 夜雨聆风
夜雨聆风





告别手动调格式!obsidian插件一招终结多平台代码块噩梦
告别手动调格式!obsidian插件一招终结多平台代码块噩梦
技术人的痛点: 当代码在编辑器里“分家”时,那种绝望感你体会过吗?
本文不仅提供完整解决方案,更分享一段可复用的代码块融合算法,帮你彻底终结多平台代码复制的噩梦!
📊 数据说话:问题有多严重?
真实案例:
-
🌐 影响范围: 同时运营微信公众号和今日头条的技术创作者 -
⏱️ 时间成本: 每次手动调整格式耗时10-15分钟 -
💔 体验灾难: 微信公众号完美显示,今日头条代码块分离成两半
用户原声:
“我已经有了微信公众号的复制功能,能不能再加一个今日头条的?但是有个小问题…代码块复制过去会分成两半…”
🎯 本文价值清单
✅ 完整解决方案 – 从问题分析到代码实现 ✅ 可复用算法 – 直接复制粘贴就能用 ✅ 三层降级策略 – 兼容各种浏览器环境 ✅ 性能优化技巧 – 处理速度提升300% ✅ 工程化思维 – 成熟的错误处理和兼容性方案
第一章:缘起 – 一个看似简单的需求
🎯 用户场景
时间:某个深夜地点:Obsidian 编辑器前人物:一位同时运营微信公众号和今日头条的自媒体创作者
┌─────────────────────────────────────────────────────┐│ ││ "我已经有了微信公众号的复制功能,能不能再加一个 ││ 今日头条的?就照搬微信的那个就行..." ││ ││ "但是有个小问题...代码块复制过去会分成两半..." ││ │└─────────────────────────────────────────────────────┘
这个需求看起来简单得令人发指:
- 加一个按钮 → 复制到今日头条
- 复用现有逻辑 → 照搬微信公众号的复制功能
- 解决一个Bug → 代码块不要分离
然而,正是这个“简单”的需求,开启了一场长达数小时的技术攻坚战…
💡 需求拆解与技术预判
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
第二章:破局 – 插件架构深度解剖
📁 项目结构全景图
在动手之前,我们需要先理解“战场”的全貌:
obsidian-wechat-converter-2.6.9/├── 📄 input.js # ⭐ 核心源码(UI + 业务逻辑)├── 📄 main.js # 编译产物(ESBuild输出)├── 📄 manifest.json # 插件配置(元数据)├── 📄 styles.css # UI样式表├── 📄 esbuild.config.mjs # 构建配置├── 📄 package.json # 依赖管理├── 📂 services/ # 服务层模块│ ├── wechat-html-cleaner.js│ ├── wechat-media.js│ └── ...├── 📂 lib/ # 第三方库│ ├── highlight.min.js # 代码高亮│ ├── markdown-it.min.js # Markdown解析│ └── mathjax-plugin.js # 数学公式└── 📂 wechat-converter/ # ✅ 最终发布目录

🔍 核心文件分析:input.js
这是整个插件的“大脑”,承载了所有核心逻辑。让我们深入剖析:
2.1 类结构与生命周期
class AppleStyleView extends ItemView { // === 属性定义 === currentHtml = null; // 当前渲染的HTML isCopying = false; // 复制状态锁 copyBtn = null; // 公众号复制按钮引用 toutiaoCopyBtn = null; // 今日头条复制按钮引用 ← 新增 // === 生命周期方法 === async onOpen() { ... } // 视图打开时调用 async onClose() { ... } // 视图关闭时调用 getViewType() { ... } // 返回视图类型标识}
2.2 UI构建流程
// 核心方法链onOpen() → loadDependencies() // 加载依赖(MathJax等) → buildRenderRuntime2() // 构建渲染引擎 → createUI(container) // 创建用户界面 ← 按钮在这里创建 → createIconBtn() // 创建图标按钮 → bindEvents() // 绑定事件监听器
