 夜雨聆风
夜雨聆风





第05篇-知识库文档分块的学问
纯手搓 AI Agent(五)—— 文档分块的学问:太大 LLM 吃不下,太小又没营养
上一篇我们把 RAG 的全链路先过了一遍:文档上传进来,抽文本、切分、向量化、存 ES,查询时再检索、重排、回填,最后把结果塞给 LLM 回答。
这条链路里最容易被低估的一步,就是分块(Chunking)。
很多人做 RAG,第一反应是先挑模型、先调 Embedding、先看向量库。结果跑起来发现回答总是不对味:明明文档里有答案,就是搜不准;或者搜到了,但返回给 LLM 的内容东一榔头西一棒子,最后答得半对半错。
坑往往不在模型,在分块。
文档块切太大,检索命中了但噪音太多;切太小,检索看起来很准,给 LLM 的上下文又不够。说白了,RAG 的第一刀没切好,后面基本都在给前面的错误擦屁股。
为什么分块这一步决定了 RAG 下限
先把问题掰开说。
1. LLM 的上下文窗口再大,也不是无底洞
很多人一看现在有 128K 上下文的模型,就容易飘:那我是不是整篇文档直接塞进去就行了?
理论上能塞,实际上没必要。因为上下文不是越长越好,而是越相关越好。
一篇几万字的排障文档里,真正和问题相关的可能就三五段。你把整篇全塞进去,相当于把关键答案埋进一堆无关背景里,LLM 不一定能稳定抓住重点。不是模型吃不下,是吃进去以后消化得不够准。
2. Embedding 也有自己的舒适区
Embedding 模型不是黑洞,不是说文字越长、信息越多,算出来的向量就越准。
文本太长,多个主题会混在一个向量里,语义中心被摊薄;文本太短,又容易只剩下几个关键词,信息量不够。最后的结果就是:该近的不够近,不该近的反而混进来了。
所以分块本质上是在做一件事:给 Embedding 和 LLM 同时准备一份它们都能吃得舒服的输入。
3. 检索命中的精度,直接取决于粒度
这个很好理解。
假设一块内容里同时讲了「HDFS 扩容」「副本数配置」「故障恢复」。用户搜的是「副本数配置」,这一整块可能会被命中,但返回给 LLM 的内容里有三分之二都是噪音。
反过来,如果你把内容切得过碎,确实精准了,但 LLM 拿到的只有一句半句,前后因果关系断了,照样容易答偏。
所以分块从来不是越小越好,也不是越大越好,而是一个很现实的 trade-off。
第一层:按 Token 精确切,先解决“别切爆了”
在 xbo-kbase 里,最基础的做法是 TokenChunker。
它不是按字符数切,也不是按行数切,而是按 Token 数量切。原因很直接:模型限制的是 Token,不是字数。
为什么不能按字符数切
中文、英文、标点、代码、URL,在 tokenizer 眼里完全不是一回事。
有的中文字会拆成多个 Token,有的英文单词可能一个 Token 就装下了。你按 500 个字符切,看起来长度差不多,实际 Token 数可能已经差出一大截。
