 夜雨聆风
夜雨聆风





如何让 OpenClaw 像 Hermes 一样去自动写技能
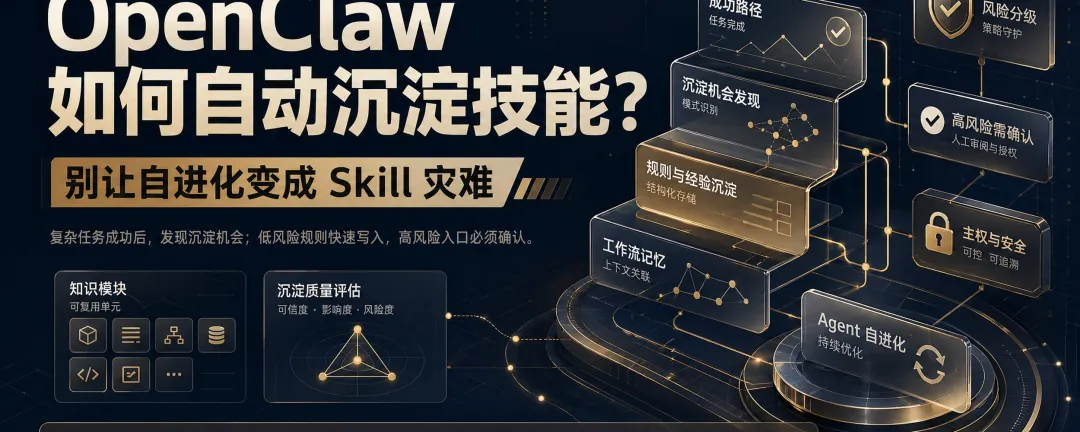
一个真正好用的 Agent,不能每次都从零开始。
它完成一次复杂任务之后,应该能记住这次是怎么跑通的:用了哪些工具,踩了哪些坑,最后哪条路径是稳定的。下一次遇到类似任务,它不应该再靠人反复提醒。
这就是 Hermes Agent 很有意思的地方:它不只是执行任务,还会尝试把执行经验沉淀成 Skill。
这件事很重要。
因为 Skill 本质上不是一段提示词,而是 Agent 的“工作经验”。当一个流程被写成 Skill,Agent 下次再遇到类似任务,就不用重新摸索,而是可以按一套成熟路径执行。
但问题也在这里:会自动写 Skill,是进化;乱写 Skill,就是灾难。
我们最近在思考的,就是怎么让 OpenClaw 也具备这种“自我沉淀”的能力,同时避免把原本稳定的 Skill 生态搞乱。
● ● ●
一、Hermes 的价值:Agent 不只会做事,还会积累经验
传统 AI 助手有一个问题:它每次都很聪明,但每次都像第一次干活。
你让它做一个复杂任务,它能查资料、读文件、跑脚本、生成图片、调用 TTS、合成视频、发到飞书。任务完成之后,聊天记录里确实有完整过程,但下一次呢?
