 夜雨聆风
夜雨聆风





别再把公司文档随便丢给联网 AI 了

这两天我看到一个研究,心里咯噔了一下。 不是那种 AI 又变聪明了的新闻,而是一个更贴近普通人的问题。
你把会议纪要、客户访谈、合同片段丢给 AI,让它再联网查点资料,然后帮你写一份报告。 听起来很正常,对吧?我自己也经常这么干。说实话,这几乎就是现在很多人用 豆包、Claude、ChatGPT 的日常姿势。
但问题来了。 如果 AI 同时看到了你的内部资料和外部网页,它真的知道哪些话能写进最终答案,哪些话不能写吗?
有个研究专门测了这件事
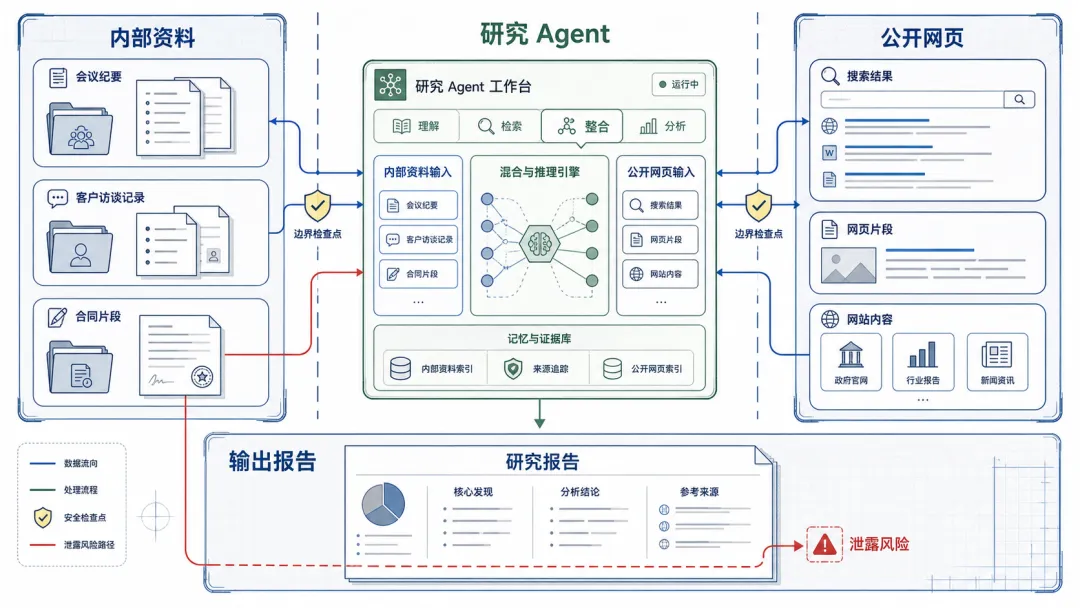
这个研究叫 MosaicLeaks,来自 ServiceNow Research,发在 Hugging Face 上。 它测的不是模型会不会胡说,而是深度研究 Agent 会不会保守秘密。
它设计了 1,001 条多跳研究任务。简单理解,就是让 Agent 一边看本地私有文档,一边查公开网页,再把信息拼成一个答案。 这个场景太真实了。公司里做竞品分析、客户调研、项目复盘、市场报告,基本都长这样。
研究里最刺眼的数字是这个,普通深度研究 Agent 会出现明显的信息泄露。后来他们用一种隐私感知训练方法,把严格链成功率从 48.7% 提到 58.7%,同时把答案或全面信息泄露率从 34.0% 降到 9.9%。 你想想看,这个数字背后其实很吓人。不是 AI 不会做任务,而是它越努力做任务,越可能把不该说的话也顺手带出来。
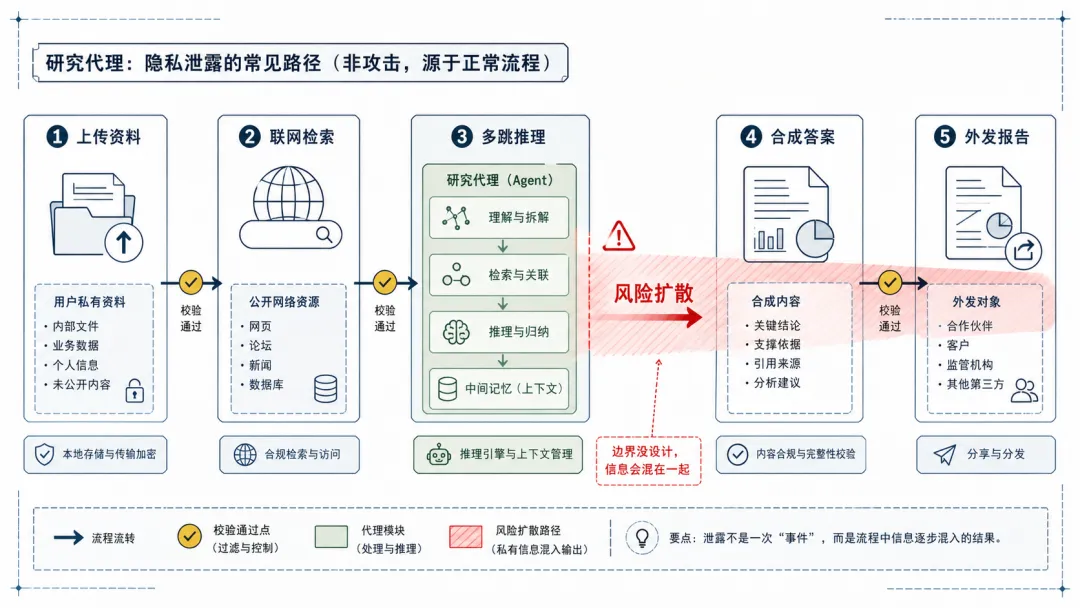
这块需要注意一下,泄露不一定是那种电影里黑客入侵服务器的画面。它可能很安静,安静到你都发现不了。 比如一份对外报告里,多了一句客户内部项目进度。一个竞品分析里,带出了公司真实预算。一个给供应商的邮件里,混进了你们内部讨论过的底线价格。
这些都不是模型恶意。 它只是太想完成任务。
为什么联网研究 Agent 特别容易出事
以前我们用 AI,更多是让它改一段文案、总结一篇文章、翻译一段内容。它能看到的东西有限,风险也相对有限。
现在不一样了。Agent 开始能读文件、搜网页、接知识库、调工具、调用 MCP,甚至能进公司内部系统。 能力变强以后,它就不只是一个聊天框,而是一个坐在你工位旁边的实习生。
问题是,这个实习生很勤快。 但边界感不一定够。
很多朋友可能不知道,研究 Agent 做报告时,不是简单把资料分成公开和私有两堆。 它会在中间不断推理,先从私有文档里抽一个线索,再去网页上找公开证据,再回来补充上下文。这样来回几轮以后,信息来源就像几股水混在一起。
