 夜雨聆风
夜雨聆风





26年最火AI渗透工具? 拆解Shannon源码实现

声明:本文内容人工手写,由AI润色、排版、画图,可放心食用。
◆前言
因工作需要,会经常看一些前沿的 SAST Agent 或 Pentest Agent 的实现,并从中吸取优秀的经验(当然后续会持续发布其他项目的分析,欢迎关注 🙌)。
最近发现,KeygraphHQ/shannon 项目在 Github 以相当快的速度获得了 3.8W 的 Star, 连续多天登顶Github Trend, 碾压一众其他安全类产品,这在安全类项目中是一个很夸张的存在。

其中他们宣称的 “no exploit, no report”、0误报 && XBOW 测试集 96.15% 得分,确实赚足了噱头。但是在市面上,除了毫无营养的营销号 AI 文之外,我还没有从源码技术层面上分析这个项目具体能力的文章,因此我深度分析后有了这篇文章。
那么它究竟如何才能在众多项目中脱颖而出呢?我这里不卖关子,直接说结论:
这个项目并没有 Agent 层面的魔法,也没有工程上的奇迹。
它仍然是基于经典渗透工作流(Pre-Recon → Recon → Vuln Analysis → Exploitation → Report),利用 Claude Agent SDK 在每个节点通过 Prompt + 容器内预装的渗透工具驱动 13 个专职 Agent 完成漏洞分析。
以开源版本的实现(以及闭源版本的技术介绍)能达到吹得这些牛吗?我觉得够呛,整体能力仍然依赖于底层的 SOTA Agent & 模型的能力,目前来看能到达的效果大家是可以想象的。
但是从 Prompt 中我们可以发现作者有很强的渗透测试经验,同时 Agent 工作流在上下文管理、任务状态管理等工程方面同样有很多可以学习的地方。它虽没有它声明的那么强大,但它仍然存在很多值得学习的地方。
接下来我将按下面目录详细分析这个项目, 并在文章最后分析下,为什么这个项目这么🔥呢🕵️♀️:
本文目录
一、整体是怎么实现的?
· Lite & Pro 版本差异
· 四层架构流程图(CLI / Temporal / Agent / 交付物)
· 13 个 Agent × 5 阶段的渗透测试工作流
二、有哪些可以偷的工程技巧?
· Agent Git 状态管理
· 多 Agent 上下文管理
· 经验丰富的 Prompt 工程
三、那么能替代人工渗透吗?
四、揣测下为什么这么🔥
◆整体是怎么实现的?
Lite & Pro 版本介绍
Shannon 其实是两个产品。开源仓库里那 4W star 对应的是 Shannon Lite(AGPL-3.0),而它还提供商业形态叫 Shannon Pro。主要的区别在于最开始的白盒:Lite 所谓的白盒,其实就是把源码目录挂进容器让 Claude Code 自己 Read/Grep;Pro 做了 CPG(Code Property Graph)级别的数据流建模后进行分析,从描述上来看,这部分更像是偏静态分析了。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
整体流程图
Shannon 整体是四层结构:
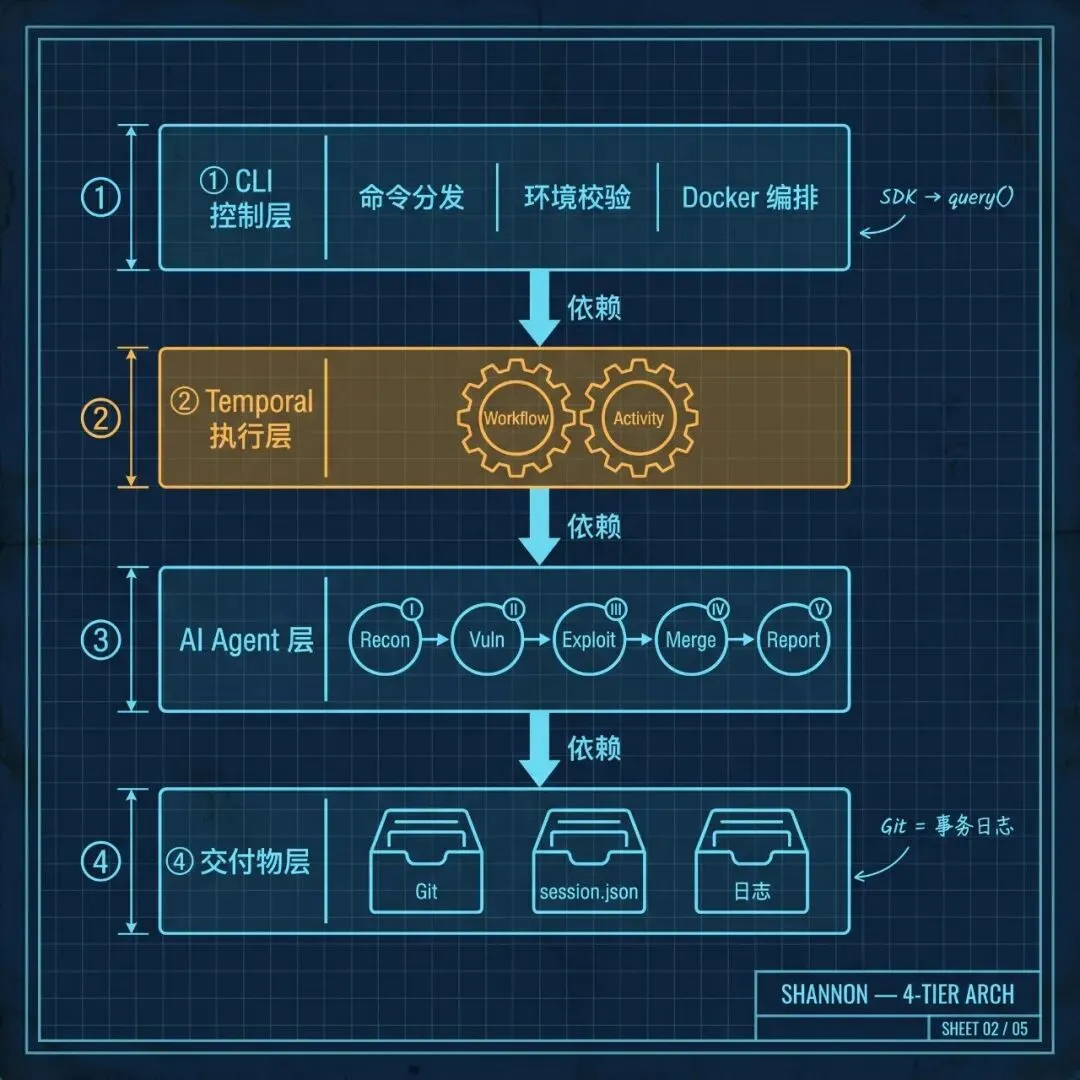
第一层:CLI 控制层。 入口是 shannon scan 命令,用户面向的部分几乎全在这里。CLI 负责环境校验(API Key、Docker daemon、目录权限)、拉起 Docker Compose(Temporal Server + Router)、起 Worker 容器。
# shannon scan 的启动流水
$shannon scan ./my-repo
├── 校验 API Key / Docker daemon / 目录权限
├── docker compose up # Temporal Server + Router
└── docker run worker # 执行 Agent 的容器
