 夜雨聆风
夜雨聆风





看懂LLM:从文本到 AI 助手
最近读了《How LLMs Actually Work》,觉得它把 LLM(大语言模型)讲得非常清晰,因此摘抄总结出来,和大家一起分享。
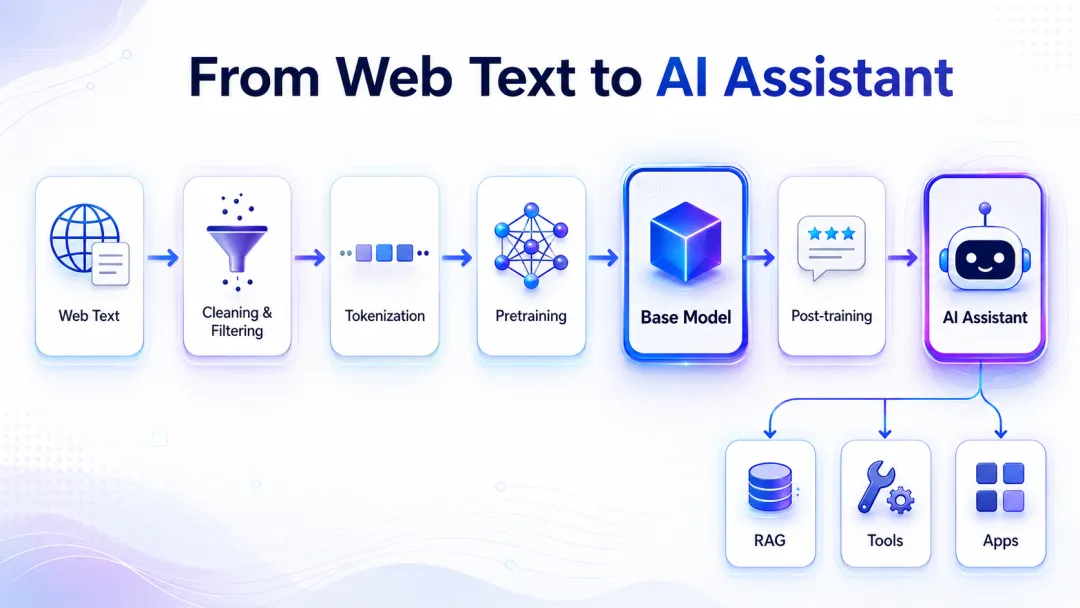
起点
链路的起点是互联网文本。
训练 LLM,第一步是收集海量文本。公开网页抓取只是原材料,里面混杂着广告、导航栏、重复页面、垃圾内容、恶意站点、个人信息以及各种网页结构。真正进入训练集之前,还要经过正文抽取、语言识别、过滤、去重和隐私处理。
比如 FineWeb 这类数据集,规模可以达到 44 TB 文本、约 15 万亿个 token。除了规模,影响模型行为的还有筛选规则:哪些页面被留下,哪些语言和领域占比更高,哪些内容被判定为低质量或危险内容。
对纯文本预训练阶段来说,模型并不直接接触现实。它接触的是人类留下的文本记录:百科、论坛、教程、代码、论文、新闻、食谱、商品介绍,以及无数网页片段。我们说模型“知道”某些东西,实际指的是这些文本规律被压缩进了参数。
分词
清洗解决的是哪些文本可以用的问题,但还没有解决文本如何进入模型的问题。
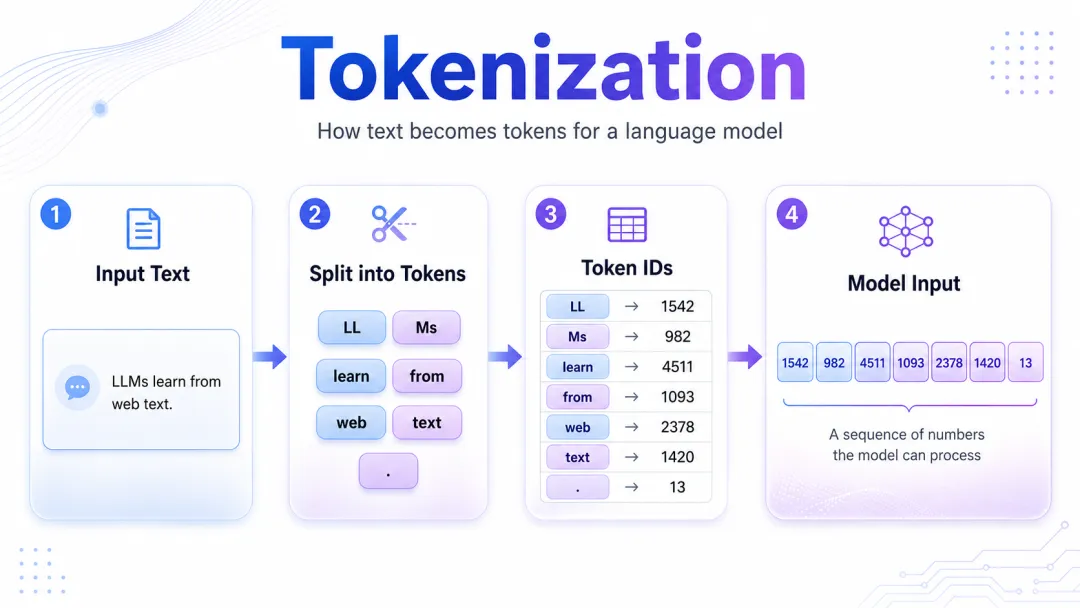
神经网络处理的是数字,不是自然语言。文本会先被切成 token,每个 token 再映射成一个编号。以 GPT-4 时代常见的 cl100k_base tokenizer 为例,词表规模约 10 万个 token,BPE 分词算法会从较小的字符或字节单位开始,不断合并高频出现的相邻片段,最后形成一套既能覆盖常见词,又能处理新词、拼写变化和多语言文本的词表。
