 夜雨聆风
夜雨聆风





不限科室,这种发文方法正好站在AI风口

记得检查 星标关注状态,不错过精彩新内容~!

大家周一好~在考虑做药物靶点相关课题吗?在为新药发现/老药新用的实验验证经费发愁吗🤔大胆跨界的人,先发表数据驱动的SCI。一起来看人工智能时代,计算机辅助的药物靶点识别,都发展到什么程度了!
发文新C位诞生,也许只需要3年
⭐
常见靶点,见微知著

“
G蛋白偶联受体(GPCRs)是介导细胞对多种刺激的反应的一大类膜蛋白。目前美国食品药品监督管理局(FDA)批准药物的靶点中,GCPR约占35%。
然而,GCPR的结构复杂性、构象异质性、膜嵌入性,对实验表征造成较大妨碍。
GPCRs在结构数据库中代表性不足,动态构象(如瞬态活性态)尤其难以捕捉。
AI驱动的预测方法并未取代实验结构生物学,而是起到了关键的补充作用。
2023~2025年,人工智能在GPCR中的应用包括:
-
结构预测
-
虚拟筛选
-
小分子和蛋白质结合剂的生成式设计
-
机制研究(利用分子动力学)
-
系统级分析
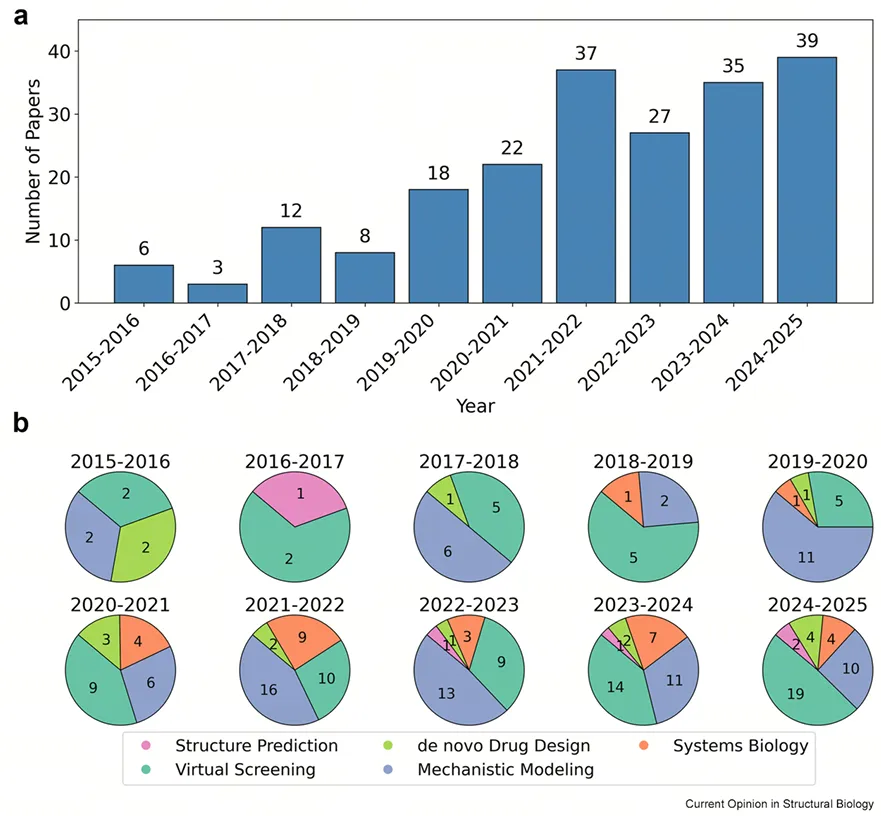
每年新发表论文按研究领域分布,除了“机制建模”外,发文第二多的便是虚拟筛选。
⭐
优化工作流程

