 夜雨聆风
夜雨聆风





AI顶会ICLR解读 | 好的推理模型,是怎么被“喂”出来的
一、论文信息
本篇推文解读的文章来自国际学习表征会议(International Conference on Learning Representations, ICLR)。ICLR是AI领域的重要会议,长期关注表示学习、大模型训练、泛化与推理能力等问题。这篇论文发表于 ICLR 2026。
-
英文题目: Data Recipes for Reasoning Models
-
中文题目 :推理模型的数据配方
-
作者 :Etash Guha,Ryan Marten,Sedrick Keh,Negin Raoof 等
-
来源 :OpenReview
二、背景与贡献
这篇文章讨论的不是单纯如何把模型做大,而是一个更基础的问题:推理模型(reasoning models)到底应该喂什么样的数据。近一段时间,数学、代码、科学等任务上的推理模型进步很快,但很多领先模型依赖专有数据,外界往往只能看到结果,看不到训练配方。于是,开源社区虽然能复现部分后训练流程,却很难判断真正起作用的是教师模型、题目来源、过滤策略,还是数据规模本身。
论文作者把推理模型训练视为一个数据工程问题,用受控消融去拆开每个环节的贡献。他们围绕题目来源、题目混合、题目过滤、重复采样、答案过滤、教师模型选择六个步骤,做了超过一千次实验,试图回答什么样的数据更能教会模型推理。
第一,文章给出了一套可复现的开源数据配方。 作者据此构建了 OpenThoughts3-1.2M,并训练出 OpenThinker3-7B。
第二,文章提供了几条很有价值的经验规律。 例如,高评测分数的模型不一定是好教师;少量高质量题源往往优于大量异质题源;长推理链不仅是生成现象,也会影响训练后的能力形成。
第三,文章把“数据配方”从经验判断推进到了实验比较。 这使得后续研究可以在统一框架下继续扩展,而不是只依赖零散的工程直觉。
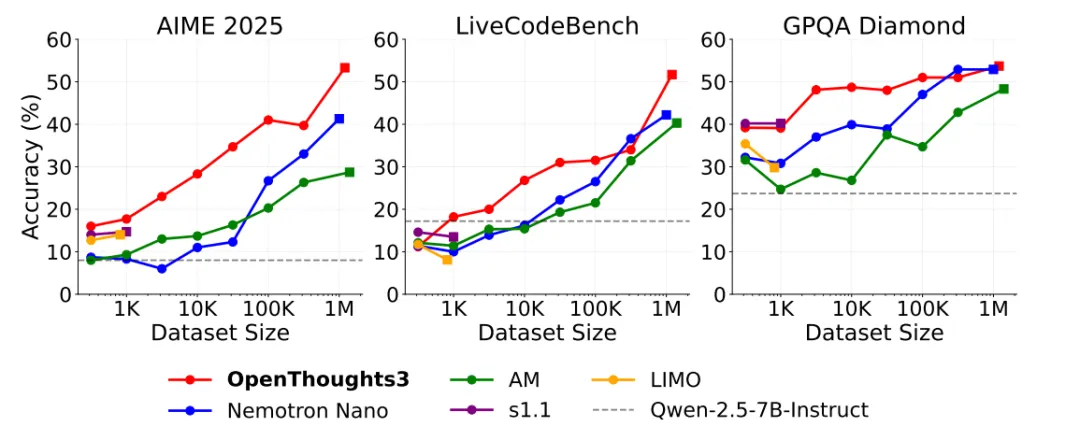
三、主要结论
