 夜雨聆风
夜雨聆风





你的AI助手为何"记得住却想不起"?HiMem用"事件-知识"双脑架构破解人类记忆密码
现有AI记忆系统有个致命盲区:它们把”记住”和”回忆”混为一谈。Mem0们擅长把对话压缩成事实碎片,却在复杂推理时丢失关键语境——就像背下整本医书,却想不起哪个病例对应哪种疗法。
澳门科技大学团队从人类认知记忆理论中找到了破局点。HiMem不是简单的”存储-检索”管道,而是双脑架构:Episode Memory保留原始对话的”情景记忆”,Note Memory萃取稳定知识的”语义记忆”,二者通过记忆再巩固(Reconsolidation)动态互哺。
在LoCoMo 600轮超长对话基准上,HiMem Multi-Hop推理70.92%,较Mem0的56.62%暴涨14.3个百分点;Temporal Reasoning达74.77%,碾压SeCom的33.54%。更关键的是,它首次让AI记忆具备自我进化能力——检索失败触发知识修正,而非静态堆积。
认知盲区 | 为什么”压缩即遗忘”
人类大脑有两套记忆系统。
当你回忆上周的晚餐,情景记忆(Episodic Memory)帮你还原餐厅灯光、对话氛围、菜品摆盘;语义记忆(Semantic Memory)则提取”那家店擅长日料””朋友不吃生食”等稳定知识。两套系统分离又协作——情景提供上下文线索,语义支撑快速决策。
现有AI记忆系统却普遍“单脑作战”。Mem0把对话拆成原子事实,存入图结构;A-MEM用Zettelkasten笔记法链接实体与时序;SeCom做事件级语义压缩。它们都在做同一件事:把丰富体验压缩成扁平表示。
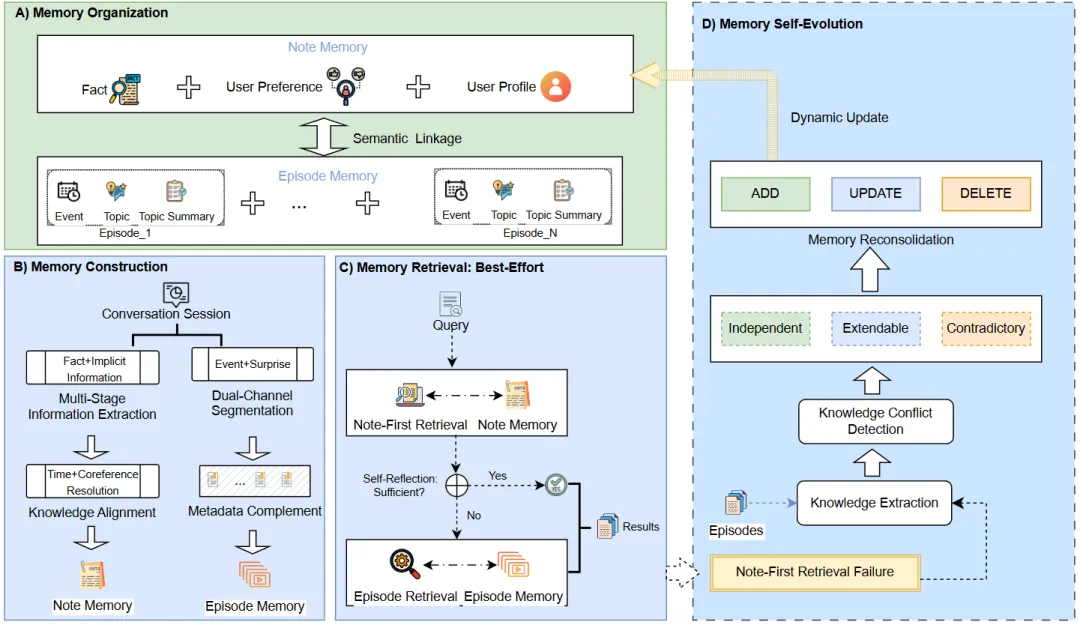
这种压缩有个隐蔽代价——表示退化(Representation Degeneration)。
Figure 3的分析框架揭示了问题本质:当记忆系统在某个维度上坍缩为单一设计选择,就会丧失适应性权衡能力。Mem0的记忆形式退化为”原子事实三元组”,SeCom退化为”事件级语义摘要”,MemGPT退化为”页式内存块”。它们在特定场景有效,却无法跨越粒度-结构-时序的三维权衡。
配图2:表示退化:单一设计选择限制适应性
具体表现有三重病灶:
病灶一:分割粗糙。现有系统按话题或时间粗粒度切分,把”用户突然沉默后转移话题”这种认知突变,和”同一话题的自然延伸”混为一谈。结果?关键转折点被淹没在冗长段落中。
