 夜雨聆风
夜雨聆风





Java开发者手把手搭AI知识库,公司文档秒变智能问答

有没有碰到过这些糟心场景?
新入职同事拉着你问了800遍”用户退款流程是啥”,你手里的bug改了三小时还没动;面试被问半年前做的旧项目细节,翻遍整个云盘才找到当年的需求文档;甚至上次线上出问题,运维找了半小时配置说明,故障都恢复了文档才刚打开。
我前阵子就被这些事烦得头大,干脆花了两天用Java搭了个专属AI知识库,把公司所有项目文档、业务规则、接口说明全灌进去,现在不管谁问啥,对着知识库发个问题,几秒就给你整明明白白。
今天就把整个搭建过程全分享给你们,看完你也能给自己团队搞一个,效率直接拉满!
——————————-
先搞懂:AI知识库到底是个啥原理?
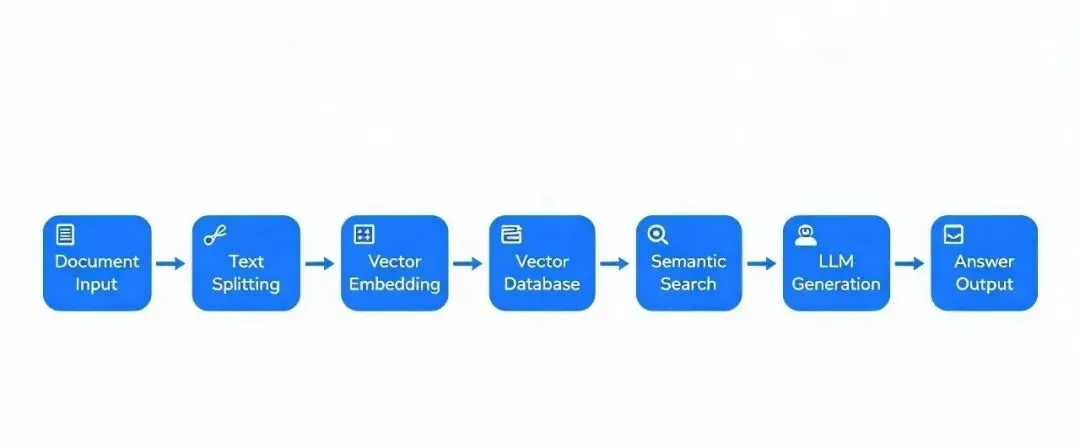
很多人一听到RAG就觉得高大上,其实说白了就三步,你平时找资料也是这个逻辑:1. 检索:你先去自己的文档库里搜和问题相关的内容2. 增强:把搜出来的相关内容整理一下,补充到问题里3. 生成:拿着问题+相关资料去问AI,AI就能结合你的资料给答案
为啥不直接把文档全发给AI?一是单个请求发不了那么长的内容,二是你总不能每次问问题都把几十M的文档全传一遍吧?RAG就是先把你的文档拆成小块转成向量存起来,每次问问题先找最相关的几块内容,再给AI,效率高还准确。
整个架构特别简单,Javaer用Spring Boot就能搞定,再加个向量数据库存向量,最后调用AI大模型的API就行,没有花里胡哨的东西。
技术选型:就选最顺手的,别搞复杂的
咱们Java开发者搞这个,就选生态最成熟的,不用搞那些冷门框架:– 后端框架:Spring Boot 3.x,天天用的东西,上手零成本– 向量数据库:就用Milvus,开源免费,Java SDK特别完善,小团队用单机版足够,要是数据多了也能扩容– AI依赖:直接用Spring AI,Spring官方出的AI工具包,封装了各种向量存储、大模型调用的API,不用自己写一堆HTTP请求– 文档处理:Apache Tika,支持word、excel、pdf、markdown各种格式的文档解析,不用自己写解析逻辑
整个技术栈全是Java生态里的东西,你不用额外学新语言,照着配就行。
——————————-
环境准备:5分钟搞定配置
首先新建个Spring Boot项目,pom.xml里加这几个依赖就行,版本我都给你试好了,直接抄:
<dependencies><!-- Spring Boot Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>3.2.0</version></dependency><!-- Spring AI 向量存储 + 大模型支持 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-milvus-store</artifactId><version>1.0.0-M1</version></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId><version>1.0.0-M1</version></dependency><!-- 文档解析工具 --><dependency><groupId>org.apache.tika</groupId><artifactId>tika-core</artifactId><version>2.9.1</version></dependency></dependencies>
然后是application.yml配置,把你的大模型API密钥和向量数据库地址填上就行,我用的是本地部署的Milvus,默认端口就是19530:
spring:ai:openai:api-key: 你的大模型API密钥base-url: 大模型API地址vectorstore:milvus:host: localhostport: 19530database-name: defaultcollection-name: knowledge_baseembedding-dimension: 1536 # 和你用的Embedding模型维度一致
哦对了,你要是没装Milvus也没关系,用Docker一行命令就能启动:
docker run -d --name milvus -p 19530:19530 -p 9091:9091 milvusdb/milvus:v2.3.5——————————-
核心代码:总共就四个模块,抄就完了
我把核心逻辑都封装好了,你直接复制粘贴就能用,总共就四个步骤:文档加载切片、向量化存储、语义检索、结合AI生成回答。
1. 文档加载与切片
首先得把各种格式的文档读出来,再切成小块,不能整段塞进去,不然检索的时候不准。切片大小我建议设成500字左右,重叠个50字,避免关键信息被切断。
@Componentpublic class DocumentLoader {private final Tika tika = new Tika();/*** 加载本地文档并切片*/public List<String> loadAndSplit(String filePath) throws IOException {// 用Tika自动识别文档格式,提取文本String content = tika.parseToString(new File(filePath));// 按固定大小切片,保留重叠部分int chunkSize = 500;int overlapSize = 50;List<String> chunks = new ArrayList<>();for (int i = 0; i < content.length(); i += (chunkSize - overlapSize)) {int end = Math.min(i + chunkSize, content.length());chunks.add(content.substring(i, end));}return chunks;}}
2. 向量化与存储
切完的文本块要转成向量才能存到向量数据库里,Spring AI已经把Embedding的逻辑封装好了,直接调用就行:
@Servicepublic class KnowledgeService {private final VectorStore vectorStore;private final DocumentLoader documentLoader;public KnowledgeService(VectorStore vectorStore, DocumentLoader documentLoader) {this.vectorStore = vectorStore;this.documentLoader = documentLoader;}/*** 上传文档到知识库*/public void uploadDocument(String filePath) throws IOException {List<String> chunks = documentLoader.loadAndSplit(filePath);// 把文本块转成Spring AI的Document对象,自动做向量化List<org.springframework.ai.document.Document> documents = chunks.stream().map(chunk -> new org.springframework.ai.document.Document(chunk)).toList();// 存入向量数据库vectorStore.add(documents);}}
3. 语义检索
用户提问的时候,先把问题转成向量,去向量数据库里找最相关的前3个文本块:
public List<String> retrieveRelatedDocs(String question) {// 相似度搜索,取前3条最相关的内容List<org.springframework.ai.document.Document> similarDocs =vectorStore.similaritySearch(SearchRequest.query(question).withTopK(3));return similarDocs.stream().map(org.springframework.ai.document.Document::getContent).toList();}
4. 结合AI生成回答
最后把检索到的相关文档和用户的问题拼到一起,给大模型发请求,就能得到结合知识库内容的回答了:
public String chat(String question) {// 先检索相关文档List<String> relatedDocs = retrieveRelatedDocs(question);// 组装prompt,告诉AI只用提供的资料回答String prompt = """你是公司内部知识库助手,请仅用以下提供的资料回答用户问题,如果资料里没有相关内容,请直接回答"我不知道",不要编造内容。相关资料:%s用户问题:%s""".formatted(String.join("\n", relatedDocs), question);// 调用大模型生成回答ChatResponse response = openAiChatClient.call(new Prompt(prompt, OpenAiChatOptions.builder().withModel("qwen-plus") // 用国产大模型API,按需替换.withTemperature(0f) // 温度设为0,回答更稳定.build()));return response.getResult().getOutput().getContent();}
——————————-
完整Demo演示:真的特别好用
我拿我们公司的《用户退款业务规则文档》做了个测试,先把文档上传到知识库:
@RestController@RequestMapping("/knowledge")public class KnowledgeController {private final KnowledgeService knowledgeService;@PostMapping("/upload")public String upload(@RequestParam String filePath) throws IOException {knowledgeService.uploadDocument(filePath);return "文档上传成功";}@GetMapping("/chat")public String chat(@RequestParam String question) {return knowledgeService.chat(question);}}
启动项目,先调用上传接口把文档传上去,然后直接提问:
问:用户买了虚拟商品能退款吗?
答:根据业务规则,虚拟商品一旦售出不支持7天无理由退款,若存在充值不到账、商品描述与实际不符等情况,经运营审核后可特殊退款。
完全正确!比你翻十分钟文档快多了,而且新员工入职直接问这个就行,再也不用拉着老员工问东问西了。
我还试了问接口参数、线上故障处理流程,只要知识库有的内容,回答全是对的,现在我们团队已经把所有项目文档全导进去了,平时查资料效率至少提升了3倍。
——————————-
部署与优化建议,踩过的坑都告诉你
1. 部署建议:小团队直接把服务和Milvus部署在同一台服务器就行,8核16G的机器存个几十万条文档完全没问题,要是数据量特别大,再把Milvus改成集群版。2. 优化点: – 切片的时候可以按文档的标题、段落来切,比固定大小切片效果更好 – 可以给每个文档加标签,检索的时候先按标签过滤,准确率更高 – 敏感文档可以加权限控制,不同角色只能访问自己权限内的知识库内容3. 避坑提醒:向量维度一定要和你用的Embedding模型一致,不然存进去也搜不到;Temperature参数一定要调低,不然AI容易瞎编内容。
——————————-
其实整个搭建过程真的没那么复杂,核心代码加起来也就一百多行,但是用起来是真的香。不管是存公司文档、个人学习笔记,还是项目历史资料,有了这个知识库,再也不用到处翻文件了。
。
——————————-
关注「编程菜鸟旅」
觉得有用的兄弟别忘了点个赞、在看,转发给身边天天被问业务问题的Javaer!
——————————-