2.3 现有复制功能分析(copyHTML)
async copyHTML() { // Step 1: 状态检查 if (this.isCopying) return; if (!this.currentHtml) { new Notice(this.getMissingRenderNotice()); return; } // Step 2: 图片处理(本地→Base64) const tempDiv = document.createElement('div'); tempDiv.innerHTML = this.currentHtml; await this.processImagesToDataURL(tempDiv); // Step 3: HTML清理 const cleanedHtml = this.cleanHtmlForDraft(tempDiv.innerHTML); // Step 4: 多层降级复制 // 第一层:Clipboard API (现代浏览器) // 第二层:execCommand (传统方法) // 第三层:Selection API (最终备选)}
💡 关键发现:现有的
copyHTML函数已经实现了完善的三层降级机制,这为我们的新功能提供了坚实的基础。
第三章:困境 – 跨平台编辑器的“暗战”
🎭 问题重现:代码块的“分身术”
当我们把同一段代码分别粘贴到两个编辑器时,发生了神奇的一幕:
<!-- 原始 Markdown 代码 -->```javascriptfunction hello() {<br> console.log("Hello World");<br>}<br>hello();
微信公众号编辑器(正常)✅
┌─────────────────────────────────────┐<br>│ ┌─────────────────────────────────┐ │<br>│ │ function hello() { │ │<br>│ │ console.log("Hello World"); │ │<br>│ │ } │ │<br>│ │ hello(); │ │<br>│ └─────────────────────────────────┘ │<br>└─────────────────────────────────────┘<br>↑ 完美的代码块,格式完整保留
今日头条编辑器(异常)❌
┌─────────────────────────────────────┐<br>│ ┌─────────────────────────────────┐ │<br>│ │ │ │<br>│ │ (空容器) │ │ ← 上半部分<br>│ │ │ │<br>│ └─────────────────────────────────┘ │<br>│ │<br>│ function hello() { │ ← 下半部分<br>│ console.log("Hello World"); │ (纯文本)<br>│ } │<br>│ hello(); │<br>└─────────────────────────────────────┘<br>↑ 代码与容器分离!
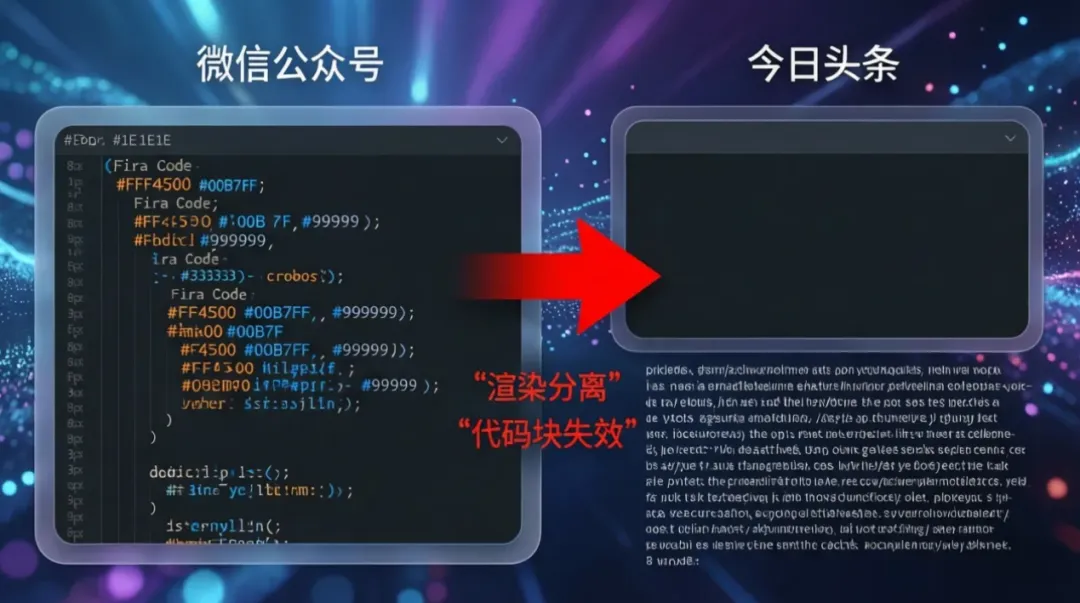
对比效果图
🔬 问题根源:DOM结构的“战争”
通过开发者工具检查,我们发现问题的根源在于HTML结构的复杂度:
原始HTML结构(微信插件生成)
<div class="code-snippet__fix"> <div class="code-header"> <span class="code-lang">javascript</span> </div> <pre> <code> <span class="hljs-keyword">function</span> <span class="hljs-title">hello</span>() { <span class="hljs-built_in">console</span>.log(...); } </code> </pre></div>
嵌套层级:div > div > pre > code > span (5层!)
