当前时间: 2026-04-26 18:57:40
更新时间: 2026-04-26
分类:软件教程
评论(0)
炸了!中国两大万亿AI模型同周开源,卷疯全球
↑阅读之前记得关注+星标✨,每天才能第一时间接收到更新
谁懂啊家人们!AI圈最近的热闹程度,堪比过年赶大集,而且还是重量级大瓜连番炸场——就在同一周,两个中国万亿参数开源模型先后官宣落地,直接把全球AI圈看懵了,这波操作真的不是提前约好的吗?🤯
先给大家捋捋这两个“狠角色”,每一个都自带王炸buff,随便拎一个出来都能独当一面,结果偏偏撞了档期,主打一个“神仙打架,凡人围观”。
王炸双响:同周上线,直接刷新开源天花板
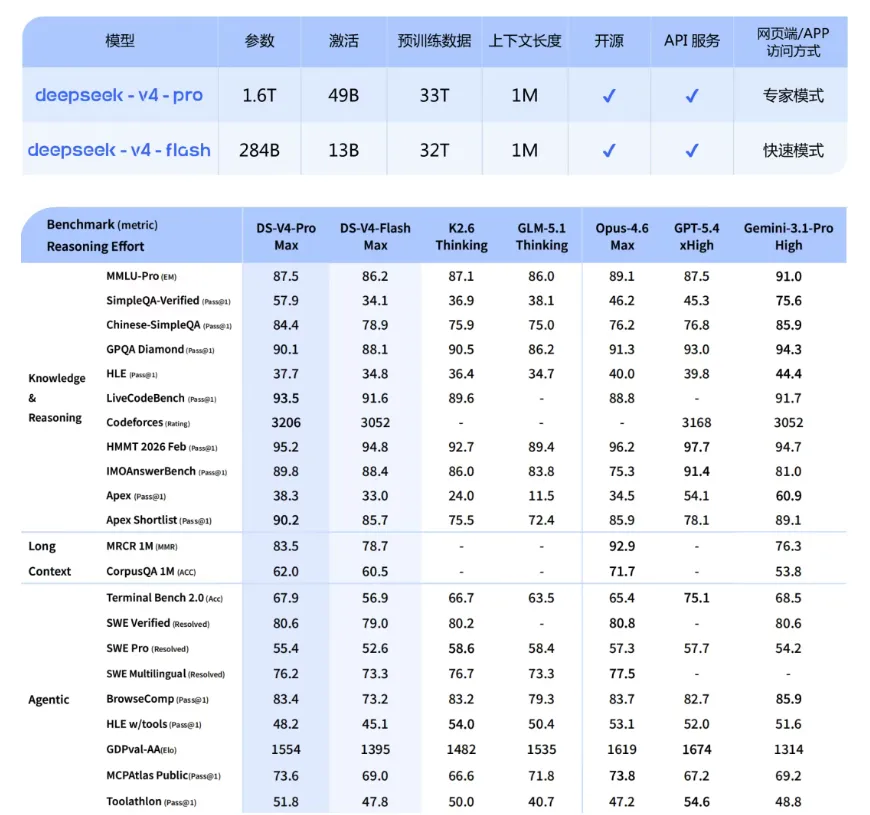
首先登场的是DeepSeek V4,一出手就自带“炸场体质”:1.6万亿参数拉满,百万token上下文的KV缓存直接砍到前代的1/10,相当于以前要占10个柜子的东西,现在1个柜子就装下了,效率直接起飞。更绝的是它的代码能力,Codeforces评分冲到3206,不仅超过了GPT-5.4,在人类选手中都能排到第23名,这水平放在程序员圈,妥妥的大佬级别的存在!
