夜雨聆风
夜雨聆风





别再把 AI Coding 当聊天框,软件开发需要理解 LSP、多智能体和工作区
于是很多人顺手就得出一个结论:软件开发,快要被一个聊天框接管了。
但我越用越觉得,不是这么回事。
只要你把 AI 真拉进一个像样的项目里,幻觉很快就会退掉。
你不是让它“写一个按钮”,而是让它:
-
先看懂这个仓库到底怎么组织的 -
找出某个接口改动影响了哪些模块 -
顺着调用链把问题一路追到后端 -
跑命令、看日志、搜引用、改代码、再验证结果 -
最后别把你最开始的问题搞丢
到了这一步,很多 AI 工具会立刻从“像个同事”,变成“像个很努力但总抓不住重点的实习生”。
不是它不会输出。 是它不会推进。
我觉得如果 AI Coding 还停留在“聊天框 + 大模型”的形态,那它能帮你写点代码,但很难真正参与软件开发。
而如果想往前走,它至少得补上三块东西:
-
LSP 级别的代码理解 -
多智能体式的任务编排 -
工作区级别的上下文隔离
最近发现一个编程软件 Helix ,内置Claude Sonnet 4.6 和GPT 5.4
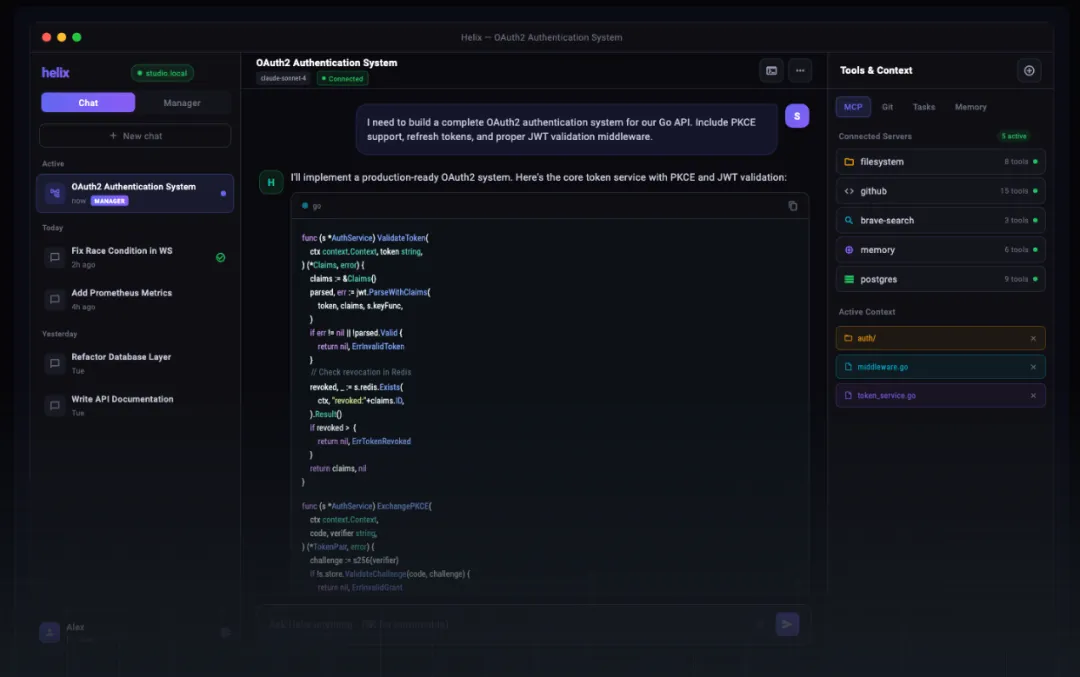
官网链接:https://helix.iqe.me
我之所以愿写这一篇文章是因为它在认真回答一个很关键的问题:AI 到底该怎么进入真实的软件工程流程。
一、在软件开发里,很多时候先卡住你的,不是“不会写”,而是“看不懂”
很多人对 AI Coding 的期待,一上来就放在“写代码”上。
但只要项目稍微成熟一点,你很快就会发现,真正先把人卡住的,往往不是写,而是看不懂。
你得先搞清楚:
-
这个函数定义在哪 -
这个符号到底被谁引用了 -
这个改动会不会牵出别的模块 -
这个类的真实职责是什么 -
这个接口在系统里到底走了哪条链路
这也是为什么我一直觉得,真正能进入工程现场的 AI,第一步不是会生成代码,而是得先获得接近 IDE 的代码理解能力。
这件事靠全文搜索不够。
全文搜索只能告诉你“这几个字在哪出现过”,却不能告诉你“它到底是不是同一个符号”“这次改动会影响到哪里”。
而 LSP 做的是另一件事:它基于语言服务去理解符号、类型、引用、定义和结构关系。说白了,就是它知道这段代码在工程里到底扮演什么角色,而不是只看表面字符串。
Helix 这块接的是 Serena 这套 LSP 代码智能。
它提供的能力,其实很像你在 IDE 里每天都会下意识用到的那套基本功:
-
找定义 -
查引用 -
看 hover 信息 -
列符号概览 -
安全重命名符号 -
按函数或类级别做结构化编辑
这听起来不像什么“黑科技”,反而特别像工程现场。
而这恰恰说明一个问题:AI 要参与软件开发,不能只会输出,它得先会读代码。
二、真正难的不是回答问题,而是把任务做完
这也是很多产品最容易搞错的地方。
问答做得好,不代表执行做得好。
真实开发里,一个任务很少是一句回答就能结束的。
它更像这样:
-
先读几个关键文件 -
再查几个符号引用 -
然后跑一条命令验证猜想 -
发现不对,再回头看日志 -
继续回到代码里修改 -
最后补检查、补验证、补总结
这不是一个“回答问题”的过程,更像一个“把事情一路推进到收口”的过程。
所以如果一个 AI 工具的能力边界,还是“输入问题,输出答案”,那它天然更适合做顾问,而不是做工程助手。
Helix 让我愿意多看一眼的一点,是它没有把工具调用藏起来装神秘,而是很直接地承认:要做工程任务,就得有工程触点。
它直接把工具这件事摊开了:
-
代码智能 -
文件系统 -
Shell 命令 -
持久终端 -
Web 抓取 -
Chrome DevTools -
远程 SSH -
上下文缓存 -
子任务执行 -
自定义 MCP 工具扩展
官方文档里提到,它内置了 12 组 MCP Server,大约 70 个工具。这个数字本身不是重点,重点是背后的产品判断:
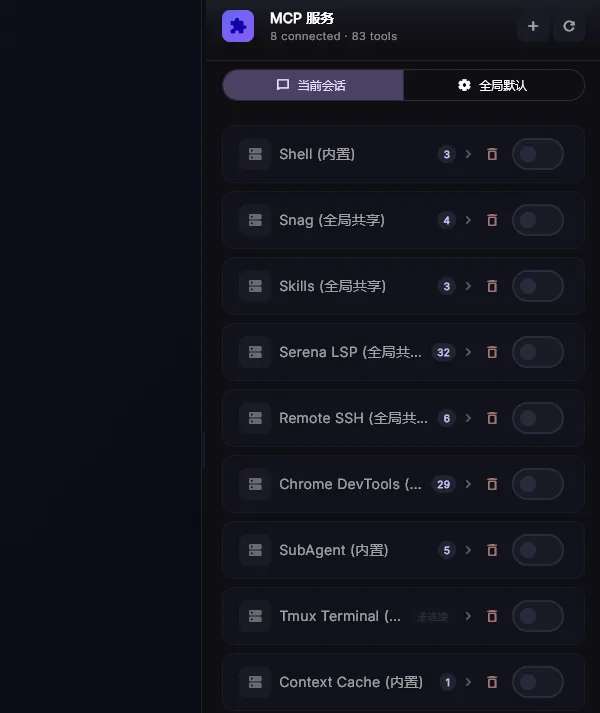
软件开发不是“想出来”的,很多时候是“查出来、跑出来、试出来、改出来”的。
如果 AI 没有文件、终端、浏览器、远程环境这些触点,它就只能在一个封闭的语言空间里猜。
而猜,在真实项目里通常不值钱。
多智能体不是炫技,是止损
很多人一听“多智能体”,第一反应是:又来一个新概念。
但如果你真的做过复杂任务,你会发现这个设计非常现实。
单个 Agent 做长任务时,几乎一定会碰到两个问题。
目标漂移
最开始你明明让它“排查接口偶发 500”。
结果它读了几轮文件、跑了几条命令、看了几屏日志之后,开始热情洋溢地修改一个边角配置,仿佛已经忘了你到底想查什么。
上下文污染
文件内容、命令输出、搜索结果、错误日志,全都往同一个会话里堆。堆到后面,真正重要的信息反而被淹了。
Helix 的多智能体设计,核心不是“显得高级”,而是试图把这两个问题拆开处理。
它把角色分成三层:
-
Manager Agent -
盯住用户原始目标,判断任务到底算不算完成 -
Execution Agent -
负责主流程,真正去读文件、调工具、推进执行 -
SubAgent -
负责并行处理那些可以独立拆开的子任务
这个分层我特别喜欢的一点是,它很像一个正常团队的工作方式。
不是所有人都一窝蜂干同一件事。 有人盯目标。 有人推进主线。 有人去分头调查。
更重要的是,SubAgent 不是开了就把一大坨中间过程塞回主会话里,而是尽量把结果压成摘要再回传。
这很关键。
因为多任务并行的价值,不只是更快,还在于主会话能保持干净。
有时候速度不是第一收益,清醒才是。
工作区不是标签页,它应该是执行边界
还有一个我很认同的点,是 Helix 对 Workspace 的定义。
很多工具所谓的“项目切换”,本质上只是换了个目录名,脑子还在同一个会话里转。
这就很容易出事。
你本来在看 A 仓库,它突然拿 B 仓库的上下文给你提建议; 你本来在看本地代码,它把远程日志里的信息混在一起; 你本来是想做架构分析,它却沿用了上一个会话的执行习惯。
