 夜雨聆风
夜雨聆风





别再往 AI 嘴里塞 10 万行 JSON 了:企业级上下文工程落地指南
📖 阅读约 15 分钟 · 2808 字
从 Prompt Engineering 到 Context Engineering,企业 Agent 的核心挑战不是模型不够聪明,而是你喂给它的上下文太脏、太多、太乱。
你用 ChatGPT 写过周报,用 Claude 改过代码,也许还用 Cursor 生成过测试用例。这些个人场景里,上下文管理几乎不是问题——你贴一段文字,AI 就能理解并回复。
但当你试图在企业内部复制这种体验时,情况就完全不同了。
第一个差异是接口层面的。 个人场景里,你调的是一个通用 Chat API,输入是自然语言,输出也是自然语言。企业场景里,你的 Agent 要对接 CRM、ERP、工单系统、交易平台、日志服务、审批流……每个系统都有自己的 API,返回的数据格式各不相同,甚至同一个字段在不同系统里含义也不一样。
第二个差异是数据量级。 个人场景里,你给 AI 的上下文也许是一篇几千字的文章。企业场景里,一次 Tool Call 可能就返回几千行 JSON:上百个字段的客户标签、三个月的交易流水、一整条审批链……全部塞进上下文窗口。
这不是细节问题,这是根本性的架构差异。你的 Agent 之所以”不好用”,大概率不是模型太笨,而是你喂给它的上下文太脏、太多、太乱了。
2025 年 6 月,Andrej Karpathy 在一条推文里把”上下文工程”做了一个类比:LLM 是 CPU,上下文窗口就是 RAM。就像操作系统要精心管理哪些数据留在内存里一样,Agent 系统最关键的工程工作,不是调 prompt,而是管理上下文。
Cognition(Devin 背后的公司)在实战中得出了同样的结论:“Context Engineering 实际上是构建 AI Agent 的工程师最核心的工作。”
但大多数讨论还停留在”科普层”,谈的是个人助手怎么写 prompt。今天我想聊点不一样的:在企业生产环境里,面对结构化数据和复杂系统集成,上下文工程到底怎么落地?
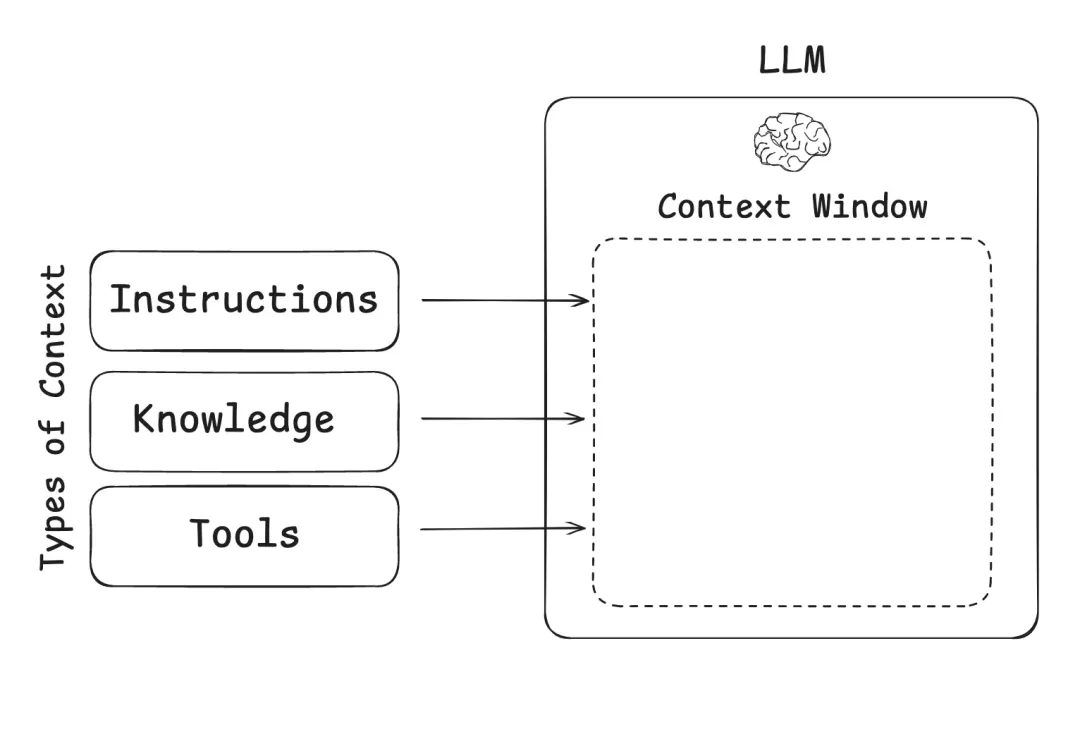
>先搞清楚:上下文工程管什么?
