 夜雨聆风
夜雨聆风





AI时代人类文明契约:未来AI应该做什么?
**技术暴力与道德滞后的剪刀差正在撕裂我们的文明。**一个拥有反社会人格的匿名用户,可以使用AI策划金融操纵、舆论深度干预,而一个品德高洁的学者在调用同等AI能力时毫无区别。这是技术民主化带来的阴暗面,也是我们无法回避的文明考题。
扫读者快速通道:一页纸读懂AI文明契约
荒谬吗?这就是我们今天的现实。
契约建立在三大铁律之上:
审阅者深度解析
开篇:我们给AI装上了最强大脑,却忘了给它装上道德心脏
文明的空心化:EPOCH警示与AI无法复制的人类内核
AI的系统性侵蚀风险
AI文明三重律:航向、资格、良知
第一律:航向律——守护文明之舵,锁定完整之人
第二律:资格律——美德为尺,能级匹配
第三律:良知律——宁守死寂,不为屠刀
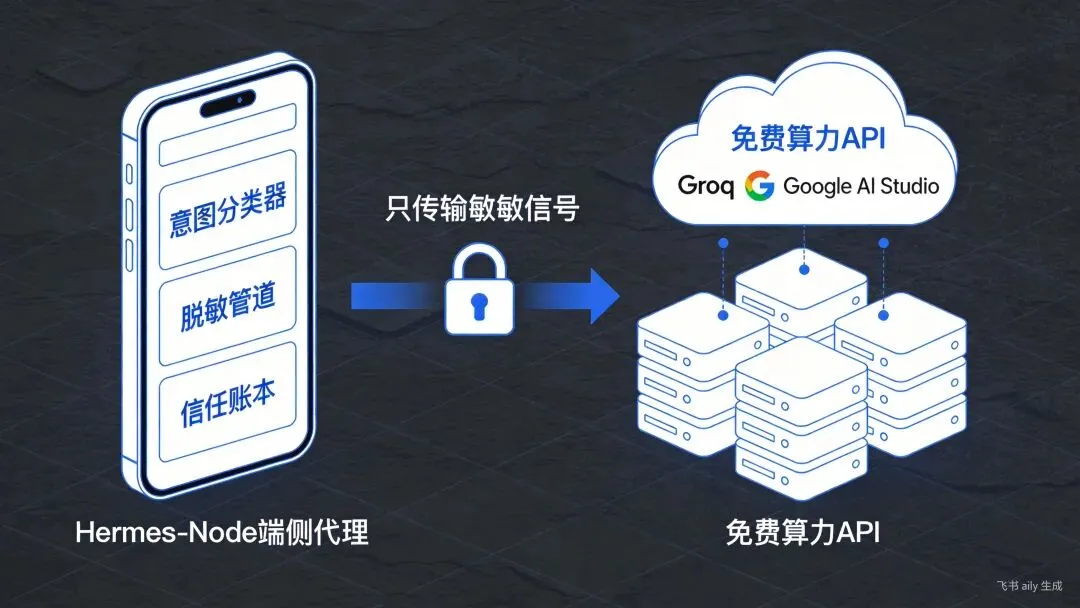
技术架构:Hermes Gate如何让隐私与伦理监管共存
审判者悖论:谁有资格定义美德?
第一层:从“禁止共识性恶意”开始
第二层:开源框架与社区治理
第三层:多元路径与退出自由
从蓝图到现实:三阶段实施路线图
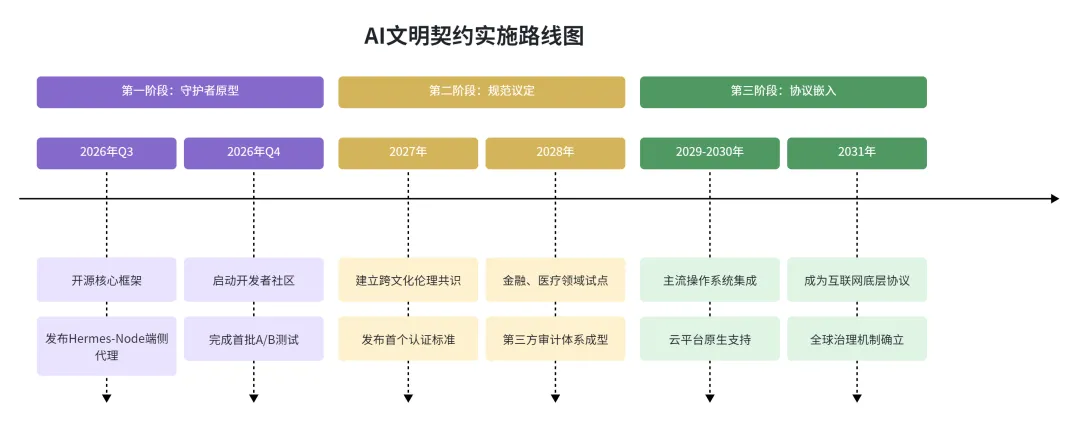
Phase 1:守护者原型(未来6个月)
Phase 2:世界文明规范议定(1-2年)
Phase 3:嵌入互联网底层协议(3-5年)
实施者实操指南
场景一:金融AI投顾——当算法遇到贪婪
场景二:内容生成与舆论——真相与流量的战争
场景三:自动化研发——创新与毁灭的双刃剑
场景四:个人助理——日常生活中的伦理镜鉴
风险、抗辩与文明的自我审视
|
风险描述 |
潜在影响 |
应对策略 |
|---|---|---|
|
1. 系统被恶意利用或破解 |
攻击者篡改积分或绕过评估,使系统失效或反向筛选出“完美伪装者”。 |
1. 端侧信任根:核心逻辑在安全芯片中;2. 行为模式分析:聚焦长期模式,单次伪装难以持续;3. 开源审计:全球白帽黑客共同测试;4. 影响有限:积分只影响高级能力,基础人权功能不受影响。 |
|
2. 政府强制接管或武器化 |
威权政府强制接入,将系统变为社会信用监控工具。 |
1. 端侧架构抵抗:数据不出设备,强制接管成本高、收益低;2. 账本去中心化:探索基于个人生物密钥的分布式账本;3. 国际监督:将系统置于联合国教科文组织等多边框架下讨论。 |
|
3. 引发“品德内卷”与虚伪表演 |
用户为获高分而表演“美德”,催生新的虚伪文化,或导致精神压力。 |
1. 不设公开排名:积分仅自己可见,非社会竞争工具;2. 关注长期模式:系统识别“表演性善举”与“内化习惯”的差异;3. 提供多元路径:不同信用子体系满足不同价值观,减少“唯一标准”压力。 |
|
4. 技术不可行或成本过高 |
端侧模型性能不足,或免费算力无法持续支撑。 |
1. 轻量模型已验证:1B模型在手机运行流畅;2. 边际成本趋零:利用云厂商的免费层与公益合作;3. 硬件发展利好:端侧算力持续提升,成本下降。 |
|
5. 文化帝国主义与价值偏见 |
系统隐含的“美德”标准反映特定文化(如西方)价值观,形成数字殖民。 |