论文的结论主要有三个。
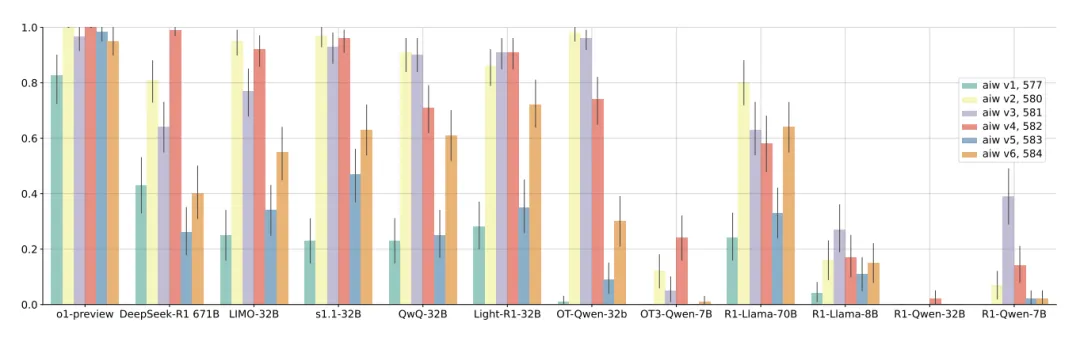
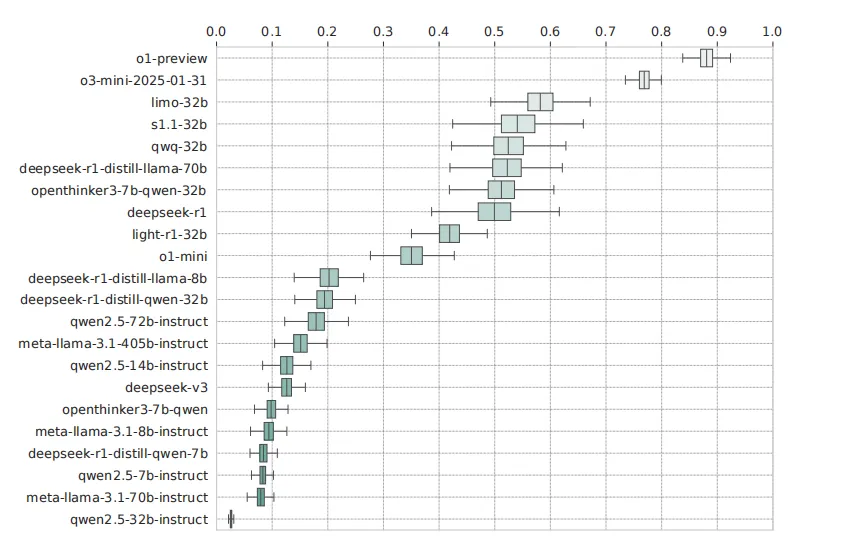
首先,基于 OpenThoughts3-1.2M 训练得到的 OpenThinker3-7B 在开源数据条件下取得了很强的结果。论文报告其在 AIME 2025 上达到 ,在 LiveCodeBench 06/24-01/25 上达到 ,在 GPQA Diamond 上达到 ,相较 DeepSeek-R1-Distill-Qwen-7B 分别提升 、、 个百分点。
其次,真正重要的并不是“更多步骤”,而是“更有效的步骤”。作者发现,题目来源选择、题目过滤、教师模型选择,对最终性能提升最明显。相反,很多看上去合理的答案过滤与验证策略,并没有稳定收益。
最后,推理数据的价值不只是答案正确,还包括推理过程本身。删除自反思内容,或显著压缩长推理链,都会明显降低下游表现。这说明训练中的长链推理并非冗余噪声,而是能力形成的一部分。
四、方法与技术细节
这篇文章的方法重点不在提出新的主干网络,而在构建一条面向监督微调(supervised finetuning, SFT)的数据管线。最终模型 OpenThinker3-7B 仍然建立在 Qwen2.5-7B-Instruct 之上,也就是说,模型结构本身基本沿用现有指令模型框架,关键创新主要体现在数据生成与筛选流程。
整条管线可以概括为六步:题目来源选择,题目混合,题目过滤,教师生成多答案,答案过滤,教师模型选择。作者在每一步都固定其余条件,只改变当前策略,再用统一的训练与评测设置比较效果。这种设计使得“哪个环节真正有效”能够被单独识别出来。
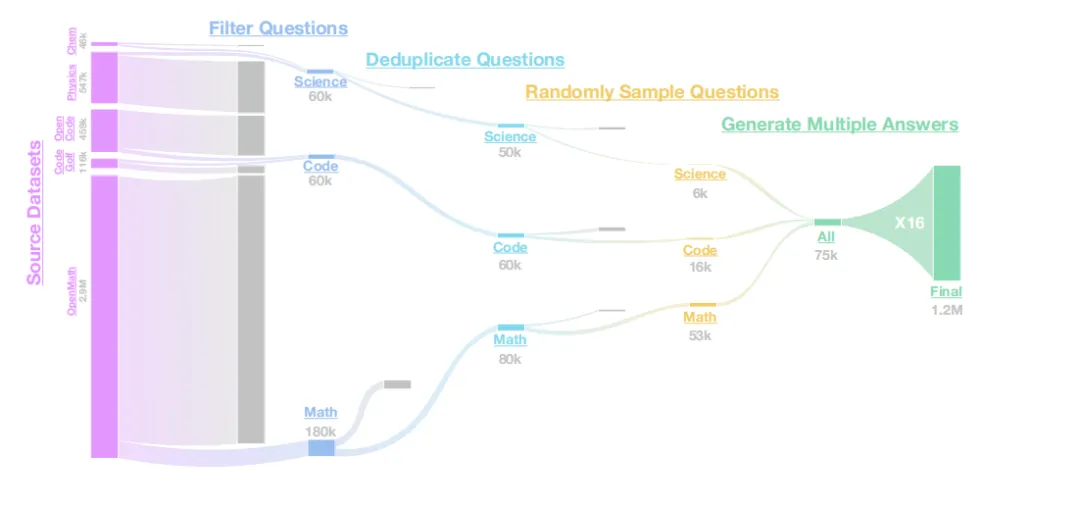
在数据规模上,作者先用 条样本作为中等实验尺度开展大规模消融,然后把最终优选配方扩展到 百万条样本,其中数学数据 条,代码数据 条,科学数据 条。流程如下图所示。