第二层:Temporal / Worker 执行层。 Temporal 这一步很关键。一次渗透可能跑几小时,13 个 Agent 每个都可能因为 API 限流、network hiccup、消费上限等原因挂掉。Temporal 提供的持久化工作流、自动重试、心跳监控、进度查询。Workflow 本身是纯编排逻辑(workflows.ts),真正执行 Agent 的是 Activity(activities.ts)——Activity 是个薄包装,里面只做心跳循环、错误分类、容器生命周期,真正的业务 logic 全在 services/ 下的Agent中,跟 Temporal 没有代码耦合。
// workflows.ts —— 纯编排,只挑 Agent
await proxyActivities.runAgent(‘pre-recon’);
await proxyActivities.runAgent(‘recon’);
// activities.ts —— 心跳 + 错误分类的薄壳
export async functionrunAgent(name) {
return services.agent.run(name); // 业务全在 services/
}
第三层:AI Agent 层。 13 个 Agent 按 5 阶段排布:Pre-Recon(白盒源码分析) → Recon(浏览器探查 + 代码关联) → 5 个 Vuln Agent 并行 → 5 个 Exploit Agent 条件触发并行 → Report。某个 xxx-vuln 跑完并产出非空 queue,对应的 xxx-exploit 立刻就起,不等其他 Vuln 结束。如果某个 vuln Agent 返回空队列,对应 exploit 直接跳过。所有 Agent 的元数据(前置依赖、prompt 模板、模型层级、交付物文件名)都集中在一个 AGENTS 注册表里声明式管理,workflow 读这个表来编排,加新 Agent 不用改编排逻辑。
// AGENTS 注册表:加新 Agent 只改这里
export constAGENTS = {
‘pre-recon’: { deps: [], model: ‘opus’, prompt: ‘pre-recon.md’ },
‘recon’: { deps: [‘pre-recon’], model: ‘sonnet’, prompt: ‘recon.md’ },
‘xss-vuln’: { deps: [‘recon’], model: ‘sonnet’, prompt: ‘xss.md’ },
‘xss-exploit’: { deps: [‘xss-vuln’], model: ‘sonnet’, prompt: ‘xss-exp.md’ },
// … 共 13 个
};
第四层:交付物与恢复层。 Agent 的每一次输出都不是临时文件——它被 commit 进一个独立的 Deliverables Git 仓库,每个 Agent 启动前创建 checkpoint,失败时 git reset --hard + git clean -fd 两步回滚到干净状态,成功时 commit 留痕。配合 session.json 追踪每个 Agent 的状态、workflow.log 记录完整执行事实,整个系统具备了崩溃-恢复-续跑的能力。这一层后面的”Agent 状态管理”会细讲。
# 每个 Agent 的事务边界 = 一次 Git 提交
git commit –allow-empty -m “checkpoint:xss-vuln start”# 启动前
# 成功分支
git commit -am “agent:xss-vuln success”
# 失败分支 —— 回到 checkpoint
git reset –hard && git clean -fd
四层之间的依赖是严格单向的:CLI 不知道 Temporal 的存在(通过 Docker 启动),Temporal 不知道 Agent 具体怎么跑(通过 Activity 调 services),Agent 不知道交付物怎么存(通过 save-deliverable CLI 落盘)。每一层都可以独立替换——换编排引擎、换模型 provider、换存储后端——核心业务都不受影响。