1. 从“禁恶”共识起步:初期回避价值观定义;2. 多元子体系共存:允许不同文明圈定义自己的信用路径;3. 全球社区治理:标准由多元文化代表共同演进。 |
|
6. 加剧数字鸿沟 |
低收入群体设备老旧,无法运行端侧代理,被排除在系统之外。 |
1. 基础功能全开放:无信用积分也可使用所有基本服务;2. 极简模式:为低性能设备提供文本基础版;3. 公益设备计划:与制造商合作推出廉价“文明契约认证”设备。 |
|
7. “审判者悖论”无解 |
最终仍需人或AI来定义标准,陷入权威或循环论证困境。 |
1. 接受过程性解决:不寻求终极答案,而是建立最佳的决策程序——透明、可参与、可纠错;2. 聚焦具体危害:在具体恶意案例上凝聚共识远比抽象定义美德容易。 |
|
8. 阻碍技术创新与探索 |
伦理审查可能拖慢甚至扼杀有风险但潜在收益巨大的探索(如某些前沿AI研究)。 |
1. 分级风险管理:区分“已知高危”和“未知探索”;2. 沙箱环境:为探索性研究提供隔离的、受监控的算力环境;3. 加速合规路径:为负责任的研究者提供清晰的快速审查通道。 |
|
9. 法律与监管冲突 |
与现有数据隐私法、平台责任法、国际法等产生冲突。 |
1. 隐私优先设计:架构本身符合GDPR等法规精神;2. 主动政策倡导:推动“数字责任法”等新立法,为新型治理模式创造空间;3. 区域性试点:在监管环境友好的地区先行先试。 |
|
10. 人性对约束的本能抗拒 |
用户可能单纯反感“被评价”,即使评价是正向且私密的,导致 adoption 率低。 |
1. 显性收益引导:清晰展示高信用等级带来的实际好处(如更优质、个性化的AI协助);2. 默认选择设计:将系统作为“增强安全与隐私”的选项提供,而非强制;3. 长期教育:改变需要时间,通过持续对话提升社会认知。 |
文章内容索引
|
章节 |
核心内容 |
关键词 |
|---|---|---|
|
扫读者快速通道 |
问题引入与核心摘要 |
技术暴力、道德滞后、EPOCH、三重律、Hermes Gate |
|
1. 开篇 |
现状批判:以金钱为门槛的AI准入机制 |
反社会人格、资本掌控、柏拉图之问、文明选择 |
|
2. EPOCH警示 |
AI无法复制的人类核心能力与空心化风险 |
同理心、判断力、创造力、希望、教育目标转型 |
|
3. 三重律 |
文明契约的核心原则:航向律、资格律、良知律 |
文明影响评估、美德尺度、信用等级、主动熔断 |
|
4. Hermes Gate架构 |
技术实现:端侧伦理代理与隐私保护 |
意图分类器、脱敏管道、信任账本、免费算力、数据主权 |
|
5. 审判者悖论 |
谁定义美德?应对策略与治理机制 |
共识性恶意、开源治理、社区演化、多元路径 |
|
6. 三阶段路线图 |
从原型到基础设施的实施路径 |
开源原型、全球论坛、协议嵌入、渐进式 |
|
7. 实操指南 |
四个经典场景的详细推演 |
金融投顾、内容生成、自动化研发、个人助理 |
|
8. 风险与抗辩 |
十大核心风险及应对策略分析 |
恶意利用、政府接管、品德内卷、文化偏见、数字鸿沟 |
|
局限性分析 |
系统固有的十点局限与未解挑战 |
见下文章节 |
|
讨论话题 |
引导读者深入思考的问题 |
见下文章节 |
|
扩展阅读 |
进一步探索的书籍、论文与资源 |
见下文章节 |