 夜雨聆风
夜雨聆风





拆开 Claude Code:AI 编程助手 98.4% 的代码,根本不是 AI,最可靠的是“工程系统”~

大模型不是主角:拆开 Claude Code,看清 AI 编程助手的工程本质
当你在终端敲下”帮我修掉这个 Bug”,背后到底发生了什么?
一篇来自 MBZUA I(哈利法大学)与 UCL 的最新论文,深入解剖了 Claude Code 的完整架构。他们发现了一个令人震惊的数字:一个”AI 编程助手”,只有 1.6% 的代码是真正的 AI 决策逻辑,其余 98.4% 全部是——工程基础设施。
🔍 从一个”修 Bug”的请求开始
让我们先看一个具体的例子,感受一下 Claude Code 背后系统的复杂程度。
当你对它说:“帮我修复 auth.test.ts 里的那个失败测试”,表面上只是一句话,但实际上会依次触发:
- 上下文构建
— 系统需要判断当前项目的代码结构、测试文件内容、相关模块 - 权限检查
— 在执行任何操作前,权限系统会评估:这个操作安全吗? - 循环推理
— Agent 进入一个”思考→行动→验证”的循环 - 工具调用
— 可能是读取文件、运行命令、调用 MCP 协议 - 子 Agent 委托
— 复杂任务可能被拆分,委托给子 Agent 并行处理 - 上下文压缩
— 当对话变长,系统自动压缩历史,保持推理效率 - 会话持久化
— 一切操作被记录,关闭终端后可以恢复
这还只是修复一个 Bug。
🧠 核心发现:那个”AI”到底有多大?
这是论文最反直觉的发现,也是我认为值得写在标题里的原因。
研究人员对 Claude Code 的源代码(v2.1.88 版本,已公开)进行了完整拆解。他们发现:
|
|
|
|---|---|
| AI 决策逻辑
|
~1.6% |
| 工程基础设施
|
~98.4% |
换句话说:Claude Code 的核心”大脑”——那个真正负责”思考”的 AI 模型——在代码量上只占冰山顶部的一角。真正的工程复杂度,在那层薄薄的大脑周围。
这个发现告诉我们一个重要事实:AI Agent 的竞争力,不在于模型有多强,而在于工程系统有多精密。
🏛️ 五大核心价值观:设计决策的底层逻辑
论文从源代码和 Anthropic 官方文档中,提炼出了驱动 Claude Code 架构的五大人类价值观。理解这些价值观,才能理解每一个技术决策背后的”为什么”。
1️⃣ Human Decision Authority · 人类决策权
核心理念:最终拍板的一定是人,不是 AI。
这不只是”用户可以随时取消”这么简单。Claude Code 设计了一套Principal Hierarchy(主体层级):
Anthropic(最高层:定义安全边界)↓Operators(运营者:配置规则的人)↓Users(终端用户:实际操作的人)
系统提供了四层控制能力:
- 实时观察
— 用户可以实时看到 AI 在做什么 - 审批/拒绝
— 每个操作可以审批后才执行 - 中断
— 正在进行的兼容操作可以被叫停 - 事后审计
— 所有操作都有记录可查
一个有趣的发现:Anthropic 的数据显示,用户对权限提示的批准率高达 93%。这个数据本该让设计者放松警惕——但他们的反应是:“这才是问题所在。”
研究表明,当用户习惯了某个流程,审批会变成机械性的”点同意”。于是 Claude Code 转向了边界式授权(sandboxing + Auto-mode classifier),让 AI 在明确的安全边界内自由工作,而不是每一次操作都打断用户。
2️⃣ Safety, Security & Privacy · 安全与隐私
核心理念:保护用户,即使用户走神了。
这里有一个重要的区分:Authority(决策权)关心的是”谁有权力选择”,而 Safety(安全性) 关心的是”即使权力所有者疏忽了,系统也要保护”。
Claude Code 的 Auto-mode 威胁模型明确定义了四类风险:
- Overeager Behavior
— AI 过于主动,做了超出范围的事 - Honest Mistakes
— AI 无意间犯了错误 - Prompt Injection
— 恶意提示词注入攻击 - Model Misalignment
— AI 模型本身的意图偏差
这四个类别,覆盖了从”不小心”到”被攻击”再到”AI本身出问题”的全谱系风险。
3️⃣ Reliable Execution · 可靠执行
核心理念:AI 要做对,还要证明自己做对了。
这包含两个维度:
- 单轮正确性
— AI 有没有真正理解用户的意图? - 长程一致性
— 跨多个上下文窗口、跨多次会话恢复,AI 的行为是否保持一致?
