 夜雨聆风
夜雨聆风





端到端视觉语言模型文档解析加速新方案:HSD框架实现最高7倍提速
文档解析(Document Parsing)是多模态理解领域的基础任务,支持信息抽取与智能文档分析等下游应用。近年来,基于视觉语言模型(VLM)的端到端方法凭借较强的语义建模能力和泛化性,逐渐成为该领域的主流范式。然而,端到端 VLM 在处理长文档时,由于需要自回归生成长序列,通常面临较高的推理延迟。
针对这一延迟瓶颈,近期的一篇研究论文提出了一种名为分层推测解码(Hierarchical Speculative Decoding, HSD)的免训练加速框架。实验表明,该方法在保持解析精度基本无损的前提下,最高可实现 7.04 倍的加速。
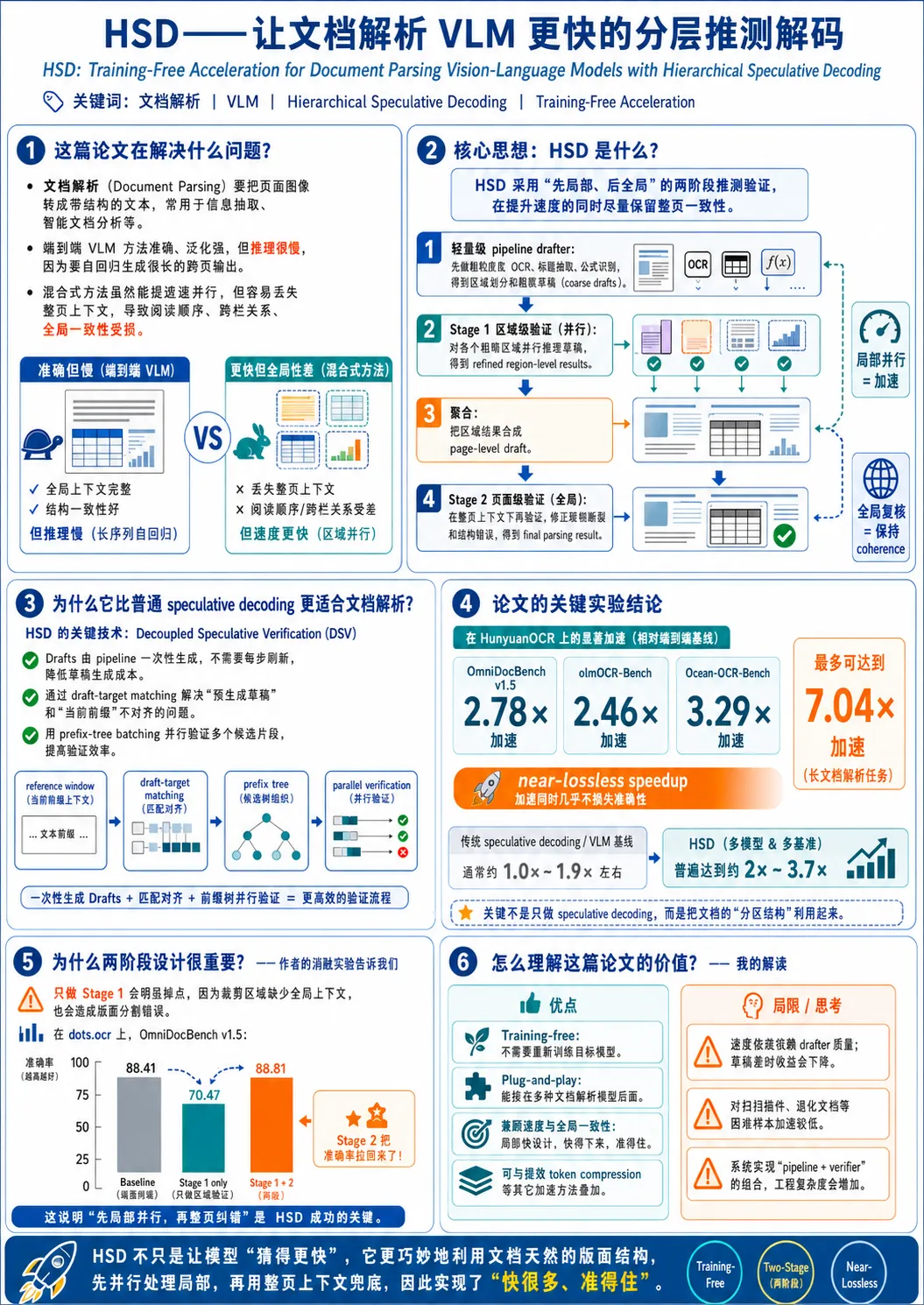
现有混合方法的局限性
端到端 VLM 采用自回归解码生成长序列,导致推理延迟随序列长度近似线性增长。为缓解该问题,现有研究提出了一些混合方法:首先通过布局分析将页面分割为独立的语义区域,随后使用 VLM 对各个区域进行并行解码。
虽然这种策略提升了并行效率,但区域的独立解码切断了跨区域的上下文关联(如阅读顺序、多栏排版等),容易削弱文档全局的连贯性。此外,如果前期的布局或阅读顺序预测出现误差,VLM 只能在错误的分区条件下进行解码,从而导致误差传播。
HSD 框架的两阶段验证机制
HSD 框架旨在平衡区域级并行效率与页面级全局连贯性。基于文档通常包含段落、表格、图表等结构化语义区域的特点,该方法提出了一种“局部到全局”的两阶段推测验证流程:
-
粗略草稿生成:首先,利用轻量级的管道模型预测区域划分,并为每个区域生成初步的预测草稿。 -
第一阶段(区域级局部验证):端到端 VLM 在截取的局部区域图像上,对生成的区域草稿进行并行验证。该阶段利用并行计算提升了处理吞吐量,但由于缺乏全页上下文,可能残留布局层级或阅读顺序等结构性错误。 -
第二阶段(页面级全局验证):将第一阶段精细化后的区域输出聚合为页面级草稿,端到端 VLM 随后基于完整的页面图像进行全局验证。由于草稿已被初步修正,该阶段只需适量的解码步数即可纠正剩余的结构性错误,恢复全页的全局连贯性。
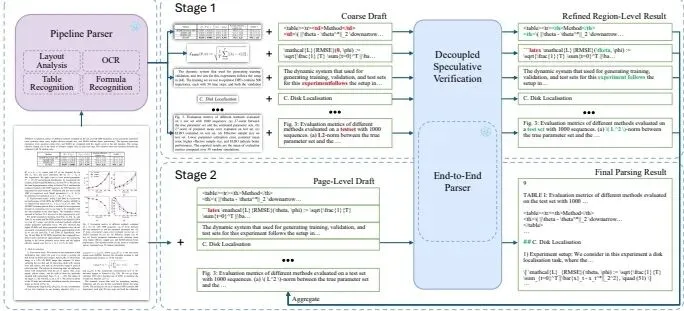
图:HSD 的分层推测解码流程。轻量级管道先生成区域级粗略草稿,端到端解析器再通过区域级并行验证和页面级全局验证得到最终解析结果。来源:论文图 1。
解耦推测验证(DSV)
