 夜雨聆风
夜雨聆风





文档处理实战:Loader 加载 + Splitter 分割,知识库入库第一步
大家好,我是James。
上一篇我们把 RAG 的理论基础讲透了——LLM 三大硬伤、两阶段流程、向量搜索原理。今天正式进入 RAG 工程的第一步:文档处理。
你以为做 RAG 最难的是向量检索、Prompt 工程?错。80% 的 RAG 项目效果差,根源在最前面一步——文档没加载对,或者切分得一塌糊涂。Garbage In, Garbage Out,入口数据质量直接决定后面所有环节的上限。
01 文档处理在 RAG 中的位置
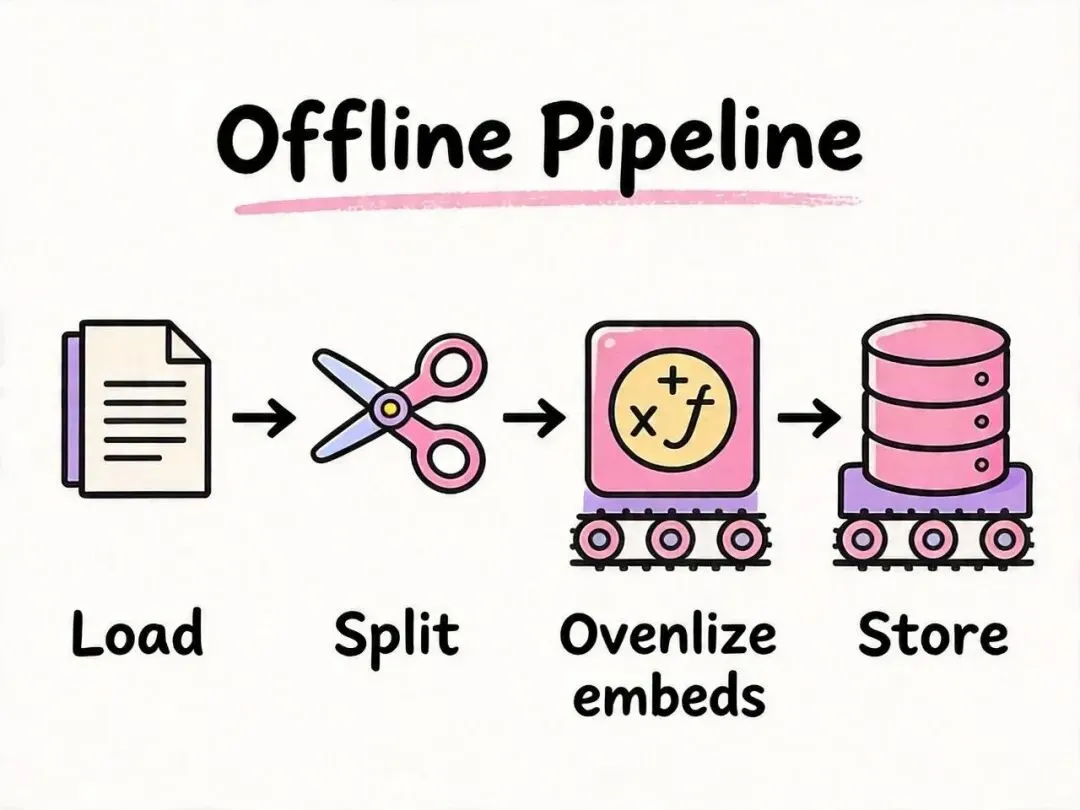
先看全景图,明确我们今天要做什么:
RAG 离线流水线(知识库构建)
┌─────────┐ ┌─────────┐ ┌──────────┐ ┌──────────┐
│ 原始文档 │──▶│ Loader │──▶│ Splitter │──▶│ Embedder │
│ PDF/TXT │ │ 加载文档 │ │ 切分文本 │ │ 向量化 │
│ CSV/JSON │ │ → Document│ │ → Chunks │ │ → Vector │
│ Web/... │ └─────────┘ └──────────┘ └──────────┘
│
▼
┌──────────┐
│ Vector DB│
│ 向量数据库 │
└──────────┘
今天的重点 ──────────────▶ Loader + Splitter
Loader 和 Splitter 是离线流水线的入口,决定了知识库的数据质量。 Loader 负责把各种格式的原始文件统一成 LangChain 的 Document 对象;Splitter 负责把长文档按策略切成合适大小的 chunks。
一个类比:Loader 像工厂的原材料进货部门,把不同包装的原料拆包统一放到流水线上;Splitter 像裁切工,把大块原料按规格切成标准件——后面的加工(向量化、检索)才能高效进行。
02 Document 对象:LangChain 的数据标准格式
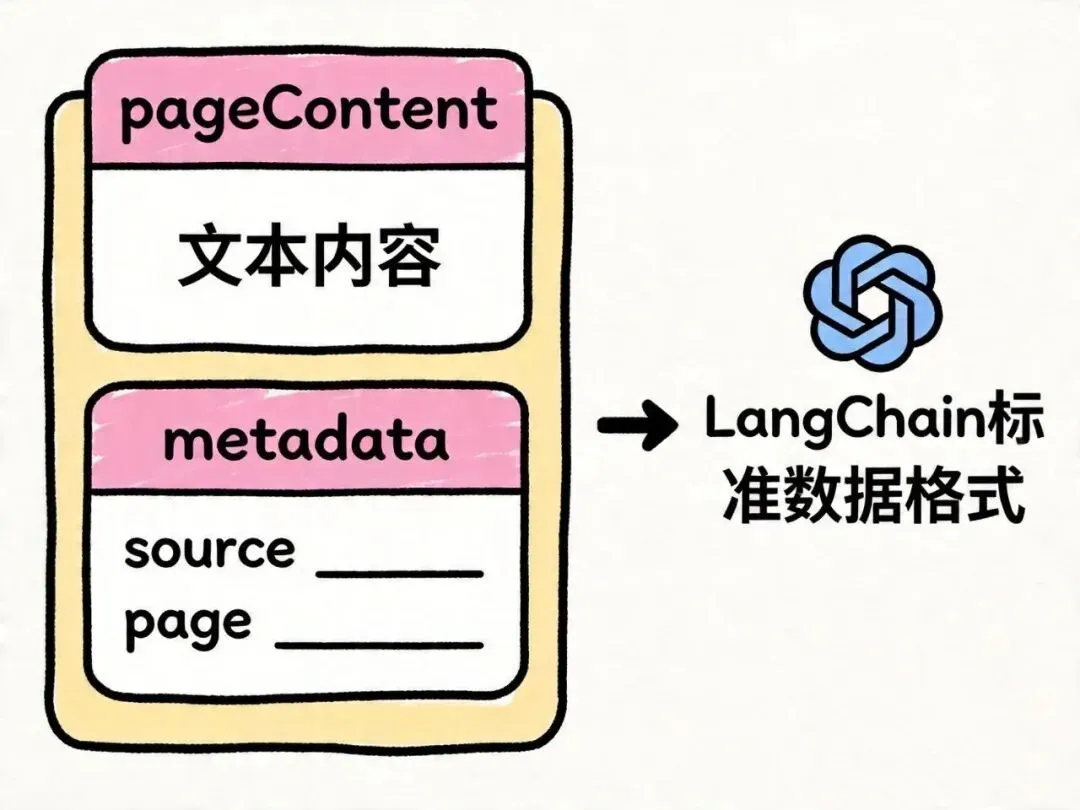
在写代码之前,先搞清 LangChain 的核心数据结构。
LangChain 中所有文档数据都统一为 Document 对象,包含两个字段:pageContent(文本内容)和 metadata(元数据)。
import { Document } from "@langchain/core/documents";
// Document 的结构很简单
const doc = new Document({
pageContent: "这是文档的文本内容,Loader 加载后就是这个字段",
metadata: {
source: "report.pdf", // 来源文件
page: 3, // 页码
author: "James", // 自定义元数据
createdAt: "2025-01-15", // 创建时间
},
});
console.log(doc.pageContent); // 文本内容
console.log(doc.metadata); // 元数据字典
这个结构贯穿整个 RAG 流程——Loader 输出 Document[],Splitter 输入 Document[] 输出 Document[],Embedder 从 pageContent 提取向量,检索时 metadata 用于过滤和溯源。
Document 对象在 RAG 中的流转
Loader 输出 Splitter 输出 存入向量数据库
┌─────────────┐ ┌─────────────┐ ┌──────────────────┐
│ pageContent: │ │ pageContent: │ │ pageContent → 向量│
│ "完整文档..." │ ──▶ │ "chunk片段" │ ──▶ │ metadata → 过滤 │
│ metadata: │ │ metadata: │ │ id → 唯一标识 │
│ {source:...} │ │ {source:..., │ └──────────────────┘
└─────────────┘ │ chunk: 0} │
└─────────────┘
