 夜雨聆风
夜雨聆风





每天一个AI知识点:偏差-方差困境:模型的"理解力"与"泛化力"如何权衡?
偏差-方差困境:模型的”理解力”与”泛化力”如何权衡?
一、一个射箭手的比喻
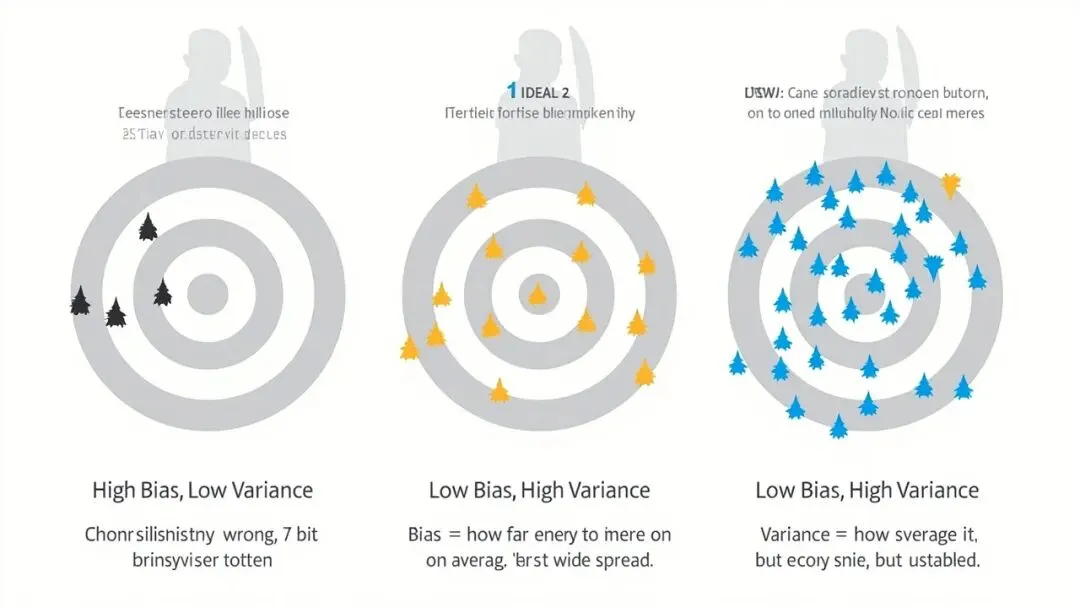
想象你是一位射箭手,目标是射中靶心。
第一种情况:你连续三箭都偏离靶心,但三箭之间距离很近——都偏左上方。这种情况叫”偏差大、方差小”——你瞄准的位置系统性地错了,但每次射击都很稳定。
第二种情况:你射出的箭分布很散,有的在靶心,有的飞到墙上,还有的差点射到观众席。但平均值恰好在靶心附近。这种情况叫”偏差小、方差大”——平均来看是准的,但每次射击都充满不确定性。
第三种情况:你射出的箭完美集中在靶心,每次都几乎一样。这是理想状态——”偏差小、方差小”。
第四种情况:又偏又散,每一箭都不知道会飞到哪里去。这是”偏差大、方差大”——最糟糕的情况。
机器学习中的偏差和方差,对应的正是这个比喻。
二、理解偏差与方差
2.1 偏差:系统性错误
**偏差(Bias)**衡量的是模型预测的平均值与真实值之间的差距。高偏差意味着模型从根本上就”理解”错了——它学习到的是错误的规律。
偏差可以类比为”方向感错误”。不管你怎么训练,偏差大的模型总是会系统性地出错。就像如果你的指南针永远指向东偏北30度,那你永远到不了真正的北方。
导致高偏差的原因通常是模型太简单——用过于简单的模型去拟合复杂的数据,就像用直线去拟合抛物线,无论怎么调整参数都跟不上数据的真实模式。
2.2 方差:对数据的敏感度
**方差(Variance)**衡量的是模型预测值在不同训练集上的变化程度。高方差意味着模型对训练数据太敏感——训练数据稍微变化一点,模型的预测就会大幅波动。
方差可以类比为”状态不稳定”。方差大的模型就像一个情绪化的人,同一件事在不同心情下会有截然不同的反应。模型从不同的训练子集上学到的”规律”差异很大,说明它可能把数据中的噪声也当成规律了。
导致高方差的原因通常是模型太复杂——参数过多,以至于能够”记住”每个训练样本的细节,但这些细节在不同样本之间差异很大。
2.3 目标:低偏差、低方差
理想情况下,我们希望模型既有低偏差(准确理解数据规律),又有低方差(稳定泛化到新数据)。这就是机器学习的终极目标。
然而现实往往不允许我们两者兼得——这就被称为偏差-方差困境(Bias-Variance Tradeoff)。
三、偏差-方差困境的本质
3.1 为什么两者难以兼得?
