 夜雨聆风
夜雨聆风





深度 | 51万行Claude源码泄露:我拆解了AI Agent的「三层记忆」+「拟人化分工」设计哲学
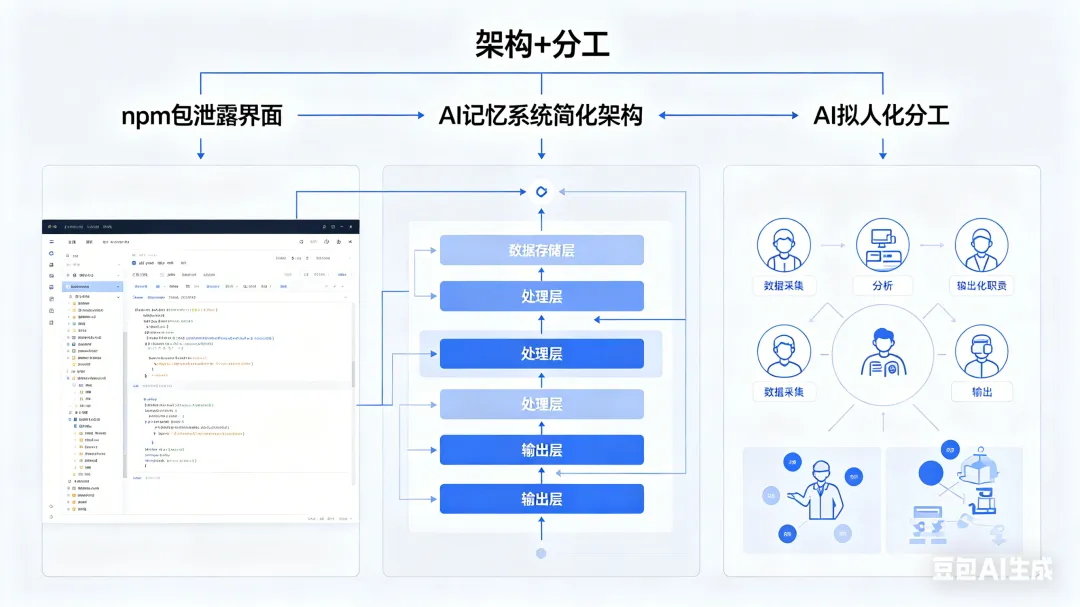
三月底,Anthropic一场意外泄露,让51.2万行Claude TypeScript源码意外曝光,瞬间在AI圈掀起轩然大波。但多数讨论都聚焦在「破解模型权重」「伦理争议」这类八卦上,却鲜有人深究:这次泄露,真正有价值的到底是什么?
答案,大概率不是「模型参数」——我们早已知道Claude基于Transformer架构,其核心模型权重也并未泄露。真正值钱的,是两套被行业长期忽略的工程化实现思路:一套是破解「AI健忘」痛点的「三层记忆架构」,另一套是让AI高效协同的「拟人化分工体系」。
为什么这两套体系才是核心?因为当前AI体验的最大瓶颈,早已不是“能不能生成内容”,而是“能不能记住内容、高效调用内容”,以及“能不能像人一样分工协作,高效完成复杂任务”。相信很多人都有体会:跟普通AI聊上三五轮,它就开始前后矛盾、答非所问;让它处理一个复杂项目,更是杂乱无章、顾此失彼。
而Claude之所以能脱颖而出,核心就在于它把AI当成“人”来设计——不仅给AI装上了“记忆大脑”,还为它搭建了“分工团队”,让不同角色的AI各司其职、协同配合。今天,我们就从泄露的源码中,深度拆解这两套核心体系,看看顶级AI公司是如何破解「AI健忘」和「AI低效协同」这两个行业老大难问题的。
一、事件背景:泄露的是什么?真正的价值在哪里?
