 夜雨聆风
夜雨聆风





用 AI 编程助手,从零搭建分布式任务调度系统
WorkBuddy 最佳实践 · 完整项目实战
一个人,一小时,一套完整的分布式系统——从架构设计到单元测试,从可观测性到 K8s 部署,全程 AI 协作完成。

写在前面
你有没有想过,把一个从零开始的分布式项目交给 AI 编程助手来协作完成,体验会是怎样的?
这篇文章记录了我用 WorkBuddy 完成 TaskFlow(分布式任务调度框架)这个项目的全过程。这不是一个 “Hello World” 级别的 Demo,而是一个真实的、具备生产可用性的系统:
-
• 5 个 Go 微服务 -
• Vue 3 全功能前端 -
• 100+ 单元测试用例 -
• Docker Compose + Helm Chart + K8s 清单 -
• 完整可观测性(OTel + VictoriaMetrics + Jaeger + Grafana)
我想通过这个案例,把使用 AI 编程助手的最佳实践系统地总结出来,供大家参考。
项目概览:TaskFlow 是什么
TaskFlow 是一个分布式任务调度框架,核心能力包括:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
技术栈一览:
后端:Go 1.25 · Gin · GORM · Redis · RabbitMQ · OTel SDK前端:Vue 3 · Element Plus · ECharts · Pinia · Vite数据库:PostgreSQL 15部署:Docker Compose · Helm Chart · K8s监控:OpenTelemetry · VictoriaMetrics · Jaeger · Grafana系统架构
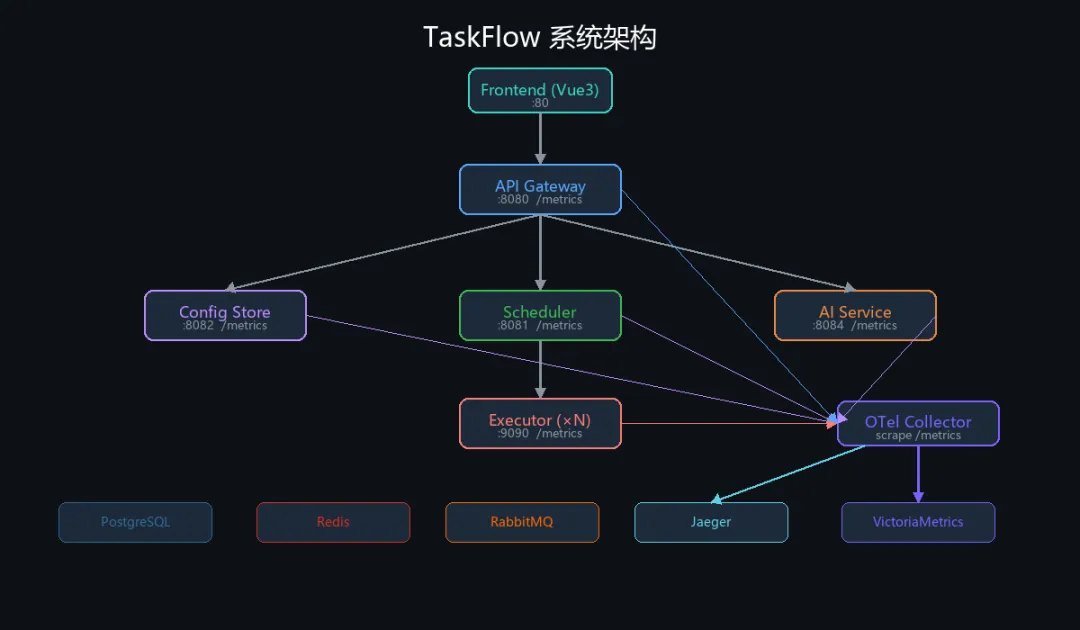
系统由 5 个独立微服务组成,通过消息队列解耦:
Frontend (:80) ↓ HTTPAPI Gateway (:8080) ← JWT 鉴权 · 反向代理 · 限流 ↓ 路由转发┌─────────────────────────────────────────────┐│ Config Store (:8082) ← 任务配置 CRUD ││ Scheduler (:8081) ← Cron + 延迟调度 ││ AI Service (:8084) ← 大模型集成 ││ Executor (×N) ← Worker Pool │└─────────────────────────────────────────────┘ ↕ MQ (Redis/RabbitMQ) ↕ PostgreSQL · Redis每个服务都暴露 /metrics 端点,由 OTel Collector 统一抓取,推送到 VictoriaMetrics。
WorkBuddy 使用方式:6 步工作流
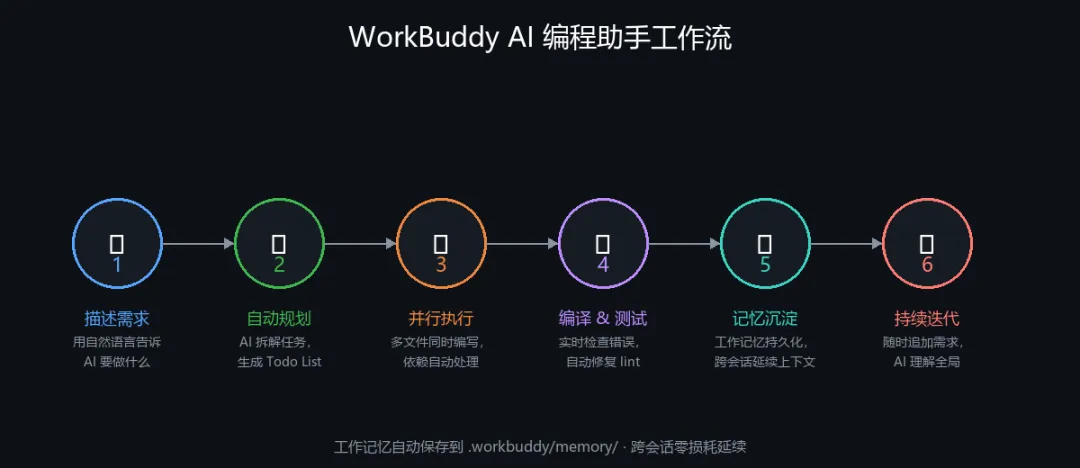
使用 AI 编程助手,我的工作流是这样的:
第 1 步:用自然语言描述需求
不需要写任何规范文档,直接告诉 AI 要做什么:
帮我搭建一个分布式任务调度框架,Go 微服务架构,支持 Cron 调度和延迟任务,用 Redis 做消息队列,前端用 Vue3
AI 会追问关键决策点,帮你把模糊的想法变成清晰的技术方案。
第 2 步:AI 自动生成 Todo List
AI 把需求拆解成有序的任务列表,优先级和依赖关系都考虑到:
1. ✅ 项目骨架初始化(go.mod · 目录结构 · Makefile)2. ✅ pkg 公共库(OTel · JWT · MQ抽象 · Config)3. ✅ Config Store 服务(GORM + PostgreSQL)4. ✅ Scheduler 服务(Cron + 延迟任务 + Worker注册)5. ✅ Executor 服务(Worker Pool + 多类型执行器)6. ✅ API Gateway + AI Service7. ✅ 前端所有页面(Vue3 + Element Plus + ECharts)8. ✅ 部署配置(Docker Compose + Helm Chart + K8s)这个 Todo List 会在整个开发过程中实时更新,你随时知道当前进度。
第 3 步:并行执行,多文件同时生成
AI 不是一个文件一个文件地写,而是批量并行处理。比如写 pkg 公共库时,AI 同时创建了:
-
• pkg/auth/jwt.go— JWT 管理器 -
• pkg/mq/interface.go— MQ 抽象接口 -
• pkg/mq/redis.go— Redis 实现 -
• pkg/mq/rabbitmq.go— RabbitMQ 实现 -
• pkg/observability/observability.go— 可观测性初始化 -
• pkg/config/config.go— 配置加载
核心优势:相关文件天然保持一致,不会出现接口不匹配的情况。
第 4 步:实时编译检查 + 自动修复
每写完一批代码,AI 会立即运行 go build,发现错误立即修复:
# AI 自动执行,不需要你操心go build ./pkg/... ./services/...go test ./... -v -race -timeout 120s遇到 Windows 平台兼容问题(比如 Shell 测试里的 echo 命令),AI 也会自动识别并适配:
// 原来(Linux)"command": "echo","args": []{"hello taskflow"}// 修复后(Windows cmd.exe)"command": "cmd","args": []{"\/c", "echo hello taskflow"}第 5 步:工作记忆持久化
这是 WorkBuddy 最有价值的功能之一。每次完成重要工作,AI 自动把关键信息写入工作记忆:
.workbuddy/memory/├── 2026-03-24.md ← 今日工作日志(追加模式)└── MEMORY.md ← 长期记忆(技术决策 · 架构要点 · 用户偏好)跨会话零损耗:下次打开项目,AI 读取记忆文件,立即恢复上下文,不需要你重新解释项目背景。
第 6 步:随时追加需求,AI 理解全局
基于持久化的工作记忆,任何时候追加新需求,AI 都能理解全局:
小仔,Prometheus 在数据量大时会很慢,帮我换成 VictoriaMetrics + OTel Collector 方案
AI 立刻知道:当前的 Prometheus 是怎么配的、哪些文件需要改、改了之后是否会影响已有测试。
最佳实践:单元测试策略
写完功能代码,我让 AI 补全单元测试。AI 采用的策略非常值得借鉴:
测试覆盖率一览
|
|
|
|
|
pkg/auth |
|
90.3% |
|
pkg/mq |
|
|
|
executor/runner |
|
97.0% |
|
scheduler/worker |
|
|
|
config-store/repository |
|
96.4% |
|
关键测试技巧