代码里用的是 GPT-3.5/4 同款的 CL100K_BASE 编码器:
这个设计有两个细节挺实用:
第一,全局只初始化一次,避免每次分块都去加载 tokenizer 的词表;第二,直接和主流大模型的 token 口径保持一致,后续估算 chunk 大小更稳。
动态 Chunk Size,不搞一刀切
一开始很多人会写死一个值,比如每块 512 Token。能跑,但不一定聪明。
问题在于:短文本和长文本根本不是一个物种。短文本本来就几百 Token,你硬切,纯属没事找事;长文本如果还按 512 固定切,又会切出过多碎片,后续召回和存储压力都上来。
TokenChunker 里做了一个动态计算:
它的思路很朴素,但很对路:
- 短文本尽量少切,能保完整就保完整
- 中等文本维持在 512 左右,兼顾语义和检索粒度
- 长文本适当放大块尺寸,减少碎片数量,但又不超过上限
对应的参数也写得比较克制:MIN_CHUNK_SIZE = 256,MAX_CHUNK_SIZE = 1024。这就意味着它不会因为文本过短而切出一堆太碎的小块,也不会因为文本过长而把块撑得离谱。
Overlap 不是可选项,是保险丝
只切块不重叠,理论上也能跑,但很容易在边界上翻车。
最典型的场景就是:一句关键结论的上半句在块 A,参数解释在块 B。检索命中了 A,但 A 里信息不完整;命中了 B,B 又缺上文。最后你会觉得“明明文档里有,怎么答不全”。
解决方法就是 overlap,也就是相邻块之间保留一段重叠内容。
这里取的是 15%,并且设了下限 20、上限 205。这个比例挺像工程上的经验值:
-
太小,等于没重叠,边界信息还是会断 -
太大,重复内容太多,存储和召回都浪费
所以 overlap 的本质,是拿一点点冗余,换跨块语义不断裂。
第二层:只按 Token 还不够,得尽量沿着语义边界切
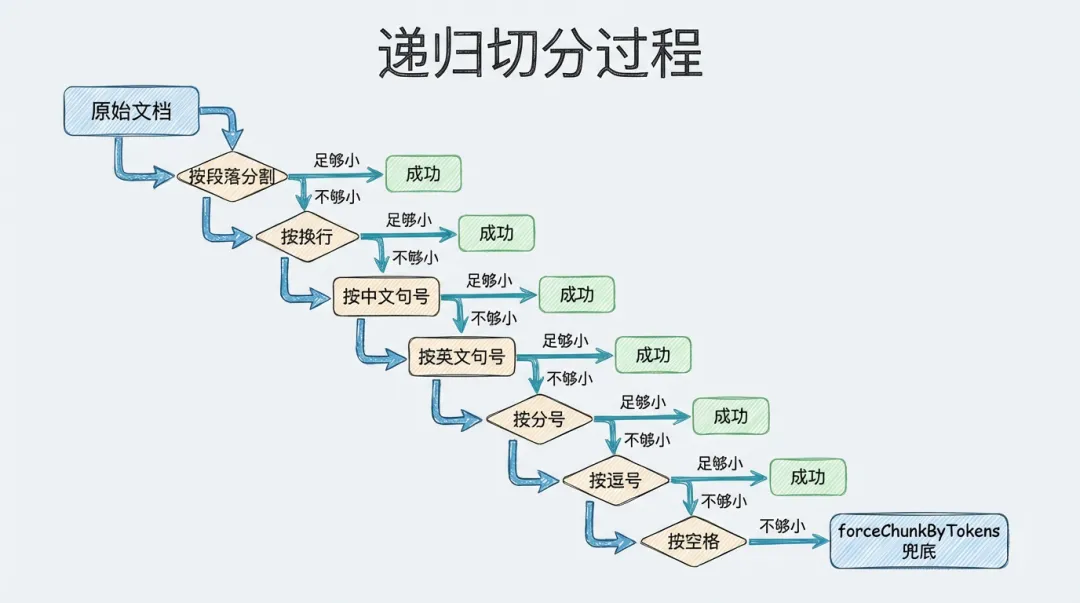
TokenChunker 解决的是长度控制问题,但还没解决语义完整性问题。
因为它本质上还是“按大小切”。就算 chunk size 算得再合理,也可能正好把一句话劈成两半,把一个列表拆在中间,甚至把一段代码逻辑从中腰斩断。
这时候就该 RecursiveTextSplitter 上场了。
递归切分的核心思想:先粗后细,能不断层就不断层
这个类最值钱的地方,不是“递归”这两个字,而是它背后的策略:
先尝试在大的语义边界上切,切不动,再逐级降级到更细的边界。
代码里的分隔符优先级是这样排的:
翻译成人话就是:
-
先按段落切 -
段落切不下来,再按行切 -
再不行,就按句号、问号、感叹号切 -
还不行,再退到分号、逗号、空格 -
实在没法优雅切,最后再硬切
这套顺序非常关键。因为段落边界天然比逗号边界更有语义完整性。优先在更大的结构上切,检索块读起来更像“人话”,而不是 tokenizer 的残片。
