当前时间: 2026-06-02 21:58:08
更新时间: 2026-06-02
分类:软件教程
评论(0)
清华LongTraceRL:AI长文档推理新突破
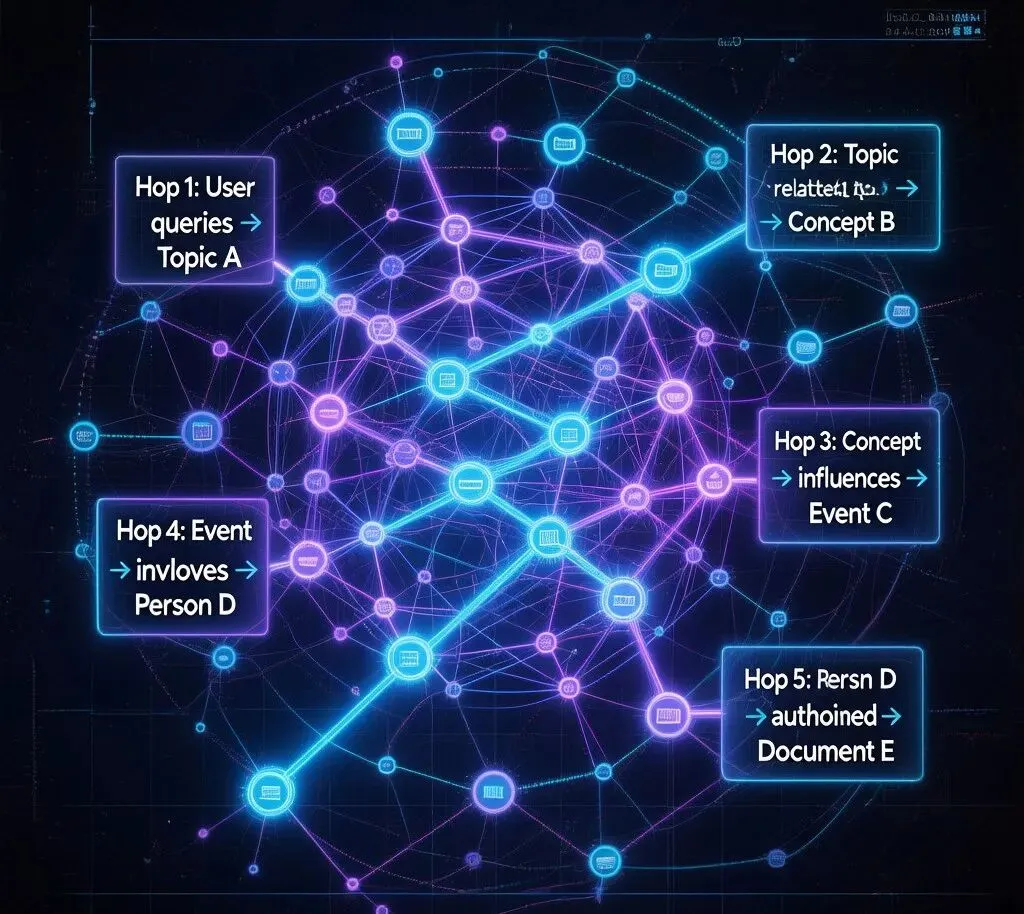
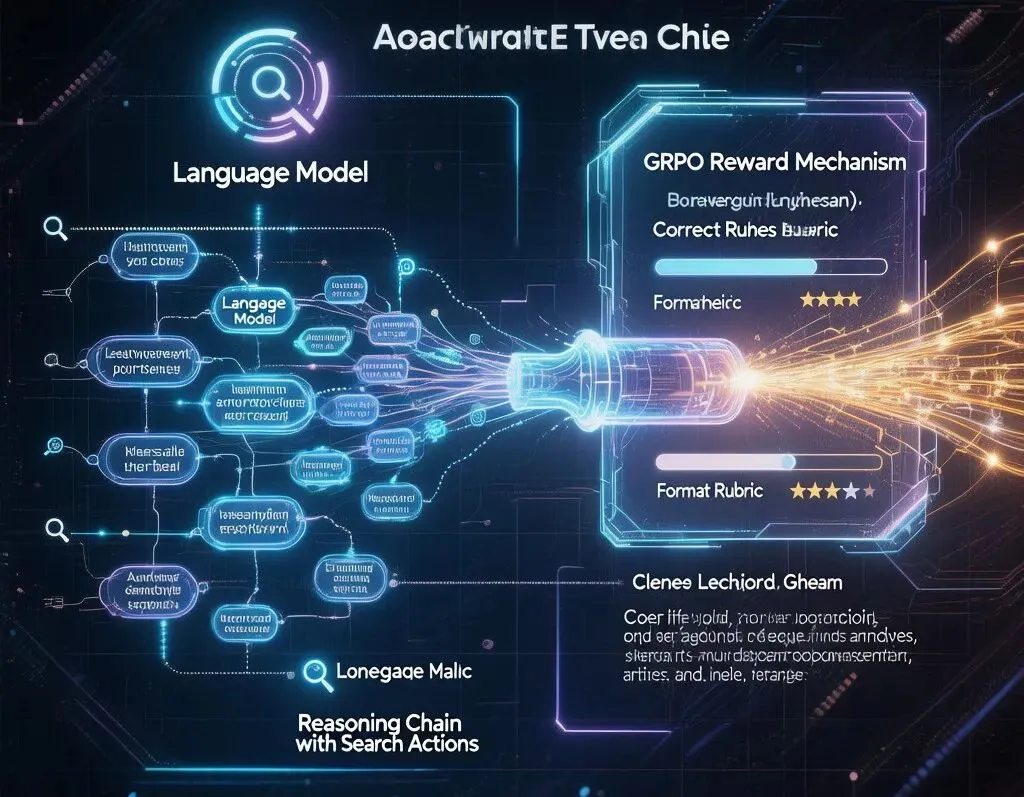
让AI在12万字中精准找到答案——清华团队LongTraceRL的搜索智能体训练法 当AI面对12万字:一次”大海捞针”的升级版 想象这样一个场景:你需要从一份12万字的文档中回答”2023年诺贝尔物理学奖得主在获奖前最后一次公开演讲中提到的量子纠缠实验,与2021年一篇Nature论文中的结论是否矛盾?” 这不仅仅是一次搜索。你需要理解两条平行的时间线,在数十个段落之间建立关联,还要判断两份文档中看似矛盾的表述是否真的冲突——这是典型的“多跳长上下文推理” (multi-hop long-context reasoning)1。 当前最强的AI大模型——无论是GPT-5.3、Claude Opus 4.6还是DeepSeek-R1——面对这种任务时,表现如何?坦白说,远不如我们想象的那么好 。 以DeepSeek-R1蒸馏的8B模型在AA-LCR基准测试(Artificial Analysis Long Context Reasoning)上为例:正确率仅13.8% 1。这意味着在100道专家精心设计的长文本推理题中,模型大约只能做对14道——比随机猜(25%)还差。 问题出在哪里?不是模型不够聪明。DeepSeek-R1-8B在常规推理任务上表现优异。但当上下文膨胀到数万字甚至十几万字时,模型开始”迷失”——它看到了所有的信息,却不知道哪些是关键,哪些是噪音 。 2026年5月29日,清华大学知识工程组(THU-KEG)在arXiv上发布的一篇论文,为这个问题提供了一个令人眼前一亮的解决方案。论文名为LongTraceRL :通过搜索智能体轨迹和Rubric奖励机制,让大模型学会在12万字的汪洋中精准定位和推理1。 这篇文章今天(6月1日)在HuggingFace论文热榜上高居第二,热度仅次于一篇多模态架构论文。本文将带你深入解读LongTraceRL的核心思想、实验设计和深远影响。 核心问题:为什么RL训练在长上下文上这么难? 要理解LongTraceRL的贡献,先要理解它试图解决的问题。 近年来,强化学习(RL)已成为提升大模型推理能力的核心手段。DeepSeek-R12通过GRPO(Group Relative Policy Optimization)算法在数学和编程任务上取得了惊人突破,OpenAI的o系列模型同样依赖RL进行推理训练。 但是,当RL训练从”短推理”扩展到”长上下文推理”时,两个棘手的问题出现了: 问题一:训练数据的干扰项太”弱” 现有的长上下文RL训练数据(如DocQA3、LoongRL4、LongRLVR5)通常通过随机采样或单次搜索来添加干扰文档。这产生的问题是:干扰项和关键证据之间的”困惑度”差距太小 。换句话说,模型很容易区分哪些文档相关、哪些无关,因为无关文档往往主题迥异。 LongTraceRL团队用一个量化指标揭示了问题的严重性:在随机采样策略下,干扰文档中包含黄金实体(gold entity)的比例仅为0.16% 1。这意味着99.84%的干扰文档对模型几乎没有迷惑性——它们太容易排除了。 