 夜雨聆风
夜雨聆风





提取拆分字符串,用REGEXP函数解锁WPS表格的文本处理超能力
“你是否曾在表格里为处理杂乱文本头疼过?要从混杂了文字、数字、符号的单元格里提取姓名、电话号、数量、金额等,要批量校验几千条号码格式是否正确,要把不规范的日期统一成标准格式等等。过去这些操作要么需要嵌套好几层文本函数,要么只能手动一条条修改,效率低还容易出错。”
作为WPS表格独有的正则表达式函数,REGEXP函数的出现直接解决了这些痛点。它把强大的正则表达式能力封装成了简单的函数形式,只需一个公式就能实现从前复杂操作才能完成的文本处理需求,真正让复杂文本处理变得简单高效。
01
—
REGEXP函数基础说明
REGEXP函数基于Perl兼容的正则表达式(PCRE)语法标准,支持文本的提取、判断、替换三大核心能力,默认区分大小写,语法结构非常简洁:
=REGEXP(原始字符串, 正则表达式, [匹配模式], [替换内容])|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
\1、\2引用正则表达式中的分组内容 |
02
—
新手必备基础正则规则
新手也不用害怕正则表达式复杂,日常90%的场景用以下几个基础规则就能覆盖,规则可直接使用。更多常用的规则表达式,已放到文末列表。
|
|
|
|
|---|---|---|
\d |
|
\d{11}
|
[一-龟] |
|
[一-龟]{2,4}
|
[A-Za-z] |
|
[A-Za-z0-9._%+-]+@
|
+ |
|
\d+
|
^/$ |
|
^1[3-9]\d{9}$
|
() |
|
(\d{3})\d{4}(\d{4})
|
03
—
高频场景使用案例
下面的案例均来自真实办公场景,公式可以直接套用。
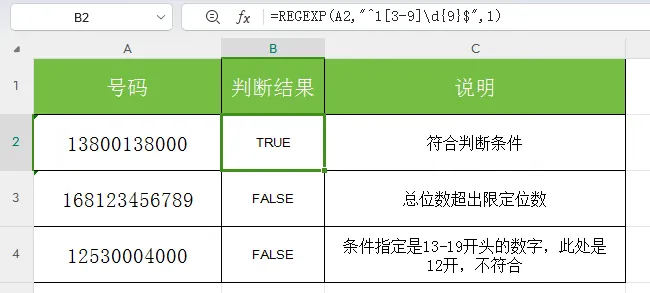
案例1:数据格式校验(判断模式)
场景:校验客户信息表中的手机号是否符合11位规范,避免后续通知短信发送失败。
=REGEXP(A2,"^1[3-9]\d{9}$",1)效果:符合规范的手机号返回TRUE,格式错误(比如位数不对、号段不存在)的返回FALSE,配合条件格式可以一键标红错误数据。
正则解析:
^1 限定手机号必须以1开头[3-9] 限定第二位为3-9的有效号段\d{9} 限定后面9位均为数字$ 限定整个字符串长度为11位,避免多字符错误
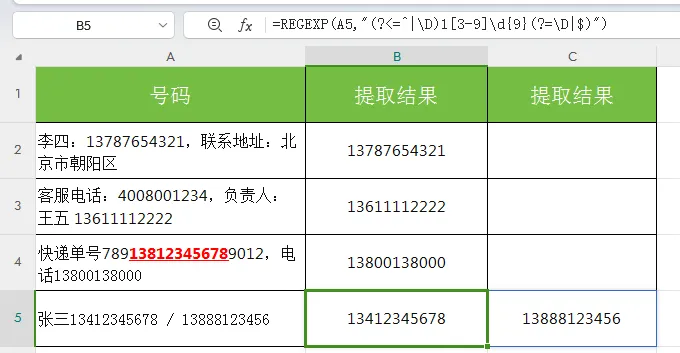
案例2:特定内容提取(提取模式)
场景:从混有汉字、数字、符号的快递地址里,批量提取所有手机号码。公式:
=REGEXP(A2,"(?<=^|\D)1[3-9]\d{9}(?=\D|$)")效果:即使单元格里同时包含姓名、地址、多个手机号,也能精准把所有手机号提取出来。
正则解析:
-
(?<=^|\D)
用于限定我们要匹配的内容(比如手机号),它的前面必须是「字符串开头」或者「非数字字符」,如果不限定,那么一长串数字中,如有符合手机号规则的,也会被匹配进来。具体请看示例图片
-
1[3-9]\d{9}
匹配11位手机号,且是1开头,第二位是3-8的数字串
-
(?=\D|$)
与前面的前面限定配套使用,限定必须是【字符串】或者【非数字】结尾,以确保不会误截取。
案例3:特定内容提取后计算(提取模式进阶用法)
场景:如果需要提取数字并直接求和或乘积的,套个SUM、PRODUCT函数即可,如根据规格得体积、根据数量单价得金额等。公式:
=SUM(--REGEXP(A2,"[0-9.-]+"))=PRODUCT(--REGEXP(A2,"[0-9.-]+"))
效果:提取单元格,混合记录的数量,单价,长宽高等数据,并计算
正则解析:
-
[0-9.-]+
[]里面是范围,表示提取0-9之间的数字,小数点,负号,括号外面的+表示匹配一次或多次
-
–REGEXP()
前面的两个负号的作用是让提取的字符经过负负运算转换为数字类型,负号其实可以用Value()函数套进去转换,但–更直接。
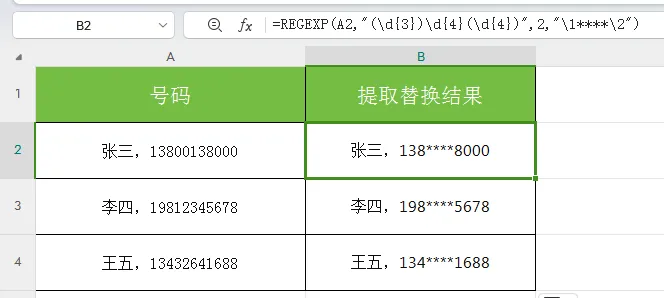
案例4:批量内容替换(替换模式)
场景:导出的客户信息中手机号是明文显示,需要批量把中间4位替换为****,实现隐私脱敏。
公式:
=REGEXP(A2,"(\d{3})\d{4}(\d{4})",2,"\1****\2")效果:原始数据: 张三,13800138000 结果:张三,138****8000
正则解析:
-
(\d{3}),(\d{4})
用()分组提取,提取出来的结果用于后面的替换,这里分别提取前3位,后4位
-
中间的2参数,是替换模式
-
\1****\2
\1表示第一组提取结果,即(\d{3}),\2表示第一组提取结果,即(\d{4})
04
—
常用的正则规则
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|