Helix 的想法更像真正的执行边界:
-
每个 Workspace 有独立会话历史 -
有独立的上下文管理状态 -
有独立工具配置 -
有独立模型和 Agent Profile -
还能区分本地 Workspace 和远程 Workspace
这个设计对真实开发特别重要。
因为现实里我们经常同时面对这些东西:
-
本地仓库 -
另一个服务仓库 -
远程测试环境 -
线上日志或部署机
这些东西如果不隔离,AI 很容易“串味”。
而一旦串味,结论就会开始不可信。
真正让我多看一眼的,不是功能多,而是它开始像“系统”了
说到底,今天大家都能接模型,也都能做聊天。
真正拉开差距的,不是“你接了几个模型”,而是你有没有把这些能力组织成一个稳定的工程系统。
我真正多看它一眼,不是因为它功能多,而是因为它终于不像一个“更会说话的聊天产品”,而开始像一个有边界、有分工、有流程的系统产品。
Helix 的文档里有几个细节,我觉得很能说明问题:
-
写代码时会走 Git Worktree,把改动放在隔离分支里,避免直接污染主工作区 -
Agent Profile 可以把模型、工具集、语言、思考模式按场景预设好 -
Skills 可以把团队知识、评审规范、部署流程作为能力模块注入进去 -
自定义 MCP Server 可以继续把数据库、监控、工单系统甚至内部平台接进来
你会发现,聊到这里,重点已经不是“AI 会不会补全代码”了。
重点变成:
-
它有没有工程安全边界 -
有没有任务分工机制 -
有没有长期上下文治理 -
有没有扩展到团队真实工作流的能力
这才是一个工程工具该回答的问题。
如果你也在看 AI Coding 工具,我建议少看演示,多看这 6 个问题
最后给一个我自己现在越来越看重的判断清单。
你看一款 AI Coding 产品,别先被 demo 打动,也别急着问“写代码快不快”,先问这 6 个问题:
1. 它理解代码,靠的是文本匹配还是 LSP 级语义能力?
如果只是搜索增强版,那上限很快就到了。
2. 它能不能真正执行连续任务,而不是只回答单轮问题?
真正的软件开发,一定是连续动作,不是一次性作答。
3. 它有没有办法处理长任务里的上下文坍塌?
没有这层能力,任务一长,质量大概率掉线。
4. 它能不能把不同项目、本地环境、远程环境隔离开?
如果上下文和环境会串,越复杂的任务越危险。
5. 它能不能并行拆任务,而且让你看得见过程?
看不见过程的“自动化”,很多时候只是把问题藏起来。
6. 它能不能接进你真实的工程流程?
包括终端、代码库、浏览器、远程机器、团队规范、内部工具,而不是只在聊天框里自娱自乐。
如果按这套标准去看,Helix 至少不是在做一个“更会聊天的 AI”。
它更像是在认真尝试:把 AI 从一个会说话的工具,变成一个能进入软件开发现场的工作台。
这条路不一定最性感,但我觉得它是对的。
进群领取额度