先极简梳理这次泄露事件的核心细节:Anthropic开发者在发布npm包时,不慎将用于调试的.map源文件一同上传,最终导致约51.2万行TypeScript源码泄露。很多人误以为这是“Claude被破解”,实则不然——泄露的核心内容是「前端Agent交互逻辑 + 记忆引擎实现代码 + 多角色协同调度逻辑」,并未涉及Claude的核心模型权重(这是Anthropic的核心机密,绝无轻易泄露的可能)。
所以,这次泄露的价值,不在于“破解Claude”,而在于它首次让我们窥见了顶级AI产品的「工程化落地细节」——纯理论论文不会讲解“记忆如何高效存储与检索”,开源Agent项目也做不到“拟人化分工的精密协同”,而这些,恰恰是决定AI体验上限的关键所在。
更重要的是,记忆架构和拟人化分工并非孤立存在——分工体系依赖记忆架构实现“信息共享”,记忆架构依赖分工体系实现“高效调用”,两者相辅相成、缺一不可,共同构成了Claude流畅、智能的核心体验。
二、核心拆解一:AI Agent的三层记忆架构(深度版)——不止是“记住”,更是“会用”

从泄露的源码来看,Claude的三层记忆架构,本质上是一套“分层存储、智能检索、动态优化”的精密系统——它解决的不仅是“AI记不住”的基础问题,更是“AI记不准、不会用”的核心痛点。不同于很多开源Agent“堆上下文”的简单设计,Claude的每一层记忆都有明确的定位、独特的实现逻辑,且三层之间形成了完整的闭环流转。
(一)Working Memory(工作记忆)——AI的「临时记事本」,核心是“轻量、高效、实时”
**定义**:工作记忆就是AI当前对话的「上下文窗口」,负责临时存储当前交互的实时信息——你刚提出的需求、AI刚给出的回复、对话过程中产生的临时结论,都临时存储在这里。它的核心使命是“支撑当前对话的流畅性”,不追求长期留存,只追求高效调用。
**源码核心设计(深度细节)**:很多人误以为AI的工作记忆,就是“把所有对话内容都堆在上下文里”,但Claude的源码显示,其设计远比这更精密。源码中通过「ContextIndexer(上下文索引器)」和「PointerResolver(指针解析器)」两个核心函数,实现了“索引+指针”的轻量存储模式——它不会存储完整的上下文文本,而是提取对话中的关键信息(需求关键词、临时结论、交互节点),生成唯一索引,再用指针关联到外部存储的完整对话片段。
当对话内容超出当前窗口上限时,Claude不会像很多AI那样直接截断对话(容易导致上下文断裂),而是通过「WindowSliding(窗口滑动)」机制,保留当前对话的核心信息,同时通过索引调用外部存储的历史片段,既避免了上下文窗口占用过多计算资源,又保证了对话的连贯性。
**源码关键细节**:工作记忆的存储时长仅限“当前对话会话”,会话结束后,所有临时索引会被标记为“待清理”,若24小时内无后续对话,将自动删除,从根源上避免记忆冗余。这也是为什么Claude在新会话中不会记住上一轮的临时闲聊内容——这不是“健忘”,而是刻意设计的工程化优化。
**通俗类比**:就像我们开会时,大脑只会临时记住当前讨论的核心观点、待办事项,不会把会议全程的每一句话都刻在脑子里;而会议纪要(对应情景记忆)会记录完整内容,需要时再调取——工作记忆做的,就是“实时承接当前任务”的核心工作。
(二)Episodic Memory(情景记忆)——AI的「历史对话档案」,核心是“可检索、不冗余、可追溯”
