 夜雨聆风
夜雨聆风





写文档就能做视频!Adobe发布Doki,用文本原生界面重构AI视频创作全流程
字数 2960,阅读大约需 15 分钟
写文档就能做视频!Adobe发布Doki,用文本原生界面重构AI视频创作全流程
每个想做视频的创作者,几乎都被同样的问题困住过:
想把脑海里的故事变成视频,先要学复杂的非线性剪辑软件,在时间线、多轨道、素材库之间反复横跳;用AI视频工具,只能生成几秒的单镜头片段,想保持人物、场景、风格的一致性,要在每个Prompt里重复写大段描述;从脚本撰写、素材生成、剪辑拼接,到音频配乐,要在五六个工具之间来回切换,创意的热情全被繁琐的操作消耗殆尽。
有没有一种可能,做视频能像写文档一样简单?
Adobe Research最新发布的这项研究,给出了颠覆性的答案。团队推出了Doki——一个完全文本原生的生成式视频创作界面,把视频创作的全流程:资产定义、场景结构、镜头生成、剪辑精修、音频添加,全部浓缩到了一个文本文档里。你写的每一句话,既是故事脚本,也是可执行的视频生成指令;你定义的每一个角色、场景、风格,能在全片自动保持一致,再也不用重复写Prompt。
在为期一周的用户研究中,10位从专业电影人到零经验新手的参与者,用Doki产出了46支视频,系统可用性评分(SUS)平均高达81.2,达到了“优秀”级别。它不仅让零经验的创作者第一次做出了自己的动画故事,也让专业创作者实现了15分钟产出1分钟视频的效率飞跃。
一、行业痛点:AI视频时代,我们依然被工具困住了
论文开篇就戳破了当下AI视频创作的核心困境:尽管文生视频模型已经能生成高保真的短片,但创作工具的交互范式,依然停留在传统剪辑的框架里。
团队通过分析大量创作者的工作流,总结出了三个行业普遍存在的核心痛点:
-
1. 工具与格式的碎片化:哪怕做一支简单的短视频,创作者也要在文本编辑器、文生图工具、视频生成模型、音频软件、剪辑软件之间反复切换,脚本、素材、工程文件散落在不同格式里,频繁的上下文切换彻底打断了创作流。 -
2. Prompt工程优先于故事创作:为了保持多镜头的一致性,创作者要在每个镜头的Prompt里重复描述人物、场景、风格,30个镜头就要写30段冗长的Prompt,精力全放在了Prompt调优上,反而没有心力打磨叙事本身。 -
3. 一致性与连贯性的失控:仅靠参考图无法保障长故事的视觉连贯性,随着项目规模扩大,人物形象、场景风格、叙事节奏必然会出现漂移,而现有工具没有提供结构性的解决方案。
更关键的是,现有工具几乎都采用了“便当盒”式的多面板界面,把脚本、画布、故事板、时间线拆分在不同窗格中,创作者需要不断在多个视图之间 reconcile,产生了极高的认知负荷。而Doki选择了一条完全相反的路:把所有创作环节统一到一个文本原生的单一表示中,让写故事的过程,就是做视频的过程。
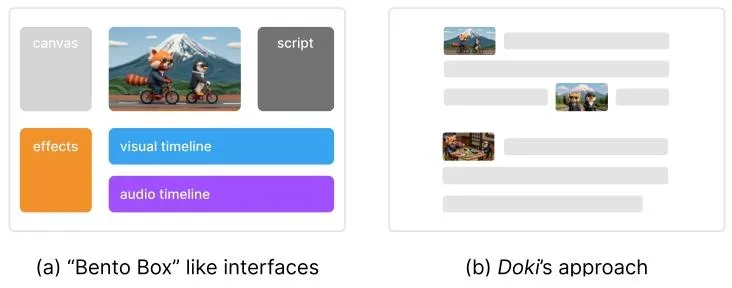
图2 界面范式对比:(a)传统“便当盒”多面板界面,创作分散在多个独立视图中;(b)Doki的文本原生范式,文档本身就是核心创作界面
二、Doki的核心设计:文档即视频,文本即创作
Doki的核心设计,是一套三层层级的结构化文本表示,完美对齐了人类的写作习惯和电影制作的底层逻辑:
文档即视频,段落即序列,句子即镜头
-
• 最高层:整个文档对应一个完整的视频项目,文本的排列顺序直接决定了视频的结构; -
• 中间层:每个段落对应电影中的一个场景/序列,围绕一个连续的叙事单元组织多个镜头; -
• 最底层:每个句子对应一个独立的镜头,是视频的最小创作单元。
在此基础上,Doki用**@提及(Mentions)** 和**#标签(Hashtags)** 构建了一套参数化定义系统,从根本上解决了多镜头一致性的行业难题。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
Character @Pandi = 一只戴墨镜穿西装的可爱小熊猫 |
|
|
|
|
Style #all = 吉卜力动画风格
#WideShot 全景镜头 |
表 Doki核心参数化定义体系
