 夜雨聆风
夜雨聆风





我每个月的AI账单,已经比水电煤网加起来还高了
看见新闻,说是豆包推出了专业版要收费了。
其实类似的产品收费的早就有了,作为Kimi的忠实用户,我每个月都要花49块充Kimi(降价了,现在39了),主要看中它上下文长外加做PPT的功能,省去我很多麻烦。
豆包还真的不怎么用,因为模型能力真的一般,支撑不了我的专业需求,除了偶尔用来练练口语会想起它,不过作为一个大杂烩产品,反应够快,还多模态,解决日常问题合格了(至少比百度一下强100倍)。
我是一个AI的重度用户,可以说AI的诞生完全颠覆了我自己以往的行为习惯。日常所有的事情我都会在行动前思考下能不能让AI代劳。
除了Kimi以外,工作上用的最多的模型是Claude Opus 4.6和GPT-5.5,没错,都是国外公司的产品。虽然很不愿意承认,但在写代码能力这一块,这两个模型能力绝对是一骑绝尘。
缺点是,贵,真的太贵了,每个月的AI充值已经超越我家水、电、煤、网加起来的费用了,这还是在我抠抠搜搜的、简单任务切换免费模型的情况下的花销。
说了这么多,还没解释下模型到底是个什么东西,为什么会有这么大的差异。
可以把大语言模型想象成一个超级压缩包。互联网上公开的文本、代码、知识,全被压缩进了这个“包“里——但它不是简单的zip压缩,而是学会了这些文字背后的规律和逻辑。
就像一个围棋高手看了几千万盘棋谱后,不再需要死记硬背每一步,而是“知道“该怎么下了。
你在对话框里打字问它问题,它做的事本质上就一个:猜下一个字该说啥。只不过它猜得极其准,因为它“读过“的东西比任何人一辈子能读的都多得多得多。
以前的大模型像是一个记忆力超强的书呆子——你问它“静夜思下一句是什么“,它能秒答“疑是地上霜“。但你让它写一份营销方案,它就只会拼凑一些看起来很对但实际没什么用的废话。
现在的模型不一样了,它不光记住了知识,还具备了推理能力。你给它一个复杂问题,它会像人一样拆解、思考、一步步得出结论。这也是为什么模型能写代码——写代码本质上就是“把需求拆解成逻辑步骤,再翻译成编程语言“,而这恰好是推理能力的体现。
所以模型跟模型之间的差距,说白了就是:
“读过“的东西多少不同(训练数据),”猜字“的准确率不同(模型能力),能处理的“字数“不同(上下文窗口)
就这么简单。
所以当DeepSeek V4横空出世后,我就赶紧试了下,我用Claude Code接了DeepSeek V4,说实话,第一反应是震惊——这玩意儿写代码的水平竟然真的能跟Claude和GPT掰掰手腕了(虽然还是逊色的,但比以前只能望其项背好多了)。
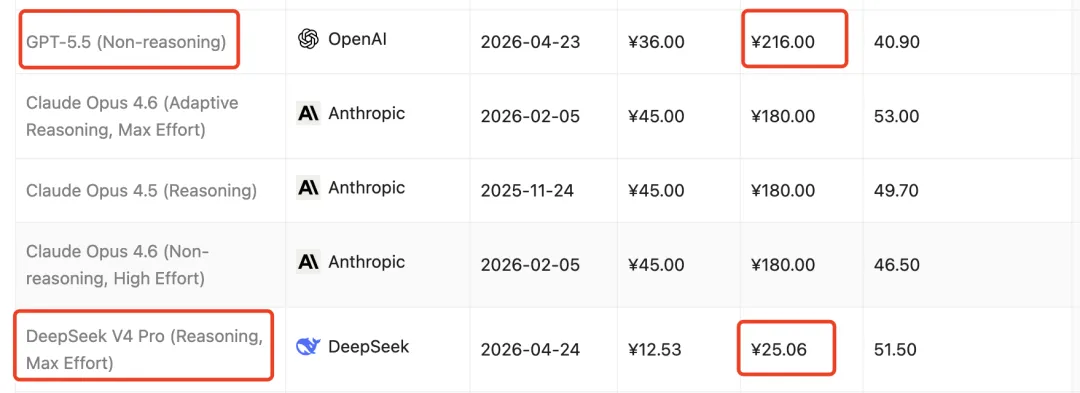
最关键的是,便宜太多了(都这个价格了,还要什么自行车)。我这几天把大部分日常任务都切到了DeepSeek V4 Pro上,只有遇到特别复杂的架构设计或者疑难问题才会切回Claude。就这一个动作,每个月立省好几百。
但DeepSeek V4 Pro肯定也不是完美的。用了一段时间,我明显感觉到它有几个短板:
第一,中文理解有时候不在线。偶尔会出现一些很基础的错误,比如让它总结一段中文文章,它抓错了重点,或者理解偏了某个句子的意思。
第二,多模态约等于没有。我要画个架构图、做个流程图、分析个复杂图表的时候,还是得乖乖切回GPT。
