 夜雨聆风
夜雨聆风





Pdf转word收钱?不存在的!
起因
某次,我需要将pdf转为docx,但是我发现在WPS使用这项功能居然需要会员!
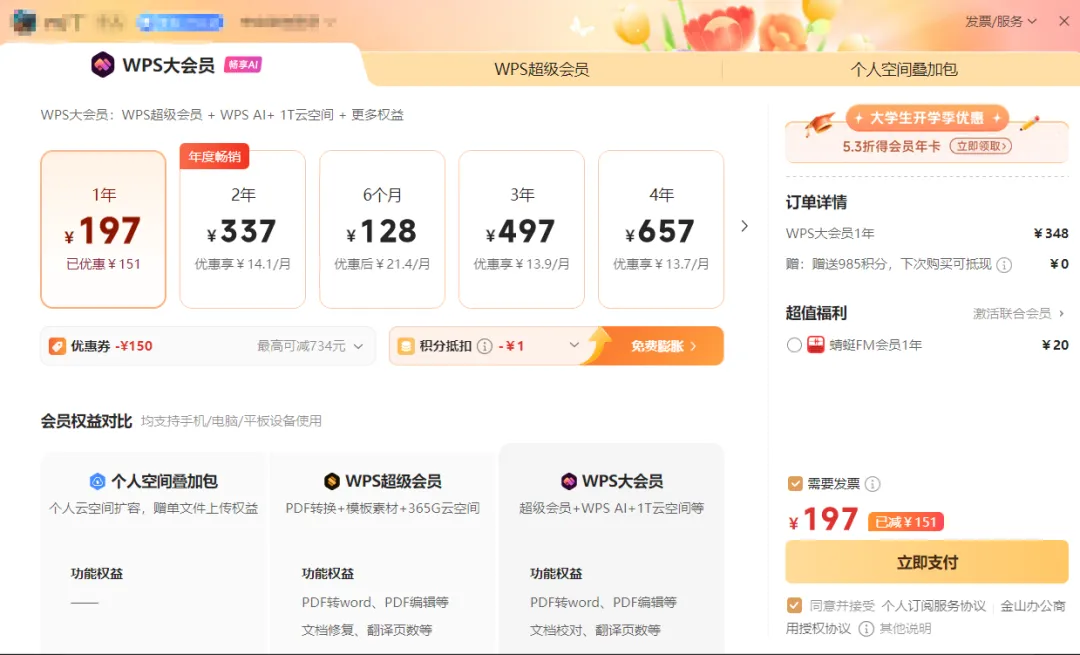
因为这点事我充值了会员,而且还是一年的!!!
某次,我需要将pdf转为docx,但是我发现在WPS使用这项功能居然需要会员!
事后,我对这件事的感觉(只不过是转个pdf而已就花了我将近200块)就像便秘了一样。然而,回想之前我用Python的情景,就想着其是否具有此功能
相关代码
后来,我发现Python居然真的有这方面的功能,就只需要下载一个相关库(pdf2docx)的功能就可以了!
安装库下载方式如下所示:
pip install pdf2docx customtkinter threading
相关代码如下所示:
from pdf2docx import Converter
pdf_file = ‘input.pdf‘
docx_file = ‘output.docx‘
#创建转换器对象并执行转换
cv = Converter(pdf_file)
cv.convert(docx_file, start=0, end=None) # start和end分别表示指定转换的开始页和结束页
cv.close()
print(“PDF转换Word成功!”)
[ 进阶 ] .