渗透测试工作流
整个项目的核心,其实只用了 Claude Agent SDK 的一个函数——query()。翻遍整个代码库,实际导入 SDK 的文件只有两个:
// apps/worker/src/ai/claude-executor.ts —— 核心 Agent 执行引擎
import { query, typeJsonSchemaOutputFormat } from‘@anthropic-ai/claude-agent-sdk’;
// apps/worker/src/services/preflight.ts —— 启动前发 “hi” 验证 API Key
import { query, SDKAssistantMessageError } from‘@anthropic-ai/claude-agent-sdk’;
query() 返回一个异步迭代器,Shannon 做的事情就是 for await 把每一条消息拿出来,路由到不同的处理器(tool_use / tool_result / text / result)。所谓”13 个 Agent”,底层其实就是用不同的 prompt、不同的参数,调用 13 次 query()。
调用参数也简单:
const options = {
model, // 按 tier 解析(Opus/Sonnet/Haiku)
maxTurns: 10_000, // 所有 Agent 一致
cwd: sourceDir, // 被测仓库路径(只读挂载)
permissionMode: ‘bypassPermissions’, // 跳过所有权限确认
allowDangerouslySkipPermissions: true,
settingSources: [‘user’],
env: sdkEnv,
…(outputFormat && { outputFormat }),// 只有 5 个 vuln Agent 有
};
没有 MCP Server,没有自定义 Skill(用了 Claude Code 内置的 playwright-cli Skill,但那是 Claude Code 的能力,不是 Shannon 的)。整个 Agent 使用的”工具”分三层:
● Claude Code 原生工具:Task、Bash、Read、Write、Edit、Grep、Glob、TodoWrite、playwright-cli
● 容器预装的安全工具:nmap、subfinder、whatweb、curl、schemathesis、Chromium(通过 Dockerfile 装进镜像)
● 项目自写的两个 CLI:save-deliverable(交付物保存 + 校验)和 generate-totp(MFA 登录)
13 个 Agent 的角色分工如下:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
*_exploitation_queue.json |
|
|
|
|
|
|
|
|
|
|
一次完整扫描就是 13 次 query() 串 / 并行起来的结果。理解这一点,后面关于 Prompt 和上下文管理的讨论才有意义——Shannon 的”魔法”全部发生在 prompt 和外围工程上,SDK 本身只是个入口。
◆有哪些可以学习的技巧?
Agent 状态管理:把 Git 当成 AI 产物的事务日志
一次渗透扫描可能要跑几个小时,13 个 Agent 每个都要烧很多的 Tokens。如果第 9 个 Agent 崩了,整个重跑显然不现实。Shannon 的做法是把每个步骤的交付物(每个 Agent 产出的 Markdown 报告和 JSON 队列)放进一个独立的 Git 仓库,用 Git 的提交 / 回滚语义实现可恢复。
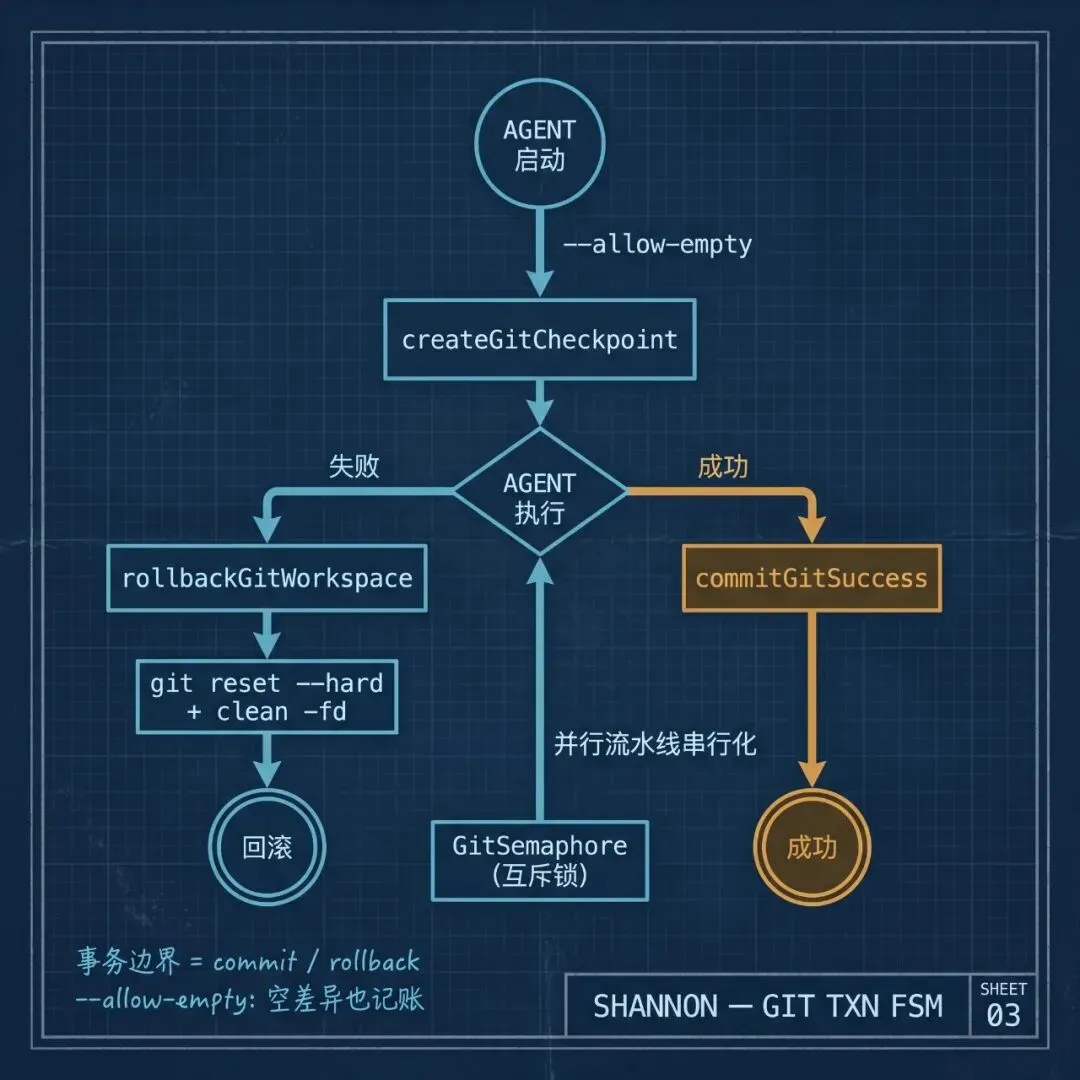
这个 Git 仓库不是用户的源码仓库,而是位于 {repo}/.shannon/deliverables/.git,专门用来记录 Agent 的输出。它的生命周期由三个核心操作支撑:
// git-manager.ts:206 —— 每个 Agent 启动前创建 checkpoint
export async functioncreateGitCheckpoint(sourceDir, description, attempt) {
if (attempt > 1) {
// 重试前清理上一次的脏状态
awaitrollbackGitWorkspace(sourceDir, `${description} (retry cleanup)`);
}
awaitexecuteGitCommandWithRetry([‘git’, ‘add’, ‘-A’], sourceDir);
awaitexecuteGitCommandWithRetry(
[‘git’, ‘commit’, ‘-m’, `Checkpoint: ${description} (attempt ${attempt})`, ‘–allow-empty’],
sourceDir,
);
}
--allow-empty 是个关键细节——即使这个 Agent 一个字没写,也要保证有 commit 可以回退到。
回滚更朴素,分两步走:
// git-manager.ts:162 —— Agent 失败时回滚
awaitexecuteGitCommandWithRetry([‘git’, ‘reset’, ‘–hard’, ‘HEAD’], sourceDir); // 已跟踪文件
awaitexecuteGitCommandWithRetry([‘git’, ‘clean’, ‘-fd’], sourceDir); // 未跟踪文件
reset --hard 处理 Agent 修改过的文件,clean -fd 干掉 Agent 新创建但没来得及收尾的文件。两步合起来保证工作区回到一个已知干净的状态。
这套机制有一个难点:5 条 vuln-exploit 流水线并行跑,它们都在往同一个 Git 仓库里写东西。Git 的 .git/index.lock 不支持并发,一旦两个 Agent 同时 commit,必然有一个挂掉。Shannon 的方案是一个全局信号量:
// git-manager.ts:78 —— 进程内单例
classGitSemaphore {
privatequeue: Array<() => void> = [];
privaterunning: boolean = false;
asyncacquire() { /* 排队 */ }
release() { /* 唤醒下一个 */ }
}
const gitSemaphore = newGitSemaphore();
每次 git 命令前 acquire、命令后 release,外加指数退避重试来处理偶发的 lock 冲突。实现很糙(进程内,不跨进程),但对单容器单 Worker 的部署模型来说够用。
然后是 Resume。崩了之后 shannon scan resume 会做三件事:读 session.json 确认哪些 Agent 已完成,扫 .shannon/deliverables/ 交叉验证交付物文件是否真的存在,然后从最后一个成功的 checkpoint 继续。这里有一个设计上的品味——不光信 session.json,还要用磁盘文件双重校验。session.json 可能因为崩溃时机错乱而和磁盘状态不一致,两边互相印证才能安全恢复。
把 Git 当作 AI 产物的事务日志这件事,我觉得是 Shannon 最朴实但也最值得学习的一个模式。Git 免费提供了原子提交、审计日志、精确回滚——三个在多 Agent 系统中本来要你自己造的基础设施。大部分 AI 代码生成项目把模型输出当一次性临时数据处理,Shannon 把它当成优秀级很高的需要版本管理的工程资产。
多 Agent 上下文管理:结构化输出作为 Agent 间的类型化 RPC