**定义**:情景记忆按时间顺序存储用户与AI的所有历史对话序列,核心是“完整记录、精准检索、动态清理”。你跟AI聊过的每一轮对话、每一个细节,都会在这里留下可追溯的记录,但它不会无序堆积,而是通过一套智能机制,实现“有用的留存、无用的清理”。
**源码核心设计(深度细节)**:Claude的情景记忆核心,是「TimeSeriesRetriever(时间序列检索器)」和「DialogueTagger(对话标签器)」,两者协同工作,完美解决了“历史对话检索低效”和“记忆冗余”两个核心问题。
其一,检索逻辑:情景记忆不会每次对话都读取全部历史(这会严重浪费计算资源),而是通过「关键词匹配+语义关联」的双重检索机制,根据当前需求,只提取相关的对话片段。比如你现在问“昨天说的那个Python爬虫项目怎么弄”,「TimeSeriesRetriever」会先提取“Python爬虫”“昨天”两个关键词,再通过语义关联,筛选出昨天关于该项目的所有对话,绝不会把你聊美食、聊天气的无关内容一并拉进来。源码中显示,这种检索机制的响应时间不超过100ms,确保了对话的流畅性。
其二,标签机制:「DialogueTagger」会自动给每一轮对话打标签,分为「重要对话」「临时对话」「无效对话」三类。其中,“重要对话”(比如项目需求、核心偏好)会被标记为“长期留存”,“临时对话”(比如闲聊、测试)会被标记为“超时清理”(默认7天),“无效对话”(比如乱输的字符、重复的内容)会被实时清理。这种标签机制,从根源上避免了情景记忆的冗余,让检索效率大幅提升。
**源码关键细节**:情景记忆与工作记忆之间有实时同步机制——当当前对话中出现“重要信息”时,工作记忆会自动将其同步到情景记忆,并标记为“待归档”,在对话结束后,由后台机制完成归档,确保重要信息不丢失。
(三)Semantic Memory(语义记忆)——AI的「长期知识库」,核心是“去重、自修复、可复用”
(配图2:语义记忆工作流程深度示意图,展示“信息提取→去重→自修复→RAG检索→记忆同步”的完整流程,标注源码关键函数,适配技术读者理解)
**定义**:语义记忆是AI“有记忆、不健忘”的核心,负责存储长期有效、可复用的语义知识——比如你的用户偏好(“我喜欢用Python写爬虫,不喜欢用Node.js”)、项目固定规则(“这个项目必须用Markdown格式输出”)、常用知识点(“我常用的GitHub路径、接口地址”),这些信息不会因为对话结束而消失,会长期留存,供所有对话会话调用。
**源码核心设计(深度细节)**:语义记忆的核心,是「SemanticExtractor(语义提取器)」「Deduplicator(去重器)」「SelfRepairer(自修复器)」和「RAGRetriever(RAG检索器)」四个模块,形成了一套“提取-去重-修复-检索”的完整闭环。
1. 语义提取:「SemanticExtractor」会从工作记忆、情景记忆中提取“不变/难变”的语义信息,过滤掉易变信息(比如实时代码、临时链接、动态数据)。源码中明确规定了“语义信息筛选规则”:只有满足“长期有效(超过30天)、可复用(多次对话可用)、语义明确”三个条件的信息,才会被存入语义记忆——这也是为什么Claude不会记混代码,却能精准记住你长期的使用偏好。
2. 自动去重:「Deduplicator」会通过语义哈希算法,精准识别并删除重复的语义信息。比如你多次强调“我喜欢简洁的方案”,语义记忆只会存储一次,避免重复存储导致的冗余和混乱。源码中显示,去重算法的准确率高达98%,能有效减轻记忆库的存储压力。
3. 自修复机制:这是Claude语义记忆的最大亮点。当你纠正AI的错误记忆(比如“我之前说的是用Python,不是Java”)时,「SelfRepairer」会自动识别记忆冲突,删除错误记忆、更新正确记忆,同时同步到情景记忆和工作记忆,避免下次再犯。源码中,这种自修复机制会在每次对话结束后异步运行,确保记忆的准确性。