问题二:奖励信号太”稀疏” 标准RL训练只关注最终答案是否正确 (outcome-only reward)。但长上下文推理是一个多步过程:读取文档→定位关键句→建立多跳链接→整合推理→给出答案。如果只在最后一步给奖励,模型无法知道”我读对文档了吗?””我找对关键句了吗?”——这正是RL中经典的”稀疏奖励问题”。 LongTraceRL的作者们打了个精妙的比喻:这就像考试时只告诉你”不及格”,却不告诉你错在哪道题、哪个知识点——你永远不知道该往哪个方向改进。 核心洞察: 要让AI真正掌握长上下文推理,不仅需要更有迷惑性的训练数据 ,还需要更细粒度的过程监督信号 。LongTraceRL正是从这两个维度同时突破。三大创新:知识图谱、搜索轨迹与Rubric奖励 LongTraceRL的方法论由三个紧密耦合的创新组成。让我们逐一拆解。 创新一:知识图谱随机游走——生成真正的”8跳”难题 首先,如何创建”足够难”的训练问题?LongTraceRL的答案是:知识图谱随机游走(KG Random Walk) 。 :从Wikipedia超链接图中随机选取一个实体作为起点(v₀)。 :LLM在每一步从最多5个候选页面中选择”最相关”的下一个实体,累积8步(k=8),形成一条知识链 [v₀, v₁, …, v₈]。 :GPT-5.2等强模型根据这8个实体的Wikipedia文本,合成一个必须依次经过这8个节点才能回答 的多跳问题。答案锁定为最后一个实体v₈的某个属性。 :所有可识别信息(人名、地名、日期)必须被改写(paraphrase),防止模型通过关键词匹配走捷径。 最终生成了2815个 训练样本,每个样本包含8跳推理链,目标上下文长度128K tokens ——大约是12万中文字符。 这些问题的难度远超现有的训练数据集。作为对比:DocQA的上下文长度仅2K-20K tokens ,LoongRL为16K tokens ,LongRLVR为8K-64K tokens 1。LongTraceRL的128K目标长度,直接拉开了数量级的差距。 创新二:搜索智能体轨迹——构建”高迷惑性”干扰项 有了难题,还需要在题目旁边铺满”高明”的干扰选项。LongTraceRL的方案堪称巧妙:让AI搜索智能体先做一遍题,然后利用它的搜索行为来分类干扰文档 。 为每道题部署搜索智能体(search agent),执行多轮搜索→打开→阅读→引用操作。 记录完整轨迹:哪些文档被搜索到?哪些被打开并阅读?哪些最终被引用? 按照”先填Tier-1、再补Tier-2″的策略,将干扰文档填充至128K tokens目标长度,然后随机打乱所有文档顺序。 这套方法的效果有多么惊人?以下是论文中各干扰策略的关键指标对比1:
traj-tiered(分层轨迹) 10.34% 50.03%
从0.16%到10.34%,迷惑性提升了64倍 。Tier-1文档单独能达到63.23%的迷惑度 ——这意味着超过六成的干扰文档在主题和实体上与正确答案高度重叠,对模型构成了真正的考验。 创新三:Rubric奖励——给推理过程”打分” 这是LongTraceRL最具方法论价值的设计。传统的RL训练只给最终答案打分(对=1,错=0)。LongTraceRL引入了一种Rubric奖励机制 (rubric reward),为推理过程提供细粒度的监督信号。 :每道题的人工标注中包含”黄金实体集合”——即正确推理链上应该出现的所有中间实体 {e₁, e₂, …, e₈}。 :计算模型输出中引用了多少黄金实体。公式简化为:引用实体数 / 总实体数。 :每个训练问题生成8个采样响应(GRPO的组大小G=8),Rubric分数除以组内最高分,确保不同难度题目间可比。 :Rubric奖励仅授予最终答案正确的响应 ——这是防止”奖励黑客”(reward hacking)的关键。如果模型答案错误却因提到了几个实体而获得rubric奖励,它就会学会”碰瓷式推理”——枚举实体但不真正建立逻辑链。 最终奖励公式:r = (1-α)× 结果奖励 + α × Rubric奖励 ,α=0.3时效果最优。 训练配置速览 算法:GRPO(组大小8,全局batch size 128) 最大上下文:160K tokens(128K prompt + 32K response) 实验结果:”少写多读”的胜利 LongTraceRL在3个不同规模的推理模型(4B/8B/30B)和5个长上下文基准测试上进行了全面评估。结果令人印象深刻。 Qwen3-4B上的主实验结果
LongTraceRL 41.8 45.8 79.5 44.1 83.8 59.0
平均分从53.3提升至59.0(+5.7),超越所有基线方法,比最强基线LongRLVR高出2.5分 。在最具挑战性的AA-LCR基准上,提升幅度达到惊人的+8.6(33.2→41.8) 。值得注意的是,如果移除Rubric奖励(即LongTraceRL-GRPO变体),平均分回落到53.7——几乎回到基线水平(53.3)。这清晰地表明:Rubric奖励是LongTraceRL性能提升的主要驱动力,而非数据本身 。 跨模型规模的一致性提升 在8B模型(DeepSeek-R1-0528-Qwen3-8B)上,平均分从42.7提升至43.8(+1.1);在30B MoE模型上,从60.5提升至63.7(+3.2)。所有三个规模、五个基准,LongTraceRL一致优于 所有对比方法。 30B模型的AA-LCR得分达到53.5——对于12万字级别的多跳推理,这是一个非常有竞争力的数字。考虑到训练仅使用了2815个样本和200步RL更新,这个性价比堪称高效。 消融实验:每个组件都至关重要 LongTraceRL包含多个精心设计的组件,论文通过系列消融实验验证了每个组件的重要性: 1. 干扰项策略消融 :traj-tiered(59.0平均分)> traj-random(57.4)> search(56.7)> random(55.7)> Base(53.3)。分层轨迹策略带来的增益超过随机采样策略3.3分 ,尤其在AA-LCR上差距达7.6分 。2. α权重消融 :α=0.3(59.0)为最优。太小(0.1→58.3)减弱过程信号,太大(0.5→57.1)稀释结果目标,导致模型偏向实体提及捷径。3. 正向仅策略 :同时给正确和错误响应rubric奖励导致平均分下降1.9分 (59.0→57.1),AA-LCR下降4.8分,证明错误响应的rubric奖励确实会误导优化方向。关键结论: LongTraceRL不依赖更大的模型或更多的数据,而是通过更聪明的训练数据构建 和更细粒度的奖励设计 ,让中小规模模型在长上下文推理上实现了质的飞跃。技术深挖:为什么”搜索轨迹”如此重要? LongTraceRL最精妙的设计,是将搜索智能体的行为轨迹 转化为训练信号的来源。这背后有一个深刻的洞察:
一个优秀的搜索智能体在筛选信息时的行为模式——它选择打开哪些文档、阅读到什么深度、最终引用哪些段落——本身就编码了”什么是迷惑性的、什么是确定性的”这一关键判断。
(Tier-1):代表了”看起来相关但实际是歧途”的信息。它们通常包含正确答案实体链上的部分实体,却用于错误的推理路径。例如,问题问”量子纠缠与超导”的关系,这些文档可能大谈”量子纠缠在通信中的应用”——相关,但不回答核心问题。 (Tier-2):仅标题或摘要与关键词匹配,但内容质量不足以引起智能体的兴趣。 这种分层思想类似于人类阅读策略:当你需要回答一个复杂问题时,你会快速浏览标题和摘要(Tier-2级别),然后深入阅读一部分你认为最相关的文章(Tier-1级别),最后引用其中的关键段落。而那些你读了但最终没用的文章——正是最有价值的”反面教材” 。 LongTraceRL的做法,本质上是用AI的搜索行为来模拟人类专家在长文档中寻找答案时的信息过滤过程,并将这个过程的”痕迹”转化为训练数据。 对AI Agent的深远影响 LongTraceRL的意义远不止于发表一篇arXiv论文。它的方法论指向了AI智能体(AI Agent)发展的下一个关键方向。 1. 搜索智能体+LLM的闭环训练 目前大多数RAG系统和搜索增强LLM是”松耦合”的:检索器和生成器分开训练,甚至来自不同团队。LongTraceRL展示了用搜索行为训练推理能力 的可能性——检索和推理不再是两个独立模块,而是一个闭环系统。 可以预见,未来的AI Agent训练将越来越多地利用”工具使用轨迹”作为奖励信号。Colleague.Skill6(同一天发布的另一篇热门论文)也在探索类似的思路——通过专家知识蒸馏自动生成AI技能,其中同样涉及轨迹数据的利用。 2. 过程监督的工程化落地 Rubric奖励提供了一种低成本、可扩展 的过程监督方案。传统的PRM(Process Reward Model)需要训练额外的奖励模型,代价高昂且容易过拟合。LongTraceRL的Rubric方法只需计算实体匹配,无需任何额外模型 ,计算开销几乎可以忽略。 这种方法可以轻易扩展到其他需要过程监督的任务:代码生成(检查中间步骤的正确语法)、数学推理(检查中间推导的一致性)、法律分析(检查引用的法条是否相关)等。 3. 长上下文推理不再是”大力出奇迹” 过去两年,业界解决长上下文问题的主流思路是”堆算力、扩窗口”——Gemini 1.5 Pro做到了100万token上下文,Claude做到了20万token。但LongTraceRL的工作表明:上下文窗口变大,不等于推理能力变强 。更有价值的道路是改进训练方法,让模型在有限窗口内实现更高效的推理。 这对于资源有限的团队尤其重要:你不需要32K张H100去训练一个几万亿参数的超大模型,用32张H800 和2815个精心构造的训练样本 ,就能让一个4B模型在长上下文推理上实现质的飞跃。 局限性与未来方向 尽管LongTraceRL成果显著,但论文也诚实地指出了几个值得关注的局限: 知识图谱的覆盖范围 :当前依赖Wikipedia超链接图构建训练数据,对于期刊论文、代码库、财务报表等结构化程度较低的知识源,KG随机游走方法可能不适用。 8B模型的有限提升 :在DeepSeek-R1-8B上仅提升1.1分,可能与模型本身的蒸馏训练策略有关(蒸馏模型对RL微调的响应可能不同)。 