病灶二:静态固化。知识一旦提取写入,系统只追加不修正。当用户说”我不再吃素了”,旧偏好”素食者”仍占据检索前排,新信息被当作独立事实堆积——矛盾不被识别,混乱持续累积。
病灶三:检索单一。向量相似度找到”相关内容”,却无法判断”是否足以回答”。Multi-Hop推理需要跨片段整合,Temporal Reasoning需要时序锚点,Open-Domain需要外部知识融合——纯相似度检索在这些场景集体失效。
配图3:LoCoMo 600轮对话的残酷差距]
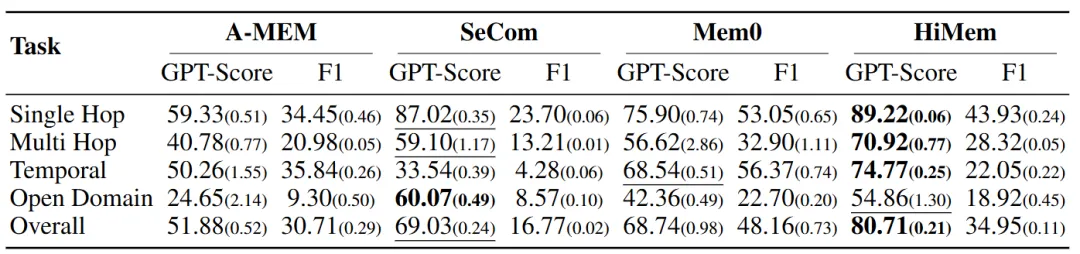
数据冰冷地证实了这一点。在LoCoMo基准——平均600轮、16K token、最长32个交互阶段的超长对话测试中:
-
Multi-Hop推理(需跨 distant turns 聚合):Mem0 56.62%,SeCom 59.10%,A-MEM 40.78%
-
Temporal Reasoning(涉及时序依赖):SeCom 33.54%,Mem0 68.54%,A-MEM 50.26%
-
Open-Domain(结合外部知识):Mem0 42.36%,SeCom 60.07%,A-MEM 24.65%
没有单一基线能在所有维度稳定。它们都在表示退化的陷阱中:追求某方面的极致,牺牲其他维度的适应性。
HiMem的切入点:与其在单一维度优化,不如重构记忆的多维架构。
双脑架构 | HiMem的”认知仿生学”
HiMem的核心设计是分层而非压缩。
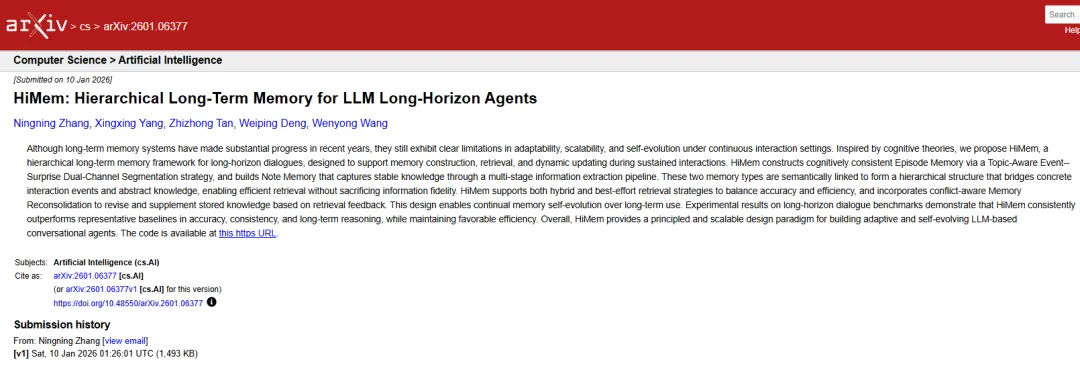
Figure 1A展示了这一架构:底层Episode Memory保留细粒度、时序锚定的交互片段;上层Note Memory萃取稳定、可复用的知识;二者通过语义链接(Semantic Linkage)形成双向通道。这不是简单的”原始vs精简”,而是功能分化——类似人类大脑的海马体(情景编码)与皮层(语义存储)的分工。
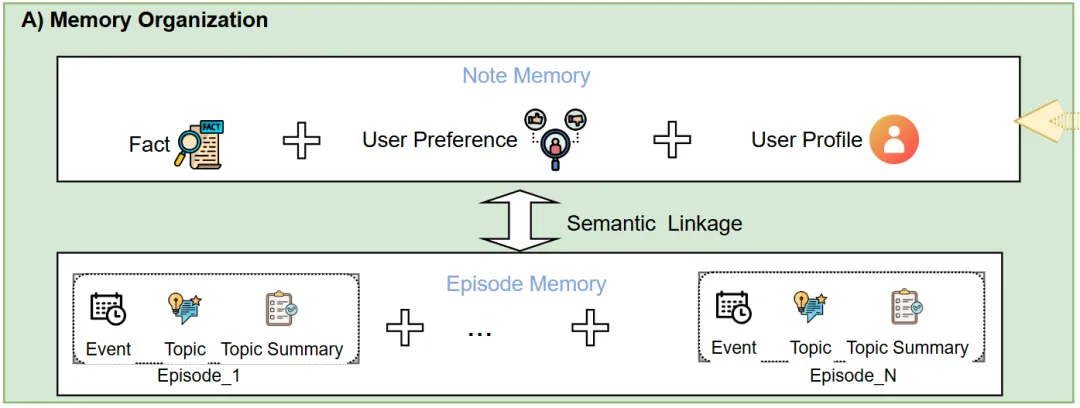
配图4:不是压缩,是功能分化
Episode Memory:认知一致的事件单元
构建Episode的关键是双通道分割策略(Topic-Aware Event–Surprise Dual-Channel Segmentation)。
