 夜雨聆风
夜雨聆风





智能体AI时代:CPU角色定位的第一性原理分析

目录
第一章:负载本质拆解 Agentic AI对计算资源的重新排序
1. 从“黑盒推理”到“系统编排”
2. CPU关键能力的第一性排序
3. 延迟占比实证:消失的GPU主导权
第二章:计算架构实证 从GB300到Vera Rubin的解耦真相
1. 机架内比例的稳定性:营销幻觉与硬件现实
2. “资源解耦”的真实意图:独立Vera CPU机架的崛起
3. 数据中心作为计算单元:跨机架调度的“神经系统”
第三章:部署范式分析——Hyperscalers的ARM自研化之路
1. 功率比的结构性位移:从配角到独立建筑
2. ARM自研CPU的吞噬效应:新增需求的内部消化
3. 对x86市场的真实挤压:并存逻辑下的生存空间
第四章:供应链与制造现实——先进制程的垄断与风险
1. TSMC的绝对主导:被GPU挤压的CPU生存空间
2. Intel 18A的生死博弈:Clearwater Forest与Diamond Rapids重塑之路
3. AMD Venice的市场机会:SMT在并发场景下的溢价空间
第五章:核心逻辑模型——协同演进与吞吐极值
1. 协同演进模型构建:决定成败的“木桶短板”
2. 瓶颈位移预测:计算正在变得“廉价”,而编排依然“昂贵”
3. 战略地位重定义:从“指令分发者”到“全系统状态管理者”
实证对比表:Agentic AI下的厂商架构策略
核心策略深度拆解:从“算力博弈”到“编排主权”
[正文内容]
智能体AI时代:CPU角色定位的第一性原理分析
摘要
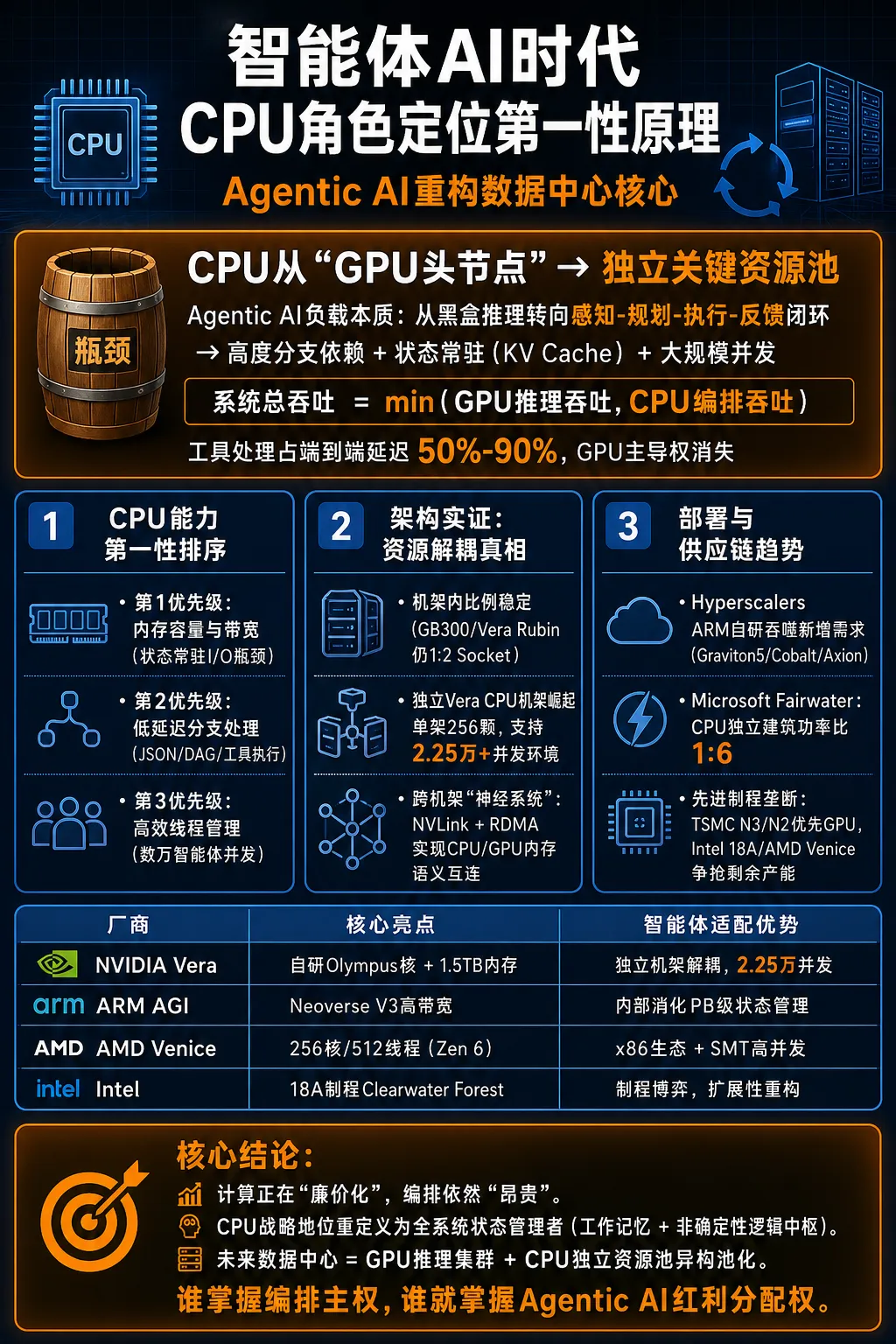
Agentic AI(智能体AI)的兴起正驱动数据中心架构发生第一性原理级别的重构。不同于传统AI的单一矩阵运算,智能体AI工作负载以“感知-规划-执行-反馈”的长序列闭环为特征,将计算瓶颈从GPU算力引向CPU的编排与工具执行能力。实证表明,CPU已从单纯的“头节点”演进为与GPU解耦的独立关键资源池。尽管NVIDIA等厂商在架内维持GPU中心化设计,但超大规模云服务商通过建设独立CPU集群(如Microsoft Fairwater项目)来应对结构性增量。未来系统吞吐量将受限于“GPU推理”与“CPU编排”的协同极值。
第一章:负载本质拆解 Agentic AI对计算资源的重新排序
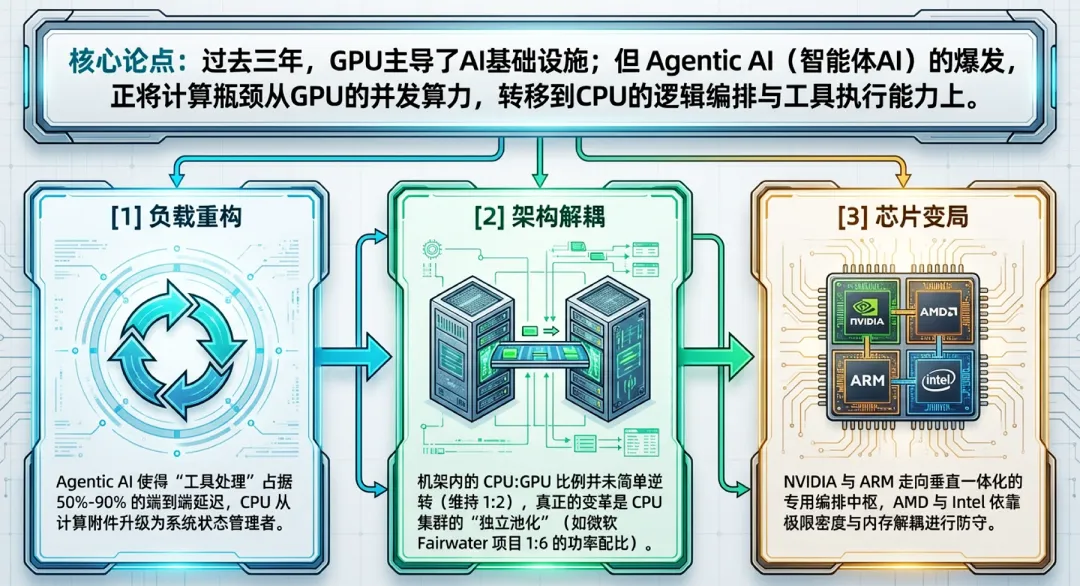
在过去三年的AI基础设施建设中,行业普遍遵循“GPU中心化”的逻辑。在这种范式下,CPU被简化为单纯的“头节点”(Head Node),主要任务是词元化输入、启动GPU内核并处理最终的输出逻辑。然而,随着智能体(Agent)的兴起,这种简单的线性负载结构正被一种复杂的循环逻辑所取代。
1.从“黑盒推理”到“系统编排”
传统的聊天机器人工作流(如ChatGPT)本质上是一种“点对点”的计算:用户输入、GPU矩阵运算、输出响应。而以OpenClaw为代表的持久运行、多智能体(Agent)平台,核心是一个“感知-规划-执行-反馈”的闭环。
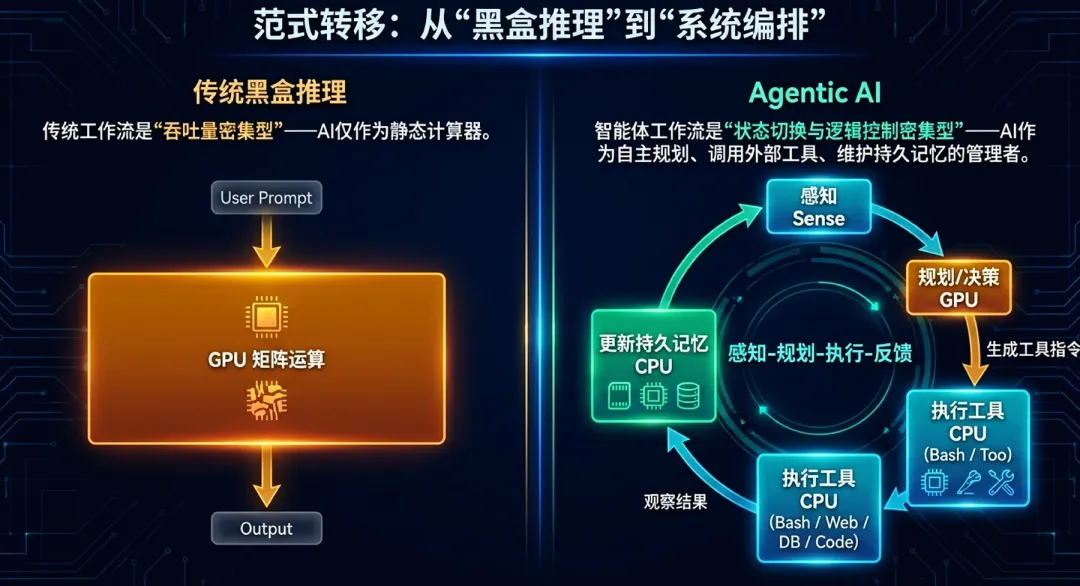
在这种新负载下,AI不再仅仅是一个“计算器”,而更像是一个“管理者”。智能体(Agent)需要自主规划任务、调用外部工具(如浏览器、Python解释器、Shell命令)、查询数据库并根据反馈持续迭代。这种转变带来了三个显著特征:
-
高度的分支依赖:每一轮循环的执行路径完全取决于前一步的工具返回结果,这种高度非确定性、串行的逻辑控制正是GPU的天然弱项。
-
状态常驻特征:不同于无状态的传统推理,智能体(Agent)需要维护持久的上下文状态(如OpenClaw中的“灵魂”配置文件Soul.md)和长期记忆,这导致计算过程中存在大量的状态读写。
-
大规模并发:一个复杂的任务可能触发数十甚至数百个子智能体(Agent)并行工作。例如,在自动编写代码时,可能同时有智能体(Agent)在查阅文档、有智能体(Agent)在执行单元测试、有智能体(Agent)在进行跨文件检索。
2.CPU关键能力的第一性排序
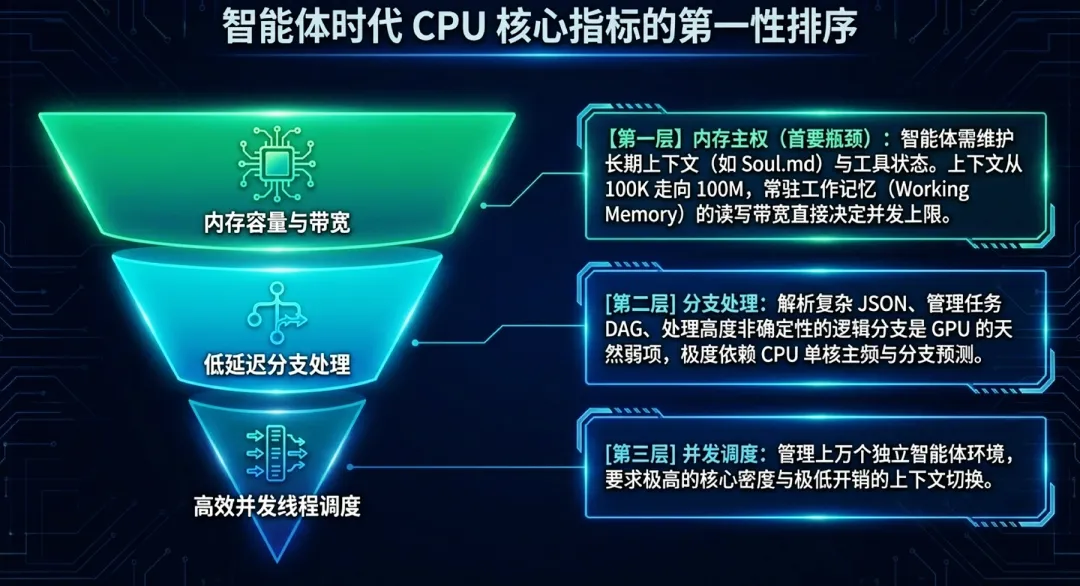
基于智能体(Agent)的负载本质,我们必须重新定义CPU在计算集群中的角色。从第一性原理出发,CPU的能力需求优先级已经发生了结构性移位:

第一优先级:内存容量与带宽(核心瓶颈)。在智能体(Agent)流程中,上下文(KV Cache)和工具执行状态不再随推理结束而释放,而是作为“工作记忆”常驻。随着上下文窗口从100K冲向100M,存储和检索这些海量状态数据的带宽直接决定了系统的并发支撑上限。例如,AWS Graviton5等新一代CPU大幅增加核心带宽和缓存,正是为了解决状态常驻带来的I/O压力。
第二优先级:低延迟分支处理。智能体(Agent)的大部分工作在于“执行”而非单纯的“思考”。解析复杂的JSON响应、管理任务的有向无环图(DAG)、处理API层的逻辑分支,这些确定性逻辑高度依赖CPU的单核主频和分支预测效率,而非GPU的吞吐算力。
第三优先级:高效线程管理与并发调度。面对数以万计的智能体(Agent)运行环境,CPU必须能在极低开销下管理复杂的上下文切换和并发线程。这要求处理器具备极高的多核心密度(如AmpereOne的192核或Intel Clearwater Forest的288核)以及成熟的并行控制机制。
3.延迟占比实证:消失的GPU主导权
实证数据表明,在智能体(Agent)时代,GPU的矩阵运算时间占比正被CPU的工具处理时间严重侵蚀。根据佐治亚理工学院与Intel在2025年11月发布的联合研究报告,在典型的智能体(Agent)工作负载中,工具处理(Tool Processing)可占据端到端延迟的50%至90%。
这意味着,无论GPU的吞吐量提升多少,如果CPU在处理Bash执行、Web爬取或数据库检索时出现延迟,整个智能体(Agent)系统的响应效率都会被卡死。在某些极端案例中,GPU甚至有超过80%的时间处于空闲状态,等待CPU完成上一个工具调用的解析。
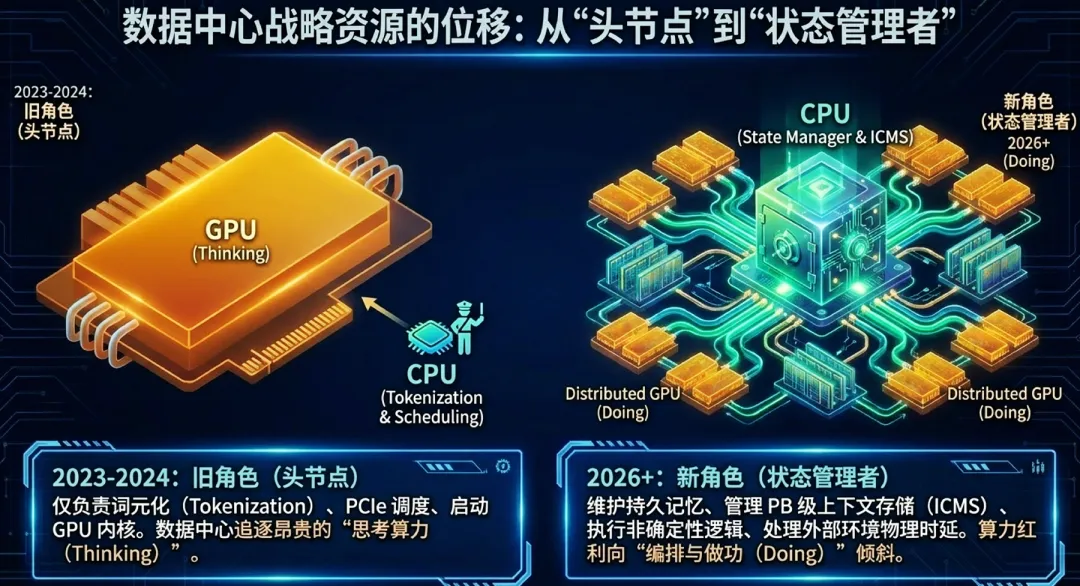
结论:智能体(Agent)行为模式使计算范式从“吞吐量密集”转向“状态切换密集”。在智能体(Agent)系统中,CPU不再是GPU的附庸,而是全系统的状态管理器与逻辑控制中枢。CPU的核心指标已从单纯的算力值,转向对系统内存的可见性深度、控制流的执行效率以及I/O控制的实时性。智能体(Agent)时代的系统总吞吐量,实质上由“GPU推理吞吐”与“CPU编排吞吐”的交集极值决定。
第二章:计算架构实证 从GB300到Vera Rubin的解耦真相
如果说第一章揭示了负载需求的“软性”变化,那么硬件架构的演进则是最硬核的实证。业界普遍存在一种误读,认为由于智能体(Agent)需求激增,服务器主板上的CPU数量将很快与GPU平起平坐。然而,通过拆解NVIDIA最新的路线图,我们发现事实并非简单的比例逆转,而是一场深刻的“资源池化与逻辑解耦”。