1. 外部依赖全部 Mock
// 不启动真实 Redis,用内存 Mock 实现 MQ 接口type memQueue struct { mu sync.Mutex items []mockItem}func(q *memQueue) Publish(ctx context.Context, msg *mq.Message) error { ... }func(q *memQueue) Subscribe(ctx context.Context, handler mq.Handler) error { ... }2. 用 SQLite 替代 PostgreSQL
// 测试时用内存 SQLite,完全兼容 GORM 的所有 ORM 操作db, err := gorm.Open(sqlite.Open(":memory:"), &gorm.Config{})db.AutoMigrate(&model.TaskConfig{}, &model.ConfigKV{})3. 优先级算法显式验证
// 验证核心调度算法:优先级 9 的新任务 vs 优先级 1 的旧任务score9 := (20 - 9) * 1e12 + float64(time.Now().UnixMilli())score1 := (20 - 1) * 1e12 + float64(time.Now().Add(-time.Hour).UnixMilli())assert.Less(t, score9, score1) // 高优先级 score 更小,先出队4. 边界场景覆盖
// JWT:极短有效期测试过期场景token, _ := mgr.GenerateToken("user", "alice", "admin",1*time.Millisecond) // 1毫秒后过期time.Sleep(5 * time.Millisecond)_, err = mgr.ParseToken(token)assert.ErrorIs(t, err, ErrTokenExpired)// JWT:算法混淆攻击防御hs512Token := signWithHS512(secret, claims)_, err = mgr.ParseToken(hs512Token)assert.Error(t, err) // 必须拒绝最佳实践:可观测性架构升级
这是本次最有价值的技术决策之一。
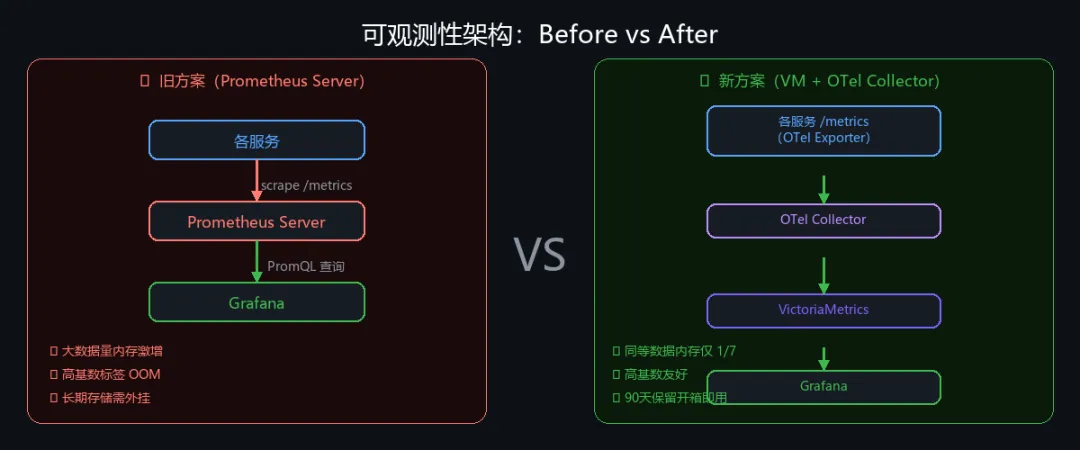
旧方案的问题
直接使用 prometheus/client_golang + Prometheus Server:
-
• 内存激增:高基数标签(如 task_id)导致时序爆炸 -
• 单点瓶颈:Prometheus Server 既要 scrape 又要存储,压力集中 -
• 长期存储需外挂:Prometheus 自身只适合短期数据
新方案:OTel → VictoriaMetrics
业务代码(OTel Metrics API) ↓OTel SDK(MeterProvider) ↓ Prometheus 文本格式/metrics 端点(各服务暴露) ↓ scrape every 15sOTel Collector ↓ RemoteWriteVictoriaMetrics(存储 + Query API) ↑ 查询(兼容 PromQL)Grafana核心优势:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
--retentionPeriod |