模型输入的并不是人眼看到的完整句子,而是一串token。它学到的也不是字典里的静态词义,而是这些token在上下文里如何相互关联。
训练目标
预训练的核心目标:预测下一个 token。模型要做的事情很简单:根据前面的 token,预测下一个 token。
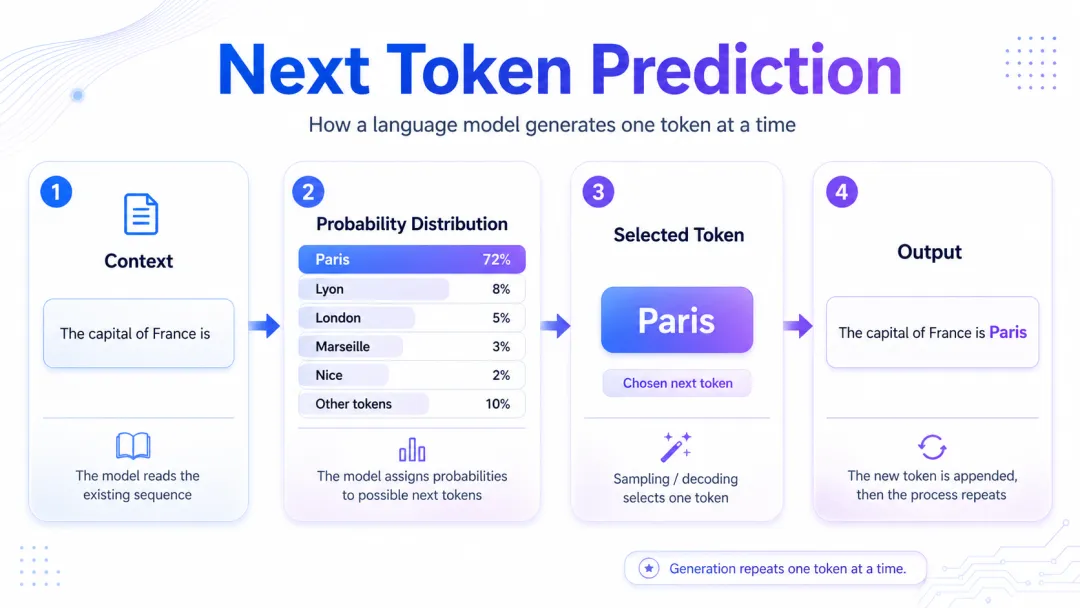
一个 Transformer 模型刚初始化时,参数基本是随机的。训练系统给它一段 token 序列,让它猜下一个 token。猜错之后,根据误差调整参数;再猜,再修正;重复数十亿次。随着训练推进,loss 下降,模型逐渐学会拼写、语法、事实关联、代码模式,以及一部分常见推理模式。
LLM 的基础能力来自下一 token 预测。很多看起来更高级的能力,并不是单独设计出来的,而是在大规模训练中由下一 token 预测这个目标间接获得的。
“模型内部没有知识库”。模型里没有某一行写着“巴黎是法国首都”。更接近事实的说法是:海量参数共同编码了大量文本中的统计关系,让某些句子、事实和推理路径在合适的上下文里更容易出现。它像一种有损压缩,保留了大量语言和知识规律,但不保证每个细节都能被准确还原。
预测
训练阶段是在反复练习这个预测任务;使用阶段,本质上也是在执行同一个动作。
用户输入问题时,模型会根据当前上下文计算下一个 token 的概率分布。系统从这个分布里选出一个 token,把它接到已有文本后面,再继续预测下一个。答案就是这样一步一步生成的。
这就是为什么同一个问题可能得到不同答案。模型不是先在内部写好完整答案再输出,而是在每一步做一次概率选择。temperature 控制这种选择的随机程度:温度低,输出更确定;温度高,输出更发散。创造性和不可预测性,来自同一个机制。