后来,我想了想这次代码有点太简单了(主要想水一水)。联想到之前做的GUI,就尝试将两者结合一下,最终的代码如下所示:
import os
import threading
import re
import tkinter.filedialog as filedialog
import customtkinter as ctk
from pdf2docx import Converter
from tkinter import messagebox
“””设置外观模式和颜色主题”””
ctk.set_appearance_mode(“System”)
ctk.set_default_color_theme(“blue”)
class PDFtoDOCXApp:
def __init__(self):
self.window = ctk.CTk()
self.window.title(“PDF 转 DOCX 工具“)
self.window.geometry(“600×400“)
self.window.resizable(True, True)
self.window._corner_radius = 20
self.input_pdf_path = ” “
self.output_docx_path = ” “
self.create_widgets()
self.center_window()
“””init方法(初始化GUI应用):创建CTk主窗口,设置标题、尺寸及不可调整大小;初始化PDF和DOCX路径变量为空;最后调用create_widgets构建界面组件,并执行center_window将窗口居中显示”””
def center_window(self):
self.window.update_idletasks() #刷新界面
x = (self.window.winfo_screenwidth() // 2) – (self.window.winfo_width() // 2)
y = (self.window.winfo_screenheight() // 2) – (self.window.winfo_height() // 2)
#计算屏幕中心与窗口中心的坐标差值确定左上角位置
self.window.geometry(f”+{x}+{y}”) #设置窗口的大小和位置
def create_widgets(self): #GUI布局
title_label = ctk.CTkLabel(self.window,text=”PDF转DOCX转换器“, font=ctk.CTkFont(size=20, weight=”bold“)) # 标题
title_label.pack(pady=15) #将组件(title_label)添加到其父容器(self.window)中,并自动调整位置(上下外边距15px)
“““输入PDF区域”””
input_frame = ctk.CTkFrame(self.window)
input_frame.pack(pady=10, padx=20, fill=”x“)
ctk.CTkLabel(input_frame, text=”输入PDF文件:“, font=ctk.CTkFont(size=14)).grid(row=0, column=0, sticky=”w“, padx=5, pady=5)
self.input_entry = ctk.CTkEntry(input_frame, placeholder_text=”未选择任何文件“, width=350) #pdf文件路径显示
self.input_entry.grid(row=0, column=1, padx=5, pady=5) #输入框位置
browse_input_btn = ctk.CTkButton(input_frame, text=”浏览…“, command=self.select_input_file, width=80) #按钮绑定select_input_file方法:导入pdf
browse_input_btn.grid(row=0, column=2, padx=5, pady=5) #按钮位置
“““输出DOCX区域”””
output_frame = ctk.CTkFrame(self.window)
output_frame.pack(pady=10, padx=20, fill=”x“)
ctk.CTkLabel(output_frame, text=”输出DOCX文件:“, font=ctk.CTkFont(size=14)).grid(row=0, column=0, sticky=”w“, padx=5, pady=5)
self.output_entry = ctk.CTkEntry(output_frame, placeholder_text=”将保存在输入文件同目录下“, width=350)
self.output_entry.grid(row=0, column=1, padx=5, pady=5) #输出框位置
browse_output_btn = ctk.CTkButton(output_frame, text=”浏览...”, command=self.select_output_path, width=80)
browse_output_btn.grid(row=0, column=2, padx=5, pady=5) #按钮位置
“““页数选择区域”””
page_frame = ctk.CTkFrame(self.window)
page_frame.pack(pady=10, padx=20, fill=”x“) #输入框位置
ctk.CTkLabel(page_frame, text=”转换页数:“, font=ctk.CTkFont(size=14)).grid(row=0, column=0, sticky=”w“, padx=5, pady=5)
self.page_entry = ctk.CTkEntry(page_frame, placeholder_text=”例如: 1-3 或 1,3,5 或留空(全部)“, width=350) #页码输入位置
self.page_entry.grid(row=0, column=1, padx=5, pady=5)