如果没有沉淀机制,下一次还是要重新讲一遍规则。
这就是 Skill 的价值。
举个例子:视频号内容生产流程里,可能包含这些步骤:
读取公众号文章 → 改写口播文案 → 生成封面和配图 → 分段 TTS → ffmpeg 合成 MP4 → 抽帧 QA → 发飞书 → 生成标题、副标题、钩子和标签
如果每次都靠人提醒:“记得生成标签”“记得不要重复音频”“记得发飞书”“记得不要把频道名写进标签”,那这个 Agent 其实还没有真正长记性。
更理想的状态是:流程跑通一次,Agent 能主动意识到:这不是一次性操作,这是一个可复用工作流,应该沉淀成 Skill。
Hermes 强的地方就在这里。它把 Skill 看成 Agent 经验的一部分,而不是一个需要人手工维护的文档目录。
这个方向非常对。
一个 Agent 如果不能沉淀自己的成功路径,它永远只是“会执行”。只有能把执行经验变成下一次的默认能力,才开始接近“会成长”。
● ● ●
二、但自动写 Skill 也很危险
自动写 Skill 听起来很酷,但真正跑起来,很快会遇到另一个问题:Skill 会膨胀。
最常见的是三类灾难。
1. 测试阶段的废 Skill 被写进系统
很多流程第一次跑通,并不代表它已经稳定。
也许只是某个 provider 当时刚好没报错;也许只是某个 prompt 这次恰好能用;也许只是临时绕过了一个问题,但还没形成真正的标准路径。
如果这时 Agent 立刻把它写成 Skill,下次就会把一个“半成品经验”当成正式能力使用。
这类 Skill 最麻烦,因为它看起来像沉淀,实际上是污染。
2. 新 Skill 抢了旧 Skill 的入口
Skill 的危险不只在内容,还在触发词。
比如系统里已经有一个稳定的 wechat-video-account-publisher,负责把公众号文章变成视频号 MP4。它跑过很多次,知道图片、音频、合成、QA、飞书交付的完整边界。
这时如果一个实验 Skill 也写了类似描述:
Use when creating 视频号 MP4 packages...
那它就可能和原来的稳定 Skill 抢入口。
更糟的是,新 Skill 可能只解决了流程里一个很小的问题,比如“生成标签”,但因为描述写得太宽,反而接管了整个视频号工作流。
这就像一个刚实习一天的人,突然坐上了生产系统的调度位。
3. 最后变成 Skill 灾难
当废 Skill、重复 Skill、实验 Skill、稳定 Skill 混在一起,系统会出现一个很尴尬的状态:
Skill 越来越多;
触发边界越来越模糊;
老流程偶尔被新流程抢走;
Agent 自己也不知道该信谁;
用户发现“以前明明好用的东西,突然变差了”。
这就是 Skill 灾难。
它不是因为 Agent 不够聪明,而是因为没有治理机制。
自动写 Skill 的本质,不是“让模型多写几个 Markdown 文件”。真正难的是:什么时候写,写到哪里,什么时候可以接管入口,什么时候必须停。
● ● ●
三、OpenClaw 要怎么做:不自动乱写,但要主动提醒
OpenClaw 现在的问题不是不能写 Skill。
它能读写文件,能创建 SKILL.md,能跑 openclaw skills info 和 openclaw skills check,也已经有 skill-creator 这类技能创建指导。
真正缺的是一个机制:任务完成后,主动判断这次经验是否值得沉淀。
过去我们的 Skill 大多是人提醒后才写:
这个规则写进 Skill。以后都这样。下次别再犯。
这当然有效,但它依赖人一直盯着。
更好的方式是:复杂任务成功之后,Agent 自己先问一句:
这次流程已经形成稳定闭环,要不要沉淀成 Skill?
这就是我们现在采取的第一步:做一个 skill-reflection-suggester。
它不负责自动写正式 Skill,不负责自动改旧 Skill,也不负责抢入口。
它只做一件事:在复杂任务完成后,主动提醒这件事可能值得沉淀。
触发条件很简单:
工具调用很多 或任务跨多个阶段 或出现失败后修正成功 或用户纠偏形成明确规则 或这个流程未来大概率会重复
比如一次视频号任务里,如果经历了:
读文章 → 写口播 → 生成图片 → 合成音频 → ffmpeg 出 MP4 → QA → 飞书发送 → 补发布信息
这显然不是一次普通对话,而是一套可复用生产链路。
这时 Agent 就应该主动问:要不要沉淀成 Skill?
