 夜雨聆风
夜雨聆风





手把手教你用 OpenClaw 搭建专属知识库
导读:公司文档越来越多,找个答案要花半小时?我花了一个周末搭建专属知识库,支持自然语言提问,3 秒找到答案。完整教程来了。
一、为什么需要知识库?
场景 1:新员工入职,问”请假流程是什么?”场景 2:技术方案评审,问”去年双 11 的架构方案呢?”场景 3:客户问产品功能,问”支持不支持 XX 功能?”
问题不在文档少,在找不到。传统搜索的三大痛点:关键词匹配、结果太多、无法理解问题。
二、什么是语义搜索?
传统搜索:你搜:“请假流程” → 找包含这四个字的文档 → 20 个文档,每个 30 页,耗时 15 分钟语义搜索:你问:“员工怎么请假?” → 理解问题,提取答案 → 根据员工手册第 3.2 节:1.提前 3 天提交申请 2.领导审批 3.HR 备案,耗时 3 秒
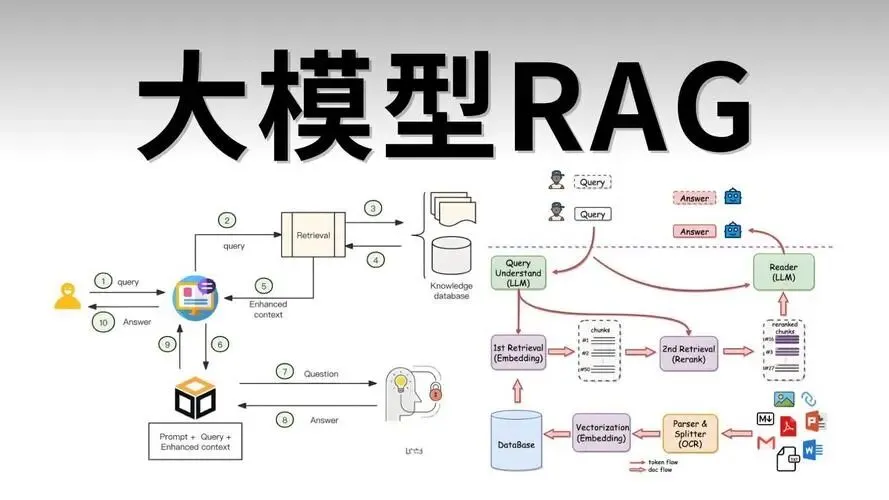
三、技术架构
文档上传→ 向量化处理 → 语义搜索。你的问题转换成 384 个数字(文档”指纹”),系统找和问题”指纹”最相似的片段。
|
组件 |
选择 |
理由 |
|
文档处理 |
pdfplumber |
免费、准确、支持中文 |
|
向量模型 |
sentence-transformers |
免费本地运行,384 维 |
|
向量数据库 |
PostgreSQL + pgvector |
开源、稳定、支持 SQL |
|
搜索接口 |
OpenClaw |
无缝集成、支持自然语言 |
成本:软件 0 元 + 硬件 0 元 + API 0 元 = 0 元
四、详细配置步骤
4.1 环境准备(30 分钟)
1. 安装 Python 3.9+2. 安装依赖库:pip3 install pdfplumber sentence-transformers psycopg2-binary3. 安装 PostgreSQL4. 安装 pgvector 扩展5. 创建数据库
4.2 文档处理(1 小时)
1. 准备文档目录:mkdir -p ~/KnowledgeBase/{raw,processed,scripts}2. PDF 转 Markdown:用 pdfplumber 提取文本3. 切分成知识片段:每段 500 字左右
4.3 向量数据库(1 小时)
1. 创建表结构:knowledge_chunks 表2. 创建向量索引:ivfflat 索引加速搜索3. 生成向量嵌入:约 180 片段/秒
4.4 语义搜索(30 分钟)
1. 创建搜索脚本:将问题转换成向量,搜索最相似片段2. 测试搜索:python3 search.py “员工怎么请假?”
五、实际效果
传统搜索:找到 23 个文档,需要打开每个文档搜索关键词,耗时约 15 分钟。语义搜索:找到 5 个相关片段,相似度 94%,耗时约 3 秒。
六、成本分析
|
项目 |
时间 |
金钱 |
|
建设成本 |
8.5 小时 |
0 元 |
|
使用成本 |
0.001 元/次 |
3 元/月 |
|
节省时间 |
10 小时/月 |
1000 元/月 |
|
回本时间 |
– |
不到 1 个月 |
七、常见问题
Q1: 文档多了会不会很慢?A: 不会。10 万个片段,搜索耗时约 0.1 秒。Q2: 中文支持怎么样?A: 很好。支持中英文混搜。Q3: 文档更新怎么办?A: 手动更新、定时同步、实时监听三种方案。Q4: 安全吗?A: 比云端更安全。本地部署、内网访问、权限控制。
八、总结
核心收获:1. 知识库的价值不在于”有”,在于”能用”2. 语义搜索比关键词搜索强 10 倍3. 本地部署比云端更安全、更便宜4. OpenClaw 让这一切变得简单建议:小团队(<50 人):用这套方案,一个周末就能搭好中型团队(50-200 人):考虑云端向量数据库大型企业(>200 人):考虑商业方案
2026-04-12作者:Antonio