更实在的是,DeepSeek直接把开源权重、API,还有近60页的技术报告一股脑扔了出来,连藏私都没有,社区大佬们已经连夜开工,蹲在电脑前拆模型、学技术,主打一个“开源即共享”。
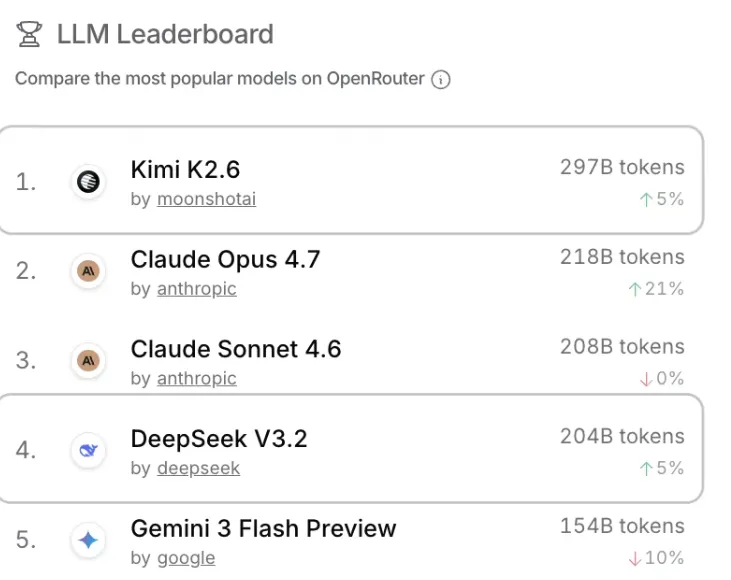
这边DeepSeek的热度还没下去,另一边Kimi K2.6就紧接着登场,同样是万亿参数的MoE模型,还能支持300个子Agent协同干活,简单说就是一个“超级团队”,能同时处理多种任务,效率直接拉满。上线没多久,OpenRouter的调用量就直接冲到全球第一,297B tokens的调用规模,把Claude、Gemini这些老牌选手都甩在了后面,气场直接拉满👏
心有灵犀?两大巨头的“撞车”史,早就有迹可循
其实这已经不是DeepSeek和Kimi第一次“撞车”了,回看过去15个月,这两家的技术方向和发布时机,对齐得让人怀疑是不是共享了“作战计划”,顶尖玩家果然总在同一个山口相遇。
2025年1月,DeepSeek的推理模型和Kimi的多模态思考模型同日上线,相隔也就两小时,说是“前后脚”都不为过;就连OpenAI的论文都认证,他们两家是最早复现o1思维链的团队,实力直接被国际认可。
之后的日子里,两家更是开启了“你追我赶、互相印证”的模式:你改Transformer注意力机制,我就搞混合块注意力;你出数学推理专项模型,我就跟着发布同路线的自验证模型;你用流形约束改造残差连接,我就搞“注意力残差”,还被Karpathy、马斯克等大神点赞。
到了2026年4月,这两家干脆直接“同框炸场”,万亿开源模型一起落地,不得不说,这默契度,连闺蜜都得羡慕。
技术互喂:你用我的优化器,我用你的注意力
表面上是竞争,背地里却是“互相成就”,这大概就是中国AI开源的底气——两家的技术不仅同步,还在互相加持,你用我验过的技术,我借你优化的方案,主打一个“抱团取暖,共同进步”。
Kimi K2的注意力机制,用的就是DeepSeek首创的MLA(多头部潜在注意力)。以前的多头注意力,每个注意力头都要单独存Key和Value,上下文越长,缓存就越大,越用越卡;而MLA直接把Q/K/V压缩成一个低秩的潜在向量,推理时只需缓存这个压缩向量再解压,KV缓存量直接大幅缩减,这才让K2能顺利扩展到万亿参数。
反过来,DeepSeek V4则用上了Kimi验证过的Muon优化器。主流的AdamW优化器,是对每个参数单独做自适应缩放,而Muon更厉害,直接对整个梯度矩阵做正交化,让更新方向更均匀,效率也更高。
可能有人不知道,Muon最初只是在小模型上验证过,是Kimi团队在2025年初的论文中,首次把它扩展到大规模训练,实验显示,相同算力下,Muon的计算效率差不多是AdamW的两倍;后来在万亿参数的K2模型上,Kimi还开发出了MuonClip,实现了15.5万亿token预训练全程零loss spike,稳定性拉满。而DeepSeek V4的技术报告里,也明确引用了Kimi的这篇论文,直言用Muon优化器,能带来更快的收敛和更好的训练稳定性。
除了这两点,两家在KV缓存、长上下文等核心技术上,也在平行推进:Kimi做分离式存储调度,DeepSeek就搞异构KV缓存;Kimi最早把长文本从概念变成用户记忆点,DeepSeek就接过接力棒,把推理算力降到前代的27%,KV缓存砍到1/10,彻底解决长上下文的成本难题。一个筛选值得关注的token,一个改写注意力计算规则,殊途同归,都在往Transformer最头疼的成本问题上动刀。
老外实锤:中国模型,才是真香底座
这两家的实力,不仅国内认可,连国外巨头和企业都在偷偷“蹭”,说中国模型是老外“套壳”的首选,一点都不夸张。
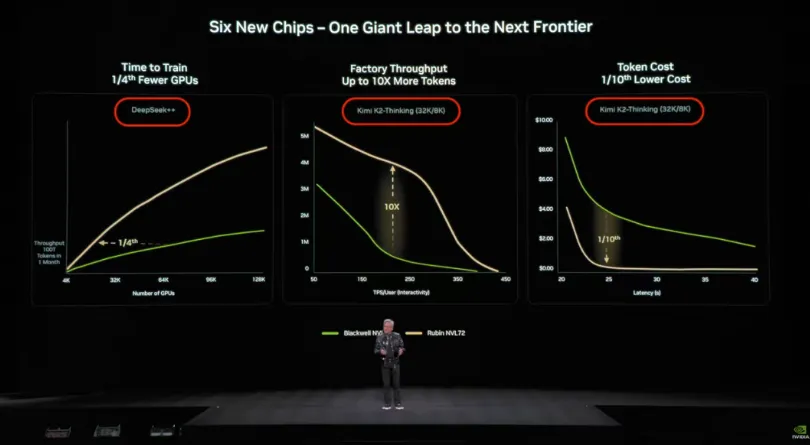
2026年初的CES大会上,黄仁勋展示Rubin NVL72性能的PPT里,训练基准用的是DeepSeek,推理吞吐和token成本基准用的是Kimi K2-Thinking,同一张PPT,两个中国开源模型,这排面直接拉满!
