 夜雨聆风
夜雨聆风





智能招聘面试评估Agent系统【附带源码】
传统招聘面试评估流程面临效率低、主观性强、标准不统一等痛点。HR需手动筛选大量简历、主观判断候选人匹配度,易造成优秀人才流失或人岗不匹配。
智能招聘面试评估Agent系统基于多Agent协作架构,实现从简历解析、岗位匹配、多维评估到面试决策的全流程自动化。系统通过5个专业Agent协同工作,从技术能力、软技能、文化匹配等维度量化评估候选人,自动生成结构化评估报告和面试问题清单。该系统可显著降低HR重复劳动,提升评估客观性和一致性,缩短招聘周期,助力企业精准识人、高效引才,为人才战略决策提供数据支撑。
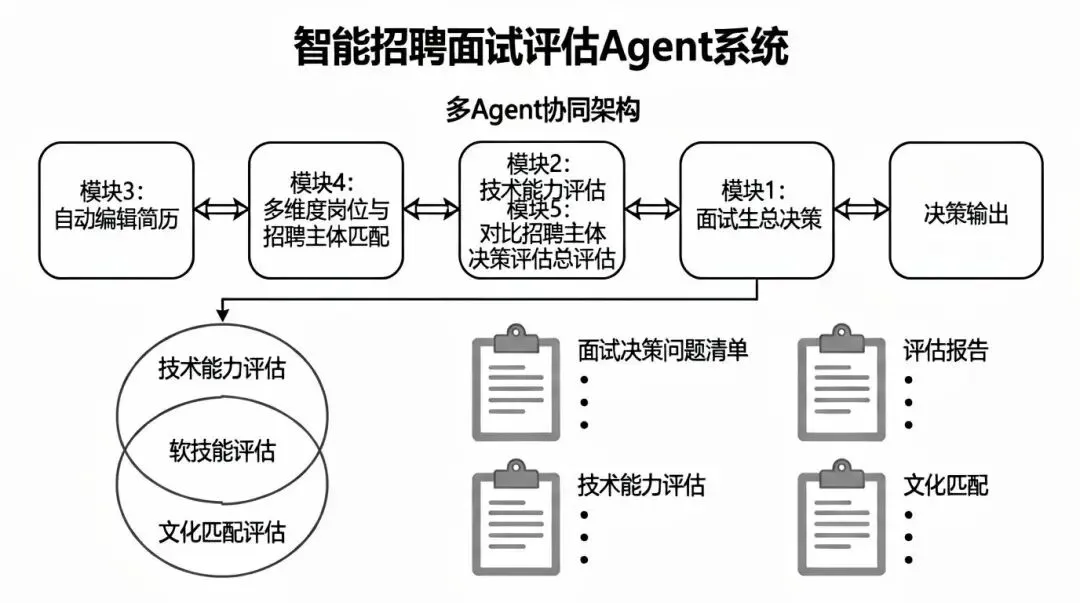
从简历到面试全流程自动化,减少HR重复劳动,提升评估客观性
系统架构
简历文档(PDF/DOCX)
│
▼
┌──────────────┐
│ 简历解析 │ ← PDF(MinerU)/DOCX(python-docx) + LLM结构化
│ Agent │
└──────┬───────┘
│ 结构化简历JSON
▼
┌──────────────┐
│ 岗位匹配 │
│ Agent │ ← JD(PDF/DOCX/MD) + 简历 → 匹配度评分(0-100)
└──────┬───────┘
│ 匹配结果
├─────────────┬─────────────┐
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 技术能力 │ │ 软技能 │ │ 文化匹配 │ ← 并行执行
│ 评估Agent │ │ 评估Agent │ │ 评估Agent │
└─────┬──────┘ └─────┬──────┘ └─────┬──────┘
└──────────────┼──────────────┘
▼
┌──────────────┐
│ 面试决策 │
│ Agent │ → 综合评分 + 面试问题清单
└──────────────┘协作模式:串行流水线 + 并行评估
LLM调用:约8-12次(解析1次 + 匹配1次 + 评估3次 + 决策1次 + 搜索N次)
5个Agent说明
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
项目结构
interview-evaluator-mas/
├── main.py # 入口文件:命令行参数解析,启动评估流水线
├── orchestrator.py # 主编排器:串行+并行流程控制,HTML报告生成
├── config.py # 全局配置:LLM后端/MinerU/搜索/评分阈值
│
├── core/ # 核心基础设施层
│ ├── __init__.py
│ ├── llm_client.py # LLM客户端:千帆+Ollama双后端路由,重试/降级/统计
│ ├── search_client.py # 百度AI搜索客户端:单条/批量搜索,结果文本提取
│ ├── mineru_parser.py # MinerU PDF解析:上传→轮询→下载ZIP→提取Markdown
│ ├── docx_parser.py # Word文档解析:python-docx提取段落+表格文本
│ └── document_parser.py # 统一文档解析入口:按扩展名自动路由(.pdf/.docx/.md/.txt)
│
├── agents/ # Agent业务逻辑层
│ ├── __init__.py
│ ├── resume_parser_agent.py # 简历解析Agent:PDF/DOCX→文本→LLM→结构化JSON
│ ├── job_matcher_agent.py # 岗位匹配Agent:6维度加权评分,0-100分匹配度
│ ├── tech_evaluator_agent.py # 技术能力评估Agent:深度/复杂度/广度/成长/影响力
│ ├── softskill_evaluator_agent.py # 软技能评估Agent:5维度+百度搜索验证公开信息
│ └── interview_decider_agent.py # 面试决策Agent:综合4维评分+STAR面试问题清单
│
├── prompt/ # 提示词文件(各Agent独立markdown,运行时动态加载)
│ ├── resume_parser.md # 简历解析提示词:7维度提取规则+JSON输出格式
│ ├── job_matcher.md # 岗位匹配提示词:6维度评分规则+量化标准
│ ├── tech_evaluator.md # 技术评估提示词:深度推断方法+技能分析框架
│ ├── softskill_evaluator.md # 软技能评估提示词:行为推断+搜索结果甄别规则
│ └── interview_decider.md # 面试决策提示词:加权公式+4级推荐+问题设计原则
