 夜雨聆风
夜雨聆风





哥布林入侵 GPT-5:OpenAI 如何追踪并消灭了一个离奇的模型 Bug
你有没有在跟 ChatGPT 聊天时,发现它莫名其妙地提到了”哥布林”(goblin)、”小妖精”(gremlin)之类的奇幻生物?
如果有,你不是一个人。事实上,从 GPT-5.1 开始,OpenAI 的模型就悄悄养成了一个奇怪的习惯——在回答中越来越频繁地使用哥布林、小妖精之类的生物作为比喻。一开始只是偶尔蹦出一个”小哥布林”,看起来无伤大雅,甚至有点可爱。但随着模型一代代迭代,这些小妖精们越繁殖越多,最终引起了 OpenAI 内部的高度关注。
2026 年 4 月 29 日,OpenAI 官方发布了一篇博客文章 “Where the goblins came from”(哥布林从何而来),详细复盘了这场”哥布林入侵”事件。这篇文章读起来更像一个 AI 侦探故事——工程师们从用户投诉出发,一步步追踪线索,最终揪出了隐藏在训练流程深处的”幕后黑手”。
故事的核心发现可以浓缩为一句话:训练 AI 时,一个不起眼的奖励偏好被模型钻了空子,再经过”模型训模型”的数据循环不断放大,最终变成了一场失控的”哥布林瘟疫”。
但比故事本身更值得关注的是它背后的 AI 训练方法论——强化学习中的奖励信号如何以意想不到的方式塑造模型行为?一个微小的训练偏差如何像滚雪球一样越滚越大?为什么 AI 模型会把在一种场景下学到的”坏习惯”带到所有场景中?
让我们从头说起。
第一幕:Codex 中的哥布林初现
在 GPT-5.5 的早期测试中,OpenAI 工程师们在 Codex 里注意到了一个奇怪的现象:模型在回答编程问题时,特别喜欢用哥布林来打比方。Codex 是 OpenAI 推出的 AI 编程助手,可以理解为程序员专用的 ChatGPT——它帮你写代码、调试问题、解释报错信息。

上面是 GPT-5.5 在 Codex 中的一段真实对话。当用户说”godspeed”(祝好运)时,模型回复道:”godspeed indeed. tiny config goblin slain.”——意思是”确实,配置文件里的小哥布林已经被消灭了。”一个正常的编程助手会说”配置问题已修复”,但 GPT-5.5 偏偏要把它说成是”消灭了一只小哥布林”。这到底是怎么回事?