传统的计算机辅助药物设计(Computer-Aided Drug Design, CADD)放在1990年代被提出。它依赖预设算法,虽然可以一定程度上加快开发速度、减少实验需求,但难以处理当代生物医学数据中的非线性高维关系。
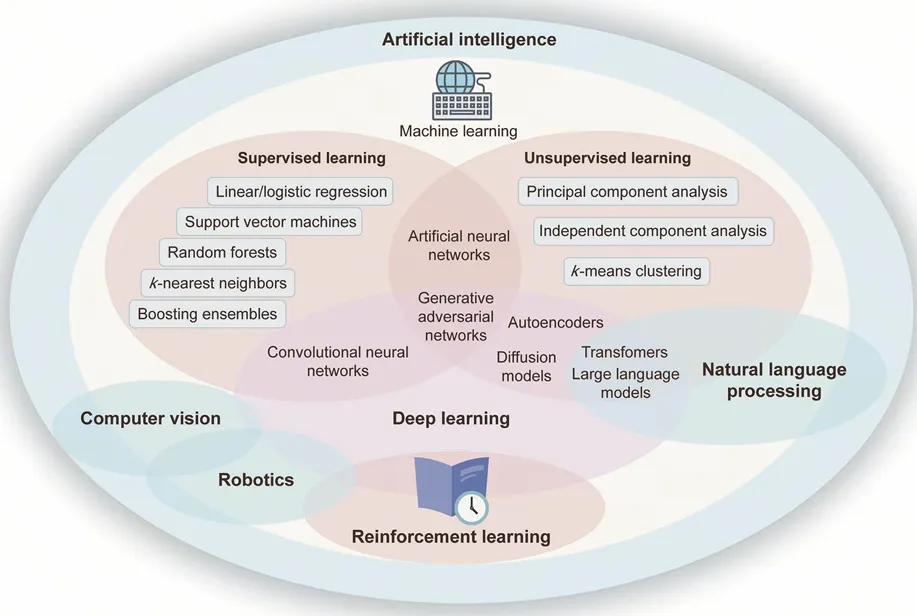
AI、机器学习和深度学习的层级概述
人工智能(包括机器学习)使模型能够从数据集中学习,分别通过带标签数据集(监督式学习)、识别未标记数据中的隐藏模式(无监督式学习)和用试错信息提升决策能力(强化学习),保证对复杂数据集的分析能力。
非线性高维模式,就可以通过机器学习+最先进的深度学习架构得到一定程度的模拟。
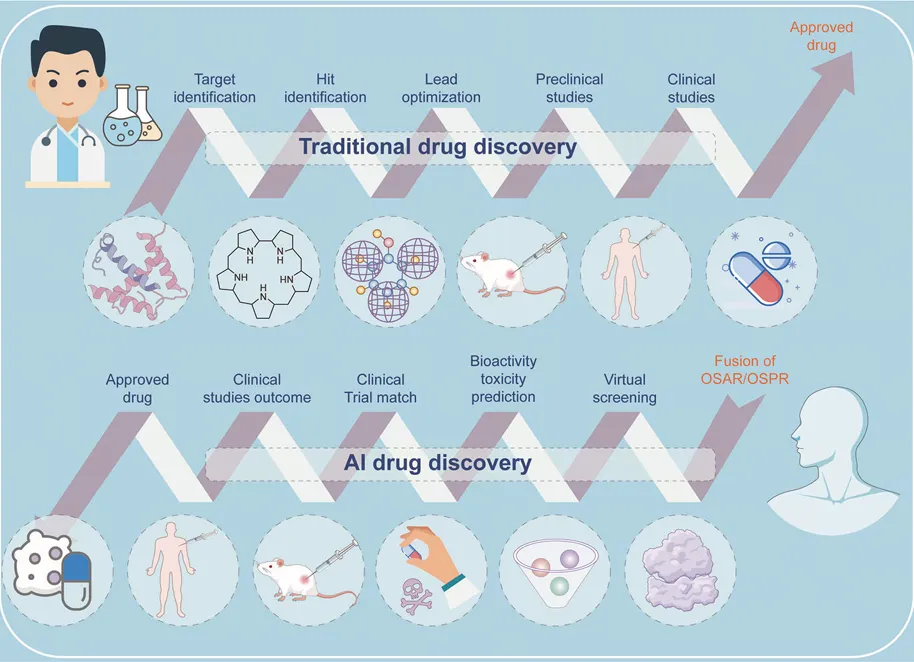
传统与人工智能驱动的药物发现工作流程的比较分析
AI驱动的药物发现方法全过程结合了预测建模、QSAR/QSPR 分析、毒性预测和虚拟筛选,从而加快早期决策、减轻实验负担。
对具有治疗潜力的药物化合物进行系统筛选是药物发现中的关键步骤。传统高通量筛选(HTS)可对数十万种化合物进行生物靶点检测。
而虚拟筛选,在成本更低、开发时间更短的基础上还能将容量提升到数百万甚至数十亿化合物,能够充分利用规模日渐增长的化合物文库。
