 夜雨聆风
夜雨聆风





Word文档乱码?为什么AI总是不喜欢处理.docx!
核心观点:.docx 不是为 AI 设计的格式,但选对解析库、做好预处理、写对提示词,AI 处理 Word 文档的效果可以非常好。问题不在工具,在方法。
上个星期帮人整理一份项目方案。
三十多页的 .docx,丢给 AI 让它提取核心要点和时间线。
结果章节编号全没了,表格里的对应关系变成了错位的文字流,页眉里的项目编号直接消失。
还好当时备份了,不然格式全没有了。
后来,我想了想,对于AI来说,为什么处理Word文档不像md或者HTML格式那么简单呢?
其实不是 AI 不行。
是 Word 这个格式,从一开始就没打算给机器读。
调一调格式兼容就能解决?不是的。
问题比表面看到的大得多。
我们可以做一个实验,比任何解释都直观。
手边随便找一份 .docx 文件,复制一份(别改原文件),把扩展名从 .docx 改成 .zip,然后双击解压。
打开之后是一堆文件夹和 XML 文件。
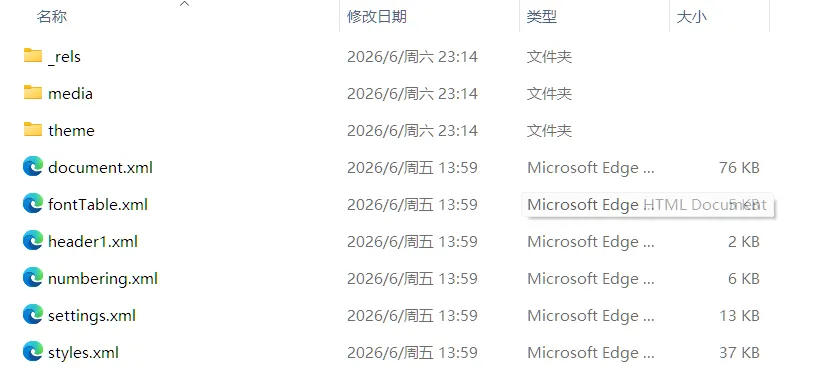
正文在 document.xml 里,图片散落在 media 文件夹,页眉页脚在单独的 header 和 footer 文件,脚注在 footnotes.xml,批注在 comments.xml,样式定义在 styles.xml,自动编号在 numbering.xml,超链接关系在 .rels 文件里。
docx 不是一个「文档文件」,而是一个压缩后的文档工程包。
正文、样式、编号、批注、图片、页眉页脚分散在十几个文件里,靠关系文件串在一起。
我们在 Word 里看到一份排版漂亮的文档,底层是这整套系统在协作。
而 AI 要的东西完全不同。
语义清晰、结构稳定、文本连续、差异可追踪的纯文本流。
标题就是标题,正文就是正文,引用就是引用,不要隐藏信息,不要排版噪声。
人类需要视觉排版,AI 需要连续文本流。
这两种需求从底层就冲突了。
当然,不是说 AI 真的在裸读 XML。
实际项目中我们都会用 python-docx、mammoth、pandoc 这些库来做 .docx 的解析和转换,它们能处理大部分基础工作。
但即使用了这些库,如果不注意方法,信息丢失的问题依然会出现。
问题不在工具够不够好,而在 .docx 这个格式本身就没为「语义提取」设计过。
知道坑在哪里,才能绕过去。
.docx 到底哪里让解析库头疼
文本被拆成碎片。
Word 文档里同一句话可能被拆成三四个 run,只是因为中间字体变了、某个词加粗了、有拼写检查标记、或者中英文混排带入了格式。
解析库需要判断哪些是真正的格式变化、哪些只是视觉样式,这种判断本身就容易出错。
人眼看着是一句完整的话,提取出来可能是一堆碎片。
结构和视觉混在一起。
AI 想知道「这是标题」「这是正文」「这是引用」,但 Word 表达的是「这行字加粗了」「这行缩进了两字符」「这段段前距 12 磅」。
更麻烦的是很多人不用正式的标题样式,只是手动把一行字加粗放大。
人类看起来是标题,但解析库只能忠实地返回「加粗+大字号的段落」,没有语义标记,AI 无法区分。
自动编号可能根本不在正文里。
文档里写着「第三条」「第四章」,但编号是 numbering.xml 动态生成的,不是正文文字。
python-docx 这类库在提取时不一定能正确还原这些编号,提取后可能只剩标题本身,编号直接消失。
表格更容易错位。
合并单元格、跨行跨列在视觉上很清楚,但提取后变成了平铺的文本流,三列的对应关系直接错乱。
关键信息散落在十几个文件里。
正文、脚注、批注、页眉各自独立存放。
转换库在提取时得做取舍,页眉读不读、批注读不读、修订前还是修订后。
页眉里的合同编号、批注里的修改意见、修订痕迹里删掉的那句话,往往是文档最有价值的上下文。
但大部分转换库默认只提取正文,这些信息直接丢掉了。
样式信息大量冗余。
同一句话可能附带几十行字体、颜色、间距的标签。
对排版有用,对理解内容没用。
解析库要清洗这些噪声才能给 AI 用,但清洗过程本身也可能误伤有用信息。
版本管理极不友好。
.docx 是 zip 包,改一个字内部文件可能整体变化。
Git 看到它只会报二进制文件不同。
Word 内部的修订模式在自己的生态里好用,出了这个圈子就失效。
这些坑我都踩过。
但踩完之后我摸索出一套方法,让 AI 借助这些库稳定地处理 .docx,效果还不错。