✅ 好的做法:从一开始就维护好 metadata,后续检索时可以按来源、页码过滤
❌ 坏的做法:只关心 pageContent,忽略 metadata——检索到内容后无法追溯来源
03 Document Loader:加载各种格式的文档
LangChain.js 提供了大量 Loader,覆盖主流文件格式。核心思路是:不同格式的文件 → 统一的 Document[] 输出。
3.1 加载纯文本文件
最简单的场景,TextLoader 直接读文件:
import { TextLoader } from "langchain/document_loaders/fs/text";
const loader = new TextLoader("./data/readme.txt");
const docs = await loader.load();
console.log(docs.length); // 1(整个文件作为一个 Document)
console.log(docs[0].pageContent); // 文件全部内容
console.log(docs[0].metadata.source); // "./data/readme.txt"
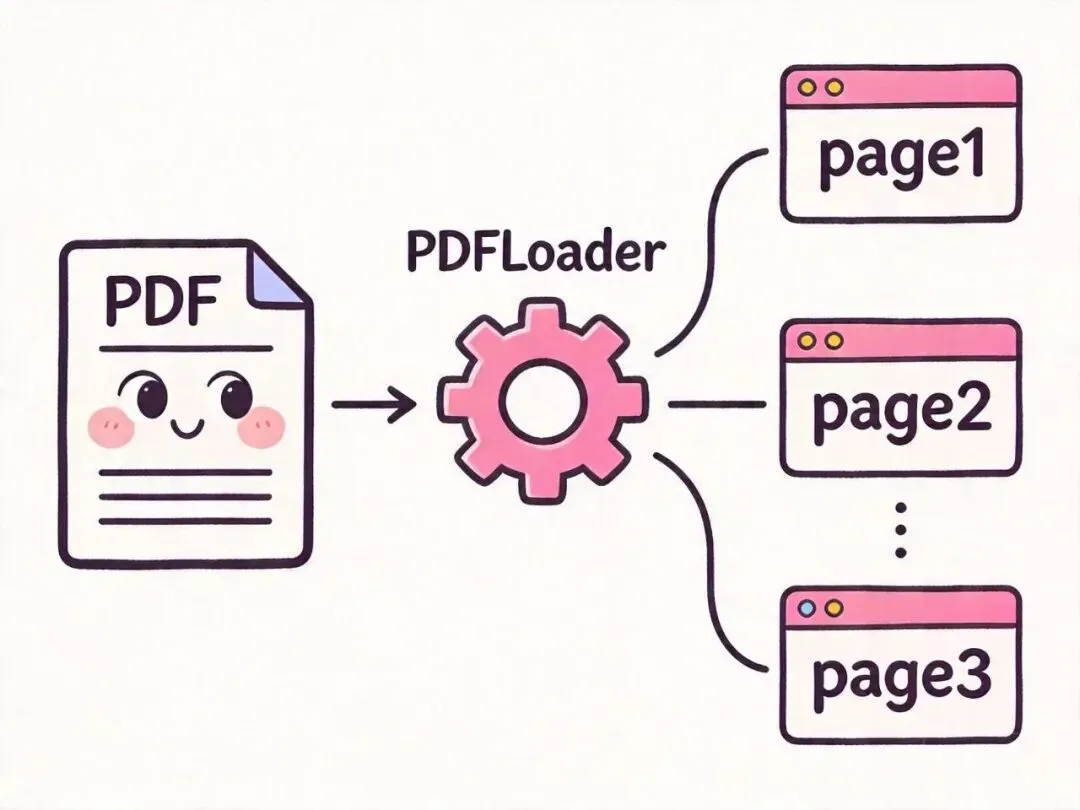
3.2 加载 PDF 文件
PDF 是知识库最常见的格式,用 PDFLoader:
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
// 默认按页分割,每页一个 Document
const loader = new PDFLoader("./data/ai-report.pdf");
const docs = await loader.load();
console.log(docs.length); // 文档页数
console.log(docs[0].metadata);
// { source: "./data/ai-report.pdf", pdf: { ... }, loc: { pageNumber: 1 } }
// 也可以合并为一个 Document
const loaderMerged = new PDFLoader("./data/ai-report.pdf", {
splitPages: false, // 不按页拆分,整个 PDF 合为一个 Document
});
const mergedDocs = await loaderMerged.load();
console.log(mergedDocs.length); // 1
✅ 按页分割(splitPages: true,默认):保留页码信息,方便溯源定位
❌ 整篇合并(splitPages: false):丢失页码信息,后续检索到内容不知道在哪一页
3.3 加载 CSV 文件
CSV 每行是一条记录,用 CSVLoader:
import { CSVLoader } from "@langchain/community/document_loaders/fs/csv";
// 每行数据 → 一个 Document
const loader = new CSVLoader("./data/products.csv");
const docs = await loader.load();
console.log(docs[0].pageContent);
// "name: iPhone 15\nprice: 7999\ncategory: 手机"
console.log(docs[0].metadata);
// { source: "./data/products.csv", line: 1 }
// 指定某列作为 pageContent
const loaderWithColumn = new CSVLoader("./data/products.csv", {
column: "description", // 只用 description 列作为文本内容
});
3.4 加载 JSON 文件
JSON 结构灵活,JSONLoader 支持用 JSON Pointer 提取特定字段:
import { JSONLoader } from "langchain/document_loaders/fs/json";
// 默认:提取所有字符串值
const loader = new JSONLoader("./data/faq.json");
