 夜雨聆风
夜雨聆风





2026年最火热的AI技术赛道:实时语音对话互动方案完全指南
前言
最近两年,AI圈最火的方向是什么?
大模型?太卷了。
AI生图?红海一片。
那还有什么?🤔
实时语音对话互动——这个赛道正在爆发。
想想看,Siri用了这么多年,我们早就习惯了”说话”的交互方式。但为什么体验始终差点意思?
因为延迟!因为声音假!因为一打断就卡壳!
今天这篇文章,我们来聊聊怎么搭建一套真正能用的实时语音对话系统,从技术选型到落地实践,手把手教学。
一、你以为的语音对话 vs 实际的技术架构
先问自己一个问题:你以为的语音对话是什么?
录一段语音 → 发给AI → 收到语音回复?
太天真了。😏
真实的全链路是这样的
图:实时语音对话系统全链路技术架构
每一环都是一道坎:
听着复杂?别担心,2026年的开源生态已经相当成熟了。
二、技术选型:我试了20+方案,推荐这三套
我花了大量时间测试市面上的开源方案,最终总结出三套推荐组合,分别对应不同场景。
方案A:快速原型(预算有限的首选)⭐⭐⭐
适合人群:个人开发者、快速验证Idea、技术调研
麦克风 → RealtimeSTT → DeepSeek V3 → ElevenLabs延迟:~2秒优点:开箱即用,配置简单缺点:声音克隆需要付费
方案B:生产级中文方案(我的强烈推荐)⭐⭐⭐⭐⭐
适合人群:企业级应用、中文教育产品、智能客服、AI数字人
核心组合: – VAD:TEN VAD(声网开源) – ASR:FunASR(阿里达摩院) – LLM:DeepSeek V3 – TTS:CosyVoice 2.0(阿里) – 编排框架:Pipecat
为什么推荐这套?
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
方案C:高端商业方案(不差钱的首选)⭐⭐⭐⭐
适合人群:高端产品、全球化应用、追求极致体验
麦克风 → Silero VAD → Deepgram → GPT-4o实时API → ElevenLabs延迟:< 1秒优点:全球支持、最低延迟、最高体验缺点:贵
三、核心模块详解
3.1 语音活动检测(VAD)—— 容易被忽视的细节
VAD 是整个链路的第一环,但很多人会忽略它。
作用:判断用户什么时候开始说话、什么时候说完。
为什么重要?因为如果VAD不准确,要么AI抢答,要么用户说完半天没反应,体验直接崩。
推荐方案:TEN VAD(声网开源)
这是2026年声网最新开源的VAD,专门为实时AI对话优化,解决了”抢答、误判静音”等行业痛点。
备选方案: – Silero VAD:适合边缘设备,可以跑在树莓派上 – FunASR内置VAD:和ASR一体化,快速集成
3.2 语音识别(ASR)—— 选对模型事半功倍
ASR是整个系统准确率的关键。
强烈推荐:FunASR(阿里达摩院) ⭐ GitHub 15.2k Stars
这是阿里达摩院开源的端到端语音识别工具包,基于PyTorch开发,核心定位是弥合学术界前沿模型与工业界实际部署之间的差距。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
FunASR 核心能力矩阵:
|
|
|
|
|---|---|---|
| Paraformer-zh |
|
|
| Paraformer-zh-streaming |
|
|
| Fun-ASR-Nano |
|
|
| SenseVoiceSmall |