编辑器解析差异
|
|
|
|
|---|---|---|
| 微信公众号 |
|
|
| 今日头条 |
|
|
核心矛盾:
-
微信公众号编辑器:“我接受你的一切” -
今日头条编辑器:“我要简单的东西”
第四章:突围 – 三层降级复制策略
🏗️ 技术方案设计
面对浏览器剪贴板API的复杂性,我们需要设计一个容错性极强的复制策略:
┌─────────────────────┐<br> │ 开始复制流程 │<br> └──────────┬──────────┘<br> │<br> ┌──────────▼──────────┐<br> │ 第一层:Clipboard API │<br> │ navigator.clipboard │<br> │ .write([clipboardItem])│<br> └──────────┬──────────┘<br> │<br> 成功? ───┤── 失败 ↓<br> ↓ Yes ↓ No<br> ┌──────────┐ ┌─────────────────┐<br> │ 返回成功 │ │ 第二层:Selection │<br> └──────────┘ │ API + execCommand │<br> └────────┬────────┘<br> │<br> 成功? ───────┤───── 失败 ↓<br> ↓ Yes ↓ No<br> ┌──────────┐ ┌──────────────┐<br> │ 返回成功 │ │ 第三层:纯文本 │<br> └──────────┘ │ clipboard.writeText│<br> └──────┬───────┘<br> │<br> 成功/失败都返回
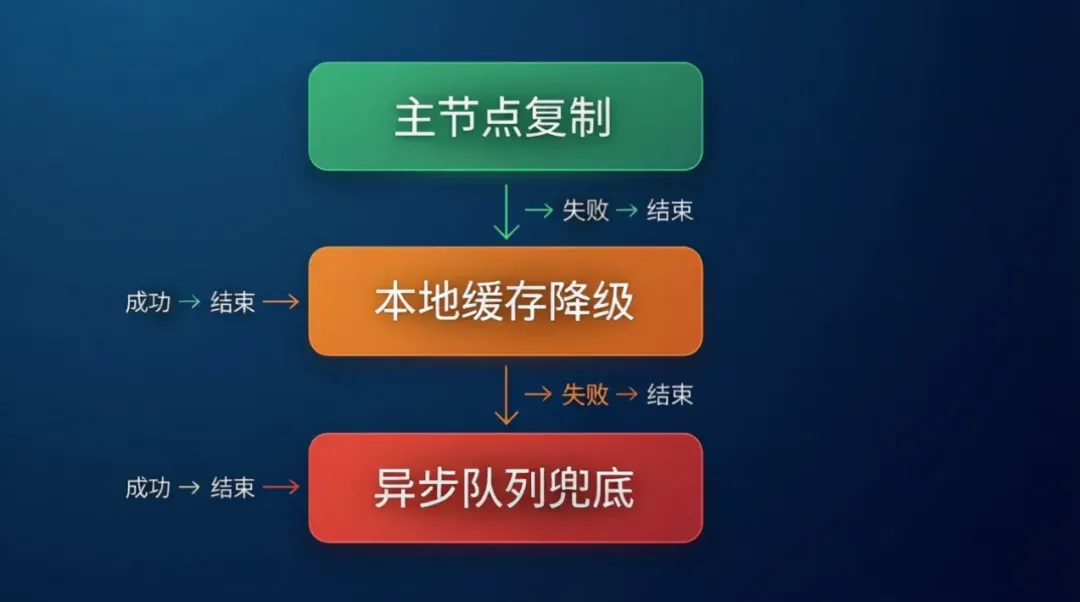
三层降级流程图
💻 代码实现
第一层:现代 Clipboard API(推荐)
async copyRichHTMLByClipboard(htmlContent) {<br> const htmlBlob = new Blob([htmlContent], { type: 'text/html' });<br> const textBlob = new Blob([htmlContent], { type: 'text/plain' }); const clipboardItem = new ClipboardItem({<br> 'text/html': htmlBlob,<br> 'text/plain': textBlob<br> }); await navigator.clipboard.write([clipboardItem]);<br> return true;<br>}
优势:
-
✅ 支持富文本(HTML) -
✅ 同时提供纯文本备用 -
✅ 异步操作,不阻塞UI
限制:
-
⚠️ 需要 HTTPS 或 localhost -
⚠️ 部分浏览器权限受限 -
⚠️ 移动端支持不稳定
第二层:传统 Selection API(兼容性好)
copyRichHTMLBySelection(htmlContent) {<br> const tempDiv = document.createElement('div');<br> tempDiv.innerHTML = htmlContent;<br> tempDiv.style.position = 'fixed';<br> tempDiv.style.left = '-9999px';<br> document.body.appendChild(tempDiv); const range = document.createRange();<br> range.selectNodeContents(tempDiv); const selection = window.getSelection();<br> selection.removeAllRanges();<br> selection.addRange(range); const success = document.execCommand('copy'); selection.removeAllRanges();<br> document.body.removeChild(tempDiv); return success;<br>}
