 夜雨聆风
夜雨聆风





从零搭一个能用的Agent:让AI学会用工具
从零搭一个能用的Agent:让AI学会用工具
AI 光会聊天不算 Agent。真正的 Agent,是你说”帮我查一下北京天气”,它真的去查了、查到了、告诉你了。这篇先用裸 API 搞懂原理,再用 CrewAI 框架快速实现。
前言
上一篇选完了框架,这篇正式动手。
但我不会一上来就甩框架代码。如果你不知道底层发生了什么,用框架就是”会开车但不知道发动机怎么转”——能跑,但出了问题不知道去哪修。
所以这篇的路线是:
1.先用裸 API 搭一个最小的 Tool Use Agent——理解核心机制
2.再用 CrewAI 实现同样的功能——感受框架帮你省了什么
3.对比两种方式——你就知道什么时候该用框架,什么时候裸写够了
全程可运行代码,跟着做就能跑。
一、Tool Use 到底是怎么回事
先搞清楚一件事:AI 不会直接执行任何操作。
很多人以为 Tool Use 是”AI 直接调 API”,其实不是。整个过程是这样的:
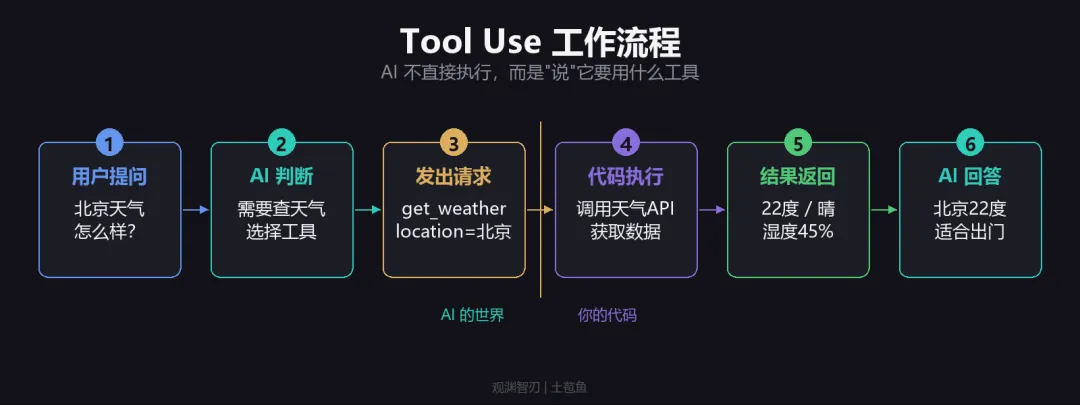
1.用户提问:”北京明天天气怎么样?”
2.AI 判断:这个问题我自己答不了,但我有一个 get_weather 工具可以用
3.AI 发出请求:get_weather(location="北京")——注意,AI 只是说它要用这个工具
4.你的代码执行:你写的代码真正去调天气 API,拿到结果
5.结果返回给 AI:{"temp": 22, "condition": "晴"}
6.AI 生成回答:”北京明天 22 度,晴天,适合出门。”
AI 是”大脑”,你的代码是”手脚”。 AI 决定做什么,你的代码去执行。这也是 Tool Use 安全的原因——你完全控制哪些工具可用、怎么执行。
二、裸 API 实现:先懂发动机
我们用 Claude 的 API 来做最小实现。选 Claude 是因为它的 Tool Use 设计更清晰——用 stop_reason 明确告诉你”我需要调工具”,而不是让你猜。文末附 OpenAI 版本差异对照。
2.1 环境准备
pip install anthropic设置 API Key:
# Windows
set ANTHROPIC_API_KEY=sk-ant-你的key
# Mac/Linux
export ANTHROPIC_API_KEY="sk-ant-你的key"2.2 第一步:定义工具
工具定义就是一份 JSON “说明书”——告诉 AI 你有什么工具、需要什么参数:
tools = [
{
"name": "get_weather",
"description": "获取指定城市的当前天气信息。当用户询问天气相关问题时使用。",
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,如'北京'、'上海'"
}
},
"required": ["location"]
}
}
]重点:
description要写清楚”什么时候用这个工具”。写得越具体,AI 判断越准。
2.3 第二步:写执行函数
工具描述是给 AI 看的,执行函数是给你写的:
import json
def get_weather(location: str) -> str:
"""模拟天气查询(实际项目替换为真实 API)"""
weather_data = {
"北京": {"temp": 22, "condition": "晴", "humidity": 45},
"上海": {"temp": 26, "condition": "多云", "humidity": 72},
"深圳": {"temp": 30, "condition": "阵雨", "humidity": 85},
}
data = weather_data.get(location, {"temp": 20, "condition": "未知", "humidity": 50})