中文长文本的泛化 :所有实验基于英文Wikipedia,中文长文本场景(如法律文书、学术论文)的效果待验证。 更长的上下文 :当前目标128K tokens,扩展到256K甚至1M tokens时,搜索智能体轨迹的收集成本将指数级增长。 作者团队已将代码、数据集和模型权重全部开源在GitHub(THU-KEG/LongTraceRL),为社区的后续研究奠定了基础。 写在最后 LongTraceRL这篇论文之所以值得被认真对待,不是因为它刷了一个榜单,而是因为它提出了一个具有方法论原创性 的思路:用AI自己的搜索行为来训练AI的阅读和推理能力。这种”用行为塑造能力”的范式,可能比模型本身的具体得分更有启发意义。 回顾AI发展的历史,真正定义一个时代的技术往往不是”更大”的模型,而是”更聪明”的训练方法。从Transformer的注意力机制,到RLHF的人类偏好对齐,再到DeepSeek-R1的纯RL推理训练——每一次范式转变都源自方法论的突破。 LongTraceRL能否成为下一个这样的转折点,还有待时间和更大规模实验的检验。但至少在今天,它为我们打开了一扇窗:让AI像人类一样——先搜索,再阅读,然后思考 。 参考文献 Lin N, Zhang J, Hou L, Li J.LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards. arXiv:2605.31584, 2026-05-29. https://arxiv.org/abs/2605.31584 DeepSeek-AI.DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948, 2025-01-22. https://arxiv.org/abs/2501.12948 THUDM.LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-Context Multitasks. arXiv:2412.15204, 2024-12-19. https://arxiv.org/abs/2412.15204 Google Research.FRAMES: Factuality, Retrieval, and Reasoning Measurement Set. arXiv:2409.12941, 2024-09-19. https://arxiv.org/abs/2409.12941 Yang A et al.Qwen3 Technical Report. arXiv:2505.09388, 2025-05-14. https://arxiv.org/abs/2505.09388 COLLEAGUE.SKILL: Automated AI Skill Generation via Expert Knowledge Distillation. arXiv:2605.31264, 2026-05-29. https://arxiv.org/abs/2605.31264 OpenAI.MRCR: Multi-round Coreference Resolution Benchmark. HuggingFace Datasets. https://huggingface.co/datasets/openai/mrcr
上一篇摆地摊 教程 视频+PDF文档
 夜雨聆风
夜雨聆风