偏差和方差之所以存在权衡,是因为模型复杂度的选择。
模型复杂度低时(比如用线性回归拟合非线性数据),模型表达能力有限,不管怎么训练都跟不上数据的真实模式——高偏差。但正因为模型简单,它不会过度记忆训练数据的细节,所以对训练集的变化不那么敏感——低方差。
模型复杂度提高后,模型能够更好地拟合训练数据,偏差降低。但同时,模型的”记忆容量”增加了,它开始记住训练数据中的噪声,在不同训练子集上表现差异变大——方差增加。
3.2 误差分解
从数学上可以证明,模型的期望误差可以分解为:
期望误差 = 偏差² + 方差 + 不可约误差
不可约误差是由于数据本身的噪声产生的误差,无论模型多么完美都无法消除——比如标签本身可能有错误,或者数据采集存在测量误差。
偏差和方差是此消彼长的关系。当我们降低其中一个时,另一个往往会上升。我们的目标是找到两者的最佳平衡点,使得总和最小。
四、模型复杂度与偏差-方差
4.1 欠拟合区域
当模型太简单时:
-
训练误差:高(模型学不会训练数据) -
测试误差:高(模型泛化能力差) -
问题根源:高偏差
解决方案:增加模型复杂度——增加网络层数、增加神经元、使用更复杂的模型架构。
4.2 过拟合区域
当模型太复杂时:
-
训练误差:低(模型完美记住训练数据) -
测试误差:高(在新数据上表现差) -
问题根源:高方差
解决方案:减少模型复杂度(但可能增加偏差)、增加训练数据、使用正则化。
4.3 最优复杂度
存在一个最优模型复杂度,使得测试误差最小。在这个点附近,偏差和方差达到最佳平衡。
这个最优复杂度不是固定的——它取决于训练数据的数量和质量。数据越多、噪声越少,最优复杂度就可以越高。
五、如何诊断偏差-方差问题?
5.1 学习曲线分析
学习曲线是诊断偏差-方差问题的利器。
高偏差的特征:
-
训练误差和验证误差都高,且两者趋于接近 -
增加训练数据无法改善(因为问题的根源是模型太简单)
高方差的特征:
-
训练误差低,但验证误差高,两者差距大 -
增加训练数据可以改善(因为更多数据帮助模型学到更准确的规律)
5.2 实践中的判断标准
| 情况 | 训练误差 | 验证误差 | 问题诊断 |
|---|---|---|---|
| 欠拟合 | 高 | 高 | 高偏差 |
| 过拟合 | 低 | 高 | 高方差 |
| 正常 | 低 | 低 | 偏差方差平衡 |
| 难得一见 | 高 | 低 | 数据或标注有问题 |
5.3 网格搜索与交叉验证
通过在验证集上系统地测试不同的模型配置(超参数),可以找到偏差-方差最优平衡点。
K折交叉验证尤其有价值:它提供了多个验证误差的估计,帮助我们更可靠地评估模型的真实泛化能力。
六、解决偏差-方差问题的策略
6.1 解决高偏差(欠拟合)
增加模型复杂度:更多的层、更多的神经元、更强大的模型架构。
增加特征:通过特征工程创造更多有意义的输入特征,帮助模型更好地理解数据。
减少正则化强度:如果正则化过度抑制了模型的学习能力,适当降低正则化参数。
训练更长时间:有时候模型只是没训练够,增加训练轮数或调整学习率可以让模型收敛到更好的解。
6.2 解决高方差(过拟合)
增加训练数据:最直接的方法,数据越多,模型越能学到真正的规律而不是噪声。
减少模型复杂度:降低模型参数数量或层数,使模型”记忆能力”减弱。
增加正则化:L2正则化、Dropout等方法可以有效约束模型的复杂度。
早停:在验证误差开始上升时停止训练,防止过度拟合。
特征选择:移除不相关的特征,减少模型的”记忆负担”。
6.3 集成方法
集成学习是同时处理偏差和方差的利器。
Bagging(如随机森林):通过训练多个模型并取平均,降低方差而不过度增加偏差。
Boosting(如XGBoost):通过串联逐步改进的模型,降低偏差而不过度增加方差。
模型堆叠:用多个模型的预测作为输入,训练一个元模型来找到最佳组合。
七、深度学习时代的偏差-方差
7.1 深度学习的新视角
有趣的是,深度学习在某些场景下改变了传统的偏差-方差认识。
传统观点认为,非常深的网络应该会过拟合(高方差)。但实践中,研究者发现足够大的网络在适当的正则化下,反而比浅层网络表现更好。
这被称为双重下降现象(Double Descent):随着模型规模增大,测试误差先下降(偏差降低),然后过拟合(方差上升),最后再次下降(模型变得非常大时,泛化能力反而提升)。
这个现象的成因仍在研究中,可能与深度网络的优化动态和隐式正则化有关。
7.2 迁移学习的优势
迁移学习是应对偏差-方差困境的优雅方案。
通过在大量数据上预训练一个大型模型,然后在特定任务的小数据集上微调——我们可以利用预训练模型已经学到的低偏差、低方差的表示,只用很少的特定任务数据就能达到很好效果。
结语
偏差-方差困境是机器学习的核心挑战之一。它提醒我们:模型不是越复杂越好,也不是越简单越好——关键在于找到与数据匹配的”恰到好处”的复杂度。
理解偏差与方差的权衡,不只是理论上的要求,更直接关系到实际工作中的模型选择和调参决策。
下次当你发现模型表现不佳时,不妨先问自己:问题是偏差太高(模型没学明白),还是方差太高(模型太敏感)?答案不同,解决方案也完全不同。
✨如果你觉得这篇文章不错,别忘了点赞、在看、转发给更多需要的小伙伴哦!我们下期再见!🌸