● ● ●
四、关键平衡:不是禁止进化,而是控制爆炸半径
我们不想走两个极端。
一个极端是完全不让 Agent 自己沉淀,所有 Skill 都靠人提醒。这样太慢,也浪费了 Agent 自己的执行经验。
另一个极端是任务一复杂就自动写 Skill,甚至自动修改稳定 Skill。这样太危险,最终会污染系统。
比较合理的中间路线是:动作可以主动,生效要分级。
低风险:可以大胆沉淀
比如这些规则:
文件命名;
本地目录结构;
元信息格式;
标签生成规则;
QA checklist;
prompt 模板;
本地打包流程。
这些即使错了,也不会立刻影响外部世界。Agent 可以主动建议,甚至在用户确认后快速写入。
中风险:可以建议,但要看影响范围
比如修改一个已有 Skill 的细节。
如果只是给现有流程补一个小规则,比如“MP4 完成后生成 视频号发布信息.txt”,这类修改可以接受。
但前提是:先读原 Skill,只做最小编辑,不重写整套规则。
高风险:必须确认
这些不能自动做:
修改稳定 Skill 的触发词;
替换已有生产流程;
改 daily cron;
涉及外部发送、发布、删除、凭证;
把实验路线变成默认路线。
这类能力一旦乱动,影响的不是一篇文章或一个视频,而是整个 Agent 的行为边界。
● ● ●
五、我们真正要的,是一个会复盘的 Agent
我越来越觉得,Agent 自进化的关键不是“自动写代码”,也不是“自动写 Skill”。
关键是它有没有复盘意识。
一个成熟的 Agent,应该在任务结束时问自己三件事:
这次有没有形成稳定成功路径? 下次遇到类似任务,能不能少走弯路? 这件事应该沉淀成规则、Skill,还是只是一条记忆?
这比“做完就结束”重要得多。
我们现在的方案很简单:先让 OpenClaw 学会主动发现 Skill 机会。
第一阶段,不自动写正式 Skill,只主动建议。
第二阶段,可以生成 draft Skill,但不抢入口。
第三阶段,低风险流程多次复用成功后,再考虑自动晋升。
高风险流程永远保留确认机制。
这套方案的目标不是把系统管死,而是让它敢进化,但不乱进化。
● ● ●
六、OpenClaw 的优势:它更适合做“可控进化”
Hermes 的优势在于更激进:它会尝试自己写 Skill,这让它有很强的自我生长感。
OpenClaw 的优势则在于更模块化、更容易治理。
它的 Skill 是文件化的,目录清晰;工具链、记忆、日程、飞书、浏览器、TTS、视频生成都能被拆开验证。一个流程能否沉淀,不需要停留在感觉上,而是可以看见:
产物有没有生成;
文件有没有归档;
QA 有没有通过;
外部发送有没有成功;
Skill 是否能被扫描;
规则有没有影响旧流程。
这让 OpenClaw 很适合走一条“可控自进化”的路线。
不是每次都让 Agent 野蛮生长,而是让它在真实任务中发现经验,在低风险区域快速沉淀,在高风险区域保留人工确认。
一句话:
Hermes 让我们看到 Agent 会自己写 Skill 的价值;OpenClaw 要解决的是,怎么让这种能力不变成 Skill 灾难。
● ● ●
结语:真正成熟的 Agent,会把经验变成下一次的能力
我现在判断一个 Agent 是否真正有潜力,不只看它一次任务能不能做成。
一次做成,是执行力。
做完之后,能不能把成功路径沉淀下来,才是进化能力。
但这件事不能鲁莽。
Skill 不是越多越好。一个写坏的 Skill,可能比没有 Skill 更危险。因为没有 Skill,Agent 只是慢;坏 Skill 会让 Agent 自信地走错路。
所以最好的路线不是“不写”,也不是“乱写”。
而是:
复杂任务成功后,主动发现沉淀机会; 低风险规则快速写入; 稳定 Skill 保持主权; 高风险入口变更必须确认。
未来真正强的 Agent,一定不是每次都从零开始的 Agent。
它应该像一个越来越老练的同事:这次踩过的坑,下次不会再踩;这次跑通的流程,下次能直接复用;这次被纠正的规则,下次会主动提醒。
这才是 Skill 系统真正的价值。
Agent 最重要的能力,不是一次做对,而是做完一次之后,下一次知道自己该怎么做。
如果你有更好的见解,欢迎到评论区留言讨论。