递归逻辑为什么比固定规则靠谱
来看核心流程:
这里有三个关键点:
- 足够小就停,不做多余切分
- 当前分隔符切不动就降级,继续尝试更细的边界
- 就算切开了,也不是简单把 parts 全扔出去,而是先合并成尽量接近上限、又不超限的块
这个“先分再合”的过程很重要。因为真实文本不是工整的砖块,段落长度长短不一。你不能只会切,还得会拼,不然一个 20 Token 的残段、一个 30 Token 的残段、一个 40 Token 的残段,最后会搞出一堆信息密度很差的碎片。
最后一层兜底:再不行就硬切
现实世界的文本不总是那么配合。
比如超长 URL、没有标点的大段日志、挤成一坨的 OCR 结果、超长代码块,都可能让上面的语义切分策略失效。这时候如果还坚持“必须优雅”,只会卡死。
所以 RecursiveTextSplitter 最后留了一个兜底:forceChunkByTokens()。
意思很明确:优雅不了就别装,先保证数据不丢、流程能跑。
这就是工程代码和 demo 代码的区别。demo 追求漂亮,生产代码先保证不炸。
第三层:小块检索准,大块上下文足——那就别二选一
做到前面两层,其实已经比很多 RAG 实现强不少了。但真跑到生产里,还会遇到一个更棘手的问题:
你到底是应该给检索更小的块,还是应该给 LLM 更大的上下文?
这问题本身就是个陷阱,因为答案往往是:两者都要。
只用小块的问题:检索很准,回答容易短路
如果块很小,比如 300~500 Token,召回通常会很准。因为每块只讲一个局部点,语义聚焦。
但问题是,LLM 最终看到的也是这一小块。它可能知道某个配置项的定义,却不知道前面的适用条件;知道一个报错片段,却不知道后面怎么处理。
结果就是它答得像对,但不完整。
只用大块的问题:上下文完整,命中太模糊
如果块很大,比如 2000 Token 甚至更长,返回给 LLM 的信息会更完整,前因后果都在。
但检索阶段会变钝。因为一个大块里往往混了多个主题,向量表达是“平均语义”,最后谁都沾一点,谁都不够准。
这就是经典矛盾:小块适合找,大块适合答。
Parent-Child 的思路:让找和答各干各的
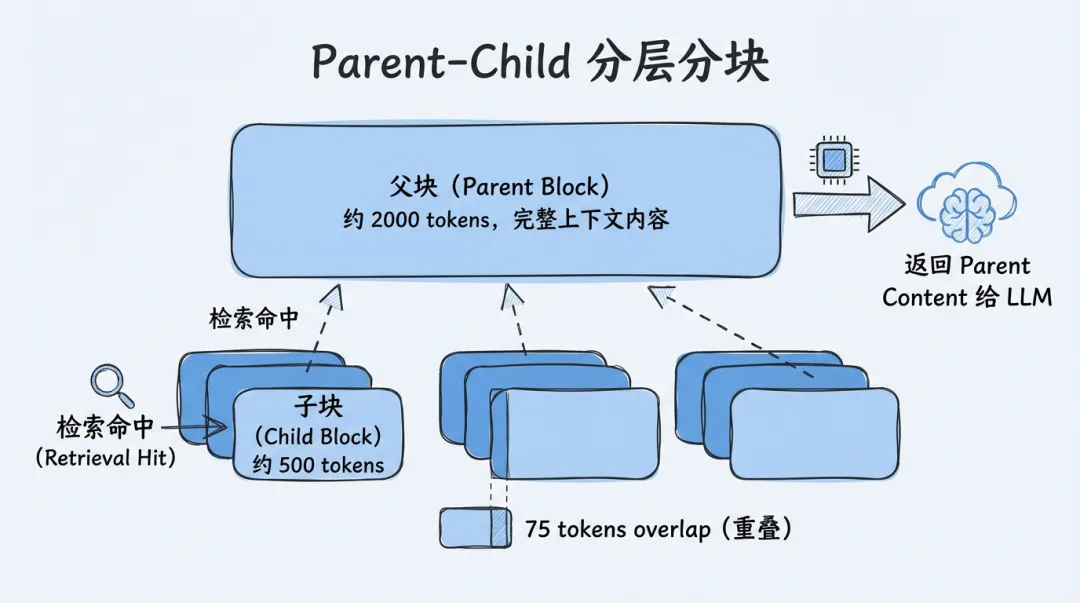
RecursiveTextSplitter 里给的解法,就是 Parent-Child 分层分块。
这个设计说复杂也不复杂,本质就是两层:
- Parent 块:大块,保留完整上下文,给 LLM 看
- Child 块:小块,粒度更细,拿去做检索
最关键的是 childToParentIndex 这个映射。它记录了每个 child 属于哪个 parent。这样一来:
-
检索阶段只对 child 做匹配,保证精度 -
命中 child 之后,根据映射找到 parent -