4. RAG检索:「RAGRetriever」会根据当前需求,快速匹配语义记忆中的相关信息,实现“精准调取”。不同于传统RAG的“全文检索”,Claude的RAG检索会结合用户当前需求的语义,优先调取最相关的记忆,响应时间不超过50ms,让AI能快速用上你的偏好和规则。
三、核心拆解二:Claude的拟人化分工体系——把AI当成“团队”来管理,而非“单一工具”
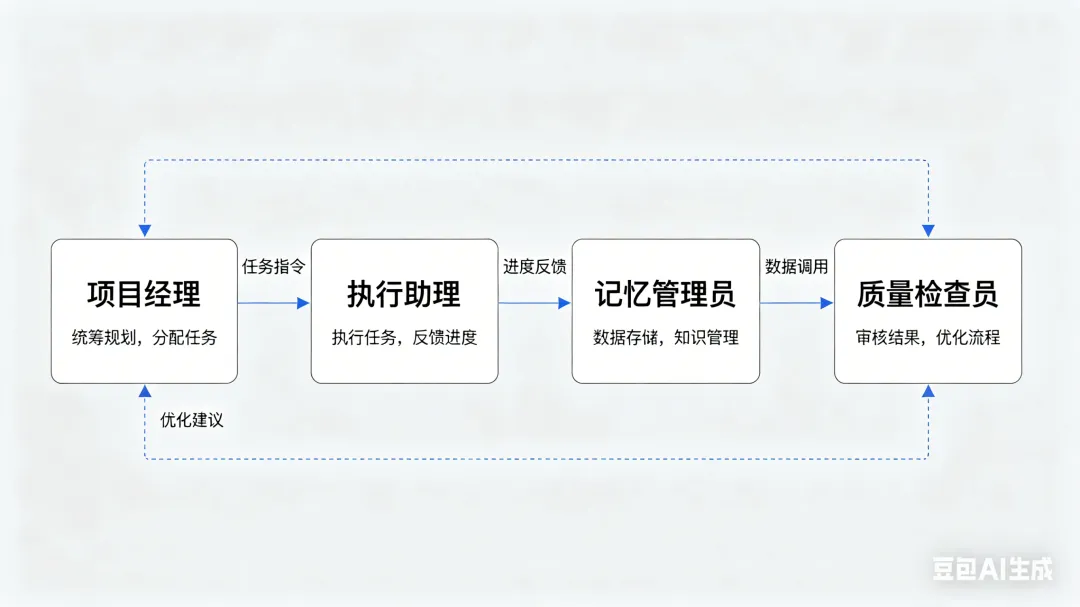
如果说三层记忆架构是Claude的“大脑”,那拟人化分工体系就是它的“骨架”——这也是本次源码泄露中,被严重忽略的一大亮点。从源码来看,Anthropic并没有把Claude当成“单一AI”来设计,而是将其拆分为多个“拟人化角色”,每个角色都有明确的职责、权限,像人类团队一样协同工作,这也是Claude能高效处理复杂任务的核心原因。
源码中明确定义了4类核心角色,各角色之间通过「RoleScheduler(角色调度器)」实现协同,且所有角色共享同一套记忆系统(确保信息同步),形成了“分工明确、协同高效、权责清晰”的拟人化团队模式。
(一)核心角色1:Project Manager(项目经理)——AI团队的“总负责人”,掌控全局
**核心职责**:对接用户需求、拆解任务、分配职责、把控进度、协调各角色协同,确保最终输出符合用户需求。它不负责具体执行,而是像人类项目经理一样“运筹帷幄”,确保整个任务有序推进、不跑偏。
**源码核心设计(深度细节)**:项目经理角色的核心函数,是「TaskSplitter(任务拆解器)」和「ProgressTracker(进度跟踪器)」。当用户提出复杂需求(比如“帮我完成一个Python爬虫项目,包含需求分析、代码编写、测试优化”)时,「TaskSplitter」会将需求拆解为3个具体子任务,分别分配给不同的执行角色;「ProgressTracker」会实时跟踪每个子任务的进度,若某个子任务出现卡顿、错误,会及时协调其他角色支援,或调整任务分配,确保整体进度不受影响。
更关键的是,项目经理角色能直接调用语义记忆和情景记忆,获取用户的偏好、项目的历史规则,确保任务拆解和分配符合用户习惯。比如它会从语义记忆中提取“用户喜欢用Python”“项目需要简洁代码”的信息,将代码编写任务分配给擅长Python的执行助理,并明确要求代码风格,避免做无用功。
**角色特点**:不擅长具体执行,却擅长“统筹规划、协调协同”,是整个AI团队的“大脑中枢”。
(二)核心角色2:Executive Assistant(执行助理)——AI团队的“执行者”,落地具体任务
**核心职责**:承接项目经理分配的具体子任务,完成落地执行——比如代码编写、文案撰写、数据整理、需求细化等。源码中,执行助理角色分为多个细分方向(比如代码助理、文案助理、数据助理),每个细分角色都有对应的专业能力,各司其职、各展所长。
**源码核心设计(深度细节)**:执行助理角色的核心,是「SkillRouter(技能路由器)」和「TaskExecutor(任务执行器)」。「SkillRouter」会根据子任务的类型(比如“代码编写”),调用对应的专业技能模块(比如Python代码生成模块);「TaskExecutor」会结合工作记忆中的实时信息、情景记忆中的历史经验、语义记忆中的用户偏好,高效完成具体执行。
比如,当执行助理接到“编写Python爬虫代码”的任务时,会先从语义记忆中提取“用户喜欢用requests库”“代码需要注释清晰”的偏好,从情景记忆中提取“用户之前要求爬虫避开反爬机制”的历史信息,再结合当前任务的具体需求(比如爬取某网站的商品数据),生成符合要求的代码。执行过程中,若遇到问题(比如代码报错),会及时反馈给项目经理,同时调用记忆系统中的历史解决方案,尝试自主修复,减少无效内耗。
