 夜雨聆风
夜雨聆风





为什么你的 OpenClaw 总在’装傻’?6 个官方文档不会告诉你的隐藏机制
这篇文章里提到的所有配置细节和排坑命令,目前已浓缩成了一张 A4 速查表。
在公众号后台回复 【OpenClaw】 即可获取。
上周有个群友在群里吐槽:“昨天明明跟 OpenClaw 说好了每天早上 7 点发简报,结果今天发了两份一模一样的,还把上周的偏好设置全忘了。”
很多人都踩过完全一样的坑,反复折腾之后才搞明白:这不是 Bug,这是 OpenClaw 的设计哲学,只不过官方文档根本没讲清楚。

今天把实操踩出来的 6 条隐藏机制全部讲清楚,每一条都是官方文档里找不到、但不知道就一定会踩坑的隐性规则。
定时任务总抽风?
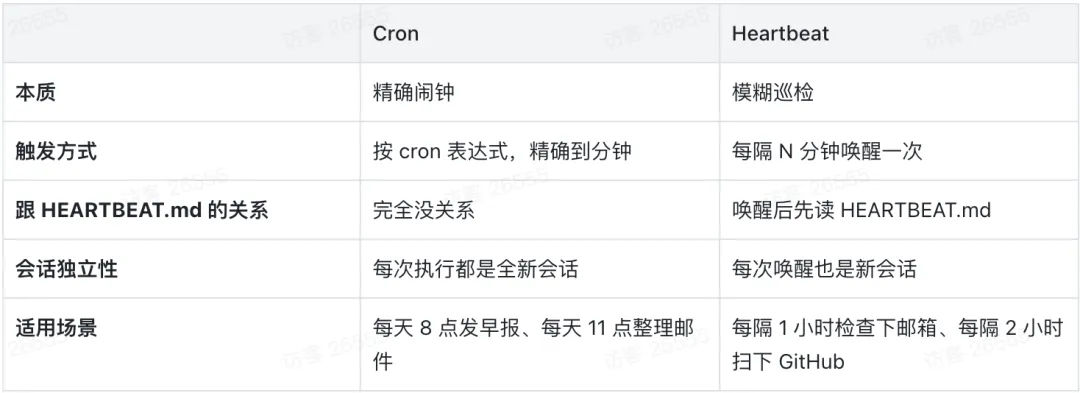
先搞懂 Heartbeat 与 Cron 的本质区别。
最常见的误解是把 Cron 当成“万能定时器”。一个做外贸的朋友想让 OpenClaw 每小时自动检查 Gmail 有没有客户询盘,直接写了个 0 * * * *,结果一天下来后台跑出了 24 个互相不认识的独立会话,每个都在重复“你好,我是辅助邮件处理的 AI 助理”的自我介绍。这就是没分清两套独立系统的代价。
这两套机制极易被混淆,但在底层逻辑上完全独立。
-
• Cron 的本质是精确闹钟。 采用标准 cron 表达式,精确到分钟触发。适用于每日准点播报、定时整理邮件等确定性任务。每次执行均唤醒完全独立的新会话。 -
• Heartbeat 的本质是模糊巡检。 每隔 N 分钟唤醒一次,唤醒后首要动作是读取 HEARTBEAT.md。适用于周期性的异步检查,例如“每隔一小时检查一次特定收件箱”或“每两小时拉取一次 GitHub 更新”。每次唤醒同样开启新会话。
核心防坑指南: 发现
HEARTBEAT.md为空时无需惊慌,这仅代表当前暂无巡检需求,并非系统宕机。
聊着聊着就断片?
很多时候吃完午饭回来继续布置任务,发现 Agent 像变了个 AI 一样毫无默契。这时候去翻日志才会发现,系统早就静默开启了新会话。这就要看透“新会话”的触发边界。
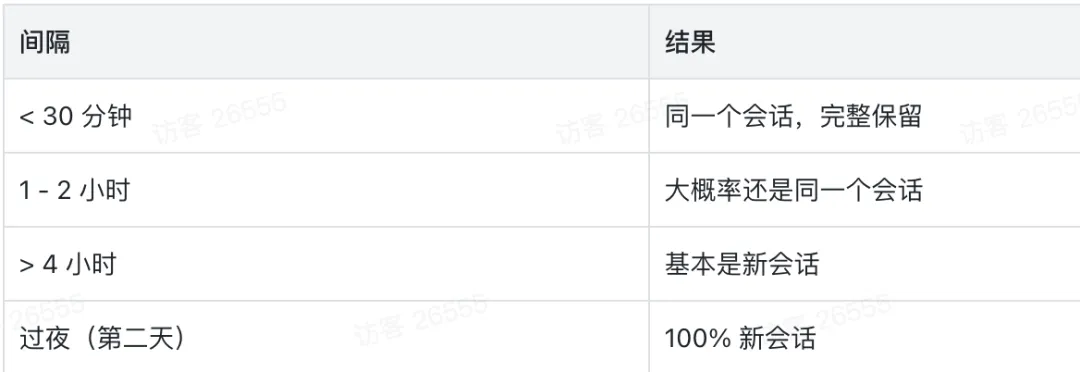
文档中未标明硬性时间阈值,系统实际上是基于活跃度进行动态判定的。理解这一点,是解决上下文断层的前提。
-
• 同一会话(完整保留): 间隔小于 30 分钟。 -
• 大概率同会话: 间隔 1 至 2 小时。 -
• 大概率新会话: 间隔超过 4 小时。 -
• 绝对新会话: 跨夜(次日触发)。
除了时间流逝,其他必然触发新会话的场景包括:跨通道切换(如从微信切换至飞书)、Cron 任务触发、Gateway 重启以及系统版本升级。