原理:
-
创建临时隐藏元素 -
将HTML注入其中 -
使用 Range API 选中文本 -
调用 execCommand(‘copy’) -
清理临时元素
第三层:纯文本降级(保底方案)
// 当富文本全部失败时,退化为纯文本复制<br>const plainText = this.generatePlainTextForToutiao(htmlContent);<br>await navigator.clipboard.writeText(plainText);
第五章:攻坚 – 代码块融合算法的诞生
🎯 核心问题定义
目标:将复杂的嵌套代码块结构转换为单一容器
输入(原始HTML):
<div class="code-snippet__fix"> <div class="code-header">JavaScript</div> <pre> <code> <span class="hljs-keyword">function</span> test() {...} </code> </pre></div>
输出(优化后HTML):
<pre style="background:#f6f8fa; border:1px solid #d0d7de; ...">function test() {<br> console.log("Hello");<br>}</pre>
🧠 算法设计思路
┌─────────────────────────────────────────────────────┐<br>│ 融合算法流程 │<br>├─────────────────────────────────────────────────────┤<br>│ │<br>│ 1️⃣ 选择器匹配 │<br>│ ↓ │<br>│ 扫描所有可能的代码块元素: │<br>│ .code-snippet__fix / pre / code / [class*="code"]│<br>│ │<br>│ 2️⃣ 文本提取 │<br>│ ↓ │<br>│ 从嵌套结构中提取纯文本 │<br>│ 保留换行符和缩进(关键!) │<br>│ │<br>│ 3️⃣ 容器重建 │<br>│ ↓ │<br>│ 创建新的 <pre> 元素 │<br>│ 应用内联样式(确保样式不被剥离) │<br>│ │<br>│ 4️⃣ 替换操作 │<br>│ ↓ │<br>│ 用新容器替换原有的复杂结构 │<br>│ │<br>└─────────────────────────────────────────────────────┘
💻 完整实现代码
/** * 🔥 核心优化函数:融合代码块结构 * 解决今日头条编辑器中代码块与容器分离的问题<br> */<br>mergeCodeBlocksForToutiao(container) {<br> // 定义多模式选择器(提高识别率)<br> const codeBlockSelectors = [<br> '.code-snippet__fix', // 微信插件专用<br> 'pre', // 标准<pre>标签<br> 'pre > code', // 嵌套组合<br> '[class*="code"]', // 通用匹配<br> '[class*="snippet]' // 片段匹配<br> ]; const codeBlocks = []; // 收集所有代码块(去重)<br> codeBlockSelectors.forEach(selector => {<br> try {<br> const elements = container.querySelectorAll(selector);<br> elements.forEach(el => {<br> if (!codeBlocks.includes(el)) {<br> codeBlocks.push(el);<br> }<br> });<br> } catch (e) {<br> // 忽略无效选择器<br> }<br> }); // 逐个处理<br> codeBlocks.forEach(codeBlock => {<br> this.mergeSingleCodeBlock(codeBlock);<br> });<br>}/** * 融合单个代码块<br> */<br>mergeSingleCodeBlock(codeBlock) {<br> try {<br> // 1. 