传统分割只看话题连续性——”从晚餐聊到工作”算一个事件,因为话题相关。但HiMem增加惊喜通道(Surprise Channel):检测意图突变、情绪跳变、话语功能转折。分割边界由话题连续性 OR 认知突变触发,用LLM单次判断输出最终分割。
这种设计的认知科学依据来自概念整合理论(Conceptual Blending)和图式记忆研究——人类事件感知不仅依赖语义连贯,更依赖显著性 discontinuity。一次情绪爆发、一个沉默间隙、一个话题急转,都是认知上的”事件边界”。
结果?Episode单元紧凑且自包含,既减少跨片段干扰,又保留复杂推理所需的关键语境证据。Table 2的消融显示:移除Episode Memory,Multi-Hop从70.92%暴跌至56.26%,Temporal从74.77%跌至68.12%。原始语境对复杂推理不可替代。
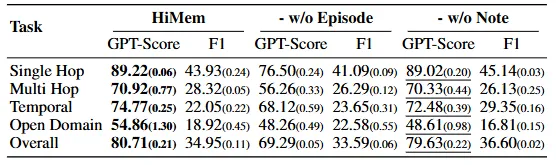
配图5:原始语境对复杂推理不可替代
Note Memory:多阶段萃取的稳定知识
如果说Episode是”未经消化的体验”,Note则是”萃取后的精华”。HiMem从每段对话提取三类知识:
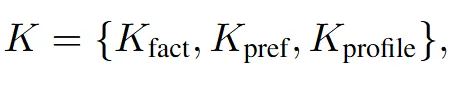
-
事实(K_fact):客观事件,如”3月15日部署了v2.1″
-
偏好(K_pref):用户倾向,如”喜欢简洁回复”
-
特质(K_profile):稳定属性,如”资深后端工程师”
提取分三阶段,刻意避免语义坍缩:
Stage 1提取独立可解释的事实单元;Stage 2识别高置信隐式信息(偏好/特质),但不引入新事实;Stage 3做非破坏性归一化——去重、指代消解(”他”→具体人名)、时序标准化(”上周三”→2026-03-15)。
每个Note是结构化记录:ID、内容、语义类别、关联元数据。Table 2显示:移除Note Memory,整体性能从80.71%降至79.63%,降幅小于移除Episode——Note主要加速定位、稳定锚点,而非替代原始语境。

配图6:展示工程细节的严谨性
知识对齐的”选择性”:记忆类型感知
最精妙的设计是差异化对齐策略。
Episode Memory优先保留原始对话语境,不做过度语义融合——因为分割已确保认知一致性,额外改写可能模糊隐式线索。Note Memory则强调抽象与归一化,因为提取后的知识脱离了原始上下文,必须依赖指代消解、时序对齐来维持可检索性。