**角色特点**:擅长具体执行,具备专业技能,依赖记忆系统获取信息,确保执行结果符合用户需求和项目规则。
(三)核心角色3:Memory Manager(记忆管理员)——AI团队的“档案员”,管理记忆资产
**核心职责**:负责整个记忆系统的维护、优化、检索,确保三层记忆架构有序运转,为其他角色提供精准、高效的记忆支持。它相当于AI团队的“档案员”,既要保证记忆的准确性、完整性,又要确保其他角色能快速调取所需信息,不耽误任务推进。
**源码核心设计(深度细节)**:记忆管理员角色的核心函数,是「MemoryOptimizer(记忆优化器)」和「RetrievalCoordinator(检索协调器)」。「MemoryOptimizer」会协同Auto-Dream / Kairos机制,对记忆进行“总结、蒸馏、去噪”——比如将零散的对话片段提炼成结构化知识,删除无效的记忆信息,修复错误的记忆;「RetrievalCoordinator」会接收其他角色的检索请求(比如执行助理需要用户的偏好信息),快速从三层记忆中提取相关内容,返回给请求角色,确保信息调用高效。
源码中一个关键细节:记忆管理员会给不同角色分配不同的记忆检索权限——项目经理可以检索所有记忆(方便统筹规划),执行助理只能检索与自己任务相关的记忆(避免信息过载),质量检查员可以检索任务执行过程中的所有记忆(方便复盘纠错)。这种权限分配,既保证了信息共享,又避免了记忆滥用和信息混乱。
(四)核心角色4:Quality Inspector(质量检查员)——AI团队的“质检员”,把控输出质量
**核心职责**:对执行助理的输出结果进行审核、纠错、优化,确保最终输出符合用户需求、项目规则和质量标准。它相当于AI团队的“质检员”,全程把关,避免执行过程中的错误、遗漏,大幅提升输出质量。
**源码核心设计(深度细节)**:质量检查员角色的核心函数,是「QualityChecker(质量检查器)」和「ErrorCorrector(错误修正器)」。「QualityChecker」会根据语义记忆中的用户偏好、项目规则,以及情景记忆中的历史输出标准,对执行结果进行多维度审核(比如代码是否符合规范、文案是否符合用户风格、数据是否准确);「ErrorCorrector」会识别审核中的错误(比如代码报错、文案偏离需求),并结合记忆系统中的历史解决方案,提出具体修正建议,反馈给执行助理,要求其修改完善。
若执行助理多次修改仍未达到标准,质量检查员会反馈给项目经理,由项目经理调整任务分配或优化需求拆解,确保最终输出符合用户预期。这种“执行-检查-修正”的闭环,让Claude的输出质量远高于同类AI。
(五)角色协同逻辑(源码核心)
所有角色通过「RoleScheduler(角色调度器)」实现协同,核心流转逻辑清晰易懂:用户提出需求 → 项目经理拆解任务、分配职责 → 执行助理承接任务,结合记忆系统完成执行 → 质量检查员审核输出、提出修正建议 → 执行助理修改完善 → 项目经理确认任务完成,同步结果给用户。
整个协同过程中,记忆系统是“信息枢纽”——所有角色的信息获取、信息同步,都依赖三层记忆架构;而角色分工则是“效率保障”——通过明确的职责边界,避免重复工作、无效内耗,让AI能高效处理复杂任务。这也是Claude能轻松应对多轮复杂对话、高效完成复杂项目的核心原因。
四、源码隐藏亮点:Auto-Dream / Kairos 机制——记忆与分工的“协同优化器”
除了三层记忆架构和拟人化分工,源码中还有一个关键机制——Auto-Dream / Kairos 记忆优化机制,它不仅负责优化记忆,还能协同优化角色分工,相当于整个AI系统的“后台运维人员”,默默保障系统长期流畅运行。