最终返回给 LLM 的,不是那一小块,而是对应的大块上下文
这一下就把“检索精准”和“回答完整”两件事分开处理了。
Parent-Child 在入库编排里是怎么落地的
说完原理,再看真正落库时怎么接进去。
在 EsKnowledgeBuildService 里,先做了一个分流判断:
也就是说,不是所有文档都上 Parent-Child。
这点很重要。因为 Parent-Child 虽然效果好,但复杂度也更高。短文本本身信息就集中,没必要为了炫技强行套两层结构。只有超过 1000 Token 的长文本,才值得上分层方案。
为什么是 1000 Token 阈值
这个值不是理论真理,更像一个工程上的经验分界线。
小于这个长度,文本通常还没长到“一个块里塞进多个大主题”的程度,普通切分已经够用;超过这个长度,长文档内部的主题扩散就会开始明显,Parent-Child 的收益会更大。
说白了,这个阈值不是学术论文里推出来的,是跑出来的。
真正写 ES 时只给 Child 做 Embedding
继续看 buildTextWithParentChild():
参数也很有代表性:
Parent = 2000 tokensChild = 500 tokensChild overlap = 75 tokens
这组参数的思路很清楚:
-
2000 Token 的 parent,足够给 LLM 提供一段相对完整的上下文 -
500 Token 的 child,检索粒度不会太粗 -
75 Token overlap,跨块连接信息不至于断掉
更关键的是:只对 child 做 embedding。
这是一个非常实在的优化。因为 parent 不参与检索,只是回填给 LLM 看。如果 parent 也做 embedding,一方面多花钱,另一方面也没实际收益。
ES 里同时存 child 和 parentContent
真正写库时,结构是这样的:
这里的设计很关键:
content
存 child 文本,供 BM25 和向量检索使用 parentContent
存 parent 文本,供命中后回填给 LLM chunkType
标记这是一条 child 记录
也就是说,ES 里每一条被检索的记录,其实都背着一份更完整的“上级上下文”。这样在召回命中时,不需要再二次查库组装,直接就能把 parentContent 取出来用。
这种设计非常适合线上路径,因为它减少了检索后的拼装成本。
别只盯着切分,文本提取质量会决定你后面能不能切得漂亮
分块讲到这里,再补一个经常被忽略的点:不是所有原始文档一开始就是干净文本。
如果上游抽出来的文本已经稀烂,那后面切分策略再高级,效果也会打折。
UniversalTextExtractor 负责的就是这件事。
小文件直接抽,大文件走流式