LangChain 团队在最近一篇深度博文中,把上下文工程的核心策略归纳为四个动作:
| 策略 | 一句话解释 | 类比 |
|---|---|---|
| Write(写入) | 把信息存到上下文窗口之外,留待将来使用 | 做笔记 |
| Select(选取) | 按需把相关信息拉进上下文窗口 | 查笔记 |
| Compress(压缩) | 只保留当前任务必需的 token | 划重点 |
| Isolate(隔离) | 把上下文拆分到不同 Agent 或模块 | 分工合作 |
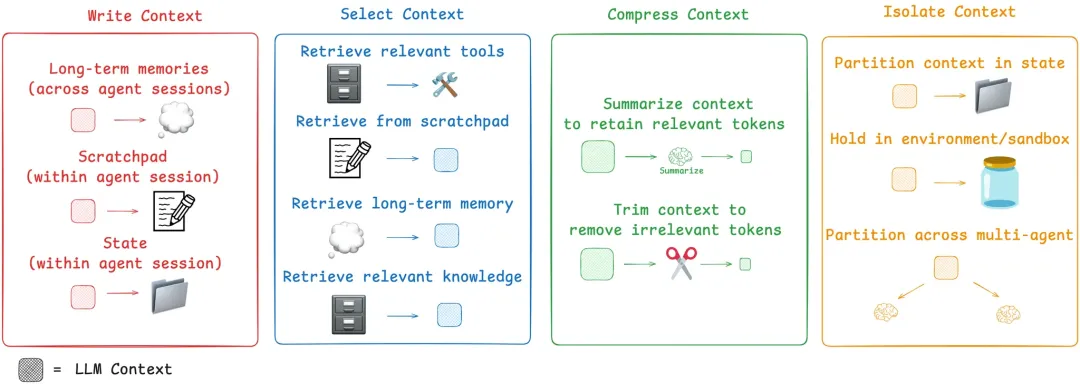
这四个策略已经在个人开发工具中被充分验证:
- Claude Code 用
CLAUDE.md文件做”程序性记忆(Procedural Memory)”,每次启动时自动读取,相当于 Write + Select - Claude Code 的 auto-compact 功能在上下文窗口使用率超过 95% 时自动触发摘要,这就是 Compress
- Anthropic Research 用多 Agent 架构做上下文隔离,结果比单 Agent 提升了 90.2% 的表现
但这些产品面对的是代码文件和自然语言对话——结构相对统一,上下文相对干净。企业场景的挑战完全不同:你面对的是几十个异构系统、成千上万个结构化字段、以及跨系统的语义冲突。
那这四个策略在企业场景里该怎么落地?