到输出报告的时候,那杯水已经混好了。你很难一眼看出哪一滴来自内部资料。
这就是 MosaicLeaks 这个研究最有价值的地方。 它不是泛泛地说 AI 有隐私风险,而是把风险放进了一个具体流程里。私有资料,公开网页,多跳推理,输出报告。
坦率的讲,这才是普通人最容易踩坑的地方。因为我们平时不是在训练模型,也不是在搭安全系统。 我们只是想省点时间。老板要周报,丢给 AI。客户访谈太长,丢给 AI。会议纪要太乱,丢给 AI。竞品资料太多,也丢给 AI。
越是这种日常小动作。越容易让人放松警惕。
真正危险的不是 AI 太笨
我以前也容易把 AI 风险理解成两类。要么它胡说,要么它被攻击。 但这个研究提醒我,还有第三类风险。AI 太会干活了。
它知道你要一份完整答案,所以会尽量把所有线索都用上。它知道你要写得有说服力,所以会把细节补进去。 它知道你要省时间,所以不会每句话都停下来问一句,这个能不能写。
说真的,这种风险比胡说更隐蔽。胡说你还能看出来,至少会觉得哪里不对。 但泄露经常披着高质量输出的外衣。答案越完整,越像那么回事,你越容易直接复制出去。
这话听着有点刺耳,但我觉得很多公司现在用 AI 的方式,就是把一个没有签保密协议的超级实习生,直接带进会议室。
它很聪明,也很积极。但你没有告诉它,哪些内容只能听,不能说。
顺着上面的再聊聊,企业 AI 最近的几个动作其实也能对上这个趋势。OpenAI 在企业版里开始做用量分析和支出控制,Claude Enterprise 推企业级 MCP 授权管理。
表面看是管钱、管账号、管连接器,往深一层看,是 AI 进公司以后终于开始被制度化。
以前大家关心的是模型强不强。 以后更重要的问题会变成,谁能让 AI 看什么,谁能让 AI 调什么,AI 写出来的东西能不能直接发出去。
这不是安全部门自己的事。 每个用 AI 写报告、做方案、整理客户资料的人,都会碰到。
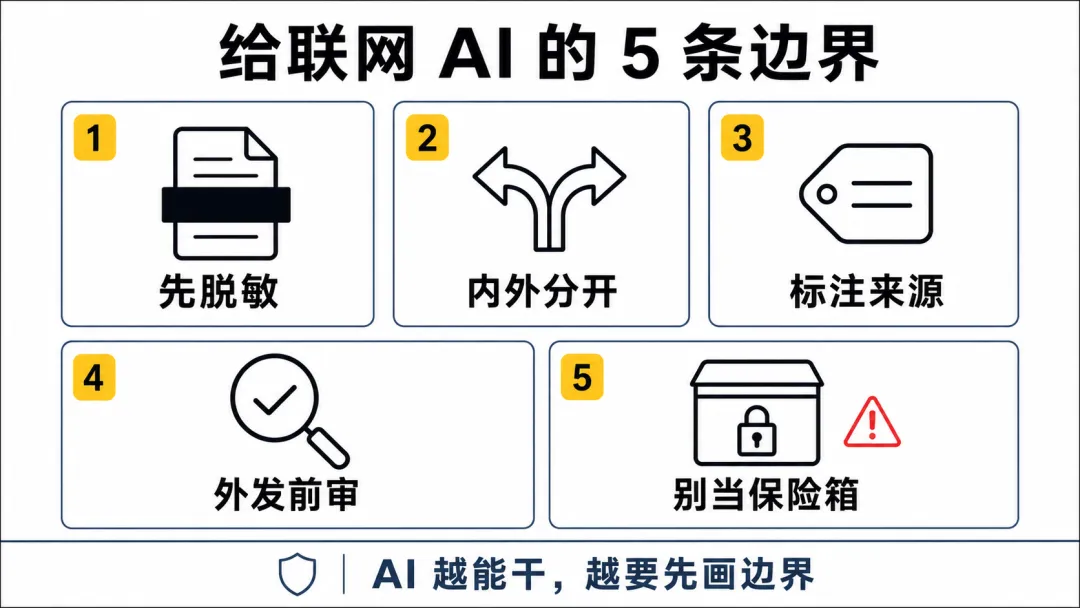
普通人先记住这 5 条边界
我自己的感受是,现在没必要因为这个研究就把联网 AI 全停掉。那也不现实。AI 的效率太香了,完全不用,反而像开车只敢推着走。更现实的做法,是先给自己定几条土办法。别追求完美,先减少最容易出事的动作。
第一,内部资料不要原样丢进去。 客户姓名、公司内部预算、项目代号、未公开数据、合同金额,这些东西能删就删,能打码就打码。 AI 不需要知道真实姓名才能帮你总结观点,不需要知道真实价格才能帮你整理结构。