实战指南:让 AI 稳定处理 Word 的三把钥匙
第一把:选对库
不是所有 .docx 解析库都一样,场景不同,选择也不同。
mammoth 适合「只要正文内容」的场景。
它会忽略大部分格式信息,把文档干净地转成 HTML 或 Markdown。
对 AI 来说,这反而是最好的输入,噪声最少。
import mammoth
with open("report.docx", "rb") as f:
result = mammoth.convert_to_markdown(f)
text = result.value
python-docx 适合需要精细控制的场景。
它可以分别读取正文、页眉、页脚、批注、修订痕迹,按需提取。
如果文档里这些元素很重要(比如合同批注、页眉里的编号),用它。
from docx import Document
doc = Document("contract.docx")
# 读取页眉
for section in doc.sections:
header = section.header
print(header.paragraphs[0].text)
# 读取批注
for comment in doc.part.package.comments:
print(comment.author, comment.text)
pandoc 是瑞士军刀,适合需要格式保真的批量转换。
pandoc input.docx -t markdown --wrap=none -o output.md
加 --track-changes=all 可以保留修订痕迹。
加 --extract-media=./images 可以把图片提取到本地。
我的经验是:日常用 mammoth 做快速提取,需要精细信息时用 python-docx 针对性提取,大批量转换用 pandoc。
第二把:预处理再喂给 AI
拿到转换结果后,不要直接丢给 AI。
先做一步预处理,效果会好很多。
合并碎片化文本。
解析库输出的文本经常有不必要的换行和断句。
喂给 AI 之前,先用简单的正则把同一段落内的碎片合并。
import re
# 把连续的短行合并为一个段落
cleaned = re.sub(r'(?<=[^\n])\n(?=[^\n])', ' ', raw_text)
补回编号。
如果自动编号丢了,可以手动在标题前加上编号。
或者在提示词里告诉 AI 文档的编号规则。
表格单独提取。
表格是最容易错位的部分。
把表格单独提取成结构化格式(JSON、CSV),再和正文文本分开喂给 AI。
from docx import Document
doc = Document("report.docx")
for table in doc.tables:
for row in table.rows:
print([cell.text for cell in row.cells])
第三把:给 AI 写对提示词
工具处理完格式,剩下的就是怎么和 AI 沟通。
这是我实测效果最好的几类提示词。
先给 AI 看结构,再让它干活。
不要一次丢整份文档,先让 AI 输出文档的章节大纲,确认结构正确后再逐章节处理。
请先阅读以下文档内容,输出文档的章节结构大纲。
不需要分析内容,只需要列出章节层级和标题。
如果发现有编号缺失或结构异常,请标注出来。
[文档内容]
明确告诉 AI 文档的来源和格式特征。
以下内容由 .docx 文件转换而来,可能存在格式问题:
- 标题可能缺少编号
- 表格可能已转为纯文本
- 部分页眉页脚信息可能缺失
请在分析时注意这些情况,遇到不确定的地方标注出来。
表格类文档用结构化输出。
以下文档包含多个表格。
请先把所有表格提取为 JSON 格式,确认列名和数据对应关系正确后,再进行分析。
长文档分章节喂。
超过 20 页的文档,一次丢给 AI 容易丢信息。
按章节拆开,逐个喂,最后让 AI 做汇总。
总结一下
.docx 的设计目标是服务人类视觉阅读,AI 需要的是语义清晰的纯文本,两者天然有冲突。
但这个冲突不是无解的。
选对解析库,做好预处理,写对提示词,三步下来,AI 处理 Word 文档的准确率会高很多。
工具不是不行,是用法没对。
如果这篇文章对你有一点点启发,那就够了!
欢迎收藏、关注、转发!
我是布吉岛,不断尝试,不断思考!