ctk.CTkLabel(page_frame, text=”(页码从1开始)“, font=ctk.CTkFont(size=12), text_color=”gray“).grid(row=1, column=1, sticky=”w“, padx=5)
“““转换按钮和状态”””
self.convert_btn = ctk.CTkButton(
self.window, text=”开始转换“, command=self.start_conversion, font=ctk.CTkFont(size=14), width=150) #转化按钮绑定start_conversion方法
self.convert_btn.pack(pady=20)
self.status_label = ctk.CTkLabel(self.window, text=” “, font=ctk.CTkFont(size=12))
#实时显示操作状态(如“正在转换…”、“转换成功”或错误信息)
self.status_label.pack(pady=5)
self.progressbar=ctk.CTkProgressBar(self.window,width=400, mode=”indeterminate“)
#以不确定模式 (indeterminate) 显示转换进度,初始状态(set(0))下被隐藏 (pack_forget),仅在转换开始时显示
self.progressbar.pack(pady=10)
self.progressbar.set(0)
self.progressbar.pack_forget()
def select_input_file(self): #文件输入方法
file_path = filedialog.askopenfilename( #提供标准的文件打开/保存对话框
title=”选择 PDF 文件“,
filetypes=[(“PDF 文件“, “*.pdf“), (“所有文件“, “*.*“)])
#filetypes=[(“PDF files”, “*.pdf”)] 确保对话框默认只显示.pdf文件,返回值file_path是用户选中文件的绝对路径;若用户点击“取消”,则返回空字符串 “”
if file_path:
self.input_pdf_path = file_path
self.input_entry.delete(0, “end“) #清空self.input_entry(即“输入PDF文件”对应的文本输入框)中的现有所有文本
self.input_entry.insert(0, file_path) #将用户选择的PDF文件完整路径(file_path)插入到输入框中
default_output = os.path.splitext(file_path)[0] + “.docx” #将路径拆分为根部分和扩展名,并把扩展名改为.docx
self.output_entry.delete(0, “end“)
self.output_entry.insert(0, default_output)
self.output_docx_path = default_output #定义输出文件路径
def select_output_path(self): #文件输出方法
if not self.input_pdf_path: #输入的pdf不存在时:
self.status_label.configure(text=”请先选择输入的PDF文件“, text_color=”orange“)
return
initial_dir = os.path.dirname(self.input_pdf_path) #提取PDF所在的文件夹路径
initial_file = os.path.basename(os.path.splitext(self.input_pdf_path)[0] + “.docx“)
file_path = filedialog.asksaveasfilename( #调用保存对话框
title=”保存 DOCX 文件“,
initialdir=initial_dir,
initialfile=initial_file,
defaultextension=”.docx“, # 设置默认扩展名为 .docx
filetypes=[(“Word 文档“, “*.docx“), (“所有文件“, “*.*“)])
if file_path:
self.output_docx_path = file_path
self.output_entry.delete(0, “end“)
self.output_entry.insert(0, file_path)
def parse_page_range(self, page_str, total_pages):
“””
将用户输入的页数字符串解析为pdf2docx所需的 pages 列表(从0开始)。
支持格式:
– “” 或 “all” -> None (全部页面)
– “1-3” -> [0,1,2]
– “1,3,5” -> [0,2,4]
– “1-3,5” -> [0,1,2,4]
如果解析失败,返回 None 并弹出错误提示”””
if not page_str or page_str.strip().lower() == “all“:
return None #如果输入为空或为 “all”(不区分大小写),直接返回 None。
pages_set = set()
parts = page_str.split(‘,‘) #字符串清洗与分割
for part in parts:
part = part.strip()
if ‘–‘ in part:
#范围: start-end
try:
start, end = part.split(‘–‘)
start = int(start.strip())
end = int(end.strip())
if start < 1 or end < 1:
raise ValueError
if start > end:
start, end = end, start
#检查是否超出总页数(如果 total_pages 已知)
for p in range(start, end + 1):
if total_pages is not None and p > total_pages:
messagebox.showerror(“错误“, f”页码 {p} 超出文档总页数 {total_pages}”)
return None
pages_set.add(p – 1) # 转为0索引
except Exception:
messagebox.showerror(“错误“, f”页码范围格式错误: {part},应为 起始-结束,例如 1-3“)
return None
else:#单页
try:
p = int(part)
if p < 1:
raise ValueError
if total_pages is not None and p > total_pages:
messagebox.showerror(“错误“, f”页码 {p} 超出文档总页数 {total_pages}”)
return None
pages_set.add(p – 1)
except Exception:
messagebox.showerror(“错误“, f”页码格式错误: {part},应为正整数“)
return None
return sorted(pages_set) if pages_set else None
def start_conversion(self):
#检查输入输出路径
if not self.input_pdf_path:
self.status_label.configure(text=”请先选择输入的PDF文件“, text_color=”red“)
return
if not self.output_docx_path:
self.output_docx_path = os.path.splitext(self.input_pdf_path)[0] + “.docx“
self.output_entry.delete(0, “end“)
self.output_entry.insert(0, self.output_docx_path) #如果用户没有指定输出的 DOCX 文件名,代码会自动提取PDF的文件名(不含扩展名),并拼接.docx后缀,生成默认的输出路径
#获取总页数(用于验证)
try:
from PyPDF2 import PdfReader
reader = PdfReader(self.input_pdf_path)
total_pages = len(reader.pages)
except Exception:
#如果无法获取总页数,跳过页数上限检查
total_pages = None
page_str = self.page_entry.get().strip()
pages = self.parse_page_range(page_str, total_pages)
if page_str and pages is None:
#parse_page_range 已经弹出错误提示
return
#保存 pages 参数供转换线程使用
self.pages_to_convert = pages
self.convert_btn.configure(state=”disabled“, text=”转换中…“) #转换时的按钮状态
self.status_label.configure(text=”正在转换,请稍候…“, text_color=”blue”) #转换状态
self.progressbar.pack(pady=10)
self.progressbar.start() #启动进度条
thread = threading.Thread(target=self.convert_pdf_to_docx, daemon=True) #创建一个后台线程,用于执行耗时的PDF到DOCX的转换任务,从而避免阻塞主界面(UI),其中daemon当主程序(主线程)退出时(例如用户关闭窗口),所有守护线程会被强制立即终止
thread.start() #启动线程
def convert_pdf_to_docx(self):
try:
cv = Converter(self.input_pdf_path)
#使用 pages 参数(如果为None则转换全部页面)
cv.convert(self.output_docx_path, pages=self.pages_to_convert)
cv.close()
self.window.after(0, self.conversion_success)
except Exception as e:
self.window.after(0, self.conversion_failed, str(e))
def conversion_success(self): #转换成功后
self.progressbar.stop() #终止进度条
self.progressbar.pack_forget() #隐藏状态栏
self.convert_btn.configure(state=”normal“, text=”开始转换“) #按钮状态更新
self.status_label.configure(text=f”转换成功!文件保存在:{self.output_docx_path}”, text_color=”green“) #状态栏更新
def conversion_failed(self, error_msg):
self.progressbar.stop()
self.progressbar.pack_forget()
self.convert_btn.configure(state=”normal“, text=”开始转换“)
self.status_label.configure(text=f”转换失败:{error_msg}”, text_color=”red“)
def run(self):
self.window.mainloop() #启动Tk主循环
if __name__ == “__main__”:
app = PDFtoDOCXApp()
app.run()
生成的GUI如下所示:
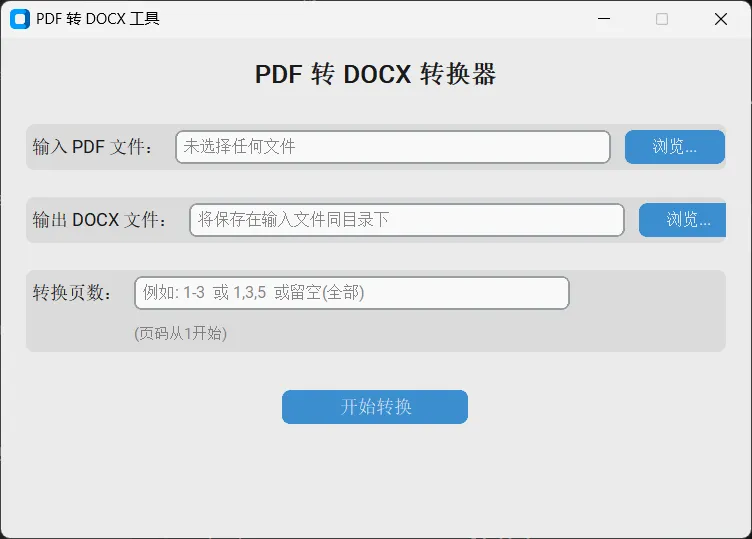
生成效果对比:


额,虽然效果有一点点不满意(毕竟文献的格式有点复杂),但进行一定的排版还是可以接受的,如果各位有什么更好的方法,可以和我私聊!
