当前时间: 2026-05-03 17:19:09
更新时间: 2026-05-03
分类:软件教程
评论(0)
与AI聊了一下午,我终于搞懂什么叫上下文
最近在学习AI Agent产品的过程中深刻体会到,有些基础概念不懂、模棱两可,真的会严重限制你的工具使用能力!
很多时候,上面刚说过的话,它瞬间遗忘,用中文聊着聊着,突然开始飙英文!
反复确认过的正确方案,它转头就用了一个已经pass掉的方案,毫无契约精神可言!
后来疯狂学习发现,有一个叫上下文(Context)的东西,它会决定你模型的能力发挥到什么水平,那些你看到的令人啼笑皆非的现象,大部分(小部分确实跟模型本身的能力有关)都可以通过组织合适的上下文,来让模型避免掉。
因为我们现在使用的AI产品(基于LLM大模型),都是基于预测下一个token来实现输出的,每一轮对话,模型是没有记忆的,不知道过往发生过什么,需要你在对话前提供足够的背景信息来辅助模型预测。
这些背景信息主要包含:你的角色/身份、过往的经历/经验、当前的任务/要求,以及一些为了完成任务必要的工具/接口/项目环境等等这些,这些所有信息的集合,构成了我们刚才所说的上下文(Context),只有喂给模型恰到好处的上下文,模型才能把他的能力发挥到极致。
为了深度学习什么叫上下文、如何用好上下文,我做了两件事情:
-
我深扒了目前主流的4款AI Agent产品:Codex、Claude Code、OpenClaw、Hermes,然后从它们的文件目录里面找到了以下这些文件;
-
然后开始基于以上信息与Claude Sonnet 4.6深度探讨上下文应该如何结构化分层:
2.1 Claude告诉我,这些各式各样的记忆文件,整体上可以分成三个层级结构:
2.2 我让它基于这个分析框架,把前面那4个产品的所有记忆文件对号入座,分门别类:
-
结论一:产品越”工程化”,System 和 Memory 层越收缩。OpenClaw 和 Hermes 把三层都铺满了,因为它们要扮演一个有自我认知、认识用户、会记事的 Agent;Codex 和 Claude Code 把 System 层内嵌进模型或配置文件,把 Memory 层交给 git 和文件系统,只剩 Task 层可见——这是”工具”而非”伴侣”的设计哲学。
-
结论二:SKILL.md 是三层框架里唯一稳定落在 Task 层的文件,且四款产品全有。这说明”告诉 AI 当前任务怎么做”是 Agent 最基础、最不可省略的需求,无论产品定位如何都绕不过去。
-
结论三:AGENTS.md 和 CLAUDE.md 的跨层特性,揭示了一个设计权衡。文件越少越易维护,但容易把不同性质的内容混在一起;文件越细越 MECE,但认知负担高。OpenClaw 用 6 个文件做到了最干净的分离,代价是用户需要维护更多文件。
2.3 这些三层结构主要通过注意力(Attention)与服从性(Obedience)机制来作用于模型:
-
注意力:模型推理时对上下文不同位置分配权重的机制——”看哪里、看多重”,是计算层的物理现象
-
服从性:模型对不同来源指令的服从优先级排序与执行倾向——”听谁的、多坚定”,是行为层的涌现结果
这是我最近看到的解释上下文(Context) & 注意力|服从性最详尽易懂的总结了!