const docs = await loader.load();
// 指定 JSON Pointer,只提取特定路径的内容
// 假设 JSON 结构: [{ "question": "...", "answer": "..." }, ...]
const loaderWithPointer = new JSONLoader(
"./data/faq.json",
"/answer" // 只提取每个对象的 answer 字段
);
const answerDocs = await loaderWithPointer.load();
console.log(answerDocs[0].pageContent); // 第一个 FAQ 的答案内容
3.5 加载 Web 页面
爬取网页内容,CheerioWebBaseLoader 最轻量:
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
const loader = new CheerioWebBaseLoader(
"https://docs.langchain.com/docs/get_started/introduction"
);
const docs = await loader.load();
console.log(docs[0].pageContent.substring(0, 200)); // 网页文本内容
console.log(docs[0].metadata.source); // URL
3.6 批量加载目录
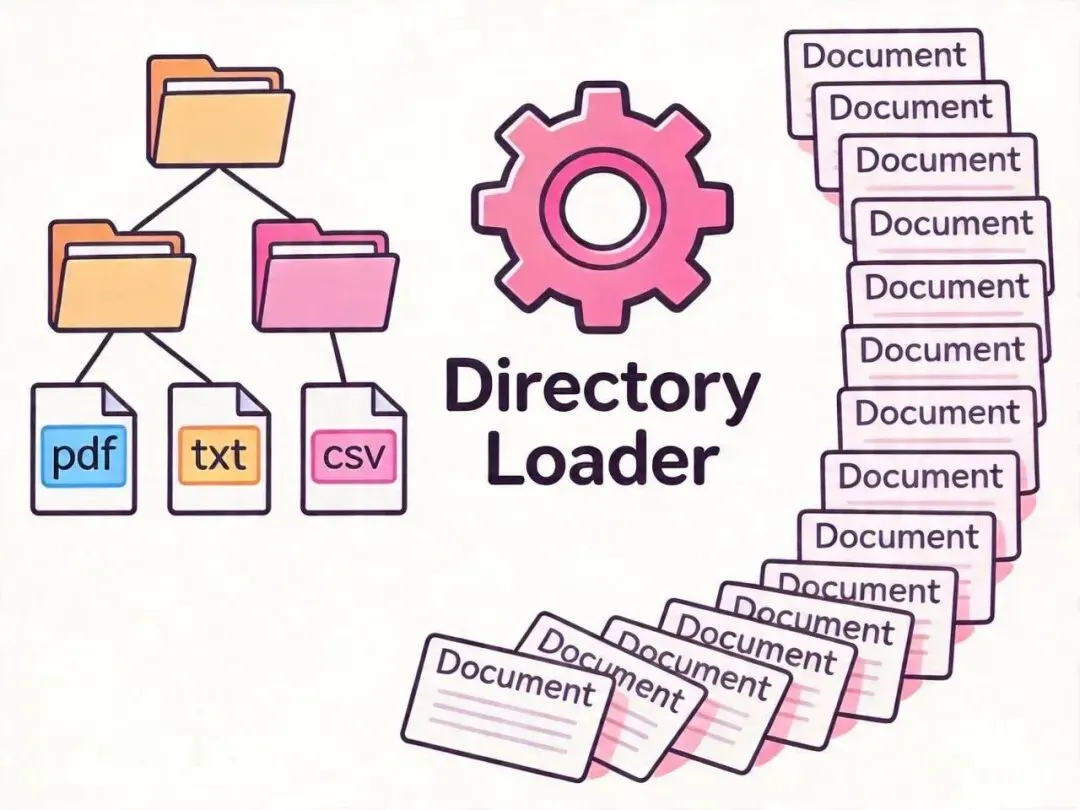
真实场景不可能只加载一个文件,DirectoryLoader 批量加载整个目录:
import { DirectoryLoader } from "langchain/document_loaders/fs/directory";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { CSVLoader } from "@langchain/community/document_loaders/fs/csv";
const loader = new DirectoryLoader("./data/knowledge-base", {
".txt": (path) => new TextLoader(path),
".pdf": (path) => new PDFLoader(path),
".csv": (path) => new CSVLoader(path),
// 按扩展名映射不同的 Loader
});
const allDocs = await loader.load();
console.log(`总共加载了 ${allDocs.length} 个 Document`);
// 按来源分组统计
const sourceCount = allDocs.reduce((acc, doc) => {
const ext = doc.metadata.source.split(".").pop();
acc[ext] = (acc[ext] || 0) + 1;
return acc;
}, {} as Record<string, number>);
console.log(sourceCount); // { txt: 12, pdf: 45, csv: 8 }
✅ 用 DirectoryLoader 按扩展名映射 Loader,一次加载整个知识库目录
❌ 手动遍历文件一个个加载,代码冗余且容易漏掉格式
04 Text Splitter:为什么要切分文档
Loader 加载完成后,文档往往很长——一个 PDF 可能几万字,一个技术文档几十页。直接把整个文档向量化有三个致命问题:
为什么必须切分文档
问题一:向量质量差
┌──────────────────────────────────────────────┐
│ 一篇 10000 字的文档 → 一个向量 │
│ 这个向量是整篇文档的"平均语义" │
│ 用户搜一个具体问题,匹配度很低 │
└──────────────────────────────────────────────┘
问题二:Context 浪费
┌──────────────────────────────────────────────┐