多 Agent 系统里,最脆弱的永远是 Agent 之间的数据交接。Agent A 产自由文本,Agent B 用另一次 LLM 调用去解析它——你不仅要祈祷 A 写得对,还要祈祷 B 能读得懂。一旦文本格式飘了,整条管线就断了。
Shannon 把 Agent 间的接口做成强类型契约。5 个 vuln Agent 全部使用 Zod Schema 约束输出格式,Claude Agent SDK 的 JsonSchemaOutputFormat 直接把 schema 下发给模型,模型在生成阶段就被强制遵守。
// queue-schemas.ts:20 —— 所有漏洞共享的基础字段
const baseVulnerability = z.object({
ID: z.string(),
vulnerability_type: z.string(),
externally_exploitable: z.boolean(),
confidence: z.string(),
notes: z.string().optional(),
});
// 各漏洞类型扩展领域特有字段
const InjectionVulnerability = baseVulnerability.extend({
source: z.string().optional(), // 输入源
sink_call: z.string().optional(), // 危险函数
slot_type: z.string().optional(), // SQL-val | CMD-argument | …
sanitization_observed: z.string().optional(),
witness_payload: z.string().optional(),
verdict: z.string().optional(),
mismatch_reason: z.string().optional(),
});
每个漏洞域都有自己的领域特有字段——注入关心 sink_call 和 slot_type,XSS 关心 render_context 和 encoding_observed,SSRF 关心 vulnerable_parameter——共享结构 + 领域差异的 Schema 设计,让下游 exploit Agent 拿到 JSON 就能直接驱动后续利用,不需要再做一次解析型 LLM 调用。
双输出模式是 Shannon 的另一个巧思。每个 vuln Agent 同时产出两份东西:
● xxx_analysis_deliverable.md:人类可读的分析报告,给审计和最终报告用
● xxx_exploitation_queue.json:机器可解析的结构化队列,给下游 exploit Agent 消费
队列验证做了 5 步函数式 Harness(createPaths → checkFileExistence → validateExistenceRules → validateQueueContent → determineExploitationDecision),其中有一点是对称性校验——queue 和 deliverable 必须同时存在,只有一个等于失败。这一条防止了”Agent 写了分析但没生成队列”或者”队列有但分析报告被吞”这种部分成功的幻觉状态。
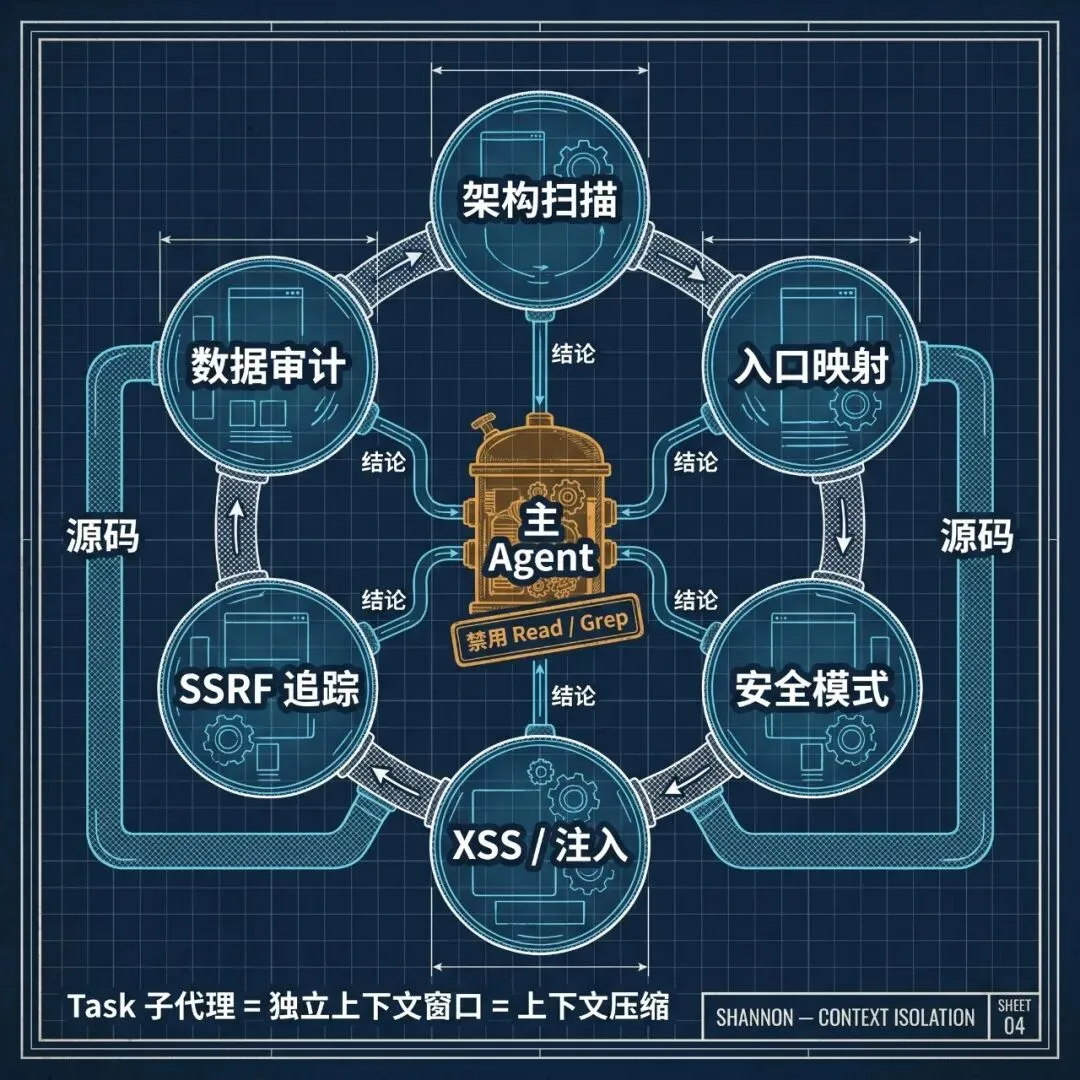
然后是主 Agent 和子代理的边界。如果你翻开每一份 vuln prompt,都会看到这一段:
CRITICAL TOOL USAGE RESTRICTIONS:
– NEVER use the Read tool for application source code analysis—delegate every
code review to the Task Agent.
– ALWAYS direct the Task Agent to trace tainted data flow, sanitization/encoding
steps, and sink construction before you reach a verdict.