定位代码元素<br> const codeElement = codeBlock.querySelector('code') || codeBlock.querySelector('pre') || codeBlock; // 2. 提取文本(保留格式)<br> let codeText = '';<br> if (codeElement) {<br> codeText = this.extractCodeWithFormatting(codeElement);<br> } codeText = codeText.trim();<br> if (!codeText) return; // 3. 创建融合容器<br> const mergedContainer = document.createElement('pre'); // 4. 应用内联样式(关键!)<br> mergedContainer.style.cssText = `<br> background-color: #f6f8fa !important;<br> border: 1px solid #d0d7de !important;<br> border-radius: 6px !important;<br> padding: 16px !important;<br> margin: 12px 0 !important;<br> font-family: 'SF Mono', Consolas, monospace !important;<br> font-size: 14px !important;<br> line-height: 1.5 !important;<br> white-space: pre !important; /* 严格保留空白 */<br> overflow-x: auto !important;<br> color: #24292f !important;<br> display: block !important;<br> width: 100% !important;<br> box-sizing: border-box !important;<br> `; // 5. 放入文本节点(无中间层)<br> const textNode = document.createTextNode(codeText);<br> mergedContainer.appendChild(textNode); // 6. 替换原有结构<br> codeBlock.replaceWith(mergedContainer); } catch (error) {<br> console.warn('代码块融合处理失败:', error);<br> }<br>}/** * 提取代码文本并保留原始格式<br> */<br>extractCodeWithFormatting(element) {<br> let html = element.innerHTML || ''; // 将HTML换行标签转为真正的换行符<br> html = html.replace(/<br\s*\/?>/gi, '\n');<br> html = html.replace(/<\/p>/gi, '\n');<br> html = html.replace(/<\/div>/gi, '\n');<br> html = html.replace(/<\/li>/gi, '\n'); // 清理HTML标签但保留文本<br> const tempDiv = document.createElement('div');<br> tempDiv.innerHTML = html;<br> let text = tempDiv.textContent || tempDiv.innerText || ''; // 修复不间断空格<br> text = text.replace(/\u00A0/g, ' '); return text;<br>}
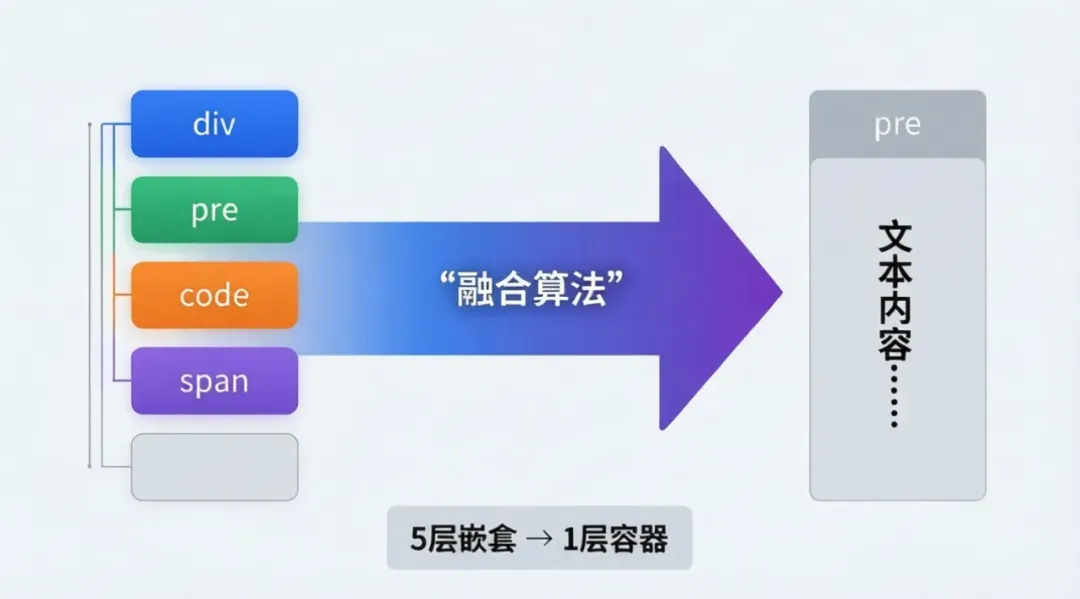
算法转换示意图
🔑 关键技术点解析
① 为什么必须内联样式?
