 夜雨聆风
夜雨聆风





告别天价账单!OpenClaw 记忆神器 QMD 深度实战指南
你是否经历过这样的绝望时刻:你的 AI 助手随着使用时间增长,回复越来越慢,从秒回变成“正在思考人生”;每次对话都在燃烧昂贵的 Token,月底账单让人心惊肉跳;聊着聊着,它突然“失忆”,忘了你半小时前说过的关键信息。如果你正在使用 OpenClaw 或类似的 AI Agent 框架,这些问题可能源于同一个“性能杀手”——上下文爆炸。
今天,我们就来深度剖析一个能彻底解决这些痛点的“神级技能”:QMD (Quantum Memory Database)。配置好它,你的 AI 将拥有“最强大脑”,同时成本直降 90% 以上。
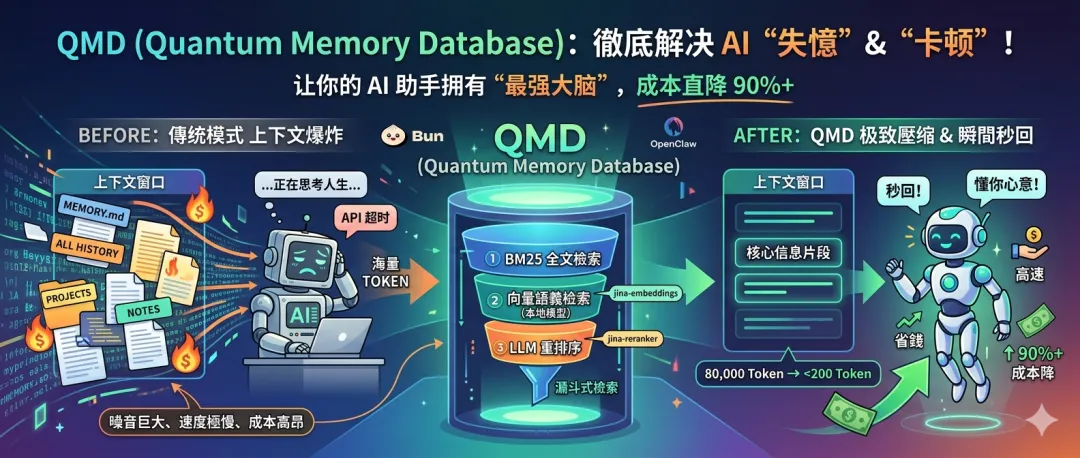
🧐 为什么你的 AI 越聊越“蠢”?在介绍 QMD 之前,我们需要先理解问题的根源。传统的 AI 记忆管理方式非常“暴力”:它会把所有的历史聊天记录、笔记文件(如 MEMORY.md )一股脑地塞进上下文窗口。
-
噪音巨大:当你问“上周那个项目的方案是什么?”时,AI 不需要回顾你三年前聊过的“今晚吃什么”,但传统模式会把这些无关信息全部加载。
-
成本高昂:大模型的推理时间与输入 Token 数量成正比。输入 10 万字和输入 1 千字,成本相差百倍。
-
速度极慢:处理海量上下文会导致 API 响应超时,甚至直接崩溃。
QMD 的核心逻辑是:先检索,后推理。它就像一个极其高效的图书管理员。当你提问时,它不会把整个图书馆(所有记忆文件)搬到你面前,而是迅速去书架上找到最相关的那几页纸,递给你。⚡️ QMD 是什么?它凭什么这么快?QMD 是一个运行在你本地的语义搜索引擎。它不是简单的关键词匹配,而是基于向量数据库技术。核心优势
-
完全本地化:模型下载后,断网也能跑,数据隐私安全。
-
语义理解:它能理解“我想找那个红色的车”和“搜索红色汽车”是同一个意思。
-
极致压缩:它能将 8 万 Token 的上下文压缩到 200 Token 以内,只保留核心信息。
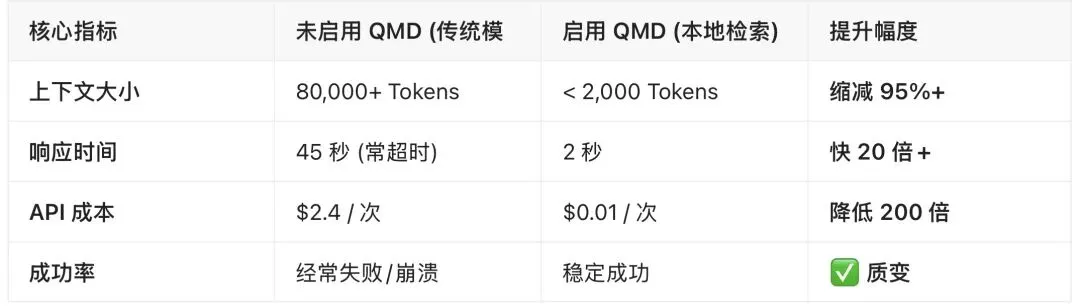
底层黑科技:三层混合搜索QMD 之所以快且准,是因为它采用了“漏斗式”的检索策略:1. BM25 全文检索:先通过关键词快速筛选出一批相关文档(速度快)。2. 向量语义检索:利用本地小模型(如 jina-embeddings )计算语义相似度,找出深层相关的片段(精度高)。3. LLM 重排序:最后用更精细的模型(如 jina-reranker )对结果进行二次排序,确保给到大模型的是最精准的答案。📉 实战数据:QMD 带来的改变根据实测数据,启用 QMD 前后的体验简直是“自行车与法拉利”的区别:
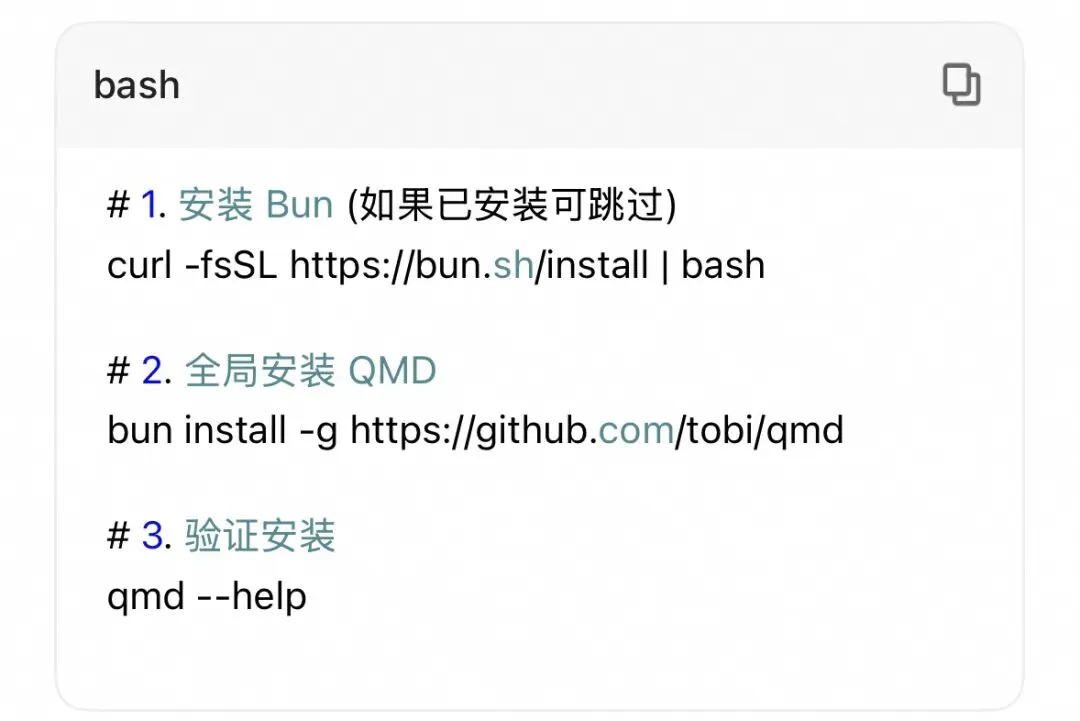
🛠️ 手把手教你配置 QMD别被技术名词吓到,配置 QMD 其实非常简单。只需三步,即可让 OpenClaw 焕发新生。第一步:安装 QMD你需要先安装 Bun 或 Node.js 环境。推荐使用 Bun,速度更快。在终端执行以下命令:
第二步:修改 OpenClaw 配置
找到你的 OpenClaw 配置文件(通常在 ~/.openclaw/openclaw.json ),在 memory 字段中加入以下配置:

-
backend: 设置为 qmd 即可启用。
-
searchMode: 推荐 query (混合搜索),兼顾关键词和语义。
-
paths: 这里填入你想让 AI 记忆的文件夹路径。
第三步:初始化索引配置改好后,需要手动把现有的笔记“喂”给 QMD 建立索引。

重启 OpenClaw,配置即刻生效!💡 进阶技巧:记忆文件“8层架构”为了让 QMD 发挥最大效能,建议配合记忆文件拆分策略。不要把鸡蛋放在一个篮子里(比如巨大的 MEMORY.md )。推荐结构:
-
SOUL.md:存放核心人设、原则(<1KB)。
-
USER.md:存放用户偏好、习惯。
-
memory/YYYY-MM-DD.md:按日期存放日常碎片记录。
-
projects/:按项目分类的长期记忆。
为什么这样做?QMD 检索的是“片段”。如果文件拆分得越细,检索的颗粒度就越精准,AI 就越不容易“幻觉”。📌 结语在 AI 时代,“记忆”是第二大脑的核心资产。不要让你的 AI 助手因为臃肿的上下文而变得迟钝、昂贵。花 10 分钟配置 QMD,不仅是省钱,更是为了让它真正懂你,成为你不可或缺的得力助手。立即动手试试吧,体验那种“秒回”且“懂你”的快感!