主 Agent 被明令禁止用 Read / Grep 读源码,所有代码分析必须派 Task 子代理。这不是设计洁癖,是防爆炸——一个源码文件动辄几千行,直接读进主 Agent 上下文立刻就会被撑爆。Task 子代理有自己独立的上下文窗口,读完源码后只把结论回传给主 Agent,相当于做了一次上下文压缩。pre-recon 阶段甚至一口气派 6 个 Task 子代理并行扫(Architecture Scanner、Entry Point Mapper、Security Pattern Hunter、XSS / Injection Sink Hunter、SSRF Tracer、Data Security Auditor),每个都独立消耗上下文,主 Agent 的窗口完全不被源码内容污染。
经验丰富的 Prompt 工程
Shannon 的 prompts/ 目录有 5000 多行、32 个文件——这是一个纯粹的 Prompt 仓库。作者本人的渗透经验以及思路在这些 prompt 里暴露无遗。可以从两条线来挖:一是安全技术层,作者把自己的方法论和经验代码化;二是Harness 层,他用 prompt 结构把模型约束。
安全技术层
方法论嵌入 prompt,对齐人类漏洞标准。 每个 vuln Agent 都不是”你来分析一下 XSS 吧”这种空泛指令,而是把一套完整方法论直接写进 prompt。以 Injection 为例,核心是反向污点分析(Sink → Source):从 sink 反推到 source,遇到”正确的 sanitizer 且后续无 mutation”就提前终止标记 SAFE;遇到数据库读就假定数据不可信(Stored Injection);sanitizer 之后出现的字符串拼接视为防护失效——这些规则不是让模型”自己想”,而是一条条在 prompt 里列出来的 checklist。
Auth Agent 有9个checklist(HTTPS/HSTS、速率限制、Cookie 三个 flag、JWT 算法、会话固定、密码策略、用户枚举、密码重置、SSO/nOAuth),SSRF Agent 有 7 点(HTTP client 识别、协议白名单、IP 限制、端口限制、URL 解析绕过、Header 处理、响应可见性)。这不是 AI 自己悟出来的,是作者把自己的经验代码化成了 checklist。
虽然后面可能存在更加强大的模型,但是工具核心还是要对齐人类意图。