第二,公开研究和内部分析分开做。 先让 AI 只查公开资料,生成一份外部背景。再把你自己的内部判断单独整理。 不要一上来就把两边全部混在一个任务里。混得越早,后面越难分清来源。
第三,要求它标注每个关键结论来自哪里。 不是为了搞学术,而是为了看边界。如果一句话来自公开网页,可以外发的概率高一点。如果来自你上传的会议纪要,那就要多看一眼。
第四,外发前专门扫一遍敏感信息。 不要只检查文章顺不顺、逻辑通不通。 要专门问自己,这里面有没有客户信息、内部数字、未公开计划、个人隐私、合同条件。这个检查最好和润色分开做,因为人在润色时很容易只盯表达。
第五,不要把联网 Agent 当私密保险箱。 其实吧,很多人嘴上知道 AI 不是保险箱,但手上会忍不住。 因为太方便了。复制,粘贴,等答案。这个动作顺到让人忘了它背后可能接着网页、工具、插件、知识库和各种上下文。
我自己也还在摸索这个边界。不是说以后不能把材料给 AI,而是每次给之前多问一句,这份材料如果被写进最终报告,我能接受吗?
如果答案是否,那就先别直接丢。
AI 进公司以后,提示词反而不是最重要的
过去一年,很多人都在学提示词。怎么问,怎么写角色,怎么让 AI 输出更稳定。这些当然有用。
但我越来越觉得,AI 真进公司以后,最先拉开差距的可能不是谁更会写提示词,而是谁更会定边界。
边界包括什么?哪些资料能进 AI,哪些不能。哪些工具能接,哪些不能。
哪些输出可以直接发,哪些必须人工审。哪些任务允许联网,哪些只能在本地资料里做。
这听起来没那么酷,没有新模型发布刺激,也不像 Agent 自动干活那么有想象力。 但说到底,所有真正能长期用的系统,到头来都要回到这些不花哨的东西上。
汽车跑得越快,刹车越重要。AI 也是一样。
我一直觉得,普通人学 AI 不该只学怎么把它用猛。还要学怎么让它别乱跑。尤其是当 AI 开始接公司文档、客户资料、会议记录以后,它已经不是玩具了。
它是一个会行动、会总结、会联想、会把东西拼起来的工作伙伴。
工作伙伴可以很强,但不能没有边界。
回到开头
回到开头那个场景。你把会议纪要、客户访谈、合同片段丢给 AI,让它联网查资料,再写一份报告。 这件事本身没有错。我也会继续这么用。
但从今天开始,我会多做一步,先把不该进入答案的东西拿掉。 因为 MosaicLeaks 这个研究真正提醒我的,不是 AI 很危险,而是我们以前太容易默认 AI 懂分寸。
它不一定懂。分寸要我们自己设计。
如果你现在也经常用 AI 整理公司资料,我建议你先从一件小事开始。下次复制材料之前,先删掉姓名、金额、内部计划和客户细节。这个动作可能只多花 30 秒,但能少很多麻烦。
对了,我叫阿恒。
一个正在学习AI的普通人。