Table 3的消融验证了这一点:对Note Memory禁用Knowledge Alignment,性能从63.44%暴跌至57.51%;但对Episode Memory启用Alignment,反而从79.63%微跌至78.12%。对齐不是万能药,必须记忆类型感知。
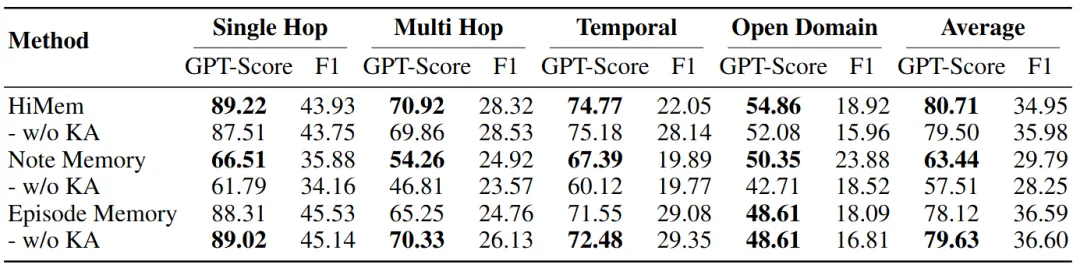
配图7:对齐不是万能药,必须记忆类型感知
这种”选择性处理”体现了HiMem的设计哲学:不做统一预处理,做分层适配。Episode保留丰富性供复杂推理,Note提供紧凑性供快速检索——二者互补,而非竞争。
第三部分:动态互哺 | 记忆再巩固的进化闭环
HiMem最颠覆的设计,是让记忆在回忆中进化。
传统系统把检索和更新当作独立流程:先查记忆,再生成回复,对话结束。知识库要么只追加(Mem0),要么按相似度替换(A-MEM),从不根据”回忆时的失败”自我修正。
HiMem的记忆再巩固(Memory Reconsolidation)机制打破了这一割裂。它把检索失败当作学习信号,形成”检索-检测-修正-写回”的闭环。
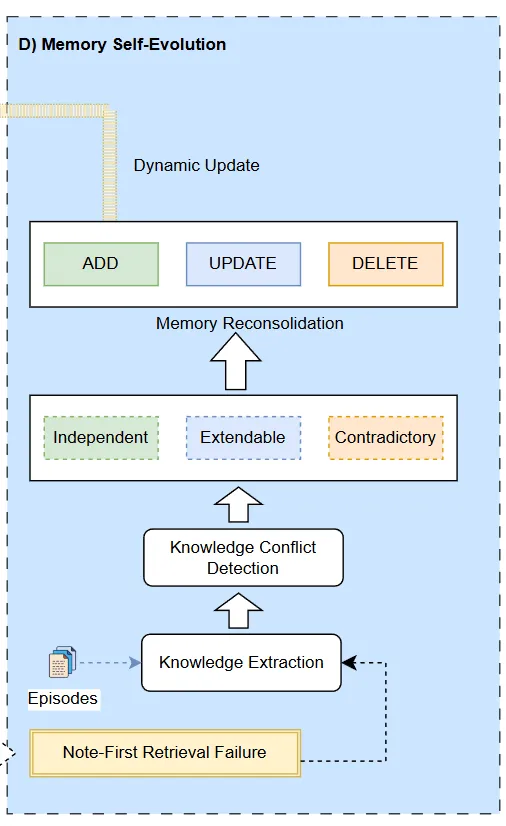
配图8:回忆即重构,失败即学习
触发条件:双重门控的保守主义
再巩固不是每次检索都触发。必须同时满足:
-
Note Memory检索不足(自评估证据不充分)
-
Episode Memory能提供支持(原始语境中有答案)
这种合取触发(conjunctive trigger)的设计充满认知科学智慧。它确保更新锚定于 episodic 证据,而非凭空生成。如果Note找不到答案但Episode也没有,系统承认失败,不胡乱修补。
Figure 1D展示了完整流程:当Note-First Retrieval失败,系统从Episode提取知识,与现有Note做冲突检测,分类为独立/可扩展/矛盾三类,分别执行ADD/UPDATE/DELETE操作。
配图9:三阶段进化:对齐→巩固→自我修正
Table 4的数据验证了机制有效性。纯Note Memory(无对齐、无进化)基线仅57.51%;加入Knowledge Alignment(KA)跃升至63.44%;再启用Memory Evolution(ME)达69.29%——累计提升11.78个百分点。
Figure 2的雷达图更直观:绿色实线(HiMem After Evolution)全面包围蓝色虚线(Note Before Evolution),Multi-Hop、Temporal、Open-Domain、Overall四维全涨。