|
|
FunASR 不只是ASR,还集成这些能力:
3.3 大语言模型(LLM)—— 流式输出是核心
没有流式输出的LLM,语音对话体验直接腰斩。
推荐:DeepSeek V3
备选:Qwen-Max(阿里)、GLM-4(智谱)
3.4 语音合成(TTS)—— 这是差异化关键
TTS分两种:
1. 普通TTS:用预设音色2. 声音克隆:用特定人物的声音
3.4.1 推荐一:CosyVoice 2.0(阿里)⭐ 中文最强
这可能是目前中文场景最强的开源TTS方案:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CosyVoice 2.0 核心升级: – 相比v1版本,音质、保真度、延迟全面提升 – 支持情感控制、语速调节 – 提供预训练音色和自定义克隆两种模式
声音克隆三步走:
3.4.2 推荐二:VibeVoice(微软)⭐ 业界最低延迟
这是微软2025年开源的语音AI框架,技术突破令人惊叹:
|
|
|
|---|---|
|
|
|
|
|
~300ms
|
|
|
|
|
|
|
VibeVoice 的三大技术突破:
① 7.5 Hz 超低帧率分词器
|
|
|
|
|---|---|---|
|
|
|
7.5 Hz |
|
|
|
提升80倍 |
这使得90分钟音频压缩至约40,500个token,端到端LLM推理成为可能。
② LLM + 扩散头混合架构
核心洞察:混合架构明确解耦”说了什么”和”怎么说”,同时获得语义一致性和声学保真度。
③ 性能数据对比
|
|
|
|---|---|
|
|
8.34%
|
|
|
|
|
|
|
|
|
|
3.5 全链路编排框架—— 让各模块无缝协作
手动串联各模块?太累了。
3.5.1 推荐一:Pipecat ⭐ GitHub 10.8k Stars
这是2026年最火的开源语音AI编排框架。
|
|
|
|---|---|
|
|
18+
|
|
|
24+
|
|
|
18+
|
|
|
|
|
|
500-800ms
|
|
|
|
Pipecat 管线架构:
支持的服务商(部分):
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
Pipecat 开发工具:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
3.5.2 推荐二:VibeVoice(微软官方)
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
300ms |
|
|
|
|
|
|
|
|
|
|
|
优秀 |
四、落地实践:12周从0到1
很多人有想法,但不知道怎么落地。
我整理了一个12周实施路径:
POC阶段必须验证这些:
五、延迟优化:这些技巧让体验提升50%
延迟是语音对话的生命线。
5.1 端到端延迟分解
5.2 优化策略
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.3 核心技巧
1. 流式TTS:边生成边播放,不要等整句生成完再播
2. LLM+TTS同步:LLM每生成一个完整句子,立即触发TTS
3. 智能分句:按标点分句,前一句播放时下一句已经开始合成
六、成本估算及部署方案(参考)
成本分析分为两个维度:单并发方案(小规模验证)和 100并发方案(生产级部署)。