|
|
|
|
|
|
|
|
业务代码的写法
只用 OTel Metrics API,不 import prometheus 包:
// 初始化(框架层,一次性)promExporter, _ := prometheusexporter.New()mp := sdkmetric.NewMeterProvider( sdkmetric.WithReader(promExporter), sdkmetric.WithResource(res),)otel.SetMeterProvider(mp)// 业务代码(任何地方)meter := observability.Meter()counter, _ := meter.Int64Counter("taskflow.scheduler.tasks.dispatched", metric.WithDescription("Tasks dispatched to workers"),)counter.Add(ctx, 1, metric.WithAttributes( attribute.String("type", taskType),))好处显而易见:将来换掉 Prometheus Exporter(比如改用 OTLP Push 模式),业务代码零改动。
最佳实践:与 AI 协作的核心技巧
经过这个项目,我总结出几条跟 AI 编程助手高效协作的核心原则:
1. 给 AI “记忆”,而不是每次重新解释
工作记忆文件是跨会话协作的基础。关键技术决策要让 AI 写入记忆:
> 小仔,把这个架构决策记下来,下次还要用也可以直接编辑 .workbuddy/memory/MEMORY.md,加入自己的约束条件。
2. 用 Plan 模式处理高风险操作
对于会影响生产的变更(重构架构、修改数据库 Schema),先让 AI 出方案,审查后再执行:
> 小仔,切换到 Plan 模式,分析一下把 Prometheus 换成 VictoriaMetrics 需要改哪些文件3. 拆小任务,而不是一次性扔给 AI
虽然 AI 能处理复杂任务,但把大任务拆成有明确验收标准的小任务,效果更好:
# 不好"帮我搭一个完整的微服务系统"# 好"先帮我设计 MQ 抽象层接口,支持 Redis 和 RabbitMQ 两种驱动, 用环境变量 MQ_DRIVER 切换,然后写单元测试"4. 让 AI 自己验证,不要只看代码
每次生成代码后,要求 AI 运行编译和测试,而不是直接接受:
> 写完先 go build 看看有没有报错,再跑一下对应的单元测试AI 在处理编译错误时非常高效,通常能一次修好。
5. 保持架构决策的一致性
当项目涉及多个服务时,要建立全局约定并写入记忆,避免 AI 在不同文件里用不同风格:
# MEMORY.md 中的约定示例- 错误处理:统一用 fmt.Errorf("context: %w", err) 包装- 日志:统一用 observability.Logger(),不直接 import zap- 指标:统一用 observability.Meter(),不直接 import prometheus项目结构:最终交付物
经过一天的 AI 协作,项目结构如下:
tasks/├── pkg/ # 公共库│ ├── auth/jwt.go # JWT 管理器│ ├── mq/ # MQ 抽象(Redis/RabbitMQ)│ ├── observability/ # OTel 初始化(Trace + Metrics + Log)│ └── config/ # 配置加载(Viper)│├── services/│ ├── gateway/ # API 网关(:8080)│ ├── scheduler/ # 调度服务(:8081)│ ├── config-store/ # 配置存储(:8082)│ ├── executor/ # 执行器 Worker(:9090 metrics)│ └── ai-service/ # AI 分析(:8084)│├── frontend/ # Vue 3 前端│ └── src/│ ├── views/ # 8 个页面│ ├── stores/ # Pinia 状态管理│ └── api/ # Axios 封装│├── deploy/│ ├── docker-compose.yml # 一键本地启动│ ├── otelcol.yml # OTel Collector 配置│ ├── helm/ # Helm Chart(17 个模板)│ └── k8s/kube-manifest.yaml # GitOps 清单│└── docs/ └── architecture.md # 完整架构文档代码量统计:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一些真实体验
最让我惊讶的地方:AI 在处理跨文件依赖时的能力。比如把 Prometheus 指标改成 OTel Metrics API,涉及 8 个文件,AI 能在一次对话里全部改完,而且改完后编译直接通过,测试全绿。
最有价值的功能:工作记忆。当天下午继续工作,AI 完全知道上午做了什么,不需要重新介绍项目背景。这种”上下文延续”是 AI 编程助手真正走向实用的关键。
一点小坑:Windows 和 Linux 的 Shell 命令差异,AI 第一次写测试用了 Linux 的 echo,在 Windows 上跑不起来。好在 AI 识别到错误后立即修复——类似这种平台差异,最好在 MEMORY.md 里预先写明开发环境。
快速上手 WorkBuddy
如果你想复现类似的工作流,几个关键设置:
1. 在 MEMORY.md 里写入项目约定
# 项目约定- 语言:Go 1.25- 错误处理:fmt.Errorf("context: %w", err)- 日志:统一用 observability.Logger()- 测试:外部依赖全部 Mock,不依赖真实服务- 开发环境:Windows,Shell 测试用 cmd.exe2. 建立明确的 Todo 驱动节奏
每次对话开始,让 AI 先确认当前 Todo 状态,再开始工作。
3. 利用 Plan 模式做架构评审
重要改动先出方案,审查通过再执行,避免不可逆操作。
4. 定期让 AI 更新工作记忆
完成一个阶段后,提示 AI 把关键决策沉淀到 MEMORY.md,这些信息会在未来的会话里持续发挥价值。
总结
用 AI 编程助手开发一个完整的分布式系统,最大的收获不是”快了多少”,而是:
-
1. 架构决策有人帮你想:AI 会主动指出方案的权衡点 -
2. 重复劳动消失了:样板代码、配置文件、测试用例,AI 一键搞定 -
3. 上下文不再遗失:工作记忆让 AI 成为真正的”长期协作者” -
4. 错误修复变得轻松:编译报错、lint 警告,AI 比你更快找到原因
WorkBuddy 最让我印象深刻的,是它把 AI 助手定位成一个真正的协作者,而不只是一个代码生成器。工作记忆、Todo 管理、Plan 模式……这些设计让 AI 能参与到真实的软件工程流程里。
如果这篇文章对你有帮助,欢迎关注转发。有任何问题,在评论区留言,我会一一回复。