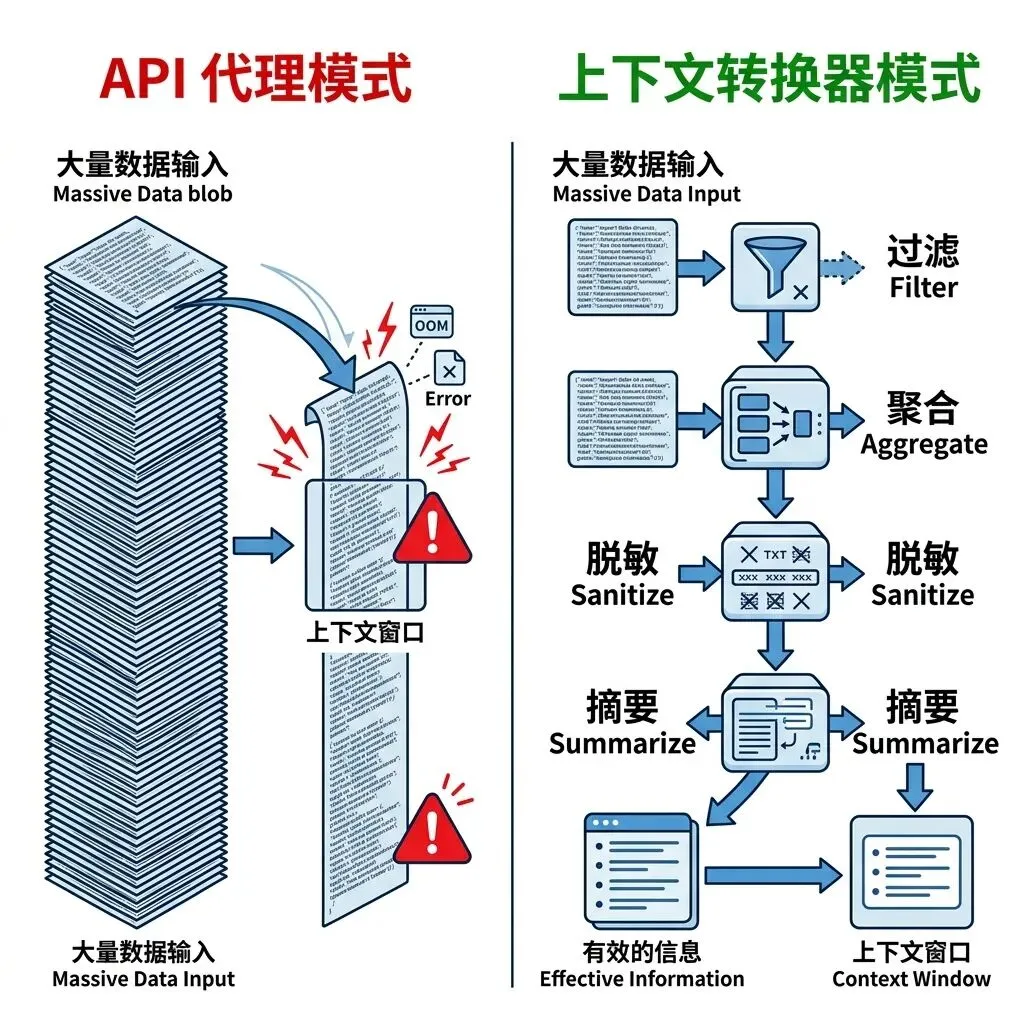
>企业最大的坑:你的 Tool 是”API 代理”还是”上下文转换器”?