return json.dumps(data, ensure_ascii=False)2.4 第三步:完整的 Tool Use 循环
核心代码——AI 判断 → 工具调用 → 结果返回 → AI 回答:
from anthropic import Anthropic
import json
client = Anthropic()
# 工具注册表(名字 → 函数)
tool_registry = {
"get_weather": get_weather,
}
def chat_with_tools(user_message: str):
messages = [{"role": "user", "content": user_message}]
while True:
# 调用 Claude,带上工具列表
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="你是一个有用的助手,可以查询天气信息。",
tools=tools,
messages=messages,
)
# Claude 明确告诉你:我需要调工具
if response.stop_reason == "tool_use":
# 把 AI 的回复加入对话历史
messages.append({"role": "assistant", "content": response.content})
# 找到 tool_use 块,执行对应函数
for block in response.content:
if block.type == "tool_use":
func = tool_registry.get(block.name)
result = func(**block.input) if func else '{"error": "未知工具"}'
# 把工具结果告诉 Claude
messages.append({
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": block.id,
"content": result
}]
})
# 继续循环,让 Claude 处理结果
else:
# 不再需要工具,返回最终回答
return response.content[0].text
# 测试
print(chat_with_tools("北京今天天气怎么样?"))
# → 北京今天晴朗,气温 22°C,湿度 45%,非常适合外出。
print(chat_with_tools("什么是量子力学?"))
# → 量子力学是物理学的一个分支...(没有调用工具)这段代码大约 40 行。 记住这个数字,等下跟 CrewAI 对比。
Claude 的 Tool Use 有一个优雅的设计:stop_reason == "tool_use" 明确告诉你”我停下来是因为要用工具”。加上 while True 循环,Claude 可以连续调用多个工具——比如你问”北京和上海天气怎么样”,它会连续调两次 get_weather。
把这个过程画成时序图,会更直观:
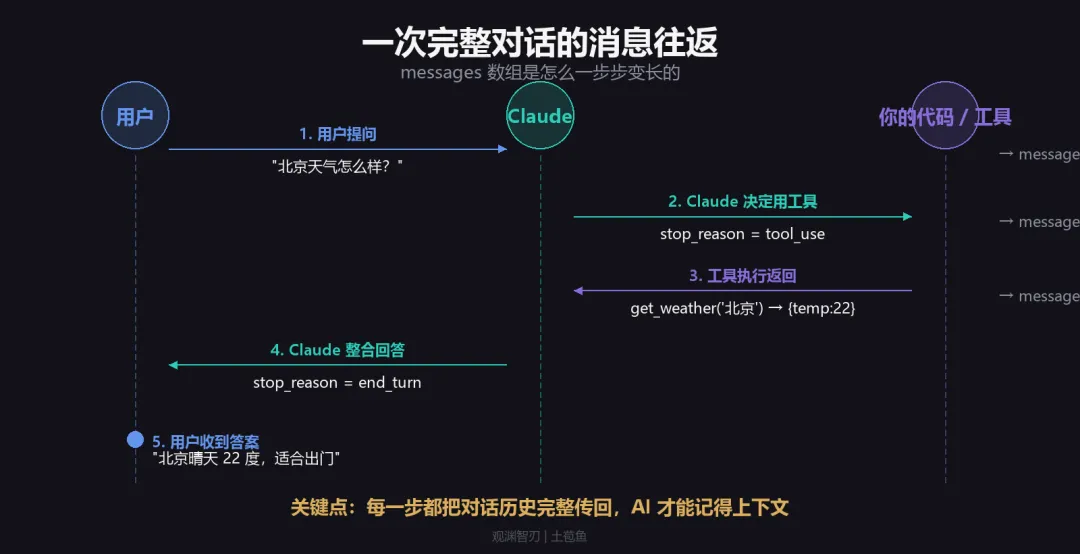
关键点:每次调用 API 时,messages 数组都要把之前的所有历史完整传回去。AI 没有真正的”记忆”,它的”上下文”就是你传给它的 messages。

2.5 完整项目结构
跟着上面跑通后,你的项目长这样——4 个文件就够了:
my-first-agent/
├── .env # ANTHROPIC_API_KEY=sk-ant-xxx
├── requirements.txt # anthropic
├── tools.py # 工具函数(执行层)
└── agent.py # 主程序(描述层 + 编排层)为什么是这个结构?