│ 检索到整篇文档,塞进 Prompt │
│ 10000 字里只有 200 字和问题相关 │
│ 剩下 9800 字浪费 token,稀释有效信息 │
└──────────────────────────────────────────────┘
问题三:超过模型限制
┌──────────────────────────────────────────────┐
│ 模型 context window 有上限(如 128K tokens) │
│ 单个文档就可能超限 │
│ 多个检索结果更放不下 │
└──────────────────────────────────────────────┘
所以切分的目标是:把长文档按语义切成适当大小的 chunk,每个 chunk 语义相对独立完整,检索时能精确匹配用户问题。
05 RecursiveCharacterTextSplitter:最常用的分割器
RecursiveCharacterTextSplitter 是 LangChain 推荐的默认分割器,90% 的场景用它就够了。
核心原理:按一组分隔符递归地尝试分割文本。先尝试用 \n\n(段落),切不动或切完还太长就用 \n(换行),再不行用 (空格),最后才按单个字符硬切。
RecursiveCharacterTextSplitter 分割逻辑
输入文本
│
▼
尝试按 "\n\n"(段落)分割
│
├── chunk ≤ chunkSize?✅ 保留
│
└── chunk > chunkSize?继续 ↓
│
▼
尝试按 "\n"(换行)分割
│
├── chunk ≤ chunkSize?✅ 保留
│
└── chunk > chunkSize?继续 ↓
│
▼
尝试按 " "(空格)分割
│
├── chunk ≤ chunkSize?✅ 保留
│
└── chunk > chunkSize?继续 ↓
│
▼
按单个字符硬切
代码示例:
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500, // 每个 chunk 最大 500 个字符
chunkOverlap: 50, // 相邻 chunk 重叠 50 个字符
separators: ["\n\n", "\n", " ", ""], // 默认分隔符列表
});
const text = `第一章 产品概述
本产品是一款基于大语言模型的智能客服系统,支持多轮对话、知识库检索、工单自动创建等功能。
第二章 核心功能
2.1 多轮对话
系统支持上下文感知的多轮对话,能够记住用户在当前会话中提出的历史问题,自动关联上下文进行回答。
2.2 知识库检索
基于 RAG 架构,系统会自动从企业知识库中检索相关文档片段,结合大模型生成准确回答。支持 PDF、Word、网页等多种文档格式。`;
const chunks = await splitter.createDocuments([text]);
chunks.forEach((chunk, i) => {
console.log(`\n--- Chunk ${i} (${chunk.pageContent.length} chars) ---`);
console.log(chunk.pageContent);
});
两个关键参数:
-
chunkSize:每个 chunk 的最大字符数。不是严格等于这个数,而是”不超过” -
chunkOverlap:相邻 chunk 之间的重叠字符数。保证语义不被硬切断
chunkOverlap 的作用
chunkOverlap = 0(无重叠)
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Chunk 0 │ │ Chunk 1 │ │ Chunk 2 │
└──────────┘ └──────────┘ └──────────┘
↑ 这里可能刚好切断一句话
chunkOverlap = 50(有重叠)
┌──────────────┐
│ Chunk 0 │
└────────┬─────┘
│ 重叠 │
┌────┴─────────┐
│ Chunk 1 │
└────────┬─────┘
│ 重叠 │
┌────┴─────────┐
│ Chunk 2 │
└──────────────┘
重叠区域保证上下文连续性
✅ 使用 RecursiveCharacterTextSplitter:按语义层级递归分割,尽量保留完整段落和句子