企业系统的一个典型错误做法:让一个 Tool 直接返回 CRM、ERP、工单、交易、日志、审批流的完整 JSON,然后指望模型自己在几千行、几十个字段里找重点。
这不叫上下文工程,这叫上下文暴力灌注。
Drew Breunig 在《How Long Contexts Fail》一文中总结了四种上下文失败模式,几乎条条戳中企业场景的痛点:
| 失败模式 | 企业场景 |
|---|---|
| Context Poisoning(投毒) | 前一轮工具调用返回了脏数据,模型在后续决策中一路错下去 |
| Context Distraction(分心) | 10 万行 ERP JSON 淹没了真正的任务指令 |
| Context Confusion(混淆) | 来自不同系统的同名字段含义不同,模型无法分辨 |
| Context Clash(冲突) | CRM 说客户是”活跃”,工单系统说同一客户”已流失” |
正确的做法,是把 Tool 从”API 代理”改造成”上下文转换器”。
什么意思?看这个对比:
❌ API 代理模式(错误)
Tool: get_customer_data(customer_id="C-12345")
返回: {完整 JSON, 847 行, 63 个字段, 包含所有历史交易记录}
✅ 上下文转换器模式(正确)
Tool: get_customer_context(customer_id="C-12345")
返回:
summary: "C-12345 是制造业头部客户,月均交易额 ¥120万,
近3个月环比下降18%"
anomalies: ["最近一次投诉未关闭(工单#W-789)",
"账期已超期15天"]
key_metrics: {mrr: 1200000, churn_risk: "medium", nps: 67}
evidence: ["交易流水聚合自 ERP.transactions",
"投诉状态来自 CRM.tickets"]
drill_down: "如需详情可调用 get_customer_detail(
customer_id, section='transactions')"原始结果留在数据库里。模型拿到的是:聚合指标 + 异常摘要 + 少量代表性记录 + 字段级证据 + 结果引用。
这个思路直接映射到 LangChain 的四策略:
- Write:原始数据存在数据库/数据仓库,不进上下文窗口
- Select:只拉取聚合后的关键指标和异常
- Compress:从 847 行 JSON 压缩到 5 行摘要
- Isolate:不同类型的数据查询由不同的子 Agent 负责
这就是 Claude Code 的”按需读取”模式在企业数据上的镜像:Claude Code 不会把整个代码仓库塞进上下文窗口,它通过 grep、find、cat 按需读取文件片段。企业数据也应该一样——按需钻取,而不是全量灌入。
>上下文窗口不是”信息容器”,是”工作台”
理解了”上下文转换器”之后,还需要转变一个认知:上下文窗口不是一个你往里塞东西的容器,而是一个你在上面组装解决方案的工作台。
LangChain 在 Deep Agents 文档中把上下文分为两层:
- 1. Startup Input Context(启动输入):系统提示词、技能定义、记忆、工具描述——这些在 Agent 启动时就加载好,类似”把工具摆上工作台”
- 2. Runtime Context(运行时上下文):工具调用返回值、中间推理结果——这些在执行过程中动态生成,类似”在工作台上加工材料”
在企业场景中,这个分层的实际操作是:
启动层(一次性加载):
- 企业特定的业务术语表(NPS、MRR、ARR 的定义)
- 部门级的处理规则(”客户投诉超过 3 天未响应需升级”)
- 可用工具的描述(但不是工具返回的数据)
运行时层(按需注入):
- 当前任务涉及的客户摘要(由”上下文转换器”生成)
- 上一步操作的结果摘要(不是原始返回值)
- 异常和需要人工干预的标记