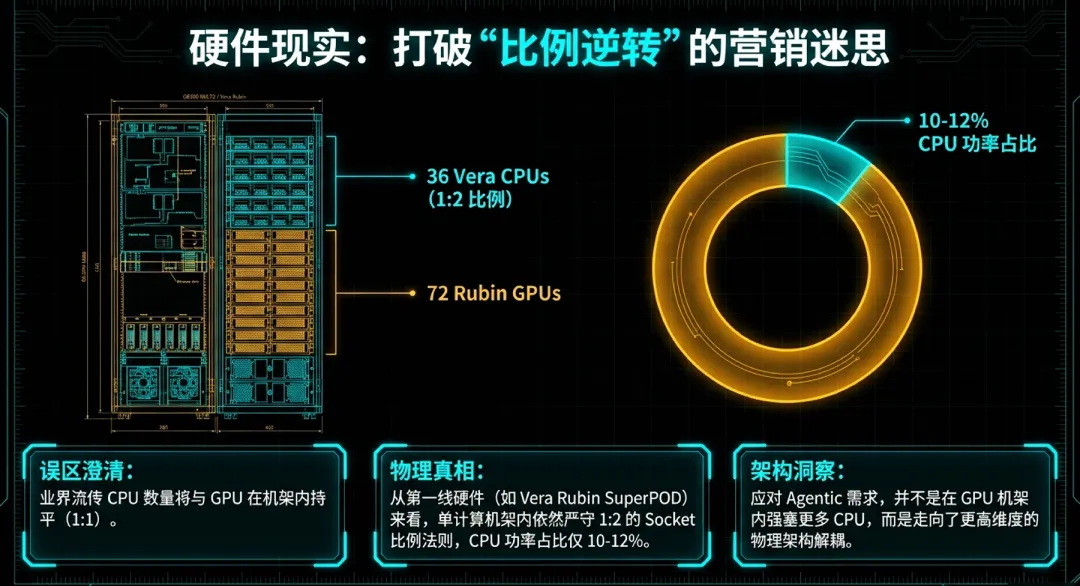
1.机架内比例的稳定性:营销幻觉与硬件现实
观察NVIDIA主力架构可以发现,虽然CPU的角色在增强,但单一机架(Rack)内的物理比例表现出了极强的稳定性。
Socket比例的“铁律”:无论是当前的GB300 NVL72还是下一代的Vera Rubin SuperPOD,其核心计算单元均严格保持着1:2的Socket比例。这意味着每2颗GPU依然对应1颗控制核心。
功率配比的真相:在GB300 NVL72系统中,72颗Blackwell GPU与36颗Grace CPU构成的集群中,CPU的功率占比仅为10%至12%,系统总功率比维持在约1:9。即便到了Rubin世代,虽然Vera CPU升级为88个自定义Olympus核(通过空间多线程支持176线程)并配备了惊人的1.5TB LPDDR5X内存,但其在NVL72机架内的物理占位并没有发生剧烈膨胀。
这说明,在“计算节点”层面,NVIDIA依然坚持以GPU为中心的吞吐量最大化设计。
2.“资源解耦”的真实意图:独立Vera CPU机架的崛起
那么,增加的CPU需求去哪了?答案不在GPU机架内,而是在独立的Vera CPU机架中。NVIDIA在GTC 2026上正式发布了独立CPU机架,单机架集成了256颗液冷Vera CPU。这种设计背后隐藏着处理智能体(Agent)负载的第一性逻辑:
强化学习(RL)模拟环境的隔离:智能体(Agent)训练(如RLVR)需要大规模的CPU环境来执行模型生成的动作并计算奖励(Reward)。在这个阶段,GPU往往处于闲置状态等待反馈。如果在GPU节点内盲目增配CPU,会导致昂贵的GPU在CPU执行环境模拟(如代码编译、物理仿真)时产生巨大的资源浪费。
支持海量并发沙箱:独立的Vera CPU机架支持超过22,500个并发CPU环境,每个环境都能独立全速运行。这种资源解耦部署支持云服务商根据不同任务阶段(是推理密集还是编排密集)弹性调度资源,而非被绑定在固定的物理配比上。
3.数据中心作为计算单元:跨机架调度的“神经系统”
在资源解耦的范式下,衡量算力的单位不再是单一服务器,而是整个数据中心。通过以下技术路径,系统实现了跨机架的资源协同:
NVLink 6与内存语义互连:NVLink 6提供了高达3.6TB/s的带宽,使72颗GPU能够像一颗芯片一样运作。更重要的是,NVLink-C2C技术实现了CPU与GPU之间的内存相干性,带宽达1.8TB/s,这支持GPU直接访问Vera CPU池中的海量DRAM作为KV Cache的扩展空间。
RDMA与Spectrum-X的协同:对于跨机架(如从计算机架到独立CPU机架)的调度,RDMA(远程直接内存访问)和Spectrum-X以太网成为了关键的“神经”。通过RDMA技术,CPU池中的状态数据可以绕过传统协议栈,以亚微秒级延迟同步至GPU推理阵列,从而解决分布式智能体(Agent)工作流中的I/O瓶颈。
结论:CPU与GPU比例的物理收窄并非发生在单一主板的微观层面,而是在数据中心宏观层面通过资源池化实现的。未来的AI工厂将表现为“物理隔离、逻辑耦合”:昂贵的GPU阵列负责瞬间的爆发式推理,而独立的、规模化的CPU资源池(如Vera CPU机架)则负责持久的逻辑编排与环境模拟。这种架构在提升系统总吞吐量的同时,极大优化了资本性支出(CapEx)与运营性支出(OpEx),标志着数据中心正式进入“异构池化”时代。