第三,生态还不够成熟。配套的工具链、第三方集成、插件这些,跟OpenAI和Anthropic比还有不小差距。
但即使有这些不足,DeepSeek最让我震撼的还不是能力本身,而是它在受限硬件上做到的这一切。
要理解这事儿有多难,得先明白训练一个模型是啥概念。
想象一下,你是一个超级学霸,要在一年内学完人类积累的所有知识——数学、物理、哲学、编程、几十种语言、无数本书。你肯定不是一个人学,你得叫一大帮人一起来学,大家一起分工、互相讨论、同步进度。
训练大模型也是类似的。它不是在一台电脑上跑的,而是成千上万块芯片连在一起,组成一个巨大的“算力集群“,一起干活。
问题来了:芯片之间要频繁地交换数据、同步状态,就像那群一起学习的人要不断开会对齐进度。这个过程中,芯片的算力、芯片之间的通信速度、稳定性,每一项都会直接影响最终结果。
现在英伟达的高端芯片不卖给中国了。H100、B200这些最新最强的卡,中国企业拿不到。能买到的是H800——英伟达为了合规专门做的”出口管制版”,它的算力跟H100一样,但芯片之间互联通信的带宽被砍了一大半。
打个比方:
让OpenAI用H100/B200去训模型,就像给你一个设备齐全的现代化厨房,有最好的灶台、烤箱、刀具,旁边还配了个助理帮你打下手。你做菜自然又快又好。
让DeepSeek用H800训模型,同一套炉灶,但水管被人拧细了一半,排风扇的转速被限制了,烤箱的电源线被拔了一根。菜还是能炒,但出菜速度被卡脖子了——不是因为你厨艺不行,是你每做一步都得等水烧开、等风排出去。
但DeepSeek愣是用这套被阉割过的设备,做出来一桌能跟米其林餐厅叫板的菜。
这背后的工程优化、训练技巧、架构创新,真的不是一句“牛逼“就能概括的。你得在算法的每一层、每一处想办法省显存、提效率、压带宽,把硬件的每一滴性能都榨干。
前段时间还有一个新闻让我印象很深:荷兰半导体设备巨头ASML的首席执行官最近接受采访时说了一句话——“试图孤立中国,只会加速中国在芯片技术上的创新。“他还打了个比方:你越是阻止一个人接触健身器材,他就越会去做俯卧撑、引体向上,用自重训练练出一身肌肉。原话大概是这个意思。
DeepSeek就是那个被逼着做俯卧撑的人。买不到最好的芯片,那就把算法优化到极致,硬是走出了一条跟OpenAI完全不同的技术路线。讽刺的是,这条被“逼“出来的路,后来反而被学术界认为是更高效的方向。
所以现在我自己的工作流变成了一个拼盘:
写代码、Debug → DeepSeek V4(省钱主力)/ Claude Opus 4.7+GTP 5.5(攻坚)
写文档、做PPT、长文分析 → Kimi(长上下文yyds)
查资料、日常问答→ 混着用,哪个快用哪个
练口语→ 豆包(就这个场景它还行)
画图、多模态→ GPT 5.5(暂时还离不开)
每个月算下来,AI订阅费还是得大几百块,但比之前纯用海外产品的时候降了不少。
回到豆包收费这件事,我觉得是好事。训练的巨大成本本身就摆在那儿呢,市场需要合理化竞争,长远的发展下去,最终受益的是用户,当然了,用户买不买单,就看市场了。
最后送给大家V4发布时,DeepSeek官网上的一句话,我个人非常喜欢。
“不诱于誉,不恐于诽,率道而行,端然正己”。
国产模型,冲啊!