在训练细节上,作者使用 LlamaFactory 与 DeepSpeed v3。不同数据规模对应不同超参数组。总体上,学习率从 到 ,批量大小从 到 ,训练轮数从 到 不等。大规模训练时使用 packing,小中规模训练时不使用 packing。
在评测上,作者统一使用 Evalchemy,覆盖数学、代码、科学三类任务,并额外保留 AIME 2025、HMMT、HLE、LiveCodeBench 06/24-01/25 作为保留测试集,以减少配方搜索对最终结论的污染。
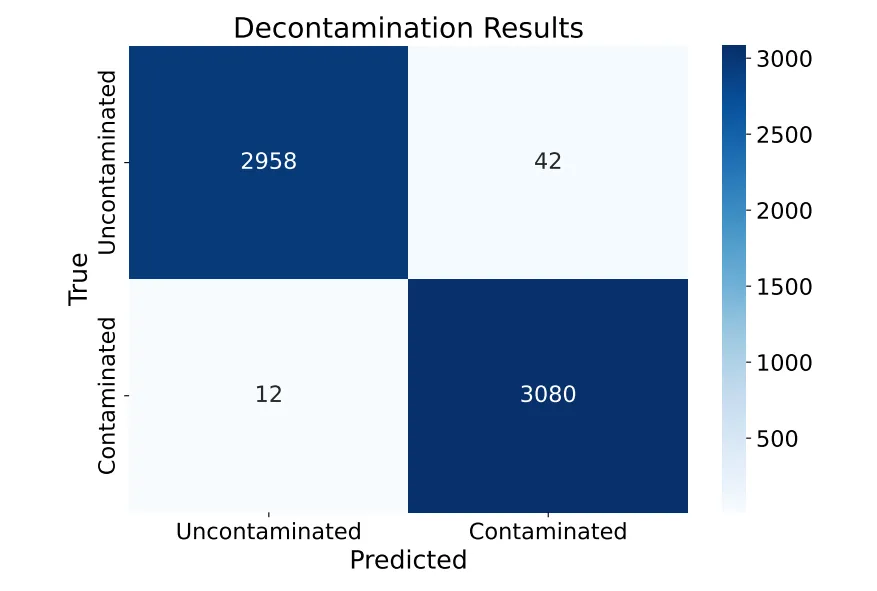
文章中较明确的公式主要出现在去污染(decontamination)部分。作者用最长公共子序列定义归一化 Indel 相似度:
当该相似度达到 时,样本会被视为可能污染。除此之外,作者还加入基于 元词片段的重叠判断。两种规则任意命中,其训练样本即被剔除。这个去污染模块的目的很明确,就是尽量避免训练数据与评测题目重叠,从而使后续消融更可信。
五、消融试验与数据生成
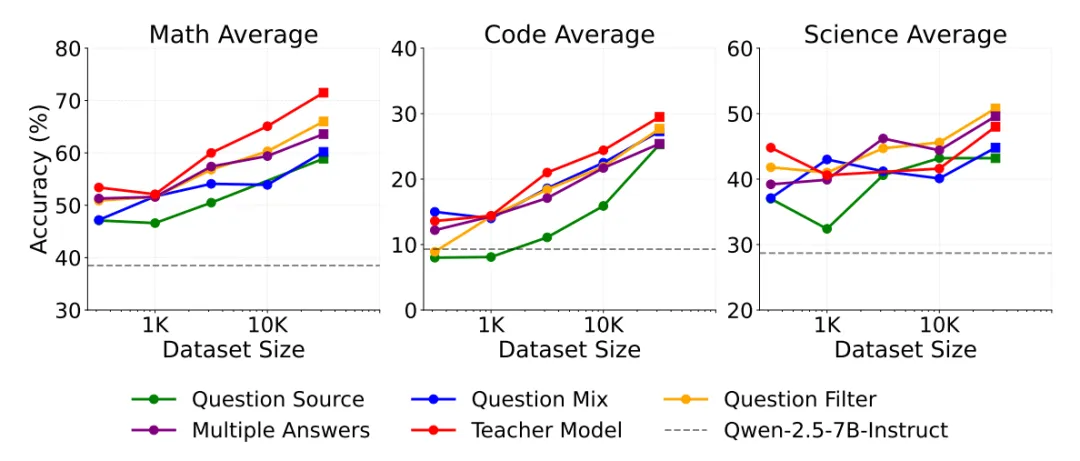
题目来源。 数学、代码、科学数据质量差异很大。代码任务中,StackExchange CodeGolf 与 OpenCodeReasoning 表现最好;数学任务中,OpenMath-2-Math 与 NuminaMath-1.5 最优;科学任务中,StackExchange Physics 与 Organic Chemistry PDF Pipeline 较强。作者据此说明,题目的“源质量”本身就是决定性变量。
题目混合。 一个很重要的发现是,多来源混合并不总是更好。对代码域而言,取前 个题源比取前 个题源更优。作者因此认为,过度追求多样性,会引入更多低质量问题,稀释高质量样本的训练信号。
题目过滤。 传统的 fastText 与嵌入相似度过滤不如大模型辅助过滤。代码域最有效的是用 GPT-4o-mini 做难度打分,保留更难的问题。数学与科学域最有效的是响应长度过滤,也就是先让模型作答,再保留能引出更长回答的问题。这里反映出一个很有意思的经验:优质问题常常能“逼出”更长、更有结构的推理。