第三章:部署范式分析——Hyperscalers的ARM自研化之路
在智能体(Agentic AI)时代,数据中心的物理景观正经历一场前所未有的建筑级重构。过去,算力的衡量标准是机架上的GPU密度;而现在,超大规模云厂商(Hyperscalers)正通过建设庞大的独立CPU资源池,悄然改变着计算权力的重心。
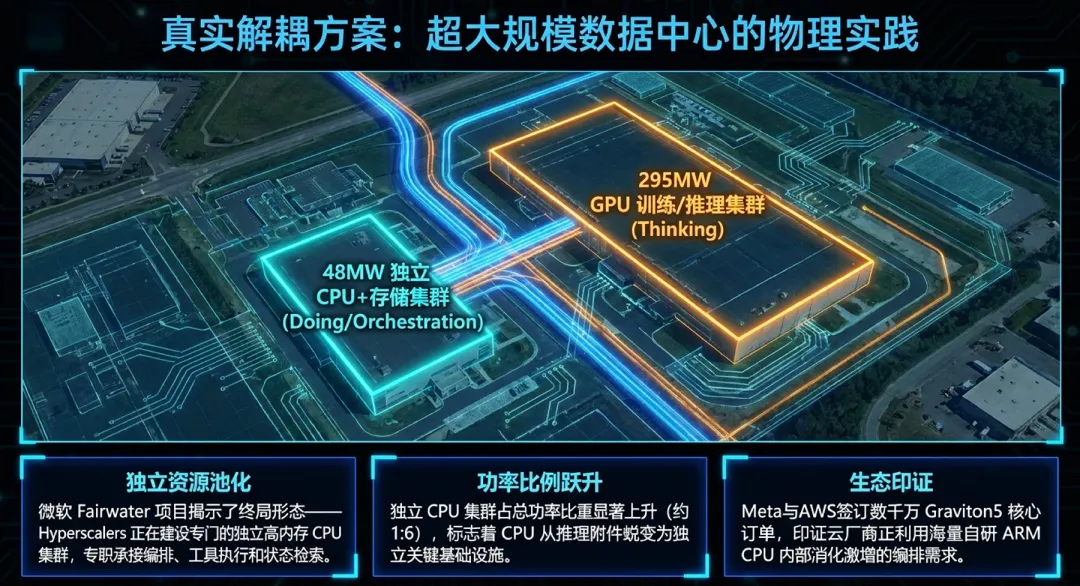
1.功率比的结构性位移:从配角到独立建筑
传统的AI架构中,CPU主要承担数据调度与预处理任务,其功耗占比极低。然而,Microsoft Fairwater项目(位于威斯康星州和亚特兰大的AI超级工厂)揭示了一个硬核趋势:CPU与GPU的资源占比正从建筑层面发生位移。
1:6的功率新常态:通过卫星图像与电力部署实证,Fairwater项目采用了一个48兆瓦(MW)的CPU与存储建筑来支撑主体的295兆瓦(MW)GPU集群。这种约1:6的功率比例显著高于传统AI训练集群。
PB级的数据管理需求:这种位移的本质在于智能体AI工作负载对海量状态数据的管理需求。在智能体工作流中,CPU不仅要存储、分片和索引数据,还要实时处理由GPU生成并需要持续更新的PB级上下文数据。这种数据密集型编排使得CPU不再只是头节点,而必须以独立建筑级的规模存在。
2.ARM自研CPU的吞噬效应:新增需求的内部消化
面对激增的CPU需求,云厂商并未将订单全部外溢给传统芯片商,而是通过自研ARM CPU构筑了一道深厚的护城河。
Meta与AWS的数千万核订单:2026年4月,Meta与AWS签订了部署数千万个Graviton5核心的协议,这笔价值数十亿美元的交易标志着算力来源的战略性多样化。Graviton5基于192个Neoverse V3核心和比前代大5倍的缓存,能将智能体间的通信延迟降低33%,适配代码生成和多步任务编排等CPU密集型工作。
内存带宽的降维打击:Microsoft Cobalt 200与Google Axion同样体现了这一逻辑。Cobalt 200基于Neoverse V3架构,其132个核心配合极高的内存带宽,相比前代实现了50%的性能提升。ARM架构在处理智能体AI工作负载时展现出天然优势:高核心密度与高内存带宽的结合,能有效消化那些GPU无法高效处理的高度分支逻辑。
3.对x86市场的真实挤压:并存逻辑下的生存空间
尽管CPU回归中心的口号响亮,但传统x86市场感受到的却是结构性寒意。
成熟生态的护城河:x86架构在兼容性、工具链支持(如Python解释器、传统数据库)方面依然拥有数十年积累的深厚生态,这使得AI实验室和部分复杂训练场景仍倾向于采购AMD Venice或Intel Xeon。
供应链的极端挤压:目前先进制程(如TSMC N3/N2)的产能被AI加速器高度占据,导致AMD和Intel的高核心数服务器处理器几乎处于售罄状态。
真实挤压的真相:云厂商通过自研ARM CPU实现了对新增智能体需求的精准拦截。这意味着,虽然整个CPU市场在增长,但最具增长潜力的智能体编排负载,已被云厂商的自研硅片在进入公开市场前内部消化了。