实操中最保险的习惯是:离开超过 30 分钟再回来时,先发一句“请确认还记得之前在讨论什么”。如果接得上,说明还在同一个会话;如果开始自我介绍,说明已经切了新会话,这时候提醒去读
MEMORY.md即可。
它隔夜就忘了你说的话?
第一次被这个坑坑惨是在配置晨间简报的时候。头天晚上反复调好了简报格式,第二天早上 Cron 触发之后,发来的东西跟没调过一样。当时以为是 Cron 出错,排查了一个小时才意识到,新会话根本没有加载昨天的记忆文件。

翻阅源码和社区讨论后发现,这不是个例,而是架构设计的必然结果。
从规范理论上看,新会话理应自动加载 SOUL.md(角色认知)、USER.md(用户认知)、近期 Daily Memory(短期记忆)以及 MEMORY.md(长期约定)。
但观测到的实际情况完全两码事:
-
1. 当前会话历史: 100% 保留。 -
2. 身份与用户认知文件: 作为 System Prompt 注入,但不一定会被大模型全文精读。 -
3. 各类记忆文件: 绝大多数情况下不会自动读取。 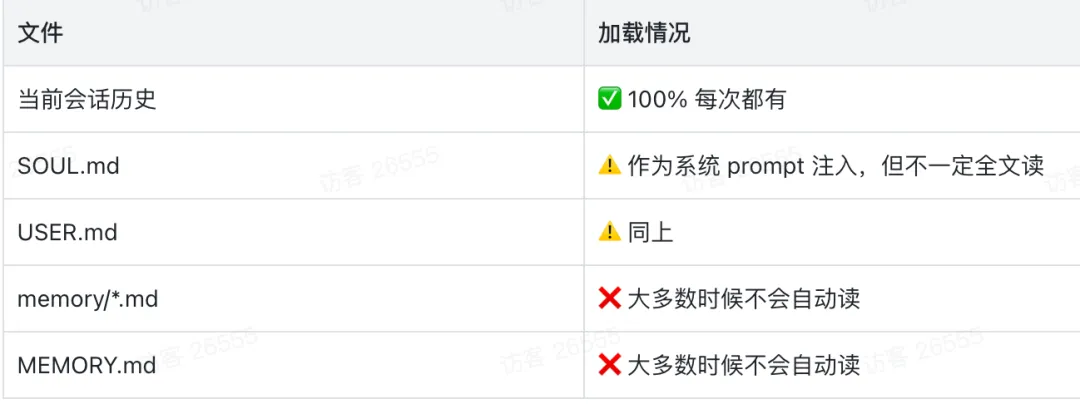
关键结论:跨会话的记忆延续,完全依赖 Agent 主动去读取文件系统。 日常场景中常会出现“昨日刚达成共识,今日又重新提问”的现象。这并非模型发生遗忘,而是在新会话的沙盒里,相关记忆文件根本未被加载。一个架构优秀的 Agent 应当具备规范的“新会话启动仪式”:先确认当前日期,接着拉取长期记忆与近两日的流水账,确认状态对齐后再开始输出响应。
聊得越多反而越蠢?
遇到过一个极端的案例,让 Agent 顺着一个长线项目改了一整天的代码,到了晚上不仅开始胡言乱语,连最初的核心需求都丢了。