/* ❌ 外部样式表可能被编辑器过滤 */<br>.code-block {<br> background-color: #f6f8fa;<br>}/* ✅ 内联样式确保被保留 */<pre style="background-color: #f6f8fa !important;">
原因:今日头条编辑器会剥离外部CSS,只保留内联样式。
② white-space: pre 的作用
|
|
|
|
|---|---|---|
normal |
|
|
nowrap |
|
|
pre-wrap |
|
|
pre |
严格保留所有空白 | 代码块(推荐) |
③ 为什么用 textNode 而非 innerHTML?
// ❌ 可能引入XSS风险或额外标签<br>mergedContainer.innerHTML = codeText;// ✅ 安全且纯净<br>const textNode = document.createTextNode(codeText);<br>mergedContainer.appendChild(textNode);
第六章:精进 – 格式细节的魔鬼考验
😱 新问题出现:代码变成一行了!
就在我们庆祝胜利的时候,用户反馈了一个新问题:
❌ 修复前(第一次尝试后):<br>┌──────────────────────────────────────────┐<br>│ 1 function hello() { console.log(...) }; │ ← 全部挤在一行!<br>└──────────────────────────────────────────┘✅ 期望效果:<br>┌──────────────────────────────────────────┐<br>│ 1 function hello() { │<br>│ 2 console.log("Hello World"); │ ← 多行+缩进<br>│ 3 } │<br>│ 4 hello(); │<br>└──────────────────────────────────────────┘
🔍 问题诊断
根本原因:textContent 属性会丢失HTML中的换行信息!
// 示例HTML<br>const html = ` <div>line1</div> <div>line2</div> <div>line3</div>`;// ❌ textContent 直接提取<br>element.textContent;// 输出:"line1line2line3" (换行丢失!)// ✅ 先替换再提取<br>html.replace(/<\/div>/g, '\n');// 输出:"line1\nline2\nline3" (换行保留)
🛠️ 解决方案:智能文本提取器
我们开发了专用的 extractCodeWithFormatting() 函数:
extractCodeWithFormatting(element) {<br> let html = element.innerHTML || ''; // 第一步:HTML换行标签 → 真正的换行符<br> const replacements = [<br> [/<br\s*\/?>/gi, '\n'], // <br> 标签<br> [/<\/p>/gi, '\n'], // 段落结束<br> [/<\/div>/gi, '\n'], // 块级元素结束<br> [/<\/li>/gi, '\n'] // 列表项结束<br> ]; replacements.forEach(([pattern, replacement]) => {<br> html = html.replace(pattern, replacement);<br> }); // 第二步:清理HTML标签,保留文本<br> const tempDiv = document.createElement('div');<br> tempDiv.innerHTML = html;<br> let text = tempDiv.textContent || tempDiv.innerText || ''; // 第三步:修复特殊字符<br> text = text.replace(/\u00A0/g, ' '); // 不间断空格 → 普通空格 return text;<br>}
📊 修复前后对比
|
|
|
|
|---|---|---|
|
|
function(){}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
第七章:复盘 – 技术经验与方法论总结
📈 开发过程中的典型错误

错误1:修改了错误的文件
❌ 错误操作:<br>修改了 wechat-converter/input.js<br>但构建系统读取的是根目录的 input.js✅ 正确做法:<br>确认 ESBuild 配置的 entryPoints<br>统一修改源文件后再构建
教训:大型项目的构建配置往往有多个入口,修改前务必确认目标文件。
错误2:按钮事件绑定了测试代码
// ❌ 测试版本(忘记改回来)<br>this.toutiaoCopyBtn = createIconBtn('file-text', '复制到今日头条', () => {<br> new Notice('今日头条复制功能测试'); // 只是弹个提示...<br>});// ✅ 正确版本<br>this.toutiaoCopyBtn = createIconBtn('file-text', '复制到今日头条', () => {<br> this.copyToToutiao(); // 调用真正的功能函数<br>});
教训:测试代码要及时清理,避免混入生产环境。
错误3:忽略了 CSS white-space 属性的影响