❌ 简单按固定字符数硬切:可能切在词语中间、句子中间,导致语义破碎
06 其他分割器:CharacterTextSplitter 与 TokenTextSplitter
CharacterTextSplitter
只按单一分隔符切割,不递归。 适合格式非常规律的文本(如日志、CSV 转文本):
import { CharacterTextSplitter } from "@langchain/textsplitters";
const splitter = new CharacterTextSplitter({
separator: "\n\n", // 只按段落分割,不递归
chunkSize: 500,
chunkOverlap: 0,
});
const text = "段落一内容...\n\n段落二内容...\n\n段落三内容...";
const chunks = await splitter.createDocuments([text]);
// 如果某段落超过 500 字符,不会继续往下拆,直接保留(这是它和 Recursive 的区别)
TokenTextSplitter
按 token 数而非字符数切割。 当你需要精确控制 token 消耗时使用:
import { TokenTextSplitter } from "@langchain/textsplitters";
const splitter = new TokenTextSplitter({
chunkSize: 200, // 每个 chunk 最大 200 tokens
chunkOverlap: 20, // 重叠 20 tokens
encodingName: "cl100k_base", // OpenAI 的 tokenizer
});
const docs = await splitter.createDocuments([longText]);
// 每个 chunk 严格不超过 200 tokens
// 适合需要精确控制 LLM 输入 token 数的场景
三种 Splitter 对比:
┌────────────────────┬───────────────┬────────────────┬─────────────┐
│ Splitter │ 分割策略 │ 适用场景 │ 推荐度 │
├────────────────────┼───────────────┼────────────────┼─────────────┤
│ Recursive │ 多级分隔符递归 │ 通用文档 │ ⭐⭐⭐⭐⭐ │
│ Character │ 单一分隔符 │ 规律文本/日志 │ ⭐⭐⭐ │
│ Token │ Token 计数 │ 精确控制token │ ⭐⭐⭐⭐ │
└────────────────────┴───────────────┴────────────────┴─────────────┘
✅ 默认选 RecursiveCharacterTextSplitter,除非有明确理由用其他
❌ 无脑用 CharacterTextSplitter——遇到没有规律分隔符的文本,切出来的 chunk 质量很差
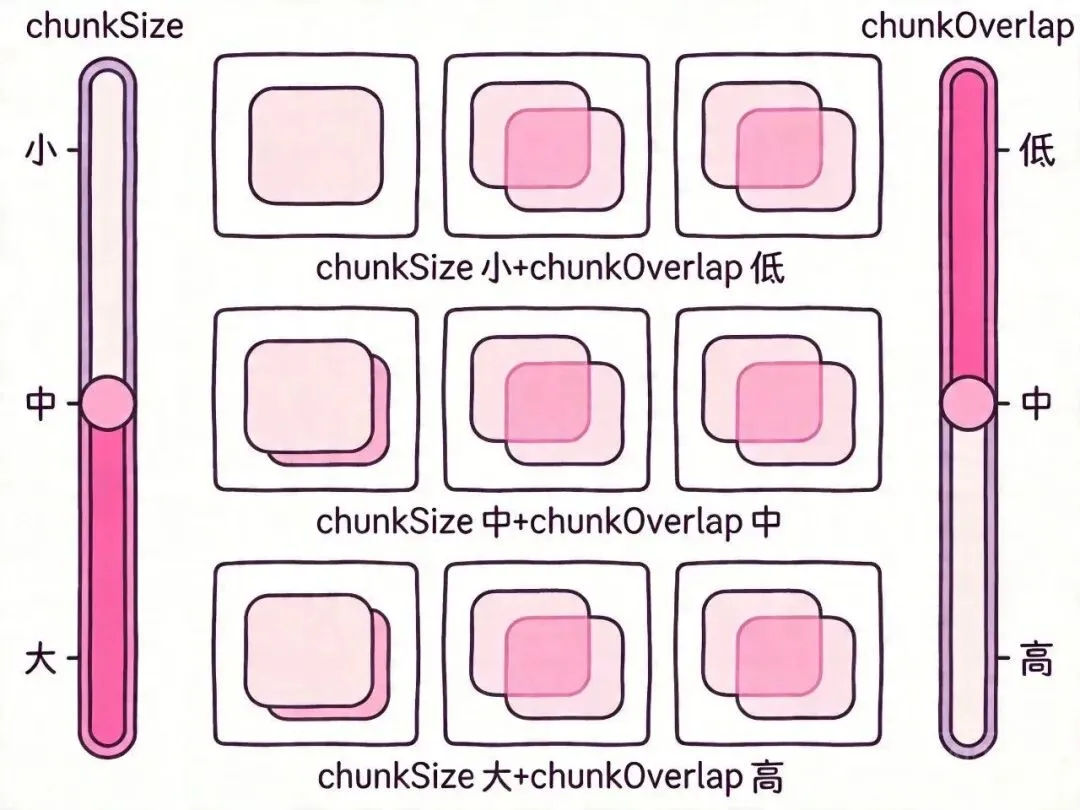
07 分割参数调优:chunkSize 和 chunkOverlap 怎么选
参数选择没有银弹,取决于文档类型、Embedding 模型、检索需求。 但有一些经验法则:
chunkSize 选择策略
chunkSize 太小 vs 太大
太小(< 200 字符)
┌────────────────────────────────────────────────┐
│ "系统支持多轮对话" │
│ │
│ 问题:语义不完整,缺乏上下文 │
│ 检索到也没法用,LLM 无法基于这一句话回答 │
└────────────────────────────────────────────────┘
太大(> 2000 字符)
┌────────────────────────────────────────────────┐
│ "第一章 产品概述... 第二章 功能... 第三章 架构..." │
│ │
│ 问题:包含多个主题,向量是"平均语义" │
│ 检索精度低,塞进 Prompt 浪费 token │