•tools.py 单独放:加新工具只动这个文件,不污染主逻辑
•tool_registry 字典分派:加工具就是字典 + 工具描述各加一项,主循环不动
•主循环写一次能用:while True + stop_reason 处理任意复杂的多轮工具调用
•不要 agents/ 子目录、不要 __init__.py:项目还小,别过度组织
扩展时怎么加? 接真实天气 API 只改 tools.py 里函数体;加新工具就 tools.py 加函数 + agent.py 的 tool_registry 和 tools 各加一项。
三、CrewAI 实现:开自动挡
同样的功能——查天气的 Agent,用 CrewAI 怎么写?
3.1 安装
pip install crewai crewai-tools3.2 定义工具
CrewAI 用装饰器定义工具,比写 JSON Schema 直观得多:
from crewai.tools import tool
@tool("查询天气")
def get_weather(location: str) -> str:
"""获取指定城市的当前天气信息。当用户询问天气时使用。
Args:
location: 城市名称,如'北京'、'上海'
"""
weather_data = {
"北京": {"temp": 22, "condition": "晴", "humidity": 45},
"上海": {"temp": 26, "condition": "多云", "humidity": 72},
"深圳": {"temp": 30, "condition": "阵雨", "humidity": 85},
}
data = weather_data.get(location, {"temp": 20, "condition": "未知", "humidity": 50})
return str(data)注意:同样的执行逻辑,但不需要手写 JSON Schema。CrewAI 从函数签名和 docstring 自动生成工具描述。
3.3 定义 Agent 和 Task
from crewai import Agent, Task, Crew
# 定义 Agent(角色)
weather_agent = Agent(
role="天气助手",
goal="准确回答用户的天气查询",
backstory="你是一个专业的天气查询助手,能获取各城市的实时天气信息。",
tools=[get_weather],
verbose=True # 打印推理过程,方便调试
)
# 定义 Task(任务)
weather_task = Task(
description="用户问:{query}",
expected_output="用自然语言回答天气情况,包含温度、天气状况和建议",
agent=weather_agent,
)
# 组建 Crew(团队)
crew = Crew(
agents=[weather_agent],
tasks=[weather_task],
verbose=True
)3.4 运行
result = crew.kickoff(inputs={"query": "北京今天天气怎么样?"})
print(result)输出(verbose 模式会打印推理过程):
> Entering new CrewAgentExecutor chain...
I need to check the weather in Beijing.
Action: 查询天气
Action Input: {"location": "北京"}
Observation: {'temp': 22, 'condition': '晴', 'humidity': 45}
Thought: I now have the weather data for Beijing.
Final Answer: 北京今天天气晴朗,气温 22°C,湿度 45%,适合出门活动。这段日志其实就是 Agent 的”内心独白”——Thought(思考)→ Action(行动)→ Observation(观察) 的循环,直到收敛到最终答案:

这个 Thought-Action-Observation 模式叫 ReAct(Reasoning + Acting),是 Agent 推理的经典范式。我们在第 3 篇《Agent 怎么想问题》里详细讲过。CrewAI 默认就是这个模式。
CrewAI 版核心代码大约 20 行。 裸 API 版 40 行。框架帮你省了一半。
3.5 完整项目结构
CrewAI 版结构比裸 API 还简单——3 个文件就够了:
my-crewai-agent/
├── .env # ANTHROPIC_API_KEY=sk-ant-xxx
├── requirements.txt # crewai + crewai-tools
└── agent.py # 工具 + Agent + Task + Crew 全在一起为什么比裸 API 还少一个文件? @tool 装饰器把”工具描述”和”工具实现”合并了——不需要单独维护 JSON Schema。
几个 CrewAI 特有的坑要注意:
•依赖比较重:首次 pip install 要几分钟(几十个包)。建议用独立虚拟环境,跟裸 API 项目分开
•默认走 OpenAI:要用 Claude 必须显式 LLM(model="claude-..."),否则会去找 OPENAI_API_KEY 而报错
•verbose=True 是金矿:能看到完整的 Thought → Action → Observation 推理日志,调试必开
•不要写 system prompt:CrewAI 用 role + goal + backstory 三件套替代,强行写 system 会冲突
四、对比:框架到底帮你省了什么?