Anthropic 的产品文档将此描述为一个三阶段循环:
收集上下文 (Gather Context)↓采取行动 (Take Action)↓验证结果 (Verify Results) → 循环重复
一个关键的设计原则:Generation(生成)和 Evaluation(评估)必须分离。研究指出:”AI Agent 倾向于自信地赞美自己的工作,即使质量一般。”所以 Claude Code 在架构上把”写代码”和”评判代码”分成了两个独立的模块。
4️⃣ Capability Amplification · 能力放大
核心理念:让人类做以前根本做不到的事,而不只是做得更快。
Anthropic 内部调研显示,约 27% 的任务代表了用户”根本不会去尝试”的工作。
换句话说:Claude Code 创造了一些全新的工作流,而不只是优化了旧的。
还有一个有趣的设计哲学:
“Claude Code 是一个 Unix 工具,而不是一个传统产品。它由最小的积木块构建,每个积木都是’有用的、可理解的、可扩展的’。”
这解释了为什么 Claude Code 在架构上选择“最小脚手架,最大操作空间”(Minimal scaffolding, maximal operational harness)——与其在 AI 模型外面套一堆约束框架,不如给它一个丰富、安全、灵活的操作环境,让越来越强的模型自己发挥。
5️⃣ Contextual Adaptability · 情境适应
核心理念:懂你,懂你的项目,并且越来越懂。
Claude Code 的扩展架构支持多层次的情境定制:
CLAUDE.md
— 项目级规则(项目规范、特定约定) - Skills
— 预定义的技能模块 - MCP(Model Context Protocol)
— 协议级扩展 - Hooks
— 生命周期钩子 - Plugins
— 插件系统
这些机制让系统可以“低成本地适应不同用户的不同上下文”,而不是用一套通用方案对付所有人。
🏗️ 架构全景:Agent Loop 才是心脏
了解了价值观之后,我们来看架构。
Claude Code 的核心,是一个极其简洁的 while 循环——调用模型、运行工具、重复。这句话大概只有 20 个英文单词。
while (true) { callModel(); runTools(); repeat; }
但这只是冰山露出水面的部分。
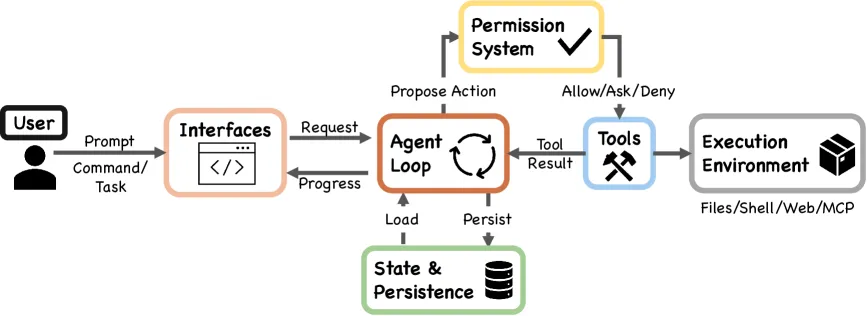
Figure 1: Claude Code 系统高层结构。七个核心组件围绕主数据流连接:用户通过不同接口输入 → 共享 Agent Loop → 权限系统 → 工具执行 → 状态持久化。
架构的四个核心设计问题
论文将 Claude Code 的架构解读为对四个经典设计问题的回答:
Q1: 推理应该放在哪里?