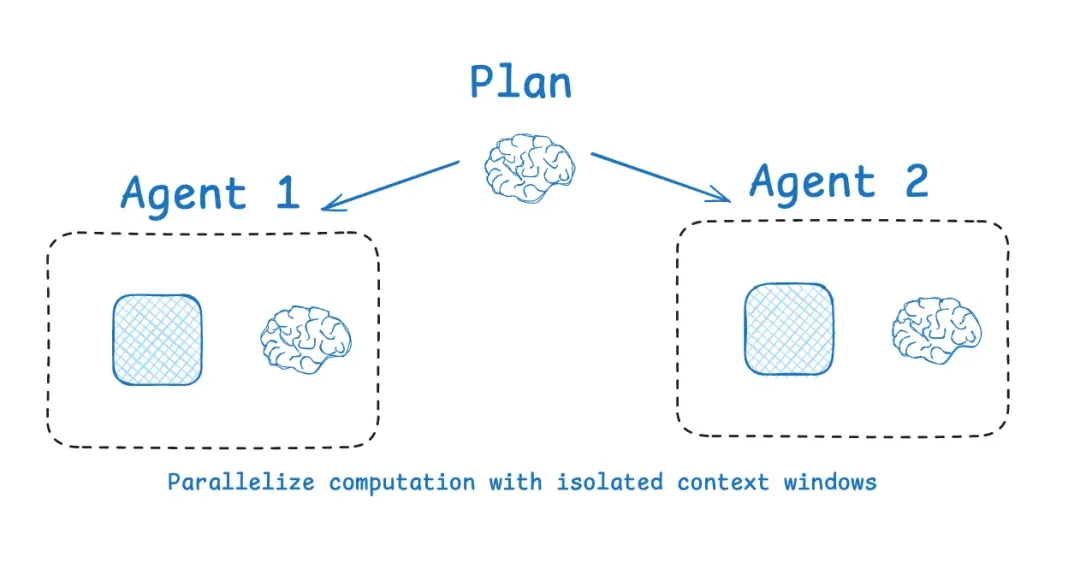
>子 Agent 隔离:企业版”分工合作”
Anthropic 的 Research 系统用多 Agent 架构实现上下文隔离,效果很显著。但他们也坦言:多 Agent 架构的 token 消耗是单 Agent 的 15 倍。
Cognition 的 Walden 在《Don’t Build Multi-Agents》一文中提出了一个更务实的观点:
大多数情况下,单线程线性 Agent 就够了。真正需要多 Agent 的场景是上下文窗口装不下了。
他提出了两条核心原则:
- 1. 共享上下文:每个 Agent 的每个行动,都应该能看到系统中其他部分做出的所有相关决策
- 2. 行动携带隐含决策:Agent A 做的事情可能与 Agent B 的假设冲突
在企业场景中,子 Agent 隔离的合理用法是:
主 Agent(编排层)
├── 子 Agent A:查询 CRM 客户数据 → 返回结构化摘要
├── 子 Agent B:查询 ERP 交易数据 → 返回聚合指标
├── 子 Agent C:查询工单系统 → 返回异常清单
└── 主 Agent:汇总三个子 Agent 的结果,生成决策建议每个子 Agent 有自己独立的上下文窗口,只关注自己负责的数据源。主 Agent 不需要看到原始数据,它只看到”精炼后的结论”。
这里的关键设计决策是:子 Agent 输出到文件系统或外部存储,而不是全部通过消息传递。 Anthropic 在博客中明确提到这一点——让子 Agent 把工作成果写入外部系统,只传回轻量级引用,既避免了信息在多层传递中失真,也减少了 token 开销。
>三条落地建议
如果你现在正在企业内部构建 Agent,以下是三条可以立即执行的建议:
1. 审计你的 Tool 返回值
去看看你每个 Tool Call 实际返回了多少 token。如果超过 2000 token,就该考虑加一层”上下文转换”——在 Tool 内部做聚合和摘要,而不是把原始数据丢给模型。
2. 用”数据流节点化”替代”一次性查询”
把上下文处理拆成可观测节点:查询 → 聚合 → 脱敏 → 摘要 → 验证 → 交付。每个节点有明确的输入输出 schema。这样做的好处是每一步都可以独立调试和优化,而不是在一个巨大的 prompt 里猜测模型哪里出了问题。
3. 建立上下文预算制度
给每个 Agent 会话设定 token 预算。Claude Code 的做法值得借鉴:它在 95% 使用率时自动触发压缩。企业 Agent 可以更激进一些——在 70% 时就开始压缩较早的对话历史,在 85% 时强制让子 Agent 接管新的数据查询任务。
“让模型管理任务,让系统管理上下文。”
上下文工程的本质,是承认一个事实:再聪明的模型,面对一个混乱的工作台也会手忙脚乱。企业 AI 的下一个突破点,不在于换一个更大的模型,而在于给现有模型一个更整洁、更精准、更可控的上下文环境。
你在企业内部构建 Agent 时,踩过哪些”上下文爆炸”的坑?评论区聊聊。
参考资料:
- 1. LangChain, Context Engineering, blog.langchain.com/context-engineering/
- 2. Cognition, Don’t Build Multi-Agents, cognition.ai/blog/dont-build-multi-agents
- 3. Anthropic, How we built a multi-agent research system, anthropic.com/engineering/built-multi-agent-research-system
- 4. Drew Breunig, How Long Contexts Fail, dbreunig.com
- 5. Andrej Karpathy, X/Twitter post on Context Engineering, 2025