两种方式实现同样的功能,区别在哪?
| 维度 | 裸 API | CrewAI |
|---|---|---|
| 工具定义 | 手写 JSON Schema(容易出错) | 装饰器 + docstring(自动生成) |
| 对话循环 | 自己写 if/while 判断 | 框架自动处理 |
| 工具分派 | 自己写 if func_name == "xxx" |
框架自动根据工具名分派 |
| 错误处理 | 自己加 try-except | 框架有内置重试机制 |
| 推理过程 | 看不到(除非手动打印) | verbose=True 直接看 |
| 核心代码行数 | ~40 行 | ~20 行 |
| 多工具扩展 | 每加一个工具,要改分派逻辑 | 往 tools=[] 列表加就行 |
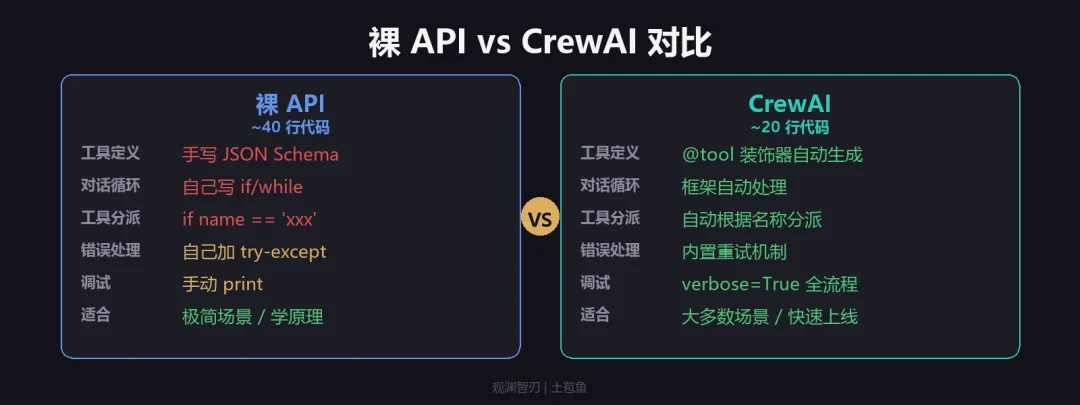
框架帮你省的不是”写代码的时间”,而是”出错的概率”。 JSON Schema 手写一个字段名拼错,调试半天。对话循环多一个 append 少一个 append,结果完全不同。框架把这些容易出错的部分标准化了。
那什么时候用裸 API? 当你的 Agent 逻辑极简(就一个工具、一轮对话),或者你需要极致性能(框架有额外开销),裸 API 反而更合适。
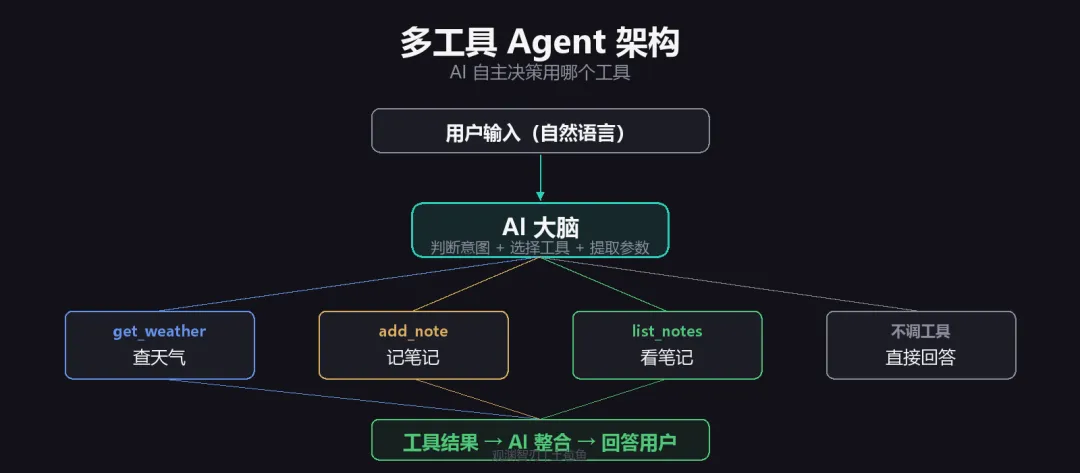
五、进阶:多工具 Agent
不管裸 API 还是 CrewAI,真正有用的 Agent 需要多个工具。我们加一个”记笔记”功能。
CrewAI 版(推荐)
from crewai.tools import tool
notes = []
@tool("记笔记")
def add_note(content: str) -> str:
"""当用户要求记录、保存、备忘某些信息时,调用此工具保存笔记。
Args:
content: 要记录的笔记内容
"""
notes.append(content)
return f"已记录,当前共 {len(notes)} 条笔记"
@tool("查看笔记")
def list_notes() -> str:
"""当用户要求查看、列出已有笔记时调用。"""
if not notes:
return "暂无笔记"
return "\n".join(f"{i+1}. {n}" for i, n in enumerate(notes))
# Agent 直接挂上多个工具
assistant = Agent(
role="私人助手",
goal="帮用户查天气、记笔记,做一个贴心的助手",
backstory="你是用户的私人AI助手,能查天气也能记笔记。",
tools=[get_weather, add_note, list_notes],
verbose=True
)加工具就是往 tools=[] 列表里加——不用改分派逻辑、不用改对话循环。 这就是框架的价值。
AI 会自动判断用户意图:
•“北京天气” → 调 get_weather
•“帮我记一下明天开会” → 调 add_note
•“我记了什么” → 调 list_notes
•“1+1等于几” → 不调工具,直接答
六、三个常见坑
不管用哪种方式,这三个坑你大概率会踩:
6.1 工具描述太模糊,AI 不会用
症状:你问”帮我记个事儿”,AI 没调 add_note,而是回复”好的,你要记什么?”