└────────────────────────────────────────────────┘
合适的大小(500-1000 字符)
┌────────────────────────────────────────────────┐
│ "2.2 知识库检索 │
│ 基于 RAG 架构,系统会自动从企业知识库中 │
│ 检索相关文档片段,结合大模型生成准确回答。 │
│ 支持 PDF、Word、网页等多种文档格式。" │
│ │
│ 语义完整,主题集中,长度适中 ✅ │
└────────────────────────────────────────────────┘
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
// 不同场景的参数配置
// 场景一:技术文档 / 产品手册
const techDocSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 800, // 技术文档段落较长,给大一些
chunkOverlap: 100, // 重叠保留上下文
});
// 场景二:FAQ / QA 对
const faqSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 300, // FAQ 本身就短,切小一些
chunkOverlap: 30,
});
// 场景三:法律合同 / 长篇报告
const legalSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000, // 法律文本需要更多上下文
chunkOverlap: 200, // 大重叠防止条款被切断
});
chunkOverlap 经验值
一般设为 chunkSize 的 10%-20%。 太小会丢失上下文连续性,太大会导致大量重复内容浪费存储和计算。
chunkSize 与 chunkOverlap 推荐配置
┌─────────────┬────────────┬───────────────┬──────────────────┐
│ 文档类型 │ chunkSize │ chunkOverlap │ 说明 │
├─────────────┼────────────┼───────────────┼──────────────────┤
│ FAQ / 短文本 │ 200-400 │ 20-50 │ 内容短,小chunk │
│ 技术文档 │ 500-1000 │ 50-100 │ 平衡精度和完整度 │
│ 法律/学术 │ 800-1500 │ 100-200 │ 需要完整上下文 │
│ 代码 │ 500-800 │ 50-100 │ 按函数/类切分更好 │
└─────────────┴────────────┴───────────────┴──────────────────┘
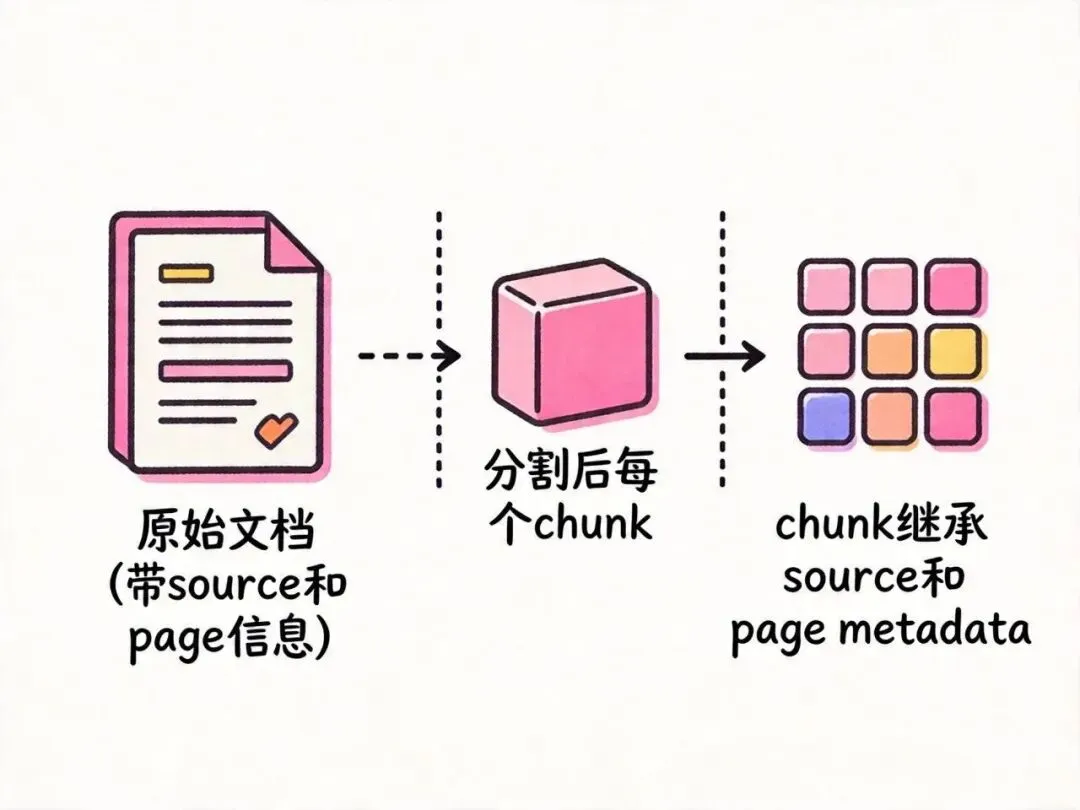
08 元数据保留:分割后别丢了来源信息
Splitter 分割后,每个 chunk 会自动继承原 Document 的 metadata,并追加 chunk 定位信息。 这一点非常关键——没有 metadata,检索到内容后无法告诉用户”这个答案来自哪个文件的第几页”。
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
// 1. 加载 PDF
const loader = new PDFLoader("./data/product-manual.pdf");
const docs = await loader.load();
// 2. 分割
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
const chunks = await splitter.splitDocuments(docs);
// 3. 查看 metadata 继承情况
console.log(chunks[0].metadata);
// {
// source: "./data/product-manual.pdf",
// pdf: { ... },
// loc: { pageNumber: 1, lines: { from: 0, to: 15 } }
// }
// metadata 自动从原 Document 继承过来了!