会话历史不可能无限增长。随着消息数量的累加,系统会执行不可逆的单向压缩:
-
• 0 至 50 条: 几乎不压缩,完整保留细节。 -
• 50 至 100 条: 开始对最早期消息进行轻度摘要。 -
• 100 条以上: 压缩感明显,旧消息仅保留骨架要点。 -
• 200 条以上: 早期内容基本坍缩为简短的摘要形式。 -
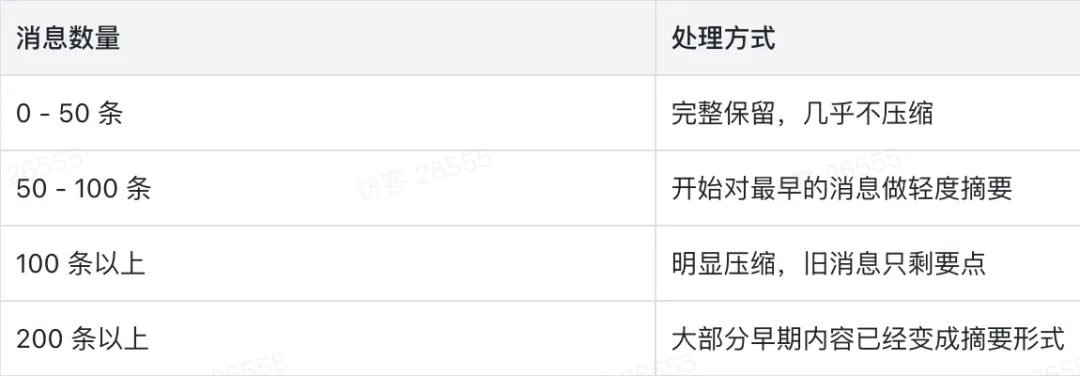
被压缩掉的信息是回不来的,最佳的工程实践是:永远不要依赖会话历史来存储重要信息,达成共识应立即写入文件系统。
微信和飞书不互通?
尝试过在微信端让 Agent 查阅一份长达 50 页的行业研报并提取核心数据,然后跑到飞书端基于这些数据写一份总结邮件。结果飞书端的 Agent 愉快地回复了一句:“好的,请提供需要总结的数据。”这就是多通道互不认账的尴尬瞬间。
多通道互不认账是 OpenClaw 刻意为之的设计选择。 微信与飞书的上下文实现了 100% 物理隔离。一端聊了上百条,另一端处于完全未知的状态。甚至可以在不同通道同时推进完全相悖的话题而互不干扰。

这种天然的隔离机制带来的好处是显而易见的:上下文更纯粹、压缩更慢、回答质量更高。代价则是信息无法直接互通。
解决信息孤岛的唯一方案是将文件系统视作共享的“全局内存”。无论是微信还是飞书,只要将核心决策沉淀至
MEMORY.md或专项文档中,双端即可实现跨通道的认知同步。
担心 API 账单爆炸?
真实的 Token 消耗比想象中低,刚跑通工作流的时候,天天盯着后台的 Token 消耗图表,生怕一不小心跑出天价账单,甚至想把所有 Prompt 压缩到极致。
连续对话时,单次调用的 Token 开销确实是滚雪球式累积的。但在当今起步动辄 128k 上下文窗口的时代,纯文本的日常交互极难撑爆上限。系统自带的自动压缩机制也会进行兜底。根据日常实操的数据,中重度使用纯文本对话,一个月的 API 账单大约在 50 元人民币左右,远低于预期。

真正消耗算力的是超大文件的分析与冗长代码的注入。 面对日常对话的 Token 消耗,过度优化的性价比极低,等账单真正发出警报时再做干预也为时不晚。若某一话题的探讨已深至数百条,主动结束并开启全新会话,反而能获得更干净的上下文和更精准的推理效果。
OpenClaw 的设计哲学
经过深度实操便会发现,OpenClaw 底层信奉的是一套极其克制的设计哲学:简单、可预测、拒绝黑盒魔法。
这套逻辑缺乏“开箱即用”的完美体验,甚至需要开发者去主动适应与沉淀记忆。但对于追求长期稳定运转的工程而言,这反而是最大的优势。毕竟在工程领域,可预测的残缺永远好过不可预测的智能。
加入交流群,一起探讨AI技术和商业机会。

这篇文章里提到的所有配置细节和排坑命令,目前已浓缩成了一张 A4 速查表,非常适合打印出来贴在工位上随时对照(包括 Cron 与 Heartbeat 的选择决策树、新会话启动仪式的标准 Prompt 模板、以及记忆文件的推荐目录结构)。
在公众号后台回复 【OpenClaw】 即可获取。