解法:description 写清楚触发条件:
# 模糊 ❌
"""一个笔记工具"""
# 清晰 ✓
"""当用户要求记录、保存、备忘某些信息时,调用此工具保存笔记内容"""6.2 工具执行出错,AI 编造结果
症状:天气 API 超时,AI 回复了一个编造的天气。
解法:把错误信息明确返回:
@tool("查询天气")
def get_weather(location: str) -> str:
"""..."""
try:
data = call_real_api(location)
return str(data)
except Exception as e:
return f"查询失败:{str(e)}"AI 收到错误信息,会如实告诉用户”天气查询暂时不可用”,而不是编数据。
6.3 工具太多,AI 选错了
症状:你注册了 20 个工具,AI 经常选错或同时调多个不相关的工具。
解法:
•工具数量建议控制在 10 个以内
•工具名和描述要互相区分,避免”记笔记”和”保存笔记”这种歧义
•复杂场景考虑分 Agent——每个 Agent 只挂 3-5 个相关工具

七、OpenAI 版本差异速查
如果你用 OpenAI 而不是 Claude,核心逻辑完全一样,只是 API 格式不同:
| 差异点 | Claude(本文主线) | OpenAI |
|---|---|---|
| 安装 | pip install anthropic |
pip install openai |
| 工具参数名 | input_schema |
parameters(外包一层 function) |
| 判断是否调工具 | stop_reason == "tool_use" |
msg.tool_calls 非空 |
| 返回工具结果 | type: "tool_result" |
role: "tool" |
| 循环方式 | while True(天然支持多轮工具调用) |
通常两轮(请求→工具→回答) |
但如果你用 CrewAI,这些差异完全不用管。 CrewAI 底层自动适配不同模型,你换个 model 名字就行。这是用框架的另一个好处——屏蔽底层差异。
总结
这篇我们用两种方式搭了一个能用工具的 Agent:
裸 API(理解原理):
•Tool Use = AI 说”我要用什么工具” + 你的代码去执行
•核心是对话循环:用户 → AI 判断 → 工具调用 → 结果返回 → AI 回答
•~40 行代码,适合极简场景
CrewAI(框架实现):
•工具用装饰器定义,Agent 用角色描述,一键启动
•自动处理工具分派、对话循环、推理日志
•~20 行代码,适合大多数场景
下一篇预告:给 Agent 装上记忆——用 LangGraph 实现状态管理和长期记忆,让 AI 越用越懂你。
写在最后
这是「Agent系列」的第七篇。从这篇开始,每一篇你都能跑出一个真正能用的东西。
如果你跟着做了,评论区分享你的 Agent 能做什么——看到真实用例我会回复。
往期推荐:
•AI Agent到底是什么?别再跟聊天机器人搞混了
•AI Agent的大脑长什么样:记忆、推理与工具
•Agent怎么想问题:三种思考模式决定它有多聪明
•AI Agent不是玩具了:2026年,谁在替你干活?
•一个Agent不够用?教它召唤一个团队
•Agent框架选型:别挑花了眼,三步选对你的第一个框架
关于作者 | 观渊智刃 & 土苞鱼
专注 AI 工具应用与效率提升,分享 AI 时代的工作方法论。
原创不易,如果觉得有帮助
欢迎点赞、在看、转发支持一下 ❤️