// 后续检索时可以用 metadata 做过滤和溯源
你还可以在加载后手动添加自定义 metadata:
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
const loader = new PDFLoader("./data/product-manual.pdf");
const docs = await loader.load();
// 手动给每个 Document 添加自定义 metadata
const enrichedDocs = docs.map((doc) => ({
...doc,
metadata: {
...doc.metadata,
department: "产品部", // 所属部门
docType: "产品手册", // 文档类型
version: "v2.1", // 版本号
indexedAt: new Date().toISOString(), // 入库时间
},
}));
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
// splitDocuments 会保留所有 metadata
const chunks = await splitter.splitDocuments(enrichedDocs);
console.log(chunks[0].metadata);
// { source: "...", department: "产品部", docType: "产品手册", version: "v2.1", ... }
✅ 在 Loader 之后、Splitter 之前添加自定义 metadata,分割后自动继承
❌ 在 Splitter 之后再给 chunks 加 metadata——容易漏加,且无法利用原始 Document 的信息
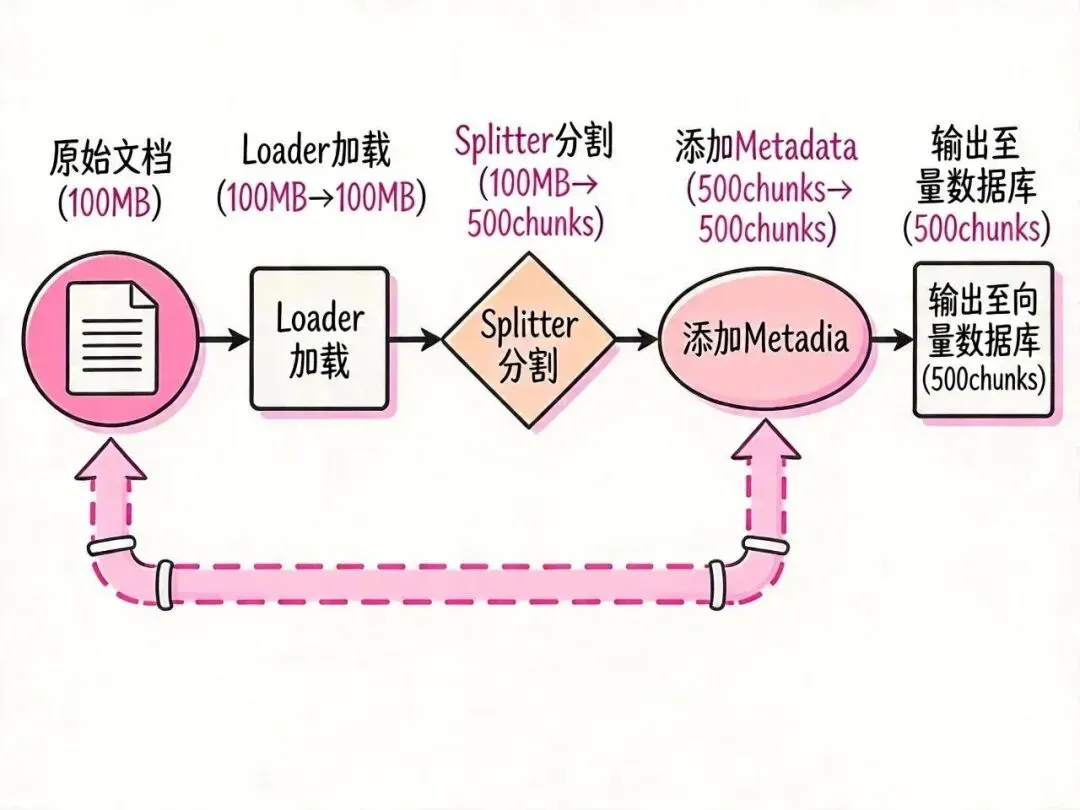
09 实战:从 PDF 加载到 Chunks 的完整流程
把前面所有知识串起来,写一个完整的文档处理流水线:
import { PDFLoader } from "@langchain/community/document_loaders/fs/pdf";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { DirectoryLoader } from "langchain/document_loaders/fs/directory";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { Document } from "@langchain/core/documents";
// ===== Step 1: 加载文档 =====
const loader = new DirectoryLoader("./knowledge-base", {
".pdf": (path) => new PDFLoader(path),
".txt": (path) => new TextLoader(path),
});
const rawDocs = await loader.load();
console.log(`✅ 加载完成:${rawDocs.length} 个 Document`);
// ===== Step 2: 清洗 & 丰富 metadata =====
const cleanedDocs = rawDocs
.filter((doc) => doc.pageContent.trim().length > 50) // 过滤空白/过短文档
.map((doc) => new Document({
pageContent: doc.pageContent
.replace(/\s+/g, " ") // 合并多余空白
.replace(/\n{3,}/g, "\n\n") // 合并多余空行
.trim(),
metadata: {
...doc.metadata,
processedAt: new Date().toISOString(),
charCount: doc.pageContent.length,
},
}));
console.log(`✅ 清洗完成:${cleanedDocs.length} 个有效 Document`);
// ===== Step 3: 分割 =====
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 800,
chunkOverlap: 100,
});
const chunks = await splitter.splitDocuments(cleanedDocs);
console.log(`✅ 分割完成:${chunks.length} 个 Chunks`);
// ===== Step 4: 统计 & 质检 =====
const stats = {
totalChunks: chunks.length,
avgChunkSize: Math.round(
chunks.reduce((sum, c) => sum + c.pageContent.length, 0) / chunks.length
),
minChunkSize: Math.min(...chunks.map((c) => c.pageContent.length)),
maxChunkSize: Math.max(...chunks.map((c) => c.pageContent.length)),
sources: [...new Set(chunks.map((c) => c.metadata.source))],
};
console.log("📊 分割统计:", stats);
// {
// totalChunks: 156,
// avgChunkSize: 623,
// minChunkSize: 89,
// maxChunkSize: 800,
// sources: ["./knowledge-base/manual.pdf", "./knowledge-base/faq.txt", ...]