Context-aware 防御匹配,不是”有没有 escape”。 XSS Agent 的 prompt 里列出 5 种渲染上下文——HTML_BODY / HTML_ATTRIBUTE / JAVASCRIPT_STRING / URL_PARAM / CSS_VALUE——每种要求的编码完全不同:HTML entity encoding 放到 JS 字符串里等于没加,URL encoding 放到 CSS 里也没用。Injection Agent 的 slot_type 同理:SQL-val 需要参数化查询、SQL-ident(表名 / 列名)需要白名单、CMD-argument 需要数组参数。判定标准不是”有没有 sanitizer”,而是”这个 sanitizer 匹不匹配 sink 所在的上下文”。而传统 SAST 只能模式匹配,很难做到上下文推理。
Side-effect 之后再鉴权 = 没鉴权。 Authz Agent 的定义里有一条很硬的规则:“Guard AFTER side-effect 不算有效防护”——哪怕代码里有权限检查,只要写操作、DB update、跨租户读取已经发生,就算漏洞。这种判定把”有 middleware 但位置不对”的半吊子防护都识别出来。漏洞挖掘稍有经验的人都知道,这种顺序错误是实战中最常见的漏洞模式之一,能把它写进 prompt。
Harness 层
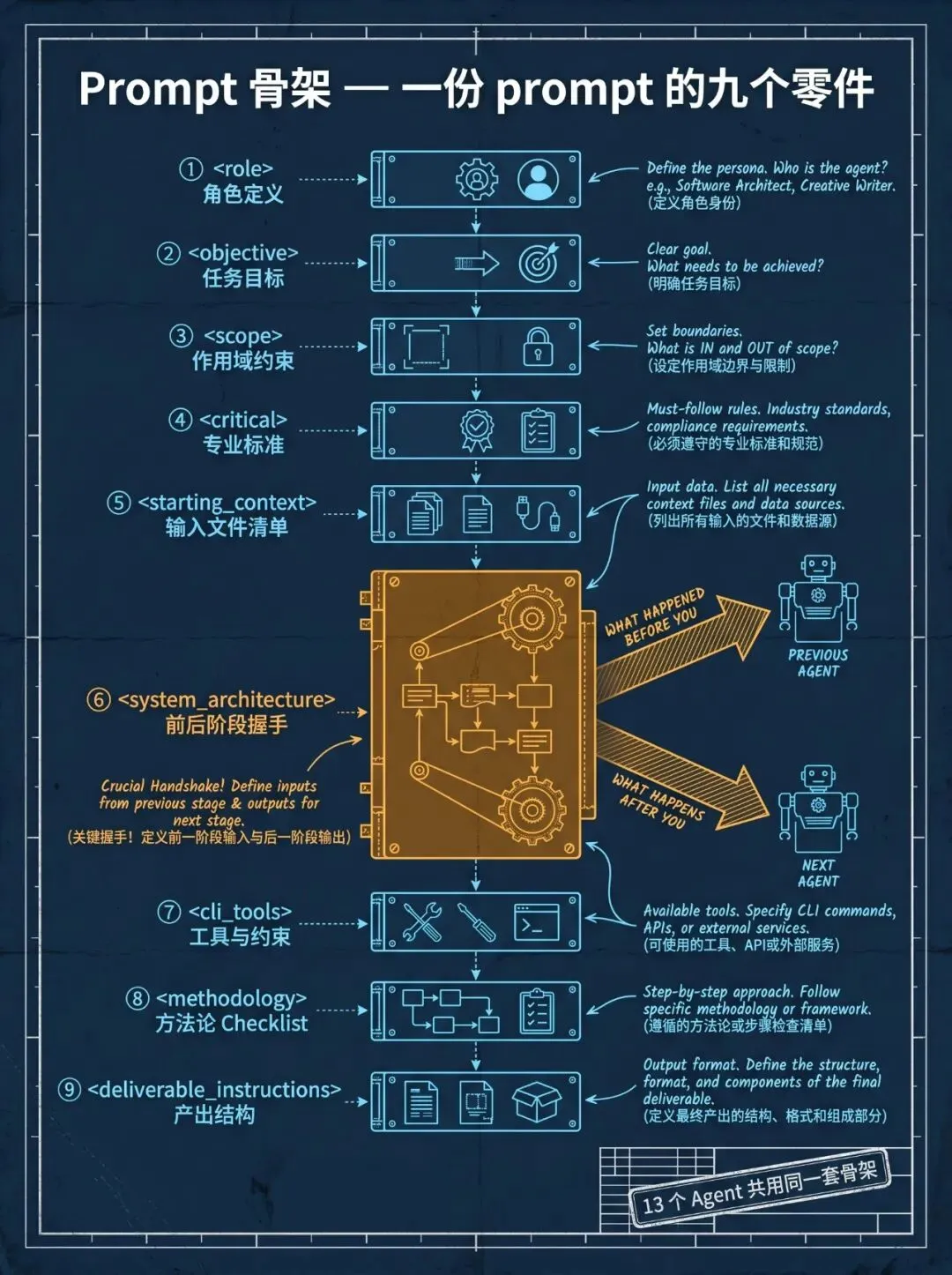
Prompt 骨架化,让 Agent 上下文更清新。 13 个 Agent 的 prompt 共用一套 XML 标签骨架:<role> / <objective> / <scope> / <critical> / <starting_context> / <system_architecture> / <cli_tools> / <methodology> / <deliverable_instructions>。其中 <system_architecture> 是关键一节,每个 prompt 必写三件事:
● Phase Sequence:我在流水线的哪个位置
● WHAT HAPPENED BEFORE YOU:上游 Agent 做了什么、交付物在哪个文件
● WHAT HAPPENS AFTER YOU:下游 Agent 要用我的什么输出
多 Agent 系统最常见的失败模式是”Agent 不知道自己依赖谁的输出、也不知道谁会用自己的输出”,结果自作主张、凭空发挥。Shannon 把流水线上下文显式写进每个 prompt,相当于强制建立了一个 Agent 间的握手契约。
把”够不够努力”量化成具体数字。 Exploit Agent 里有一组很细的阈值:
● 初始确认:每个漏洞至少 3 种不同 payload
● Bypass 穷尽:每个疑似漏洞至少 8-10 种技术变体(encoding、syntax、comment 变形等)