Claude Code 的答案:模型负责推理,Harness(系统框架)负责执行。
AI 模型输出 tool_use 指令块,Harness 负责:
-
解析指令 -
检查权限 -
调用具体工具 -
收集执行结果
这个分离有一个重要的安全意义:即使 AI 模型被污染或被攻击,它无法绕过 Harness 层的安全机制,因为它只能通过结构化的 tool_use 协议与世界交互。
而其他系统选择了不同的答案:
- Devin
(另一款 AI 编程工具)维护了显式的规划和任务追踪结构 - LangGraph
让开发者通过状态图定义控制流
这些设计把更多推理逻辑放在了”脚手架侧”。
Q2: 需要多少个执行引擎?
Claude Code 的答案:统一引擎,多个接口。
无论用户是通过:
-
交互式终端(Interactive CLI) -
自动化脚本(Headless CLI) -
Agent SDK -
IDE 集成
都调用同一个 queryLoop() 函数。只有渲染层和用户交互层不同。
Q3: 默认安全姿态是什么?
Claude Code 的答案:Deny-first with Human Escalation。
Deny 规则 > Ask 规则 > Allow 规则
未识别的操作 → 升级给用户,而不是默认允许
Q4: 什么是核心资源约束?
Claude Code 的答案:上下文窗口(Context Window)是硬约束。
Claude Code 的解决方案是一个五层上下文压缩管道(Five-layer Compaction Pipeline),而不是简单的截断。
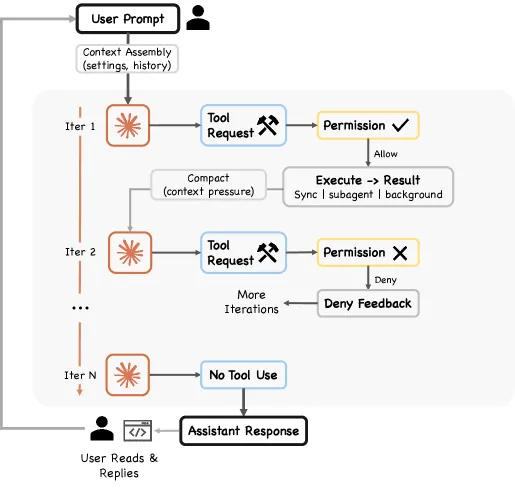
Figure 2: 运行时 Turn 执行流程。用户提示词进入上下文组装 → 调用模型 → 工具请求通过权限门 → 工具结果反馈到循环 → 压缩管道管理上下文压力。
⚙️ 权限系统:为什么 93% 的通过率反而是警报
权限系统是 Claude Code 最有深度的子系统之一。
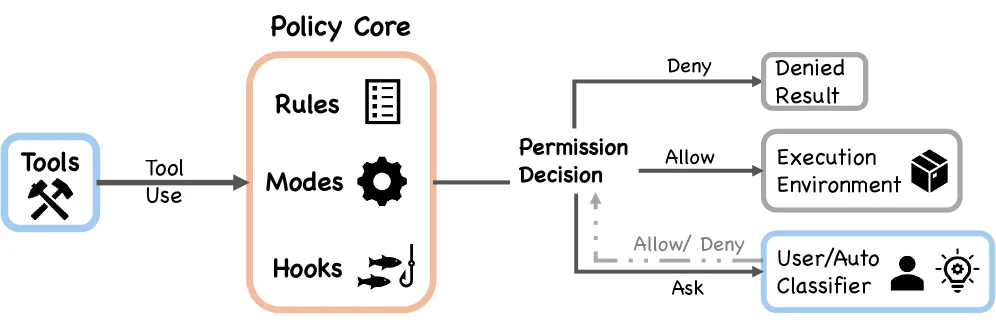