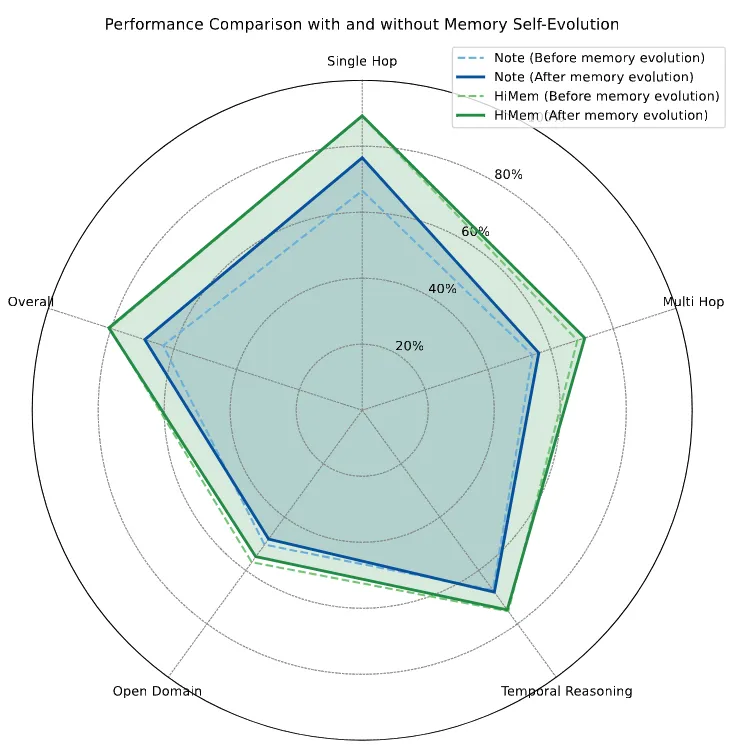
配图10:进化后的记忆全面包围原始状态
与神经科学的深层呼应
“再巩固”概念直接来自Nader 2003年的记忆研究。传统观点认为回忆是读取过程,Nader发现回忆是重构——每次提取都会改变记忆本身,使其更易与后续经验整合。
HiMem的工程实现模拟了这一生物学机制:
-
提取即信号:检索失败不是错误,是更新触发器
-
冲突即类型:独立/可扩展/矛盾的分类,避免无差别覆盖
-
修正即学习:写回Note Memory的知识,下次检索直接可用
这与Mem0的”相似度驱动更新”形成本质区别。Mem0用向量距离判断重复,可能把”我不再吃素”当作新事实追加,与旧偏好并存;HiMem的矛盾检测会识别冲突,执行UPDATE或DELETE,维持一致性。
保守主义的工程智慧
论文坦诚这一机制的局限:触发过于保守。只有检索失败时才更新,可能遗漏隐性不一致——比如用户多次暗示偏好变化,但从未被直接查询。
但保守有其价值。在医疗、法律等高风险场景,宁可漏更新,不误修正。Table 11的拒绝规则分析(附录)显示,HiMem的R1规则(合取触发)是唯一零假阴性方案——从不误杀有效查询。
检索策略 | “尽力而为”的效率美学
双脑架构提供了灵活性,HiMem用两种检索策略兑现。
Hybrid Retrieval:双脑并行,精度优先
同时查询Note Memory和Episode Memory,聚合结果后由LLM综合判断。这是召回最大化策略——不放过任何可能相关的线索。
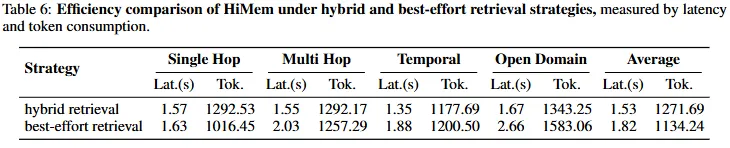
Table 5显示,Hybrid在Multi-Hop达70.92%,Temporal 74.77%,Open-Domain 54.86%,全面最优。但代价是token消耗:平均1271.69(Table 6),因为两层记忆的内容都被送入上下文。

配图11:精度优先vs效率优先,场景适配而非绝对优劣
Best-Effort Retrieval:Note优先,按需下探
更聪明的策略是分层下探:先查Note Memory,LLM自评估证据是否充分;若不足,再检索Episode。这是效率优先策略——用紧凑知识回答大部分查询,只在必要时动用原始语境。