这个分支不复杂,但很有必要。因为不同文件大小,对内存占用和处理方式完全不一样。文档一大,直接一次性全读进来,轻则慢,重则顶内存。
OCR 和 PDF 配置不是点缀,是质量底座
UniversalTextExtractor 里用了 Apache Tika 做统一解析,同时给 OCR 和 PDF 做了专门配置:
这些配置看着像细枝末节,其实很影响后面的 chunk 质量。
比如 PDF 如果不按位置排序,抽出来的文字顺序可能是乱的;不自动补空格,英文和数字可能粘成一团;OCR 语言没配对,中文英文混排文件就容易识别得一塌糊涂。
而分块是建立在“文本基本可读”的前提上的。你前面抽出来一锅粥,后面怎么切都不可能太优雅。
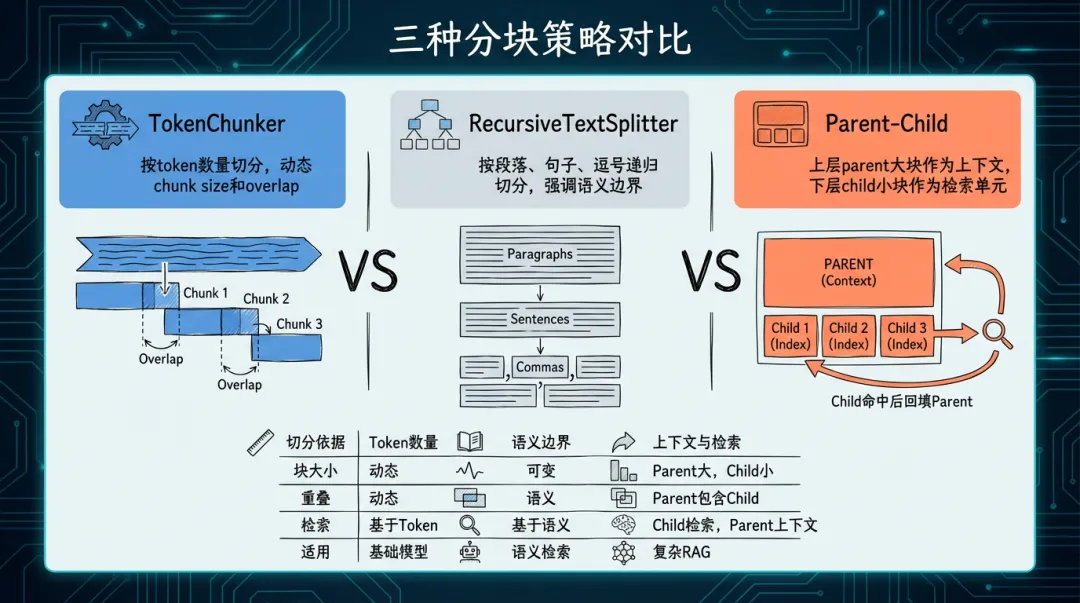
三种策略怎么选,不要迷信唯一正确答案
看到这里,基本可以把这套分块设计总结成三层选择:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
TokenChunker |
|
|
|
|
|
RecursiveTextSplitter.split() |
|
|
|
|
|
splitWithParentChild() |
|
|
|
真要给经验结论,我会这么说:
- 短文本先别上重型方案,普通 Token/递归切分就够了
- 通用知识文档优先递归语义分块,比死切稳定得多
- 长文档、规章制度、手册类内容,尽量上 Parent-Child,收益非常明显
别一上来就追求“最先进方案”,先看你的文档长度、内容结构、检索目标是不是配得上它。
小结
RAG 里,分块不是准备动作,而是决定检索质量的起跑线。
这篇文章拆了三层思路:
- TokenChunker 解决的是长度边界问题:按 Token 精确切,动态 chunk size + overlap
- RecursiveTextSplitter 解决的是语义完整性问题:尽量沿着段落、句子这些自然边界切
- Parent-Child 解决的是检索和回答目标冲突的问题:小块负责找,大块负责答
如果要浓缩成一句话,就是:
RAG 的分块,本质不是把文档切开,而是把“适合检索的表示”和“适合回答的上下文”同时准备好。
这件事做对了,后面的向量检索、重排、去重,才能真正建立在靠谱的输入上。做不对,后面调再多参数,也常常是在给错误的切法打补丁。
下一篇我们继续往下拆,聊聊向量检索最核心的底层问题:Embedding 到底是什么,余弦相似度到底在算什么,为什么“苹果手机”和“iPhone”在向量空间里会靠得很近。
纯手搓 AI Agent 系列 | 第 5 篇 / 共 25 篇
#纯手搓AIAgent #RAG #文档分块 #Chunking #向量检索 #AI #Java #后端开发 #知识库 #大模型 #智能问答
觉得有用?扫码关注「昕悦技术栈」持续输出实战干货

长按识别二维码,关注我!