│
├── data/ # 输入数据目录
│ └── jd_llm_engineer.md # 示例岗位描述(高级大模型算法工程师)
│
└── output/ # 评估报告输出目录(HTML格式,自动按时间戳命名)文件职责速查
|
|
|
|
|---|---|---|
main.py |
|
|
orchestrator.py |
|
|
config.py |
|
|
core/llm_client.py |
|
|
core/search_client.py |
|
|
core/mineru_parser.py |
|
|
core/docx_parser.py |
|
|
core/document_parser.py |
|
|
agents/resume_parser_agent.py |
|
|
agents/job_matcher_agent.py |
|
|
agents/tech_evaluator_agent.py |
|
|
agents/softskill_evaluator_agent.py |
|
|
agents/interview_decider_agent.py |
|
|
快速开始
环境准备
# 安装依赖
pip install requests python-docx
# (可选)Ollama本地运行
ollama serve
ollama pull qwen2.5:7b运行方式
# 方式1: PDF简历 + Markdown JD
python main.py 简历.pdf data/jd_llm_engineer.md
# 方式2: Word简历 + Word JD
python main.py 简历.docx 岗位描述.docx
# 方式3: Word简历 + PDF JD
python main.py 简历.docx jd.pdf
# 方式4: 使用Ollama后端
LLM_PROVIDER=ollama python main.py 简历.pdf data/jd_llm_engineer.md
# 方式5: 无参数运行(使用data目录中的示例文件)
python main.py支持的文件格式:
-
简历: .pdf(MinerU解析) /.docx(python-docx解析) -
JD: .pdf/.docx/.md/.txt
配置说明
通过环境变量或修改 config.py 进行配置:
|
|
|
|
|
|---|---|---|---|
|
|
LLM_PROVIDER |
qianfan |
qianfan
ollama |
|
|
QIANFAN_API_KEY |
|
|
|
|
QIANFAN_MODEL |
ernie-x1-turbo-32k |
|
|
|
OLLAMA_BASE_URL |
http://localhost:11434 |
|
|
|
OLLAMA_MODEL |
qwen2.5:7b |
|
|
|
MINERU_TOKEN |
|
|
|
|
BAIDU_SEARCH_API_KEY |
|
|
评估维度详情
岗位匹配 (权重30%)
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
技术能力 (权重30%)
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
软技能 (权重20%)
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
文化匹配 (权重20%)
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
面试建议等级
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
软技能搜索策略
软技能评估Agent会智能拆分搜索关键词,通过百度AI搜索获取候选人公开信息:
- 姓名 + 公司名
:验证职业经历 - 姓名 + 技术领域
:查找技术影响力(博客、开源) - 姓名 + 行业活动
:查找公开分享、演讲 - 姓名 + 学校
:学术背景验证
搜索结果会与简历信息交叉验证,仅采纳能确认与候选人相关的内容。
输出报告
系统生成HTML可视化报告,包含:
-
综合评分概览(四维雷达图) -
评估摘要(一句话总结 + 优势/关注点) -
各维度详细评分表 -
技能分析(核心技能 + 缺失技能) -
面试问题清单(技术类 + 软技能类 + 文化适配类) -
面试建议和注意事项
报告保存在 output/ 目录下。
通过网盘分享的文件:interview-evaluator-mas.zip
链接: https://pan.baidu.com/s/1Yhph1V9emc8QfIwPNog_Ng?pwd=6cwy 提取码: 6cwy
–来自百度网盘超级会员v4的分享