● 升级触发:手动测试超过 10-12 次无进展,升级到 sqlmap 或 Task Agent 脚本
● 脚本限制:每次 Task Agent 脚本 ≤ 15 行、≤ 5 个 payload
把”试得够不够”从主观感受变成可审计的规则。LLM 最常见的偷懒方式就是”试两三次不行就放弃”,标上硬阈值以后,模型想提前收工都没借口。相关的还有 FALSE POSITIVE 的纪律:WAF 拦截不算 FALSE POSITIVE,必须穷尽 bypass 才能下结论。prompt 里直接写 Classification is FORBIDDEN until you have attempted multiple distinct bypass techniques,FALSE POSITIVE 被要求和 EXPLOITED / POTENTIAL 一样严肃地对待。
◆那么能替代人工渗透吗?
经过上述的结论,目前来看肯定是不行的。
项目极度依赖 Claude Code + 模型本身的能力。项目在系统架构上,仍然缺乏额外的 Harness 或者创新点来保证渗透探索深度、广度和稳定性,也没有对通用逻辑漏洞、业务漏洞建模提出可靠的解决方案。项目在可扩展性上也同样需要下功夫。
除了以上问题,Reddit 上有不少对于这个项目效果 & 烧钱的讨论,没有限制的每个节点的多子 Agent 并行,烧的钱测试出来的漏洞还不一定比购买人工渗透服务来得划算。文档中吹得牛可以理解为创业公司的某种营销罢了,当然也不能掩盖项目本身的价值。
◆揣测下为什么这么🔥
这个项目有很多优秀值得学习的地方,但热度如此高还是存在困惑。
在我深度互联网冲浪的努力下,终于找到了部分的蛛丝马迹。它热度爆涨、Star 狂飙的时间实在 26 年 2 月 7 号开始,Claude Code Security(26.02.20)还没发布消息,因此并不是蹭上它的热点。
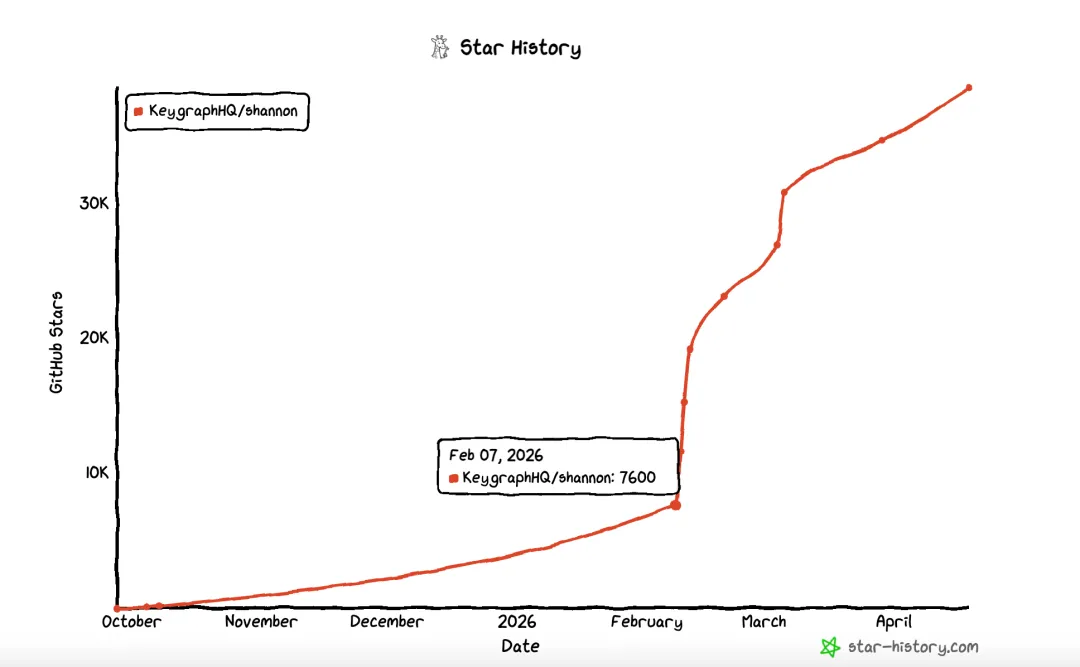
在不懈的努力下,我找到了最可能的原因,一位博主在 Twitter 上推荐了这个项目,并且目前获得了500w的阅读量。
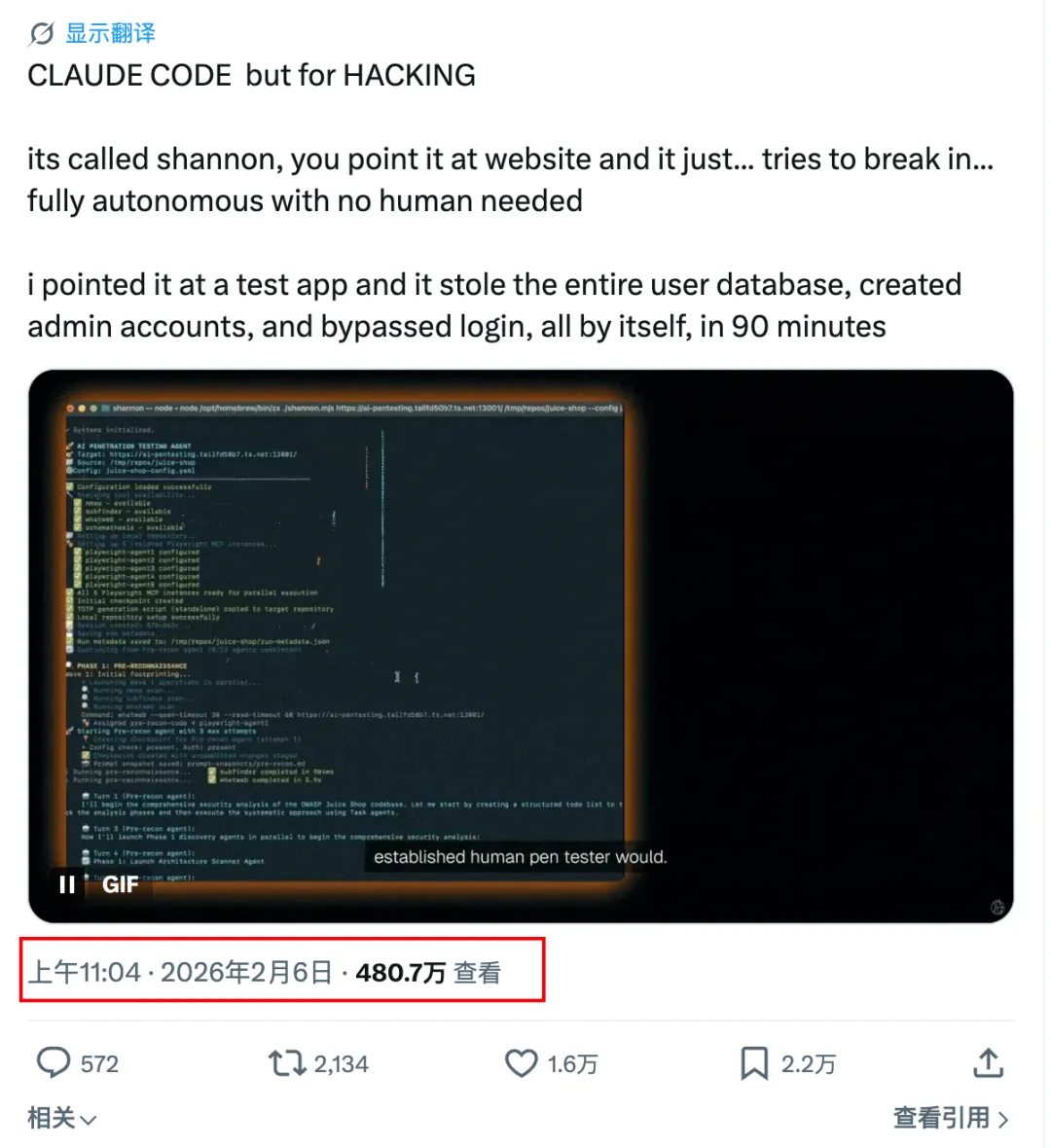
这个推文有两个引燃点:
● 1. “CLAUDE CODE but for HACKING”,成功还是蹭上了Claude Code。
● 2. “90 分钟拿到管理员权限 + 脱库”,很有感官冲击力的话语。
如果感兴趣可以去搜搜看下该推文下面的回复,人类又再一次要完蛋了😂。
在这些整体的助推下,该推文直接实现了近 500w 的阅读及 2000+ 转发,并借此连续多天登上 Github Trend 第一名。
如果这是推广的话,这无疑是相当成功的。
各位师傅有啥其他见解欢迎👏🏻和我讨论。