Table 6显示,Best-Effort token消耗降至1134.24(-10.8%),但延迟增加(1.82s vs 1.53s)。因为需要两次评估:Note检索后的自评估,以及可能的Episode二次检索。
策略选择的场景适配
两种策略不是优劣关系,是权衡工具:
-
Hybrid:复杂推理场景,精度第一,token预算充足
-
Best-Effort:日常对话场景,效率优先,快速响应
更关键的是,Best-Effort的自评估机制本身就是质量控制。它避免盲目下探,也避免Note不足时强行回答——系统明确知道”我知道什么”和”我需要查什么”。
配图12:证明信息密度优势,避免盲目扩大检索
超参数的”饱和洞察”
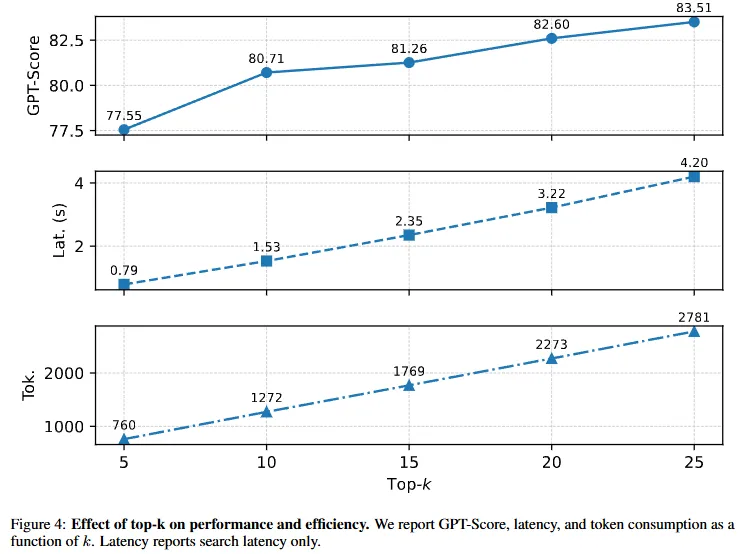
Figure 4展示了top-k参数的影响。k从5增至10,GPT-Score从77.55跳至80.71;但k>10后性能** plateau **(15→20→25仅+2.8分),延迟和token却线性增长。
这一”饱和点”证明HiMem的信息密度优势:Episode分割足够精细,Note提取足够紧凑,小检索窗口(k=10)已捕获关键信息。更大k引入噪声,得不偿失。
工程启示:不要靠扩大检索范围补偿表示质量。HiMem用更好的记忆组织,避免”检索更多→上下文爆炸→生成质量下降”的恶性循环。
Table 7的效率对比更震撼:HiMem整体延迟1.53s,token1271.69;Mem0延迟4.53s(+196%),token1582.51(+24%)。分层架构不仅精度更高,效率也碾压——因为精准定位减少了无效检索。
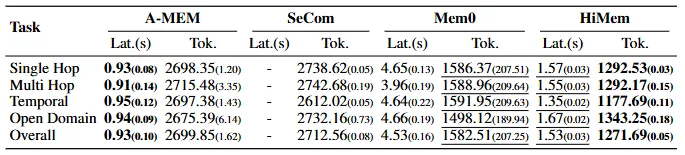
配图13:分层架构:不仅更准,还更快
边界诚实 | HiMem不做什么
HiMem的论文罕见地坦诚——不是罗列贡献,而是划定边界。
依赖LLM判断能力:分割、提取、冲突检测、证据评估,全部绑定基座模型质量。噪声输入、隐喻语言、跨文化语用变异,都可能让LLM误判。论文建议未来引入轻量分类器或不确定性估计,但当前版本无此防护。
单次分割上限:极端长对话或高度交织的多话题场景,可能需要多粒度迭代重组。HiMem的一次性全局分割,是效率与表达力的权衡。
保守进化触发:仅检索失败时更新,可能遗漏隐性不一致。用户多次暗示偏好变化,若从未被直接查询,Note Memory保持原样。主动探测机制缺失。
评估范围局限:单用户、文本、英文场景(LoCoMo)。多智能体记忆交互、多模态输入、跨语言泛化——均未验证。

