 夜雨聆风
夜雨聆风





从你说出一句话到 AI 回答——大语言模型是怎么"猜"出下一个词的?
读完这篇,你会知道LLM从输入到输出的完整链路——大语言模型的每一个零件都在为”预测下一个词”服务。后续的系列文章会逐一展开每个环节的细节。
先抛一个问题
你在AI Agent 里输入了一句话:
“今天天气真好,我想去”
然后 AI 接上了:”公园散步。”
它怎么知道该接”公园散步”而不是”银行贷款”?
这不是魔法,也不是它在”思考”。它的做法其实极其简单——从所有可能的词里,选一个最”顺”的。
但”顺”怎么判断?这就是整篇文章要回答的问题。
一句话概括大语言模型
大语言模型(LLM)做的事情只有一件:给定前面的文字,预测下一个最可能的词。
就这么简单。
但”简单”和”容易”是两回事。要做到这个预测足够准确,需要一整套精密的系统。我们来拆开看看。
第一步:把文字切成”词片”——Tokenization
计算机不认识文字,它只认数字。所以第一件事就是:把你的输入变成它能处理的东西。
但这里有个问题——不能一个字一个字切,也不能一个词一个词切。
一个字太碎了。”葡”和”萄”分开就没意义了。一个词又太死板了。”unbelievable”这种词,英文里无穷多,你不可能把所有词都提前存好。
所以 LLM 用了一种折中方案:切成”词元“(Token)。
常见的组合就整块切,不常见的就拆成小块。
举个例子,”今天天气真好”可能被切成:
今 | 天 | 天 | 气 | 真 | 好
“unbelievable” 可能被切成:
un | believe | able
切法不是随意的,是模型训练之前就定好的。每种模型有自己的”刀法”(tokenizer),比如 GPT-4 用的叫 tiktoken,Claude 用的叫 tokenizer 也各有不同。
关键认知:Token(中文叫词元) 是模型处理文字的最小单位。你看到的”字数”和模型看到的”Token 数”不一样——通常 1 个汉字约等于 1-2 个 Token,1 个英文单词约等于 1-1.5 个 Token。
这一步的意义:把连续的文字流变成一个离散的 Token 序列,就像把一条绳子剪成一截一截的珠子,方便后续逐个处理。
第二步:给每个 Token 贴上”身份证”——语义向量(Embedding)
切好 Token 之后,每个 Token 还是符号,计算机依然没法运算。我们需要把每个 Token 变成一串计算机认识的数字。
最朴素的想法:给每个 Token 编个号。Token #1 = 1,Token #2 = 2……
但这有个致命问题——编号大小没有意义。Token #3 和 Token #4 之间,并不比 Token #3 和 Token #999 更”接近”。
所以 LLM 用了一种更聪明的方式:语义向量(Word Embedding)。
给每个 Token 分配一个”坐标”,让意思相近的词在坐标空间里靠得近。
想象一个巨大的”语义地图”:
●“开心”和”高兴”住在隔壁
●“猫”和”狗”住在同一个小区
●“开心”和”猫”隔了十万八千里
每个 Token 会被映射成一个向量——就是一串数字,比如 4096 个数字。这 4096 个数字就像是这个 Token 在”语义空间”里的 GPS 坐标。
最经典的例子:
king – man + woman ≈ queen
“国王”减去”男人”加上”女人”,坐标刚好落在”女王”附近。这不是人为设计的,是模型自己学出来的。
关键认知:语义向量把离散的符号变成了连续的数字向量,而且让”语义相似”变成了”距离相近”。有了向量,数学运算才能上场。
这一步的意义:文字 → 数字,而且是有意义的数字——意思相近的词,数字也相近。
第三步:让每个词”看”到上下文——自注意力(Self-Attention)
语义向量有个问题:同一个词永远对应同一串数字。
“苹果手机”里的”苹果”和”吃了一个苹果”里的”苹果”,拿到的是同一个向量。但它们的含义完全不同。
怎么办?让每个词在理解自己之前,先环顾四周。
这就是自注意力机制(Self-Attention)——Transformer 的灵魂。
一个直觉理解
想象你在读一句话:
“小明把苹果放在桌子上,它很红。”
当你读到”它”的时候,你的大脑自动回看前面的内容,判断”它”指的是”苹果”而不是”桌子”或”小明”。
自注意力做的就是这件事——让每个 Token 根据上下文来调整自己的表示。
具体来说,每个 Token 会向其他所有 Token “提问”:
●“你跟我有关系吗?”
●“关系有多大?”