// }
完整流程图
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ knowledge- │ │ rawDocs │ │ cleanedDocs │
│ base/ │────▶│ (加载原始) │────▶│ (清洗过滤) │
│ ├── *.pdf │ │ 48 docs │ │ 42 docs │
│ └── *.txt │ └──────────────┘ └──────┬───────┘
└──────────────┘ │
▼
┌──────────────┐ ┌──────────────┐
│ chunks │◀────│ Splitter │
│ 156 个 │ │ chunkSize: │
│ avg 623字 │ │ 800 │
└──────┬───────┘ └──────────────┘
│
▼
下一步:Embedding + 存入向量数据库
10 中文文档的特殊处理
中文分割是最容易踩坑的地方。 英文有天然的空格和标点分隔,中文没有——默认的 RecursiveCharacterTextSplitter 用 ["\n\n", "\n", " ", ""] 分隔符,对中文不够友好。
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
// 针对中文优化的分隔符
const chineseSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
separators: [
"\n\n", // 段落
"\n", // 换行
"。", // 中文句号
"!", // 中文感叹号
"?", // 中文问号
";", // 中文分号
",", // 中文逗号(最后才用)
" ", // 空格
"", // 兜底:按字符切
],
});
const chineseText = `人工智能正在深刻改变各行各业。在医疗领域,AI辅助诊断系统已经能够识别X光片中的异常,准确率超过资深医生。在金融领域,智能风控系统每天处理数百万笔交易,实时识别欺诈行为。
然而,AI技术的发展也带来了新的挑战。数据隐私保护、算法偏见、就业替代等问题,都需要社会各界共同面对和解决。`;
const chunks = await chineseSplitter.createDocuments([chineseText]);
chunks.forEach((chunk, i) => {
console.log(`\n--- Chunk ${i} ---`);
console.log(chunk.pageContent);
});
✅ 为中文文档定制分隔符列表,优先在句号、问号等自然断句处切割
❌ 使用默认英文分隔符处理中文——可能在词语中间硬切,导致语义断裂

11 常见坑:踩过才知道
坑一:PDF 加载出来全是乱码或空白
不同 PDF 生成工具(扫描版、加密、图片型)的解析结果差异巨大。扫描版 PDF 需要先 OCR 再加载。PDFLoader 底层用的是 pdf-parse,只能处理文字型 PDF。遇到扫描版,要先用 OCR 工具转成文字,或者换用支持 OCR 的 Loader。
坑二:chunkSize 设成 token 数但实际按字符切
RecursiveCharacterTextSplitter 的 chunkSize 单位是字符,不是 token。中文一个字 = 一个字符 ≈ 1-2 个 token。如果你需要精确控制 token 数,用 TokenTextSplitter,或者给 RecursiveCharacterTextSplitter 配置 lengthFunction:
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { encoding_for_model } from "tiktoken";
const enc = encoding_for_model("gpt-4o");
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500, // 这里就是 500 tokens 了
chunkOverlap: 50,
lengthFunction: (text: string) => enc.encode(text).length, // 用 token 计数
});
坑三:Overlap 设为 0,检索时总是缺上下文
chunkOverlap = 0 意味着相邻 chunk 之间完全不重叠。如果一句话刚好被切成两半,分别在两个 chunk 里,任何一个 chunk 的语义都不完整,检索时两边都匹配不上。永远给一个合理的 overlap,至少 chunkSize 的 10%。
坑四:metadata 在自定义处理流程中被丢弃
很多人会在 Loader 之后做一些文本清洗(去特殊字符、格式化),操作时直接用 new Document({ pageContent: cleanedText }),忘了把原始的 metadata 带过去。一旦丢失 metadata,后续检索完全无法溯源。
坑五:目录下混入大文件,内存爆炸
DirectoryLoader 会递归加载目录下所有匹配文件。如果目录里混入了一个 500MB 的 PDF,Node.js 进程直接 OOM。加载前先检查文件大小,设置上限过滤。
import * as fs from "fs";
import * as path from "path";
// 过滤超大文件
const MAX_FILE_SIZE = 50 * 1024 * 1024; // 50MB
const files = fs.readdirSync("./knowledge-base");
const safeFiles = files.filter((f) => {
const filePath = path.join("./knowledge-base", f);
const stats = fs.statSync(filePath);
if (stats.size > MAX_FILE_SIZE) {
console.warn(`⚠️ 跳过大文件:${f} (${(stats.size / 1024 / 1024).toFixed(1)}MB)`);
return false;
}
return true;
});
总结
这篇我们完成了 RAG 流水线的第一步——文档加载与分割,核心要点:
-
Document 是 LangChain 的数据标准格式: pageContent存文本,metadata存元信息,贯穿 RAG 全流程 -
Loader 统一了数据入口:PDF、TXT、CSV、JSON、Web 页面,不同格式统一输出 Document[],DirectoryLoader批量加载整个目录 -
必须切分才能高效检索:长文档直接向量化语义模糊、浪费 token、可能超限——切成 500-1000 字符的 chunk 是基本操作 -
RecursiveCharacterTextSplitter 是首选:多级分隔符递归分割,语义保留最好,90% 场景的默认选择 -
参数调优靠场景:chunkSize 500-1000 起步,chunkOverlap 设 10%-20%,不同文档类型配置不同参数 -
中文要定制分隔符:加入句号、问号等中文标点,避免在词语中间硬切
下一篇我们深入 LangChain Splitter 全解析——Markdown Splitter、Code Splitter 等高级分割策略,以及如何根据文档结构做语义分块,让你的 RAG 检索精度再上一个台阶。
关注我,James 的成长日记,持续分享干货,帮你在 AI 时代少走弯路。