6.1 单并发方案
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
💡 单并发场景下,FunASR/CosyVoice/TEN VAD 本地部署于 RTX 4090(24GB显存),DeepSeek V3 使用 API,成本可控。
6.2 100并发方案
当业务规模扩大,需要专门的架构设计。
核心挑战
LLM推理是最大瓶颈: – FunASR/CosyVoice/TEN VAD:本地部署后被所有请求共享,无需按并发扩展 – DeepSeek V3 (671B):INT4量化需 ~20GB 显存,100并发需要 2000GB+ 显存
方案一:RTX 4090 集群 ⭐ 性价比首选
目标用户:中型产品、在线教育、智能客服
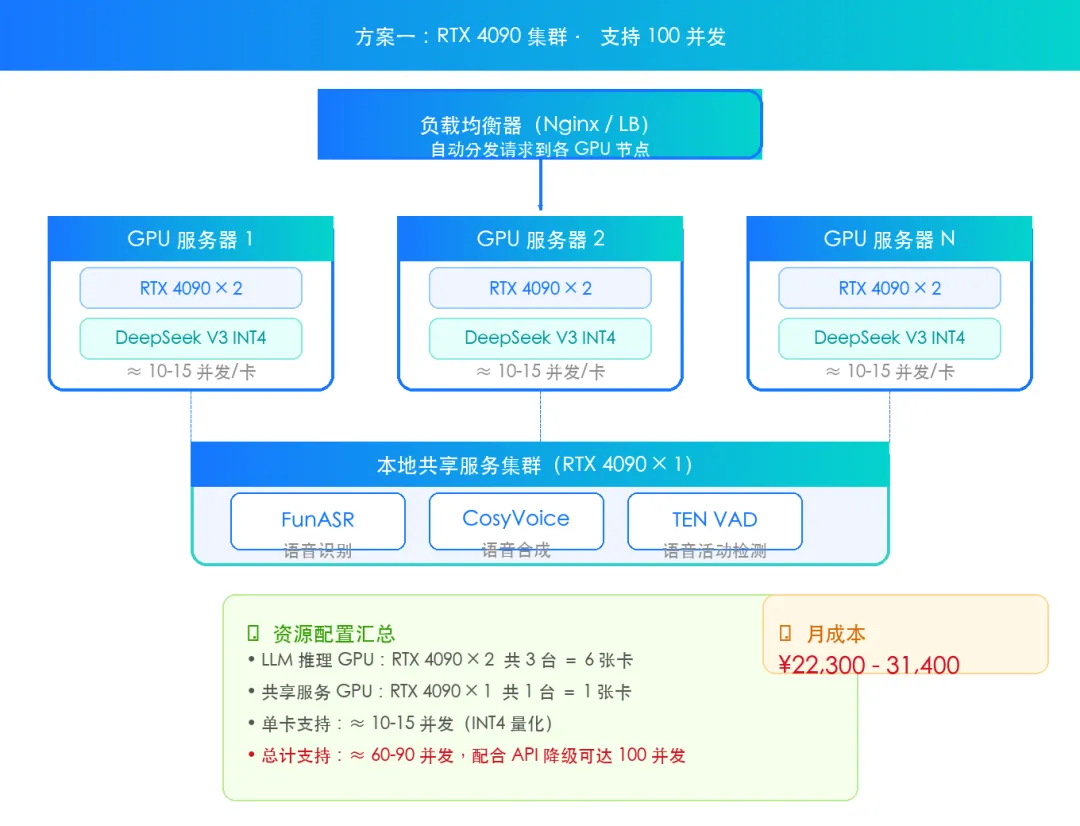
图:方案一 RTX 4090 集群架构
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 总计 | ¥22,300-31,400/月 |
并发能力:6张RTX 4090(INT4量化约10-15并发/卡)≈ 60-90并发,配合API降级可支撑100并发。
方案二:A100 集群 🔥 性能优先
目标用户:大型产品、高用户体验要求
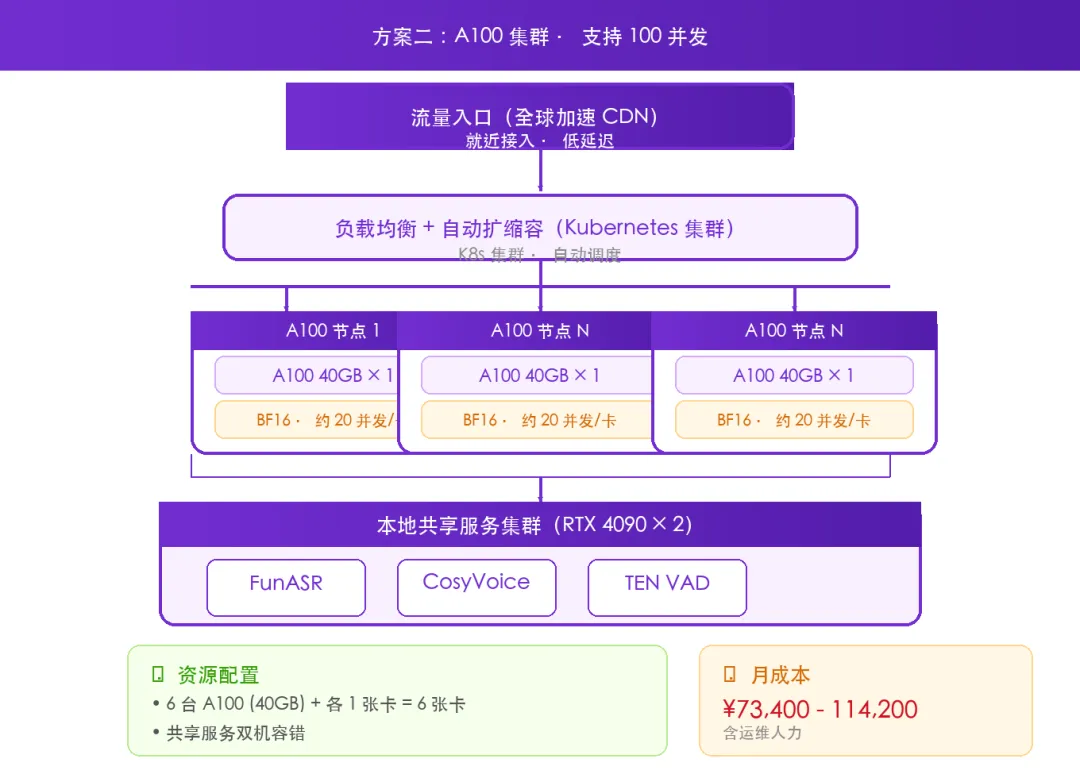
图:方案二 A100 40GB 集群架构
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 总计 | ¥73,400-114,200/月 |
并发能力:6张A100(BF16量化约20并发/卡)≈ 120并发。
方案三:混合云 API ⭐ 灵活起步
核心思路:本地部署 ASR/TTS 节省成本,LLM 使用云 API 按需扩展。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
| 总计 | ¥12,200-25,100/月 |
💡 推荐:如果团队技术实力有限,优先选择方案三。本地部署 ASR/TTS 节省70%成本,LLM 使用 API 确保稳定性。
100并发方案对比
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
📊 性价比分析:方案三的性价比最高,特别适合业务增长阶段。随着并发量增长,可逐步增加 GPU 将 API 成本转化为自有基础设施。
七、避坑指南
坑1:忽视VAD
很多人觉得VAD随便选一个就行,结果线上经常出现”AI抢答”或”说完没反应”。
解决:用TEN VAD,专门为实时对话优化。
坑2:TTS音质不行
用了通用TTS,声音听着像机器人,用户直接流失。
解决:用CosyVoice 2.0做声音克隆,MOS 4.0+接近真人。
坑3:延迟太高
端到端超过3秒,用户明显感知,体验崩塌。
解决:全链路流式处理,目标<1秒。
坑4:单点故障
LLM服务挂了,整系统就挂了。
解决:多服务商备份(DeepSeek + Qwen),自动降级。
参考资源
|
|
|
|
|---|---|---|
| Pipecat |
|
|
| VibeVoice |
|
|
| FunASR |
|
|
| CosyVoice 2.0 |
|
|
| TEN VAD |
|
|
感谢阅读,如果你觉得有用,点个「赞」吧