然后根据关系大小,把其他 Token 的信息按比例融合进来。
结果就是:经过自注意力之后,同样一个”苹果”Token:
●在”苹果手机”的上下文里,向量偏向”科技公司”
●在”吃了一个苹果”的上下文里,向量偏向”水果”
同一个词,不同语境,不同向量。 这就是”上下文嵌入”。
稍微多一点细节
自注意力的计算涉及三个角色:
|
角色 |
类比 |
作用 |
|
Query(查询) |
我在找什么 |
当前词发出”查询请求” |
|
Key(键) |
你是什么 |
其他词展示”身份标签” |
|
Value(值) |
我有什么信息 |
匹配后提供实际内容 |
想象你在图书馆找书:你心里有个”问题”(Query),每本书有”标签”(Key),你拿问题去和标签匹配,匹配度高的书,你认真读它的内容(Value)。
关键认知:自注意力让每个 Token 不再是孤立的,而是”眼里有全局”的。这是 Transformer 最大的创新——不需要一个字一个字顺序读,所有词可以同时看到彼此。
这一步的意义:静态的语义向量 → 动态的上下文嵌入。每个词的表示不再只取决于自己,还取决于它周围的所有词。
第四步:层层提炼——Transformer 的深层结构
一个自注意力层做了一次”环顾四周”。但一次不够。
就像你读一篇文章,读第一遍只抓大意,读第二遍能理解段落间的关系,读第三遍才能把握深层含义。
所以 Transformer 把同样的结构堆叠了很多层:
输入向量 → 自注意力(环顾四周) → 前馈网络(消化信息) → 自注意力(再环顾一次) → 前馈网络(再消化一次) → …… → (重复 N 层) → 输出向量
●GPT-2 有 12 层
●GPT-3 有 96 层
●… …
每一层都在做两件事:
1自注意力:让 Token 之间交换信息(横向沟通)
2前馈网络:让每个 Token 独立处理信息(纵向深挖)
还有一个巧妙的设计叫残差连接——每一层的输出不是替换输入,而是加在输入上面。信息可以从底层一路”穿层”到顶层,不会在中间丢失。
这一步的意义:多层堆叠让模型能捕捉从”词法”到”句法”到”语义”到”篇章逻辑”的不同层次的特征。正常情况下层数越多,理解越深。
第五步:从向量到词——”投票”选出下一个词
经过 N 层 Transformer 之后,我们拿到了一串深度加工过的向量。但我们需要的是一个词,不是一堆数字。
怎么做?
语言模型头(LM Head)
在 Transformer 的最后一层之后,接了一个语言模型头。它的工作很简单:
把最后一个位置的向量,映射回”词表”——变成一个覆盖所有可能 Token 的分数列表。
假设词表有 10 万个 Token,那这一步就输出 10 万个分数。每个分数代表”接下来是这个 Token 的可能性有多大”。
这个过程本质上就是一次大规模投票:
●“公园” 得了 8.5 分
●“家” 得了 7.2 分
●“银行” 得了 2.1 分
●“恐龙” 得了 -5.3 分
●……
从分数到概率——Softmax
原始分数可以是任意大小(正数、负数、很大、很小),需要变成”概率”——所有选项加起来等于 1。
这个转换用一个函数叫 Softmax:
把分数变成”百分比”,保持大小排序不变,但总和归一化。
比如:
|
Token |
原始分数 |
Softmax 后概率 |
|
公园 |
8.5 |
68% |
|
家 |
7.2 |
20% |
|
银行 |
2.1 |
8% |
|
恐龙 |
-5.3 |
0.01% |
|
… |
… |
… |
选哪个?——采样策略
有了概率分布,怎么选?
●贪心选择:永远选概率最高的。听起来合理,但模型会变得无聊且重复——每次同样的输入给出同样的输出。
●温度采样:给概率分布加个”温度”参数。温度高,选择更随机、更有创意;温度低,更保守、更确定。
●Top-K / Top-P:只在概率最高的 K 个或累积概率 P 内的候选词里选,砍掉尾部的不靠谱选项。
你可以理解为:模型不是”决定”下一个词是什么,而是”推荐”一个概率排行榜,然后按一定策略从中抽取。
这一步的意义:向量 → 分数 → 概率 → 选词。模型不是给唯一答案,而是给概率分布。生成过程的随机性就来自采样策略。
第六步:一个词一个词往外蹦——自回归生成
选出了第一个词之后呢?