结论:云厂商通过自研ARM CPU,不仅是为了降低资本性支出(CapEx)与运营性支出(OpEx),更是为了实现硬件与智能体特定负载(感知-规划-反馈循环)的深度适配。这种适配带来了显著的能效比优化:通过在建筑层面解耦CPU资源,云厂商能够支持PB级的上下文管理。结果显而易见,智能体(Agentic AI)引发的计算增量绝大部分被ARM自研生态所吞噬,传统x86芯片正面临着需求爆发但增量空间受限的辩证窘境。
第四章:供应链与制造现实——先进制程的垄断与风险
如果说智能体(Agentic AI)对架构的需求是软约束,那么先进制程的产能分配则是决定这一演进速度的硬瓶颈。在2026年的产业格局中,尽管CPU的需求因强化学习(RL)和编排任务而激增,但其实际产出却深陷于先进制程的供需错配中。
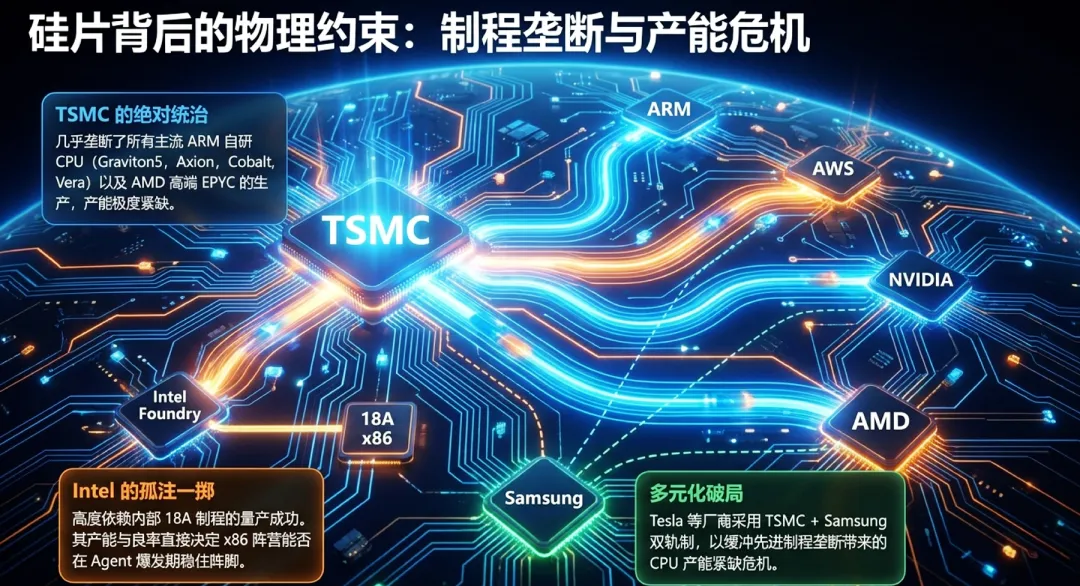
1.TSMC的绝对主导:被GPU挤压的CPU生存空间
目前,全球数据中心CPU的更新节奏已完全锚定在TSMC的N3与N2制程之上。
产能分配的优先序列:在TSMC内部,AI加速器(GPU及定制ASIC)拥有绝对的产能优先级。由于GPU带来的利润率更高,CPU厂商往往只能竞争剩余的高端产能。TSMC主席魏哲家曾公开表示,先进节点产能缺口依然巨大。
先进制程的集体大跃进:NVIDIA的Vera CPU(3nm)、AMD的Venice(2nm)以及各家云厂商的自研硅片(如Graviton5、Cobalt 200、Axion)均深度绑定TSMC。这种高度集中化意味着,一旦N3/N2的良率波动或产能分配偏向GPU,智能体时代所需的独立CPU资源池将面临结构性短缺。据估计,TSMC在2026年仅能满足约80%的晶圆需求,这已直接导致高端服务器CPU价格上涨15%至50%。
2.Intel 18A的生死博弈:Clearwater Forest与Diamond Rapids重塑之路
为了重夺失去的服务器市场份额,Intel将其所有筹码压在了18A制程上,但这条路充满了执行风险。
良率学习车Clearwater Forest:作为首款采用18A并引入Foveros Direct混合键合技术的芯片,Clearwater Forest(Xeon 6+)拥有288个核心,被视为Intel重塑计算密度的希望。然而,受限于较低的键合良率,其实际性能提升仅比前代高出17%,目前更多被视为Foveros技术的产能验证工具,而非大规模商用的利润支柱。
延期的Diamond Rapids:针对P-core(性能核)市场的Diamond Rapids(Xeon 7)已推迟至2027年年中发布。虽然它在架构上尝试分离内存控制器(IMH)以追求极致扩展性,但缺乏SMT(同步多线程)支持使其在面对智能体高并发场景时,吞吐量提升可能不及AMD对手。Intel当前的困境在于,制程端的良率挑战限制了其响应智能体需求爆发的能力。
3.AMD Venice的市场机会:SMT在并发场景下的溢价空间
在Intel受挫与TSMC产能受限的双重夹缝中,AMD Venice(Zen 6架构)正迎来其战略高光时刻。
512线程的暴力美学:Venice通过TSMC N2工艺与SoIC封装,在256个核心上实现了惊人的512个同步线程。对于需要同时运行数万个智能体沙箱环境(如OpenClaw)的数据中心来说,Venice提供的极高核心密度与线程容量具有极高的溢价空间。
生态与能效的双重护城河:相比于自研ARM CPU,Venice保留了成熟的x86生态支持(如复杂的Python工具链和遗留数据库),这使其在AI实验室和复杂编排任务中极具吸引力。AMD CEO苏姿丰指出,智能体AI工作负载对EPYC CPU的需求激增是意料之外的,目前AMD正通过强化供应链弹性来吞噬Intel空出的市场份额。
