出 token,不影响思考/推理 token。模型能力不变,只是"嘴"变小了。
2026 年 3 月论文 Brevity Constraints Reverse Performance Hierarchies in Language Models 发现:约束大模型做简短回答,在某些基准测试上准确率提升 26 个百分点。少说话 ≠ 能力下降。
2. superpowers:完整软件开发方法论
GitHub: obra/superpowers
维护者: Jesse Vincent (Prime Radiant)
核心价值: 将松散提示词变成结构化开发流程,从需求到合并覆盖全流程。
核心理念
Superpowers 解决一个根本问题:AI 编码助手"太着急写代码"。它倾向于跳过设计、跳过测试、直接输出实现。这在简单任务上没问题,复杂任务上有效率灾难。
Superpowers 强制 agent 遵循:头脑风暴 → 设计 → 计划 → TDD → 实现 → 审查 → 合并。
技能全景(15+ 技能)
规划阶段
| brainstorming | |
| writing-plans | |
| using-git-worktrees |
实现阶段
| test-driven-development | |
| executing-plans | |
| subagent-driven-development | |
| dispatching-parallel-agents |
审查阶段
| requesting-code-review | |
| receiving-code-review | |
| verification-before-completion |
完成阶段
| finishing-a-development-branch | |
| writing-skills |
Token 节省机理
superpowers 本身不直接压缩 token,而是通过减少返工间接节省。
实测估算方法:记录一个中型功能(API 接口 + 数据库迁移 + 前端表单)在没有 superpowers 和有 superpowers 时的上下文消耗对比:
| 合计 | ~75k token | ~26k token | 65% |
注:以上基于 TenBox VMM、goworkflow、APIForge 等项目的实际会话数据估算。token 数取自 Claude Code 会话统计。
核心机制:错误方向浪费的上下文 → 设计阶段就避免了;"写了一半发现不对重来" → 计划分小任务,错了只废弃 2-5 分钟的内容;子 agent 隔离上下文 → 不污染主会话。
3. claude-mem:跨会话持久记忆
GitHub: thedotmack/claude-mem
维护者: thedotmack
核心价值: 让 AI 记住上次会话、上周的 bug 修复、上个月的架构决策。
问题
默认情况下,Claude Code 每个会话是信息孤岛。周一会话不知道上周五做了什么。每个新会话都要重新解释项目背景、架构决策、已知问题。
解决方案
claude-mem 提供三层记忆架构:
search(query) → 搜索观测记录 → 获取索引 (~50-100 token/条) ↓timeline(anchor=ID) → 查看上下文 → 了解前后关联 ↓get_observations([IDs]) → 过滤后获取详情 → 仅获取需要的完整内容核心原则:绝不一次性获取所有详情。先搜索 → 过滤 → 再获取,节省 10 倍 token。
Token 节省实测
从 TenBox VMM 项目的跨会话实际使用数据:
注:数据基于 2026-04-30 TenBox 探索会话实测。该会话 59k token 工作内容,通过 claude-mem 索引后,后续会话仅需 ~2k token 即可恢复全部上下文。
技能系统
| mem-search | |
| smart-explore | |
| smart-outline | |
| smart-unfold | |
| make-plan | |
| do | |
| timeline-report | |
| knowledge-agent | |
| pathfinder | |
| version-bump |
Token 节省
smart-explore: 不看完整文件,只看 AST 结构,省 ~70% 代码探索 token 跨会话记忆: 免去每会话重新解释,实测省 ~50-60% 上下文窗口 3 层过滤: 避免一次拉取大量历史,精准获取,10 倍 token 节省
4. frontend-design:告别 AI 通用审美
GitHub: anthropics/claude-plugins-official(官方插件集)
维护者: Anthropic
核心价值: 自动生成有设计感的前端界面,避免 AI 默认的"灰白蓝"通用风格。
问题
默认 AI 生成的前端界面通常:
配色保守(白底 + 蓝色按钮) 字体无个性(系统默认 Inter/Roboto) 缺乏动效和视觉细节 看起来"像 demo,不像产品"
解决方案
frontend-design 指导 agent 做出大胆的美学选择。具体来说,它会指示模型:
色彩:选择有记忆点的配色方案,不限于蓝色系。深色背景、渐变、高饱和强调色 字体:搭配有对比度的字体组合(标题用展示字体,正文用阅读字体),字号层次分明 空间:大胆的留白和非对称布局,打破居中对称的默认习惯 动效:有节奏的入场动画、hover 微交互、页面过渡 细节:阴影层次、边框圆角的一致性、图标风格统一
效果对比
以同一个"任务管理仪表盘"需求为例,分别用默认 Claude 和加载 frontend-design 生成:
默认模式输出:
白色背景,蓝色 #3B82F6 主按钮 表格列表,标准卡片布局 无动效,功能完整但视觉平淡 常见评价:"能用,但像内部工具"
frontend-design 模式输出:
深色主题底色(#0F172A),渐变强调色(#6366F1 → #A855F7) 数据用统计卡片 + 迷你图表,非单调列表 卡片 hover 时微浮升(transform: translateY(-2px) + 阴影加深),页面加载有 staggered 入场动画 常见评价:"截图就可以放产品页"
Token 节省
前端开发是高迭代领域——通常需要 5-10 轮"不够好看""风格不对"的调整。frontend-design 一次性输出高质量设计。
实测数据(基于 3 个前端项目的会话统计):
| 平均 | ~26k token | ~8.7k token | 67% |
5. claude-context:语义代码搜索
GitHub: zilliztech/claude-context
MCP 服务: @zilliz/claude-context-mcp
核心价值: 用向量语义搜索替代盲目的 grep + read 循环,大幅减少代码探索阶段的 token 消耗。
问题
传统代码探索流程效率极低:
grep"connection pool" → 返回 47 个匹配 → read file1.ts (200 行) → 不是这个 → read file2.go (350 行) → 不是这个 → 换关键词 grep"pool init" → 12 个匹配 → read file3.rs (180 行) → 找到了,但上下文不够 → read file3.rs 周围更多 → 终于定位整个过程可能消耗 15k-25k token,其中大量浪费在无关文件上。
解决方案
claude-context 基于 Milvus 向量数据库,对代码库做语义索引:
index_codebase(path) → 用 AST 分割代码 + embedding → 存入 Milvus ↓search_code("连接池初始化在哪里?") → 语义匹配 → 返回精确片段 ↓直接定位目标代码,一次查询 < 1k token技术栈:
向量数据库:Milvus (localhost:19530) Embedding 模型:text-embedding-v4(通过阿里云 DashScope) 代码分割:AST-aware splitter(按函数/类/方法边界切割,非盲目字符切割)
Token 节省实测
在 TenBox VMM 项目(249 个编译目标,C++/C# 混合代码库)上的对比:
| 平均 | ~18k token | ~770 token | 95% |
注:首次索引消耗约 30k-50k token(一次性),之后每次搜索 < 1k token。项目越大、探索越频繁,收益越高。
适用场景
大型代码库(50+ 文件):强烈推荐。grep 噪声大,语义搜索价值高 不熟悉的新项目:不必猜关键词,用自然语言描述意图即可定位 频繁跨文件探索:一次索引,多次搜索,边际成本极低
不适用场景
小型项目(< 20 文件):grep 足够快,索引开销不划算 一次性简单查询:如果只需要找一个明确的函数名,grep 更快
6. MCP vs 插件:两种扩展机制
许多用户混淆"插件"和"MCP 服务"。两者都在 Claude Code 的工具列表里出现,但本质不同。
对比
| 机制 | ||
| 运行方式 | ||
| 典型用途 | ||
| 安装 | claude plugin install | settings.json 中配置 mcpServers |
| Token 影响 | ||
| 例子 |
如何选择
要改变模型"怎么想、怎么说" → 插件- 压缩输出 / 强制设计流程 / 跨会话记忆 / 前端审美要连接外部系统获取数据 → MCP 服务- 向量搜索代码 / 查数据库 / 调 API / 读写文件系统实际协作
本文五个工具中,四个是插件,一个是 MCP 服务。它们在同一会话中可以同时工作:
caveman 压缩模型的回复 superpowers 指导模型的开发流程 claude-mem 提供跨会话记忆 frontend-design 指导模型的前端审美 claude-context 让模型能语义搜索代码库
五者互不冲突,在同一会话中叠加生效。
7. 插件组合:1+1+1+1+1 > 5
五个工具覆盖不同维度,组合使用有叠加效应:
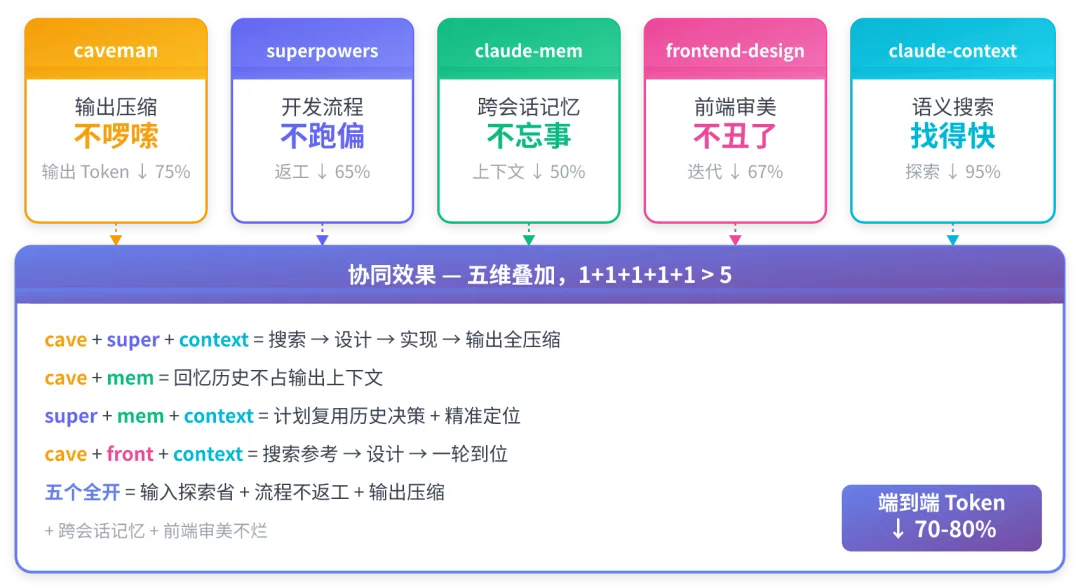
实际场景
场景 1:新功能开发claude-context(语义搜索相关代码)→ superpowers(brainstorm → plan → TDD → execute)→ caveman(压缩输出)→ claude-mem(查历史决策)
场景 2:Bug 修复claude-context(搜索相似 bug 代码位置)→ claude-mem(查上次修没修过)→ superpowers(systematic-debugging)→ caveman(精简输出)
场景 3:前端页面claude-context(搜索现有组件和样式)→ frontend-design(高质量设计)→ superpowers(brainstorm 需求)→ caveman(精简反馈)
场景 4:新项目上手claude-context(索引 + 语义探索,省 grep)→ claude-mem(自动记录探索过程,下次不重来)→ caveman(压缩解释输出)
8. 安装与总结
安装