配图14:不是技术债务,是设计选择的必然代价
这些不是技术债务,是设计选择的必然代价。HiMem用保守换稳定,用边界换聚焦,用诚实换可信。
与Mem0的范式差异:两条道路
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这不是优劣判断,是场景适配。Mem0适合需要即时上线、团队共享、商业支持的企业;HiMem适合研究探索、认知科学验证、可解释性优先的场景。
论文的伦理章节(Ethical Considerations)进一步划界:医疗/法律等高风险领域,必须人类在环;用户需被告知”正在与有长期记忆的Agent交互”;GDPR的”被遗忘权”需通过Entry级删除实现。
从”存储”到”认知”
HiMem的价值不在SOTA数字,而在范式示范。
它证明:AI记忆系统可以不像数据库,而像大脑——分层而非扁平,动态而非静态,进化而非堆积。Episode Memory与Note Memory的分工,不是工程妥协,是认知功能的分离;记忆再巩固的闭环,不是优化技巧,是回忆即重构的生物学模拟。
这一范式对行业的启示深远:
不要更大,要更分层。220k记录的向量库不如600轮对话的双脑架构,因为检索质量取决于表示结构,而非数据规模。
不要更快,要更自知。Best-Effort的自评估机制,让系统明确”知道何时不知道”——这是可靠性的根基。
不要更多,要更一致。冲突感知的更新,比无差别追加更能维持长期交互的连贯性。

配图15:不像数据库,像大脑
HiMem的开源地址已公布:https://github.com/jojopdq/HiMem
未来方向在论文中清晰列出:时序索引、交叉编码器重排序、自适应去重、多主题覆盖、任务级归因。这些不是空洞承诺,是预留的扩展点——当前架构已为之准备。
当行业追逐“更大上下文窗口””更强嵌入模型”时,HiMem回归认知科学的第一性原理:人类记忆不是存储介质,是动态重构的体验。让AI记忆更像大脑,或许才是”长记性”的真正开始。
论文链接:https://arxiv.org/pdf/2601.06377
项目链接:https://github.com/jojopdq/HiMem.
持续关注本公众号【赛博雷达】,我们会第一时间拆解更多前沿开源模型、本地AI实战和Agent最新进展。喜欢这篇文章就点个关注+转发给正在专注AI的朋友,一起拥抱这个免费又强大的AI核弹!
感谢阅读,我们下期见~