多答案采样与去重。 作者比较了不去重、模糊去重、精确去重,以及每题采样 次、 次、 次答案。最终方案是所有领域都采用每题 次答案采样,数学与科学使用精确去重,代码不去重。这个结论说明,答案多样性可以成为有效的扩展轴。
答案过滤。 这部分结果相当克制。无论是多数一致、最长答案、最短答案、英语过滤,还是 GPT 验证,都没有显著优于“不做过滤,直接用全部答案”的基线。因此最终管线放弃了答案过滤。
教师模型。 这是文章里最有启发性的结论之一。虽然 DeepSeek-R1 自身在若干评测上更强,但作为教师模型时,QwQ-32B 反而更有效。也就是说,好的教师不一定是分数最高的模型,而可能是更适合生成训练痕迹的模型。
长推理链。 作者进一步研究了压缩推理链的影响。若移除自反思片段,平均推理长度从 token 降到 token,平均性能下降 。若直接过滤掉长度超过 的样本,平均性能也会下降 。这说明长推理链与自反思内容在训练中具有明确作用。
扩展结论。 论文还指出,错误回答往往比正确回答更长,因此“最短答案”有时比“最长答案”更可靠。与此同时,蒸馏得到的推理模型虽然在总体性能上优于普通语言模型,但在结构保持不变的简单扰动测试中仍有明显波动,说明鲁棒泛化仍未解决。
六、我们的思考
这篇文章最值得借鉴的地方,是它把大模型训练中的“经验活”转化成了可以比较复核的问题。从统计学的观点来看,这里面有四个可能可以继续展开的方向。
其一,教师模型选择可以被视为一个统计决策问题。 当前做法主要靠下游效果回看。以后可以尝试建立教师特征、生成轨迹特征与学生提升之间的预测模型,做更系统的教师选择。
其二,数据配方搜索本质上接近实验设计。 哪些题目值得保留,哪些题目值得多次采样,完全可以引入更正式的效用函数与预算约束模型,用统计学习的方法做最优资源分配。
其三,去污染问题很适合与误差控制结合。 例如,可以把相似度阈值、词片段重叠规则与误判代价统一起来,讨论更稳健的阈值校准方法,使去污染不再只依赖经验阈值。