到这一步,模型还只是一个很强的文本续写器。这种逐 token 生成机制,足以让模型续写文本,但还不足以让它稳定地按照用户期望回答问题。
预训练后的基础模型,本质上是在延续模式。给它百科开头,它可能继续写百科;给它问答片段,它可能继续补答案;给它几组翻译示例,它也可能按格式完成下一组。它具备广泛能力,但还没有学会如何作为 AI 助手回答用户。
后训练
预训练解决的是通用文本能力问题,而不是产品形态问题。要让模型变成AI 助手,还需要专门训练它的对话行为。
后训练一般分两类:
第一类是监督微调。标注人员,或者经过筛选的合成数据,会提供大量理想对话样本。模型继续在这些对话上训练,于是学会理解用户意图、组织答案、保持礼貌,并遵守一些边界。
第二类是偏好优化。评审者比较多个回答,标出哪个更好;系统训练奖励模型来预测这种偏好;再让 LLM 更倾向于生成符合这些偏好的回答。监督微调教模型像助手一样说话,偏好优化继续调整模型,让它更倾向于生成被评审者认为更好的回答。
所以,LLM 聊天的风格,分点回答、谨慎措辞、拒绝某些请求、承认不确定性,都和后训练阶段的标注规范、偏好排序和产品目标有关。
RAG
后训练可以改变模型的回答方式,但不能让模型自动获得训练之后的新知识,也不能让它凭空读取企业内部资料。
RAG 的作用,就是把外部资料临时放进上下文,而不是重新训练模型。系统先把文档转成向量;用户提问时,检索最相关的片段;再把这些片段连同问题一起交给模型。模型生成答案时,就更可能依据刚刚提供的资料,而不是只依赖参数里的旧信息。
参数保存的是训练阶段压缩下来的统计规律,上下文则是模型当前可以直接读取的任务材料。参数容量大,但不可直接查询,而且有时间边界;上下文容量有限,但可以放入当前任务所需的精确材料。