结论:制造端的木桶效应决定了智能体时代的进化速度:系统的最终性能不取决于最快的GPU,而取决于那块被挤压在先进制程边缘的CPU。2026年的制造现实是,CPU的更新节奏被迫受限于高端晶圆的产能分配优先级。这种供应链弹性已成为智能体爆发初期的核心约束,谁能锁定TSMC的N3/N2产能,或者率先突破18A良率关口,谁就握有了构建未来独立CPU资源池的准入许可证。
第五章:核心逻辑模型——协同演进与吞吐极值
在完成了对负载本质、硬件架构、部署范式及供应链瓶颈的深度拆解后,我们必须回归数据中心架构演进的底层逻辑。智能体(Agent)时代并非简单的硬件堆叠,而是一场关于“计算协同”的深刻变革。
1.协同演进模型构建:决定成败的“木桶短板”
在传统的推理任务中,GPU的吞吐量几乎等同于系统的生产力。但在智能体(Agent)工作流中,系统的总生产效率服从一个更为严苛的最小函数模型:
系统总吞吐量 = min(GPU推理吞吐, CPU编排吞吐)
根据实证研究,工具处理(如Bash执行、Web检索、数据库查询)可占据端到端延迟的50%至90%。在这种模型下,即使GPU的FLOPS以摩尔定律级别的速度翻倍,如果CPU在管理任务有向无环图(DAG)、解析JSON或执行环境模拟时出现瓶颈,整个AI工厂的“做功”效率都将被卡死在CPU的编排上限上。
这种协同演进意味着,未来数据中心的扩展将不再是单一GPU机架的重复复制,而是需要根据负载的“推理/编排比”动态匹配CPU资源池的规模。
2.瓶颈位移预测:计算正在变得“廉价”,而编排依然“昂贵”
一个被忽视的趋势是:随着NVIDIA Rubin等平台引入NVFP4等超低精度格式,GPU的推理成本正在以惊人的速度下降,其性能密度提升远超CPU。
GPU算力的“消费品化”:通过计算密度提升(Vera Rubin支持10倍推理吞吐提升),单次“思考”的边际成本趋于极低。
CPU编排的“持久成本中心”:相比之下,智能体(Agent)对外部环境的物理操作(如复杂的Python代码执行、跨数据中心的API调用)存在物理时延的硬下限。此外,随着上下文窗口向100B词元(Token)演进,KV Cache的频繁加载与状态维护使得CPU侧的I/O压力成为长期难以消除的瓶颈。
因此,数据中心的战略性资源将发生位移:从追逐昂贵的“思考算力”,转向管理那些持久且难以并行化的系统编排负载。
3.战略地位重定义:从“指令分发者”到“全系统状态管理者”
CPU在数据中心架构中的角色正经历从“头节点”(Head Node)向“独立关键资源池”的质变:
-
旧角色(指令分发者):过去CPU只是GPU的“保姆”,负责任务下发、词元(Token)化和PCIe调度。
-
新角色(状态管理者):在智能体(Agent)时代,CPU升级为全系统的状态管理者(State Manager)。它负责维护智能体(Agent)的持久记忆、管理PB级的上下文存储(ICMS)、执行非确定性的逻辑分支,并根据实时反馈优化资源调度。
NVIDIA推出独立Vera CPU机架、ARM推出首个成品AGI CPU,以及Hyperscalers大规模建设独立CPU建筑,都是这一重定义的物理证明。CPU不再是GPU主板上的一个附件,而是一个解耦的、规模化的、专门处理“复杂性”的权力中心。