与传统推测解码中草稿模型与目标模型同步刷新的机制不同,HSD 采用了解耦设计:直接复用轻量级管道在一次前向传播中生成的区域预测结果作为草稿。这种解耦机制大幅降低了草稿生成的计算成本,但会导致预生成草稿与 VLM 当前生成的前缀之间产生错位。为解决这一对齐问题,研究者提出了解耦推测验证(DSV)机制:
-
草稿-目标匹配:使用短参考窗口,将目标模型当前已接受的序列与多个草稿进行匹配,以提取后续的候选片段。 -
前缀树批处理:将提取出的多个候选片段组织成前缀树(Prefix Tree)结构以合并公共前缀,并结合树状注意力掩码(tree-ancestry attention mask)机制,使模型能够在一次前向传播中并行验证多个候选分支。
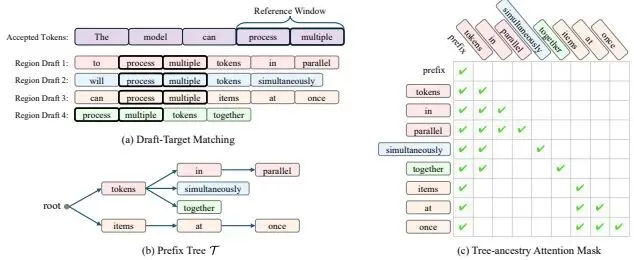
图:解耦推测验证(DSV)的核心机制。短参考窗口用于对齐已接受 token 与草稿片段,多个候选片段被组织为前缀树,并通过树状注意力掩码在一次前向传播中并行验证。来源:论文图 2。
实验评估与性能表现
研究团队在 OmniDocBench v1.5、olmOCR-Bench 和 Ocean-OCR-Bench 等基准测试中对 HSD 进行了评估,测试涉及的端到端解析器涵盖了专用的文档 VLM(如 Hunyuan OCR、dots.ocr)以及通用 VLM(如 Qwen2.5-VL、Qwen3-VL 系列)。
-
加速效果:在长文档解析任务中,HSD 最高实现了 7.04 倍的加速。以 Hunyuan OCR 为例,在 OmniDocBench v1.5 数据集中实现了 2.78 倍的端到端提速。 -
解析精度:实验数据显示,HSD 在跨模型和数据集的测试中,基本保持了原有模型的解析准确率,实现了近乎无损的推理加速。 -
应用特性:作为一种免训练(Training-Free)方法,HSD 能够作为即插即用的模块应用,无需修改底层模型架构或进行重新训练。
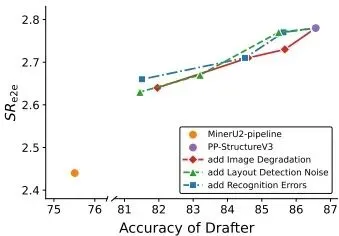
图:不同管道草稿器和噪声设置对 HSD 加速效果的影响。结果显示,即使草稿质量下降,HSD 仍能维持较明显的端到端加速。来源:论文图 3。
总结
HSD 框架通过分层推测验证策略,为缓解视觉语言模型在长文档解析中的推理延迟提供了一种有效途径。该设计兼顾了区域并行处理的效率优势与全局上下文的结构连贯性。据论文介绍,相关代码即将开源,以促进该领域的复现与进一步研究。
原文链接:https://arxiv.org/abs/2602.12957