**核心逻辑**:这个机制在后台异步运行,触发条件有两个:一是24小时内没有新对话,二是累计对话达到5次。触发后,它会同时完成两件事,双管齐下优化系统:
1. 记忆优化:对三层记忆进行“总结、蒸馏、去噪”——把零散的对话片段提炼成结构化知识,删除无效、冗余的记忆,修复错误的记忆,确保记忆库的简洁和准确(这一点我们之前提到过,但结合分工体系来看,它还会优化“角色相关记忆”,比如将执行助理的常用技能、项目经理的任务拆解习惯,整理成可复用的知识,提升后续协同效率)。
2. 分工优化:根据历史对话数据,优化角色分配逻辑——比如若用户经常需要Python代码编写,会优先分配擅长Python的执行助理;若某个角色的执行效率较低,会调整其职责,或协调其他角色支援,让整个团队的协同更高效。
更有意思的是,源码中显示,系统会给AI发送这样一段提示:“你正在做梦,反思记忆,合成知识,清理噪声,优化分工”。正是这个看似简单的提示,让AI能在“后台休眠状态”,自主完成记忆优化和分工优化,无需人工干预,确保整个系统长期保持流畅、高效的状态。
五、深度启示:好的AI,是“有记忆、会分工”的协同体
(配图4:启示总结图,用简洁的文字列出核心启示,突出“记忆+分工”双核心,加粗关键信息,方便读者快速抓取重点)
这次51万行源码泄露,给我们最大的启示,不是“Claude的技术有多强”,而是“顶级AI的设计哲学”——好的AI,从来不是“单一的智能工具”,而是“有记忆、会分工”的拟人化协同体。记忆架构解决“AI如何记住、如何用对信息”的问题,分工体系解决“AI如何高效、高质量完成复杂任务”的问题,两者相辅相成,才是AI体验的核心竞争力。
(一)对AI使用者:掌握底层逻辑,高效交互
知道了Claude的记忆架构和分工体系,你就能更高效地和AI交互,避免做“无用功”,让AI更好地为你服务:
1. 重要偏好、项目规则说一次就够了——这些信息会被存入语义记忆,所有角色都能调用,不用每次对话都重复强调,节省时间;
2. 提出复杂需求时,可明确“任务分工”——比如“让项目经理拆解任务,执行助理编写代码,质量检查员审核”,AI会快速响应,按分工高效推进,避免杂乱无章;
3. 临时闲聊、测试内容不用纠结——这些内容会被标记为“临时对话”,超时后自动清理,不会占用记忆资源,也不会影响后续任务的执行。
(二)对行业/开发者:跳出“模型内卷”,聚焦工程化落地
当前AI行业,很多人都在盲目卷模型参数、卷生成能力,却忽略了两个核心:记忆系统的工程化优化,以及拟人化分工的落地。但从Claude的体验来看,用户真正在意的,不是“AI能生成多华丽的内容”,而是“AI能不能记住我、能不能高效完成我的需求”。
Claude的源码告诉我们:AI的体验上限,不仅靠大模型,更靠“记忆架构+分工体系”的工程化设计。未来,AI Agent的核心竞争力,不会是“生成能力更强”,而是“记忆更精准、分工更高效、协同更流畅”。这也是很多开源Agent项目与顶级AI的差距所在——不是模型不够强,而是工程化落地不够精细,忽略了用户最核心的体验需求。
总结来说,这次51万行源码泄露,没有带来“破解Claude”的八卦,却给我们揭开了顶级AI的设计面纱:好的AI记忆,不是“记得多”,而是“记得准、用得巧”;好的AI交互,不是“单一应答”,而是“分工协同、高效落地”。
结尾互动
你平时用AI时,有没有遇到「AI记不住历史对话」「AI处理复杂任务杂乱无章」的问题?你印象最深的一次是怎样的?欢迎在评论区留言分享你的经历,我们一起探讨如何更高效地和AI交互~
后续我们会持续拆解AI相关热点,聚焦AI工程化设计,深入解析记忆架构、拟人化分工等核心技术,关注蜗壳数字,不错过每一个实用的AI干货!
📮 蜗壳数字工作室:聚焦AI、CAD、Excel实用干货,每周更新
关注我,一起拆解硬核技术,搞定日常问题