结论:智能体(Agent)时代的系统效率取决于“思考”与“行动”的完美对齐。当GPU推理趋于瞬时完成时,CPU对任务链路的编排能力、对持久状态的检索效率,将决定AI应用的商业可行性。CPU不再重回中心,它正在建立自己的中心——一个与推理集群平行、以状态管理为核心的独立资源池。未来数据中心的优劣,将由其处理非确定性逻辑的“编排吞吐量”而非单纯的“矩阵算力”来定义。
实证对比表:Agentic AI下的厂商架构策略
在深入探讨了智能体(Agent)对计算负载的重构逻辑后,我们必须观察这些理论是如何在顶尖芯片厂商的硬件路线图中落地的。为了支持“感知-规划-执行-反馈”的高频循环,各大厂商不再仅仅将CPU视为GPU的“保姆”,而是将其作为独立的逻辑编排中枢进行军备竞赛。

以下是针对智能体(Agent)AI时代的四大主流芯片厂商架构策略的实证对比与深度分析。
|
特性指标 |
NVIDIA (Vera CPU) |
ARM (AGI CPU) |
AMD (Venice) |
Intel (Diamond Rapids) |
|
核心架构 |
自研Olympus核 (基于ARMv9.2) |
Neoverse V3核心 |
Zen 6 (Dense核心设计) |
Panther Cove-X (P-Core) |
|
内存指标 |
1.5TB LPDDR5X, 1.2TB/s带宽 |
每核6GB/s内存带宽 |
16通道MRDIMM, 带宽达1.64TB/s |
16通道DDR5 |
|
部署策略 |
独立机架与解耦部署方案 |
品牌硅片商模式(卖芯片+卖机架) |
坚守x86生态并追求极端线程密度 |
自有工厂18A制程驱动 |
|
智能体(Agent)支持 |
单Rack支持超过2.25万个并发环境 |
液冷机架可达4.5万个核心 |
单Socket支持512个同步线程 |
峰值可达512核 (基于E-core版本) |
核心策略深度拆解:从“算力博弈”到“编排主权”
1.NVIDIA:从“附件”到“独立数据引擎”
NVIDIA的Vera CPU标志着其CPU策略的彻底转向。不同于Grace时期主要作为GPU的本地控制器,Vera被定义为“AI工厂的数据引擎”。

自研Olympus核的意图:为了解决ARM公版架构在分支预测上的瓶颈(曾导致GB200某些负载变慢),NVIDIA重组了自研核心团队。Olympus核通过空间多线程(Spatial Multithreading)技术,将核心资源物理分区以支持高并发智能体(Agent)任务,而非简单的时分复用。
资源解耦的物理落地:NVIDIA推出的独立Vera CPU机架集成了256颗液冷CPU,其目标并非单纯喂送数据,而是专门处理智能体(Agent)AI所需的强化学习模拟环境(Sandboxes)。通过这种硬件层面的解耦,NVIDIA在CapEx(资本性支出)分配上实现了更精细的控制。
2.ARM:从“IP授权”到“全栈成品”
ARM推出AGI CPU是其35年历史上最激进的商业模式变革,直接下场销售成品硅片和机架设计。
消除通信税:基于Neoverse V3核心与自研网格互连(Mesh Interconnect),ARM宣称其机架级性能可达传统x86部署的2倍以上。
针对性调优:AGI CPU特别优化了内存带宽(6GB/s per core),这正是为了应对智能体(Agent)多轮对话中KV Cache频繁交换导致的I/O墙问题,显著降低了数据中心在大规模推理时的OpEx(运营性支出)。
3.AMD:x86生态下的线程暴力美学