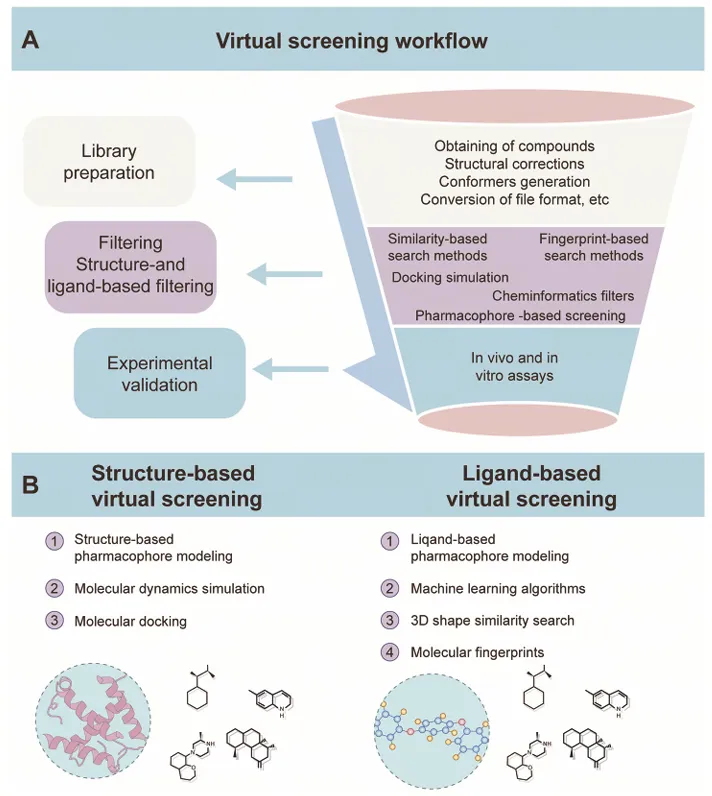
展示过程的虚拟筛选漏斗
AI模型辅助的虚拟筛选策略,可以快速筛除不合适的候选物,并在有限时间内筛选数百万化合物。包括 CNN 和 GNNs 在内的深度学习系统,训练于化学存储库(如 PubChem、ChEMBL)上,可以捕捉分子结构和生物活性中的非线性(包括复杂)特征,从而实现药物-靶点相互作用的更准确预测。
虚拟筛选的两大核心子分类包括:
-
基于结构的药物筛选
-
基于配体的药物筛选
分别适用于靶蛋白的三维结构已知(基于结构)的场景、靶蛋白结构未知/难以解析(基于配体,相似分子具有相似生物活性)的场景。

跨学科融合创新,在人工智能方法越来越红火的当下,也可能是一次计算资源的挑战。如果想把当前处于蓝海期的发文方案变成真正属于自己的发文成果,别担心,你也可以巧妙借力!
雪球老师作为一位7年+服务经验的科研导师,已带领科研服务团队(从0到1,成员90+人)陪跑4000+生信/临床项目,并顺利拿到成果,涵盖发表SCI、标书申请、硕博毕业等重大场合。

👇找雪球老师,来一场生信/临床数据库SCI安心的陪跑交付吧!

添加雪球
回复“个性化”咨询详情
星标公众号 及时把握科研新动向



转发记录实用好套路