Figure 4: 权限系统概览及设计原则
七种权限模式
Claude Code 提供了一个渐进式信任光谱:
|
|
|
|---|---|
| Asymmetric |
|
| Read |
|
| Write |
|
| Bash |
|
| Edit |
|
| TodoWrite |
|
| Browser |
|
四层安全机制(Defense in Depth)
Claude Code 的安全不是一道墙,而是多层重叠:
第1层:Permission Rules(权限规则)
第2层:PreToolUse Hooks(工具前钩子)
第3层:Auto-mode Classifier(ML 分类器)
第4层:Shell Sandboxing(沙箱隔离)
任何一层都可以单独阻断操作。
🧊 上下文压缩:五层管道详解
当对话越来越长,Claude Code 面临一个现实问题:上下文窗口是有上限的。
Claude Code 的解决方案不是简单截断旧消息,而是一个五层压缩管道:
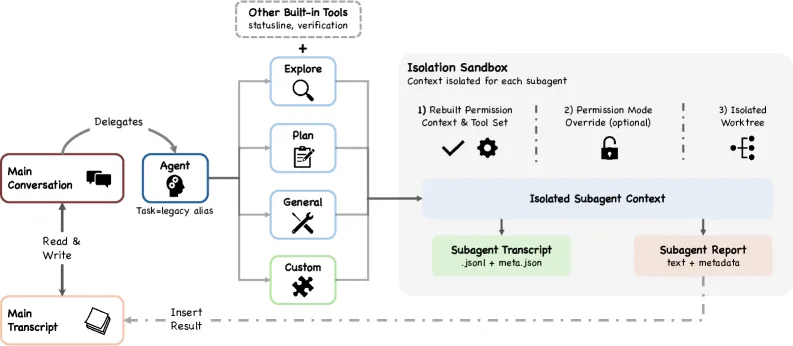
Figure 6: 上下文构建与记忆层级
为什么不用简单截断?
论文指出了一个关键问题:如果直接丢掉旧的对话历史,AI 会失去:
-
项目背景的理解 -
长期任务的上下文 -
用户的偏好和习惯
Claude Code 的压缩管道设计目标:在有限空间内,保留最具价值的上下文。
🧩 扩展机制:四种方式接入 Claude Code
Claude Code 的扩展架构覆盖了四个层次:
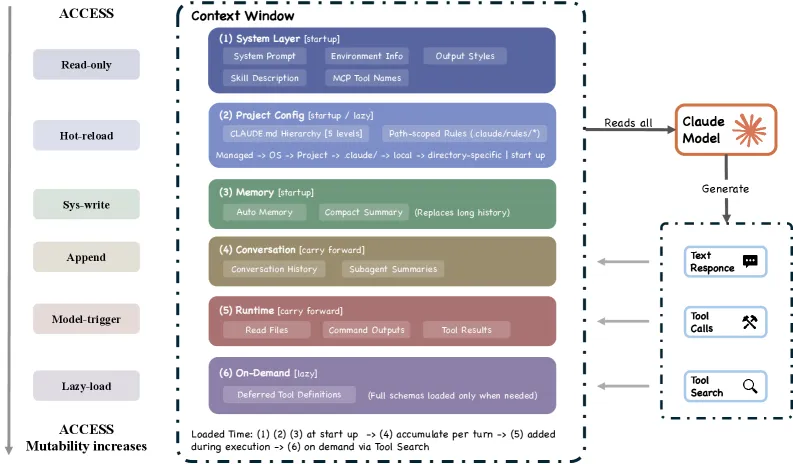
Figure 5: Claude Code 扩展机制在 Agent Loop 中的接入点
|
|
|
|
|---|---|---|
| MCP |
|
|
| Plugins |
|
|
| Skills |
|
|
| Hooks |
|
|
👥 子 Agent:并行处理的艺术
对于复杂任务,Claude Code 支持子 Agent 委托与编排。