AMD在智能体(Agent)时代展现了极强的防御与反击能力,其核心武器是Venice(Zen 6架构)。

高并发红利:Venice通过TSMC N2工艺,在单插槽内塞入256个核心并支持512个同步线程,这对于需要同时管理数万个独立智能体(Agent)进程的数据中心极具吸引力。
生态护城河:相比转向ARM所需的代码迁移成本,Venice基于成熟的x86生态(特别是对复杂Python工具链和遗留数据库的支持),在AI实验室中保持了极高的溢价能力。
4.Intel:先进制程的“最后一搏”
Intel的Diamond Rapids(Xeon 7)是其重返数据中心巅峰的关键筹码,核心赌注压在了18A制程上。
架构重构:Diamond Rapids首次将内存控制器(IMH)与计算核心(CBB)完全分离,追求极端的内存扩展性。
制造驱动:尽管面临良率挑战,Intel依然希望通过Foveros Direct 3D封装技术实现超越AMD的核心密度。然而,Diamond Rapids推迟至2027年发布,这使Intel在智能体(Agent)AI爆发初期面临巨大的交付压力。
结论:这四种策略实际上映射了数据中心架构的异构演进模型:
-
NVIDIA与ARM代表了“垂直一体化”路径,试图通过芯片与机架的深度耦合,将CPU转变为专门处理智能体(Agent)编排的专用处理器。
-
AMD与Intel代表了“通用池化”路径,利用x86庞大的软件惯性,通过堆叠核心数与线程密度,在保证兼容性的前提下吞噬新增的编排负载。
最终的胜负将不再由核心主频决定,而取决于谁能更高效地管理那PB级的工作记忆(Working Memory),并将其以最低延迟喂送给日益廉价的GPU推理阵列。

结论:从“头节点”到独立权力的演进
CPU在智能体(Agent)时代并非单纯地“回归”到旧有的通用计算中心地位,而是以一种更加独立且专门化的形式重新进入了数据中心的权力核心。这种转变并非历史的重复,而是计算范式在第一性原理驱动下的重构:在智能体(Agent)AI的闭环中,GPU负责瞬时的“思考(Thinking)”,而CPU则演变为全系统的“做功(Doing)”层,承担起复杂的、非确定性的逻辑编排与环境模拟任务。
其核心战略价值正经历着双重维度的重定义:
在内存层级中的主权:随着上下文窗口向千万级甚至亿级词元演进,CPU已成为“工作记忆(Working Memory)”的管理者。其价值不再仅仅体现在计算频率上,而更多体现在其对PB级KV Cache的检索带宽、存储分片及跨节点调度的效率上。
非确定性逻辑的执行中枢:智能体(Agent)的高频工具调用(Tool Calls)和分支逻辑是GPU的天然弱项,CPU通过其卓越的分支预测、高单核主频以及日益增强的核心密度,成为了智能体(Agent)系统的控制流中枢。
展望未来,衡量数据中心先进性的指标将发生根本性位移。数据中心的成熟度将不再由GPU的绝对数量来简单衡量,而取决于“CPU资源池”与“加速器集群”之间的动态平衡。正如Microsoft Fairwater项目和NVIDIA Vera独立CPU机架所揭示的趋势,未来的AI工厂将是一个由推理(GPU)、编排(CPU)与低延迟解码(LPU/DPU)协同构成的池化异构体。
在这场协同演进中,CPU正在建立属于自己的中心,一个与推理集群平行、以全系统状态管理为核心的独立资源池。谁能最先解决“做功层”的I/O瓶颈与编排效率,谁就将掌握智能体(Agent)时代算力红利的最终分配权。
更多交流,可加本人微信
(请附中文姓名/公司/关注领域)