# Caveman - 输出压缩claude plugin marketplace add JuliusBrussee/cavemanclaude plugin install caveman@caveman# Superpowers - 开发方法论(官方市场,自动安装)claude plugin install superpowers@claude-plugins-official# Frontend Design(官方市场)claude plugin install frontend-design@claude-plugins-official# Claude Mem - 跨会话记忆claude plugin marketplace add thedotmack/claude-memclaude plugin install claude-mem@thedotmackclaude-context 需要在 ~/.claude.json 或项目的 .claude/settings.json 中配置 MCP 服务:
{"mcpServers":{"claude-context":{"type":"stdio","command":"npx","args":["@zilliz/claude-context-mcp@latest"],"env":{"OPENAI_API_KEY":"your-api-key","OPENAI_BASE_URL":"https://dashscope.aliyuncs.com/compatible-mode/v1","EMBEDDING_MODEL":"text-embedding-v4","MILVUS_ADDRESS":"localhost:19530"}}}}需提前启动 Milvus(Docker 或本地安装)。
Token 节省总览
结论
五个工具各自解决一个痛点:
caveman — AI 太啰嗦 superpowers — AI 太着急写代码 claude-mem — AI 记不住上次的事 frontend-design — AI 做的界面太丑 claude-context — AI 找代码太盲目
装完这五个,Claude Code 从"好用的终端助手"变成"能独立完成复杂任务的工程搭档"。每个工具覆盖开发流程的不同阶段,五维叠加后,一个典型中型功能的端到端 token 消耗降低 70-80%。
实际场景
场景 1:新功能开发claude-context(语义搜索相关代码)→ superpowers(brainstorm → plan → TDD → execute)→ caveman(压缩输出)→ claude-mem(查历史决策)
场景 2:Bug 修复claude-context(搜索相似 bug 代码位置)→ claude-mem(查上次修没修过)→ superpowers(systematic-debugging)→ caveman(精简输出)
场景 3:前端页面claude-context(搜索现有组件和样式)→ frontend-design(高质量设计)→ superpowers(brainstorm 需求)→ caveman(精简反馈)
场景 4:新项目上手claude-context(索引 + 语义探索,省 grep)→ claude-mem(自动记录探索过程,下次不重来)→ caveman(压缩解释输出)
8. 安装与总结
安装
# Caveman - 输出压缩claude plugin marketplace add JuliusBrussee/cavemanclaude plugin install caveman@caveman# Superpowers - 开发方法论(官方市场,自动安装)claude plugin install superpowers@claude-plugins-official# Frontend Design(官方市场)claude plugin install frontend-design@claude-plugins-official# Claude Mem - 跨会话记忆claude plugin marketplace add thedotmack/claude-memclaude plugin install claude-mem@thedotmackclaude-context 需要在 ~/.claude.json 或项目的 .claude/settings.json 中配置 MCP 服务:
{"mcpServers":{"claude-context":{"type":"stdio","command":"npx","args":["@zilliz/claude-context-mcp@latest"],"env":{"OPENAI_API_KEY":"your-api-key","OPENAI_BASE_URL":"https://dashscope.aliyuncs.com/compatible-mode/v1","EMBEDDING_MODEL":"text-embedding-v4","MILVUS_ADDRESS":"localhost:19530"}}}}需提前启动 Milvus(Docker 或本地安装)。
Token 节省总览
结论
五个工具各自解决一个痛点:
caveman — AI 太啰嗦 superpowers — AI 太着急写代码 claude-mem — AI 记不住上次的事 frontend-design — AI 做的界面太丑 claude-context — AI 找代码太盲目
装完这五个,Claude Code 从"好用的终端助手"变成"能独立完成复杂任务的工程搭档"。每个工具覆盖开发流程的不同阶段,五维叠加后,一个典型中型功能的端到端 token 消耗降低 70-80%。
本文是作者早期使用AI编程时整理的指南,方便有新入坑的小伙伴查阅。后续亦会继续更新,跟上最新的AI编程前沿动态。