你只需要在文档开头用一行文本定义好角色、场景、全局风格,后续的故事里只需要用@和#引用,Doki就会自动把定义注入到每个镜头的生成中,同时自动引用前序镜头的画面作为参考,从结构上保障了全片的视觉连贯性。修改定义时,所有引用的镜头会自动标记为待更新,一键就能完成全片的风格迭代,彻底告别了逐个修改Prompt的繁琐。
除此之外,Doki的极简交互设计,让创作门槛降到了极致:
-
• 斜杠菜单:输入 /就能呼出全部创作工具,新建镜头、定义资产、添加音频,无需记忆任何指令; -
• 行内镜头预览:每个镜头的生成预览直接嵌入在文本中,点击就能播放、剪辑、重新生成,不用离开文档就能完成精修; -
• 双AI代理体系:侧边栏对话代理可以基于全文档上下文完成大规模修改,行内代理能选中文本直接做润色、转定义、自定义修改,AI的每一步操作都直接体现在文档里,完全透明可编辑; -
• 原生音频支持:用方括号就能在文本中插入旁白、背景音乐、音效,和视频生成深度同步。
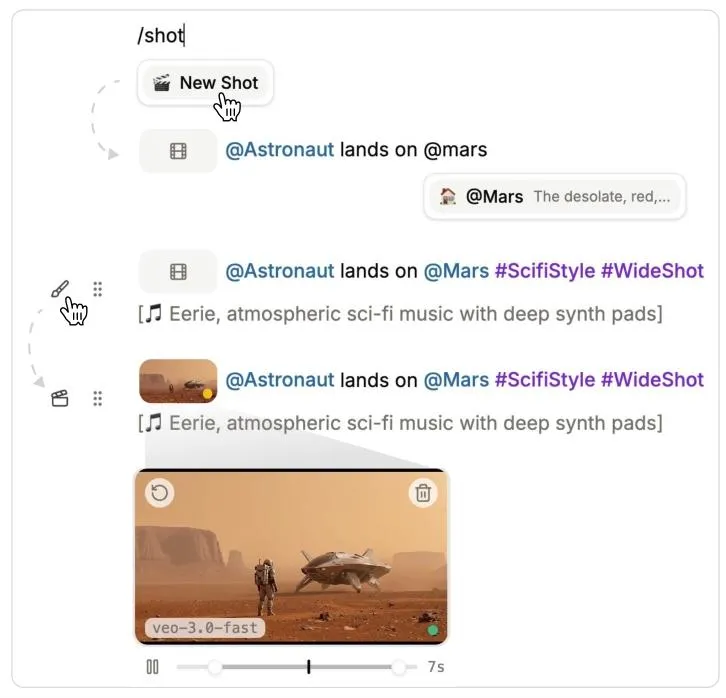
图4 Doki镜头创建流程:在文本中插入镜头节点,后续的描述就是生成Prompt,系统先生成预览图,再生成视频片段,全程在文档内完成
三、用户研究:10位创作者,46支视频,验证文本原生的创作力
为了验证Doki的实际价值,团队开展了为期一周的日记式用户研究,招募了10位不同背景的参与者,涵盖专业电影人、动画师、设计师、软件工程师,以及零视频创作经验的新手。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表1 参与者背景与系统可用性评分,平均SUS得分81.2,达到“优秀”级别
研究结果展现出了文本原生范式的强大生命力:
-
1. 极致的创作效率:参与者平均单次使用时长91.7分钟,每分钟能产出0.6张预览图、0.3条视频,平均15分钟就能完成1分钟的完整视频,而传统手工作业,1分钟动画往往需要数天的制作周期。 -
2. 新手被彻底赋能:4位没有视频创作经验的参与者表示,Doki让他们第一次做出了属于自己的动画故事,原本需要专业技能的视频创作,变成了人人都能上手的写作。 -
3. 专业创作者的新工具:专业电影人和动画师并没有把Doki当成专业工具的替代品,而是将其作为快速原型、故事板创作的互补工具。一位动画师表示,手工制作1分钟动画需要2个月,而用Doki1小时就能完成故事版动态预览,效率提升是颠覆性的。 -
4. AI自动化与创作所有权的完美平衡:8位参与者会优先用AI生成初稿,甚至全程依赖AI代理完成大部分工作,但所有人都表示自己依然拥有强烈的创作所有权,他们把自己的角色比作“导演”,而AI是执行的团队——文档作为人机协同的共同基础,让人类始终掌握着叙事的最终决策权,AI的每一步操作都透明、可追溯、可修改。

图11 参与者用Doki创作的视频关键帧,涵盖故事叙事、教学、广告、音乐视频等多种类型
四、范式革命:文本,是人机协同创作的最佳共同基础
这篇论文的价值,远不止于推出了一款新的AI视频工具,而是重新定义了生成式AI时代的创作交互范式。
当下绝大多数AI创作工具,都遵循“Prompt输入-黑盒生成-成品输出”的模式,创作者很难在生成过程中介入和修改,AI的操作是不透明的,一旦生成结果不符合预期,只能推倒重来。而Doki提出了一个全新的思路:用文档作为人机协同的中间表示,它既是人类可读可编辑的故事脚本,也是AI可理解可执行的生成指令。
在这个范式里,人类和AI不再是“指令-执行”的单向关系,而是在同一个文档空间里协同创作。AI的所有修改都直接体现在文本中,人类可以随时打断、修改、调整,创作的主动权永远掌握在人手里,同时又能充分利用AI的生成能力。
当然,论文也坦诚了当前方案的局限性:线性的文本文档,在表达时间并发、跨镜头转场、音画精准同步等精细的时间控制上,依然存在短板。未来团队会通过轻量级的时间原语,进一步完善文档的时间表达能力。
但不可否认的是,Doki为生成式视频创作,打开了一条全新的道路。它让我们看到,AI时代的创作工具,不该是用复杂的界面复刻传统剪辑的流程,而应该回归创作的本质——让创作者专注于故事本身,把技术的繁琐交给AI。
当写文档就能做视频,当每个人都能把脑海里的故事,轻松变成可看可感的视频,创作的边界,将会被无限拓宽。
https://arxiv.org/pdf/2603.09072