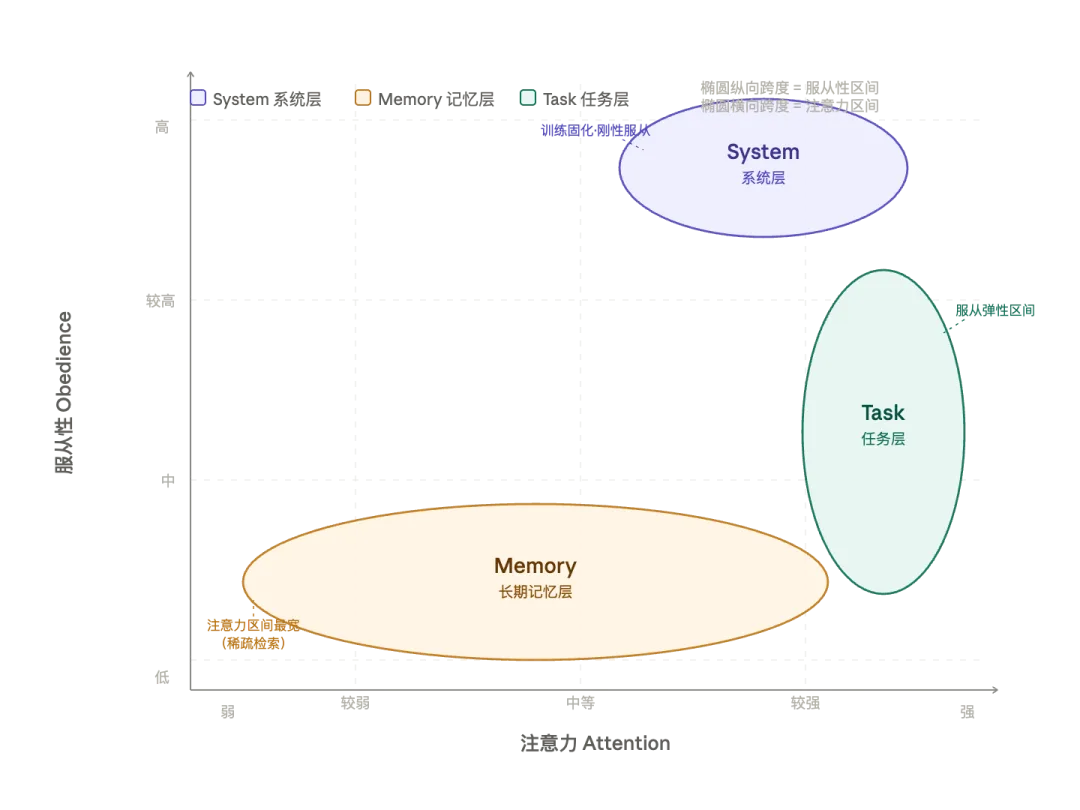
2.4 然后我又让它把上下文三层结构 与 注意力|服从性做一个矩阵分析的图表:
图中三个椭圆的形状本身就在编码信息:椭圆的宽窄 = 注意力的不确定性区间,椭圆的高矮 = 服从性的弹性范围。
-
System(紫色,右上角):宽扁偏圆——注意力强但非极端,服从性极高且几乎没有弹性,形状最"紧"
-
Memory(橙色,横贯中下部):极宽扁带——注意力区间跨度最大(从稀疏检索的低权重到被直接引用时的高权重),服从性低且稳定,所以纵向很薄
-
Task(绿色,右侧竖长):高挑竖椭圆——注意力极强(近端锚定),但服从性有明显弹性区间(用户可以灵活调整行为),所以纵向拉长
2.5 最后,我把自己掌握的有关大模型训练&Agent编排的相关提示信息告诉它,让它分析一下这个流程的不同阶段,分别是如何作用于大模型注意力&服从性的。
至此,我结束了对话,基本上对Context这个话题的认知,又上升了一个台阶。
虽然作为非技术人员,我们无需对这些概念做过度研究,但是能够系统的了解和熟悉,这些概念及其对大模型的作用机制,对于我们更好的掌握AI Agent使用技巧是非常有帮助的。
至少你再去面对类似Codex、Claude Code、OpenClaw、Hermes这些工具的时候,内部的各类记忆文件分别起什么作用、应该如何编写等等,会有一些心得。
进一步说,如果你还是不懂如何自己维护、编写这些文件!
那么就继续跟大模型聊,你告诉大模型,你的角色/身份、过往的经历/经验、以及各类你自己的工作环境,让大模型帮你起草、编写、修改。
一直修改到你满意为止,然后把这些信息,分门别类的整理写入以上这些工具的记忆文件。
未来就是在实际工作应用中逐步完善更新、迭代。你会慢慢的发现,你的AI Agent会越来越懂你!
 夜雨聆风
夜雨聆风