把这个新词拼到输入里,再来一遍。
输入:”今天天气真好,我想去” → 预测:”公园” 输入:”今天天气真好,我想去公园” → 预测:”散步” 输入:”今天天气真好,我想去公园散步” → 预测:”。” 输入:”今天天气真好,我想去公园散步。” → 预测:<结束>
这就是自回归生成(Autoregressive Generation)——模型的输出变成下一步的输入,像多米诺骨牌一样一个推一个。
这也解释了为什么大模型有时会”一本正经地胡说八道”——一旦某一步选错了一个不太合适的词,后续的所有预测都建立在错误的基础上,错误会累积。
这一步的意义:生成是逐步的、串行的。每一步的输出影响下一步的输入。这也是为什么长文本容易”跑偏”。
完整流程:一张图串联所有环节
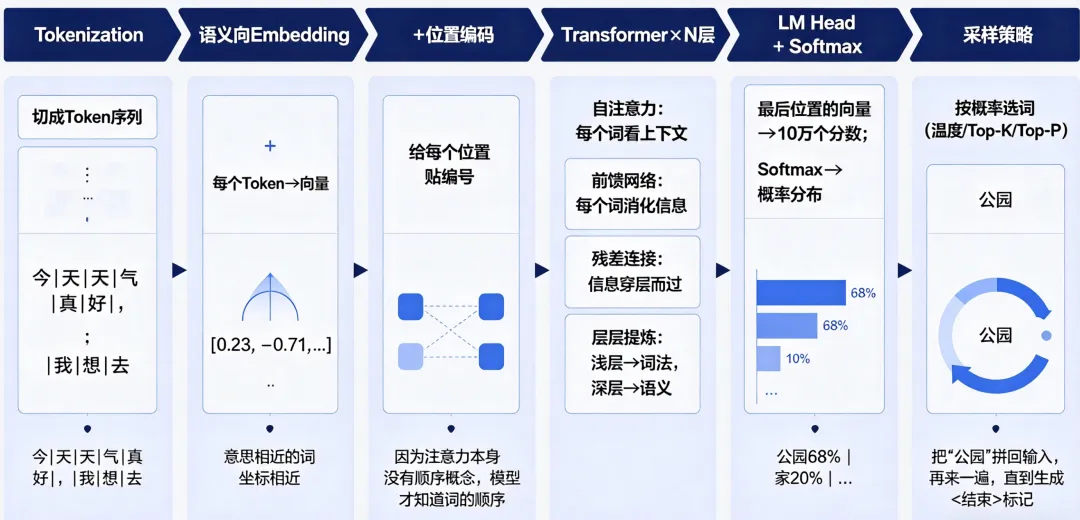
但它怎么知道”公园”比”银行”更合适?——训练
上面讲的是模型使用时的流程(推理阶段)。但模型凭什么知道”天气真好想去公园”比”天气真好想去银行”更合理?
因为它读过海量的文本。
训练的过程,说起来非常朴素:
1收集海量文本(网页、书籍、对话……)
2遮住某个位置后面的词
3让模型猜被遮住的词是什么
4猜对了就奖励(损失小),猜错了就调整(损失大)
5数万亿次重复
本质上就是:做了亿万道完形填空题,填到几乎不会出错。
这个简单到不可思议的训练目标——预测下一个词——为什么能产生如此强大的能力?
因为要准确预测下一个词,模型必须学会:
●语法(否则句子不通顺)
●常识(否则说外行话)
●逻辑(否则推理出矛盾)
●事实(否则给出错误信息)
●甚至一定的”心智模型”(否则无法理解对话中的意图)
不是有人教它这些,而是不学会这些,就做不对这道填空题。
🔑 训练的哲学:简单的目标 + 海量的数据 + 巨大的模型 = 涌现出复杂的能力。(训练的详细讲解见系列第 8-9 篇)
三个关键认知
回顾全文,你只需记住三件事:
1. LLM 只做一件事:预测下一个词
不管它看起来多聪明,底层都是一个”下一个词预测器”。写诗、写代码、回答问题——都是一词一词”接”出来的。
2. 所有环节都在为这件事服务
●Tokenization:把文字变成可处理的最小单元
●词嵌入:让文字变成有意义的数字
●自注意力:让每个词理解上下文
●多层 Transformer:层层提炼语义
●LM Head + Softmax:把提炼后的向量变成概率
每个零件都有明确的功能,去掉任何一个,预测都不准。
3. 能力来自训练,不是来自设计
没有人告诉模型”语法是什么””逻辑是什么”。这些能力是从海量数据中”涌现”出来的——因为不学会就做不对填空题。
💡 思考题
如果模型只是”预测下一个最可能的词”,那它有可能产生真正”创造性”的回答吗?还是说它永远只能重复训练数据里见过的模式?
欢迎在评论区分享你的想法 👇