所以企业知识问答系统不能只是一个模型 API。它还需要文档切分、向量检索、排序、上下文拼接、引用和评估。模型负责生成语言,系统负责把可靠材料放进上下文。
完整链路
这条链路可以压缩成一张表:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总结
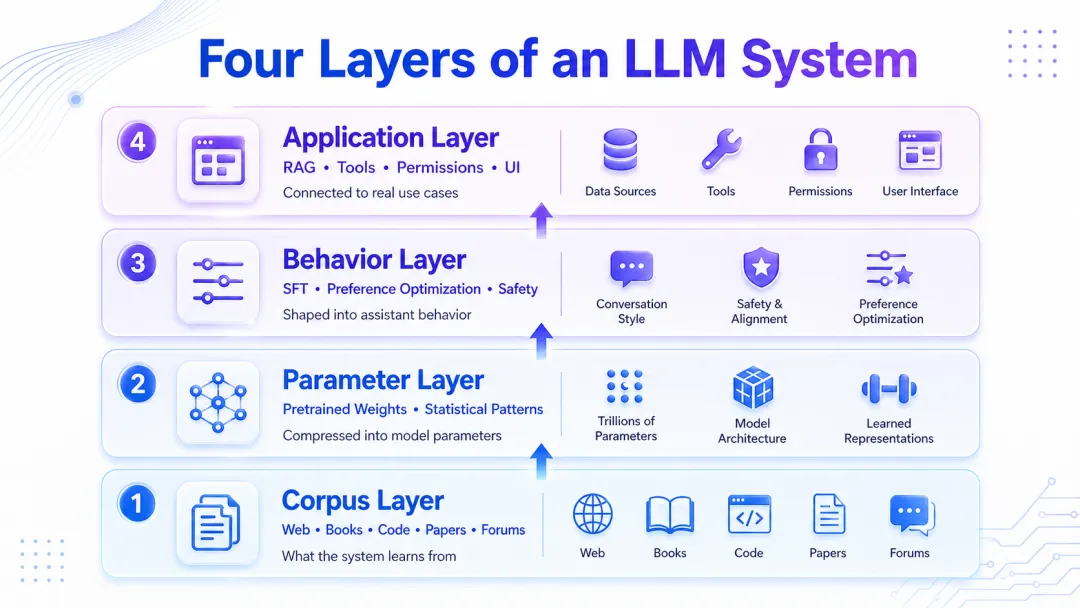
第一,LLM 的底层训练目标比产品表现简单得多。核心任务是预测下一个 token,但在足够大的数据、参数和计算规模上,这个目标会扩展出很多可用能力。
第二,预训练只得到基础模型,不等于得到可用的 AI 助手。后续的监督微调、偏好优化、系统提示、检索和工具调用,都会影响最终表现。
第三,幻觉是生成式模型的结构性风险:训练目标、数据噪声、上下文不足、采样机制和缺少外部校验,都会让模型生成听起来合理但未必真实的内容。检索、引用、拒答训练和工具调用,都是在给这个概率生成过程增加约束。
更实用的分层方式,是把 LLM 系统看成四层。
语料层决定它学过哪些文本世界。
参数层把这些文本规律压缩进神经网络。
行为层通过后训练,把续写器塑造成助手。
应用层通过检索、工具、权限和界面,把模型接入具体使用场景。
公司文档答不好,可能是检索问题;回答太啰嗦,可能是产品提示和后训练问题;事实出错,可能是知识截止、上下文不足或采样机制问题。
LLM 是一套复杂工程:先通过预训练把大规模文本规律压缩进参数,再通过后训练、检索、工具和应用层设计,把基础模型变成可用的 AI 助手。
https://ynarwal.github.io/how-llms-work/