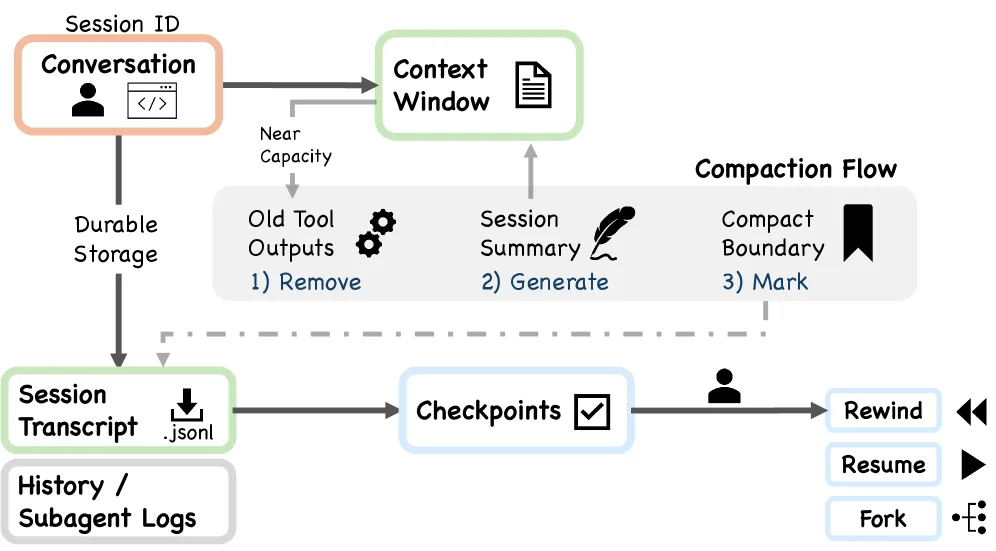
Figure 7: 子 Agent 隔离与委托架构
核心设计思路:
- 任务拆分
— 复杂任务被分解为可并行处理的子任务 - 结果聚合
— 各子 Agent 的结果被合并回主流程 - 隔离执行
— 子 Agent 在隔离环境中运行,互不干扰
💾 会话持久化:附录式状态管理
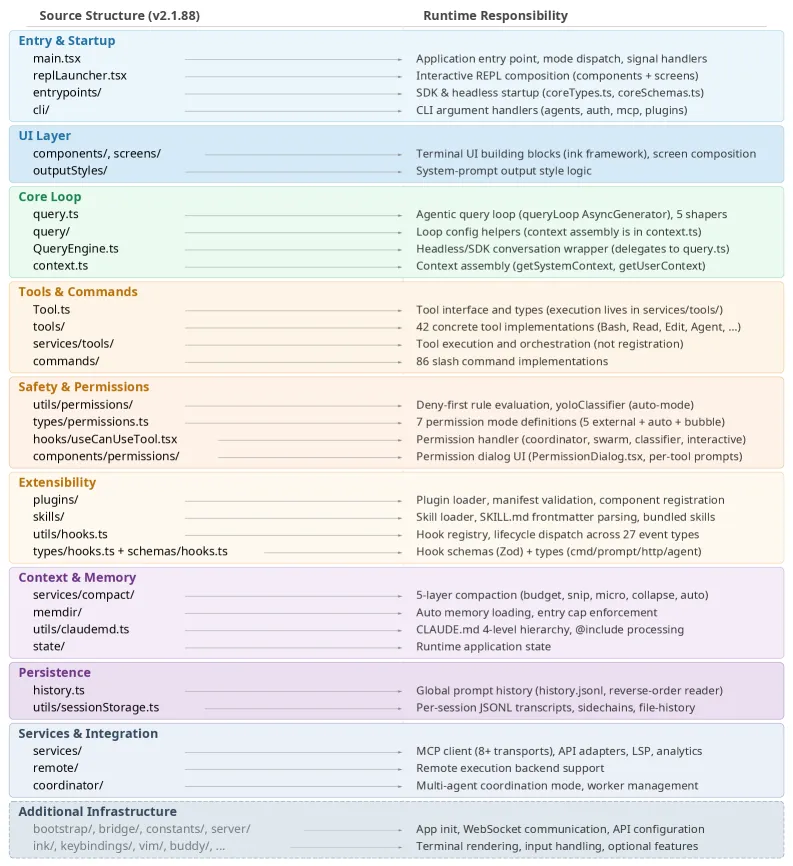
Figure 8: 会话持久化与上下文压缩
Claude Code 使用附录导向的会话存储(Append-oriented Session Storage):
不同于传统的关系型或文档型数据库,Claude Code 的会话存储本质上是一个不断追加的日志。每次操作都是往日志里添加一条记录,而不是修改已有状态。
这个设计的优势:
- 原子性
— 每个操作独立,不互相干扰 - 可回溯
— 所有历史操作完整记录 - 可重放
— 理论上可以回放整个会话
🔄 Claude Code vs OpenClaw:同一个问题,不同的答案
论文将 Claude Code 与另一个开源 AI Agent 系统 OpenClaw 进行了对比。OpenClaw 是一个多通道个人助理网关,专注于”让用户通过多种渠道(语音、文本、API)与 AI 交互”。
虽然两者都在解决”AI Agent 的设计问题”,但因为部署场景和用户假设不同,在多个维度给出了不同的答案:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
核心启示: 同一个设计问题,在不同场景下会产生完全不同的架构答案。这提醒我们:没有”最好”的 AI Agent 架构,只有”最适合当前场景”的架构。
🔮 六大未来方向
论文最后总结了 AI Agent 领域的六个开放设计问题,也是未来研究的热点方向:
1. 可验证的 Agent 正确性(Verifiable Agent Correctness)
如何证明一个 AI Agent 在长期任务中确实完成了预期目标?