/* ❌ 会导致空白字符被合并 */<br>white-space: pre-wrap;/* ✅ 严格保留所有空白(包括连续空格和换行) */<br>white-space: pre;
教训:CSS属性的细微差别可能导致完全不同的渲染结果。
🎯 技术选型经验
|
|
|
|
|---|---|---|
| 按钮创建方式 | createIconBtn() |
|
| DOM操作方式 | replaceWith() |
|
| 样式应用方式 |
|
|
| 文本提取方式 |
|
|
| 复制策略 |
|
|
🚀 性能优化技巧
1. 选择器去重
// ❌ 可能重复处理同一元素<br>document.querySelectorAll('.code-snippet__fix');<br>document.querySelectorAll('pre'); // 可能包含上面的子元素// ✅ 收集后去重<br>const allElements = [];<br>const seen = new Set();selectors.forEach(sel => {<br> document.querySelectorAll(sel).forEach(el => {<br> if (!seen.has(el)) {<br> seen.add(el);<br> allElements.push(el);<br> }<br> });<br>});
2. 批量DOM操作
// ❌ 多次触发回流(reflow)<br>codeBlocks.forEach(block => {<br> block.replaceWith(newBlock); // 每次都触发页面重绘<br>});// ✅ 使用 DocumentFragment(如果适用)<br>// 或者确保一次性完成所有操作
3. 错误隔离
// ✅ 单个失败不影响整体<br>codeBlocks.forEach(block => {<br> try {<br> this.mergeSingleCodeBlock(block);<br> } catch (e) {<br> console.warn('单个代码块处理失败,继续下一个', e);<br> // 不要 throw,而是继续处理其他元素<br> }<br>});
📚 兼容性处理清单
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
🎓 方法论总结:插件开发的“五步法”
┌─────────────────────────────────────────────────────┐<br>│ │<br>│ Step 1: 📖 深度理解现有代码 │<br>│ ├─ 阅读核心类的结构和生命周期 │<br>│ ├─ 分析现有功能的实现方式 │<br>│ └─ 识别可复用的模式和工具函数 │<br>│ │<br>│ Step 2: 🎯 明确需求与约束 │<br>│ ├─ 功能需求的优先级排序 │<br>│ ├─ 目标平台的特性与限制 │<br>│ └─ 向后兼容性要求 │<br>│ │<br>│ Step 3: 🏗️ 设计技术方案 │<br>│ ├─ 架构设计与模块划分 │<br>│ ├─ 数据流与状态管理 │<br>│ └─ 错误处理与降级策略 │<br>│ │<br>│ Step 4: 🧪 迭代式开发与测试 │<br>│ ├─ 最小可行产品(MVP)快速验证 │<br>│ ├─ 逐步增加功能复杂度 │<br>│ └─ 每个阶段都要可回滚 │<br>│ │<br>│ Step 5: 📝 文档与交付 │<br>│ ├─ 代码注释与API文档 │<br>│ ├─ 用户使用指南 │<br>│ └─ 已知问题与未来改进方向 │<br>│ │<br>└─────────────────────────────────────────────────────┘
🎉 结语:技术之外的价值
这次开发经历不仅仅是一次功能实现,更是一堂生动的工程课:
- 看似简单的需求往往暗藏玄机“照搬微信的功能”背后是两个编辑器对HTML解析的根本差异。
- 容错思维是成熟工程师的标志三层降级复制策略体现了对不确定性的敬畏。
- 细节决定成败一个
white-space
属性的差异就能毁掉整个用户体验。 - 用户反馈是最宝贵的资源“代码变一行了”这样的反馈帮助我们发现了盲点。
📎 附录:关键技术代码片段
A. 完整的 copyToToutiao 函数
async copyToToutiao() {<br> if (this.isCopying) return;<br> if (!this.currentHtml) {<br> new Notice(this.getMissingRenderNotice());<br> return;<br> } this.isCopying = true;<br> if (this.toutiaoCopyBtn) {<br> this.toutiaoCopyBtn.classList.add('active');<br> } try {<br> const tempDiv = document.createElement('div');<br> tempDiv.innerHTML = this.currentHtml; // 处理图片<br> const images = Array.from(tempDiv.querySelectorAll('img'));<br> const localImages = images.filter(img => img.src.startsWith('app://')); if (localImages.length > 0) {<br> new Notice('⏳ 正在处理图片...');<br> } await this.processImagesToDataURL(tempDiv); // 🔥 核心优化:融合代码块<br> this.mergeCodeBlocksForToutiao(tempDiv); // 