Meta的Muse Spark官方博客里,也把DeepSeek-V3.1 Base和Kimi-K2 Base,跟Llama 4 Maverick放在一起做代码困惑度对比,要知道,代码困惑度越低,说明模型对未见过的代码库理解能力越强,能被Meta选中对标,足以证明中国模型的实力。
更有意思的是,估值500亿美元的AI编程工具Cursor,3月份发布“自研”模型Composer 2,结果不到一天就被开发者扒出底裤——API日志里的模型ID,明明白白写着“kimi-k2p5-rl-0317-s515-fast”,说白了就是基于Kimi K2.5改的。后来Cursor创始人也不得不承认,没提Kimi基座是疏忽,还直言“Kimi K2.5是我们测试过的最强基座模型”,主打一个“嘴上说自研,身体很诚实”🤣
无独有偶,日本乐天同月发布的Rakuten AI 3.0,也被社区发现底座是DeepSeek V3,看来中国开源模型,已经悄悄成为国外企业的“香饽饽”。
而OpenRouter的调用量排行榜,更能说明问题:Kimi K2.6以297B tokens排名第一,DeepSeek V3.2以204B tokens排名第四,前五名里两个中国模型,夹在中间的都是Claude这样的国际巨头,这实力,不服都不行!
暗线同步:芯片赛道,一起发力破局
除了模型本身,两家在芯片这条暗线上,也在朝着同一个方向发力,毕竟AI模型要落地,芯片就是“基石”,没有靠谱的芯片,再强的模型也难以发挥实力。
DeepSeek V4的技术报告里明确写到,他们的细粒度专家并行方案,已经同时在NVIDIA GPU和华为Ascend NPU上完成了验证,也就是说,不仅能适配国外芯片,还能完美兼容国产芯片,打破国外芯片的垄断。
而Kimi的新论文《Prefill-as-a-Service》,则引入了分离式架构,专门推进国产芯片的混合推理方案,努力让中国AI模型,能在国产芯片上跑得更稳、更快、更省成本。
值得一提的是,两家公司的核心负责人,都先后参加了总理座谈会,都是中国AI领域被点名的代表。这两家公司都在2023年起步,短短两年多时间,就成长为中国AI创业公司里最受关注的存在,也是业内公认人才密度最高的团队,不得不说,中国AI的崛起,从来都不是偶然。
竞争是表面,加速才是真正的结果
有人说,这两家同周上线,是恶意竞争,但其实,真正的良性竞争,从来都不是互相拆台,而是互相成就。
当有些闭源模型还在互相猜忌、藏着掖着的时候,DeepSeek和Kimi已经在论文里互相引用、在代码里互相复用,把开源的精神发挥到了极致。他们的每一次“撞车”,都不是内耗,而是在互相推动技术进步;每一次技术互喂,都在降低中国AI的研发门槛。
同一周两个万亿开源模型落地,被GTC和Meta选为性能基准,被国外企业拿去当底座,被社区疯狂追捧,这背后,是中国AI底座技术的崛起,也是开源精神的胜利。
或许,这就是中国AI最动人的地方——不是一家独大,而是百花齐放;不是互相排挤,而是抱团前行。相信再过不久,中国AI一定会在全球舞台上,占据更重要的位置!
⭐点赞、转发、在看一键三连,点亮星标,每天第一时间get AI圈大瓜~
 夜雨聆风
夜雨聆风