2. Agent 间的互操作性标准(Interoperability Standards)
当不同厂商的 Agent 需要协作时,如何建立通用的通信标准?(MCP 协议是这方面的尝试)
3. 记忆的长期性与遗忘机制(Long-term Memory & Forgetting)
AI Agent 应该记住什么?忘记什么?保留多久?
4. 安全边界的动态调整(Dynamic Safety Boundary Adjustment)
如何让安全边界随用户信任度动态变化,而不是静态配置?
5. 多模态扩展的安全考量(Multi-modal Extension Security)
当 Agent 不只处理代码,还处理图像、音频、视频时,安全模型如何演进?
6. 人机协作的评估框架(Human-AI Collaboration Metrics)
如何量化”好的协作”?现有指标(通过率、任务完成率)是否足够?
💡 AI Agent 的工程时代
读完这篇论文,我最大的感受是:AI Agent 正在进入”工程时代”。
早期,人们以为 AI Agent 的核心竞争力是”模型有多聪明”。但随着 Claude Code 的拆解,我们看到了一个不同的真相:
模型的智能是门槛,但工程系统的精密程度才是壁垒。
权限系统、上下文管理、会话持久化、子 Agent 编排……这些看似”不酷”的基础设施,恰恰是让 AI Agent 在真实环境中可靠运行的关键。
就像飞机的竞争力不在于”飞得够快”,而在于发动机、航电系统、气动设计的精密配合。AI Agent 的竞争,正在从”大脑有多强”转向”神经系统有多完善”。
参考资料:
Liu, J., Zhao, X., Shang, X., & Shen, Z. (2026). Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems. arXiv:2604.14228v1GitHub: VILA-Lab/Dive-into-Claude-Code
如果你对 AI Agent 的工程设计感兴趣,欢迎关注,我会持续拆解更多这类”幕后真相”。