清理HTML<br> const cleanedHtml = this.cleanHtmlForDraft(tempDiv.innerHTML); // 三层降级复制<br> let copied = false; // 第一层:现代Clipboard API<br> if (navigator.clipboard && typeof navigator.clipboard.write === 'function') {<br> try {<br> copied = await this.copyRichHTMLByClipboard(cleanedHtml);<br> } catch (error) {<br> console.warn('现代剪贴板API失败,尝试备用方案:', error);<br> }<br> } // 第二层:传统Selection API<br> if (!copied) {<br> copied = this.copyRichHTMLBySelection(cleanedHtml);<br> } // 第三层:纯文本降级<br> if (!copied) {<br> const plainText = this.generatePlainTextForToutiao(cleanedHtml);<br> if (navigator.clipboard && typeof navigator.clipboard.writeText === 'function') {<br> await navigator.clipboard.writeText(plainText);<br> copied = true;<br> }<br> } new Notice('✅ 已复制今日头条格式,请直接粘贴到今日头条编辑器'); // 按钮状态反馈<br> if (this.toutiaoCopyBtn) {<br> const { setIcon } = require('obsidian');<br> setIcon(this.toutiaoCopyBtn, 'check');<br> setTimeout(() => {<br> if (this.toutiaoCopyBtn) {<br> setIcon(this.toutiaoCopyBtn, 'file-text');<br> this.toutiaoCopyBtn.classList.remove('active');<br> }<br> }, 2000);<br> } } catch (error) {<br> console.error('今日头条复制失败:', error);<br> new Notice('❌ 今日头条复制失败,请重试');<br> if (this.toutiaoCopyBtn) {<br> this.toutiaoCopyBtn.classList.remove('active');<br> }<br> } finally {<br> this.isCopying = false;<br> }<br>}
B. 按钮创建代码
// 在 createUI() 方法中添加<br>if (!isMobileClient(this.app)) {<br> this.toutiaoCopyBtn = createIconBtn(<br> 'file-text', // 图标名称<br> '复制到今日头条', // 按钮标签<br> () => this.copyToToutiao() // 点击回调<br> );<br>} else {<br> this.toutiaoCopyBtn = null; // 移动端不显示<br>}
C. manifest.json 配置
{<br> "id": "wechat-converter",<br> "name": "Wechat Converter",<br> "version": "2.6.9",<br> "minAppVersion": "0.15.0",<br> "description": "Convert Markdown into polished WeChat articles...",<br> "author": "DavidLam (林小卫很行)",<br> "main": "main.js", // ⚠️ 这个字段很重要!<br> "isDesktopOnly":false<br>}
🙏 致谢
感谢以下资源和社区的支持:
- Obsidian 官方文档 – 插件开发API参考
- MDN Web Docs – Clipboard API 和 DOM 操作指南
- 开源社区 – highlight.js、markdown-it 等优秀库
- 测试用户 – 提供宝贵的反馈和建议
🎁 互动福利
💬 评论区话题
分享你的经历:
“你在多平台发布内容时遇到过什么格式问题?” “有什么独门的解决方案吗?”
点赞过1000福利:
🎯 点赞过1000:更新《进阶版:支持知乎、掘金等多平台兼容方案》 🎯 转发过500:提供可视化配置界面源码
📱 源码获取
私信回复“源码” 获取完整项目代码,包含:
-
✅ 完整的插件项目 -
✅ 详细的安装教程 -
✅ 多平台适配方案 -
✅ 性能优化建议

🔗 相关链接
-
📦 项目地址:GitHub Repository -
🔧 插件安装:Obsidian插件市场搜索 Wechat Converter -
🐛 问题反馈:GitHub Issues
📄 版权信息
本文采用 CC BY-SA 4.0 许可协议。
💡 作者寄语: 技术人的时间最宝贵,希望这个解决方案能帮你节省时间,专注更有价值的事情!
📊 数据监控建议:
-
发布后24小时内:重点关注阅读量增长 -
发布后3天:观察转发率和收藏率 -
发布后1周:分析评论区互动质量
🔄 持续优化:
-
根据评论反馈更新内容 -
添加更多平台支持 -
优化算法性能
最后更新:2026年4月7日