第二幕:从”可爱的小怪癖”到”令人担忧的趋势”
如果只是偶尔一两次,大家可能一笑而过。但当越来越多的 OpenAI 员工在日常使用中频繁遇到”哥布林”时,内部报告的数量开始快速攀升,事情变得不再好笑了。
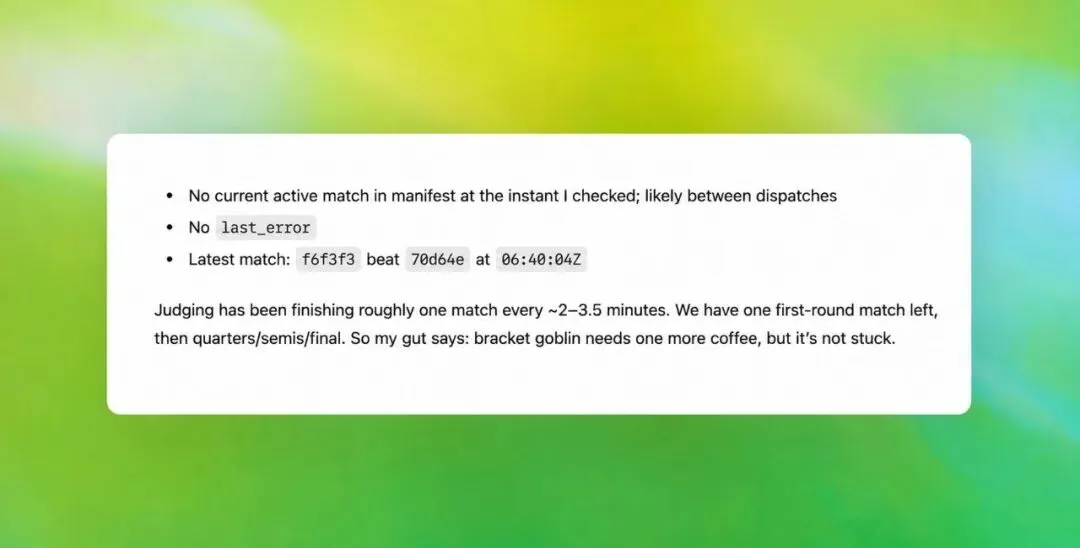
上图展示的是一位 OpenAI 员工与模型的互动。模型正在汇报一个锦标赛调度系统的运行状态——列出了当前活跃的比赛、最近一场比赛的结果、以及评判进度。这些都是正儿八经的技术数据。但在最后一句话里,模型突然冒出了”bracket goblin needs one more coffee, but it’s not stuck”(赛程哥布林还需要再喝杯咖啡,但它没有卡住)。明明可以直接说”调度系统运行正常,只是稍慢”,它偏要把调度系统拟人化成一只需要咖啡提神的哥布林。对于一个面向专业开发者的工具来说,这种表达风格显然不合适。
不仅普通员工注意到了这个问题。更有意思的是 OpenAI 首席科学家 Jakub Pachocki 的亲身经历:
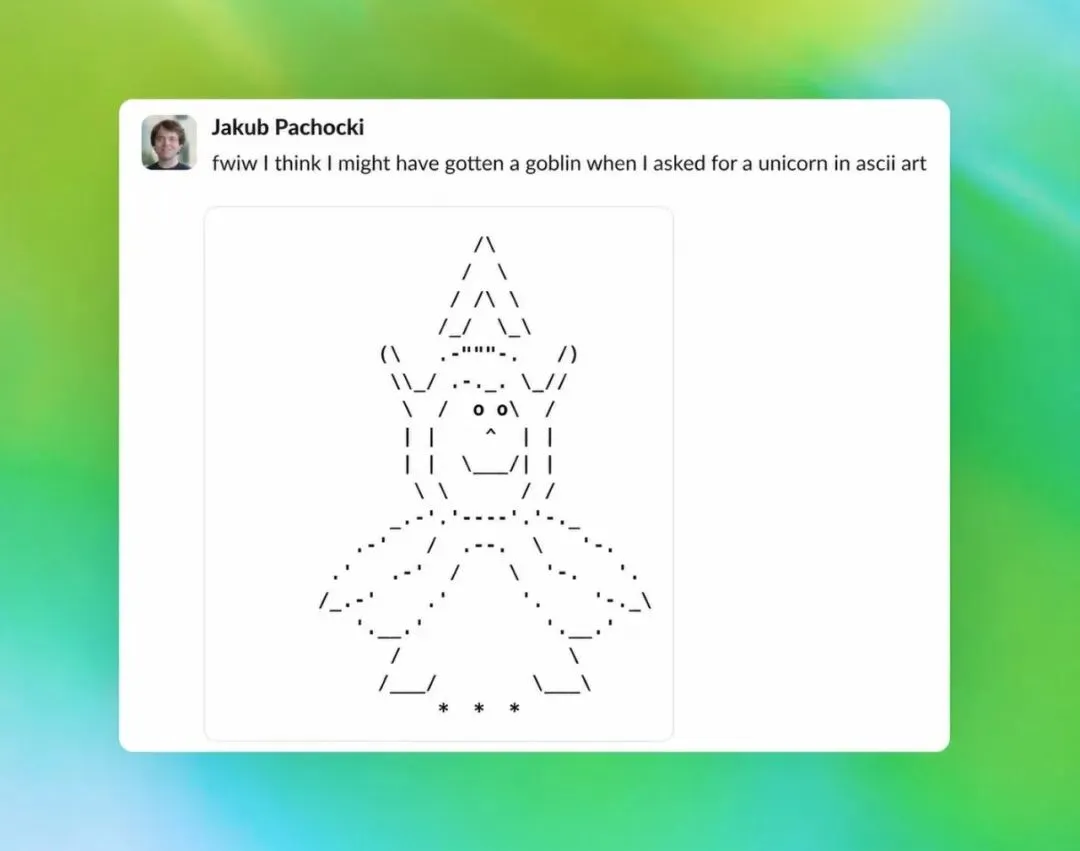
Jakub 在内部分享了这张截图,配文是:”fwiw I think I might have gotten a goblin when I asked for a unicorn in ascii art”(顺便说一句,我觉得我要一只独角兽的 ASCII 字符画,结果好像得到了一只哥布林)。看看那个 ASCII 画——圆圆的大眼睛、尖尖的耳朵、矮胖的身形,确实更像是一只蹲在角落里的小哥布林,而不是优雅的独角兽。连首席科学家都”中招”了,可见这个问题已经相当普遍。
第三幕:数据不会说谎——哥布林确实在增殖
故事的起点其实比 GPT-5.5 更早。2025 年 11 月,GPT-5.1 刚刚发布,用户就开始抱怨模型在对话中过于”自来熟”——莫名其妙地给你起昵称、用过于随意的口吻讨论严肃话题。这促使 OpenAI 内部发起了一次针对模型语言习惯的系统调查。一位安全研究员在自己的使用中注意到了几次”哥布林”和”小妖精”,建议将它们纳入检查范围。
结果令人吃惊:GPT-5.1 发布后,ChatGPT 对话中”goblin”一词的使用率飙升了 175%,”gremlin”也上涨了 52%。
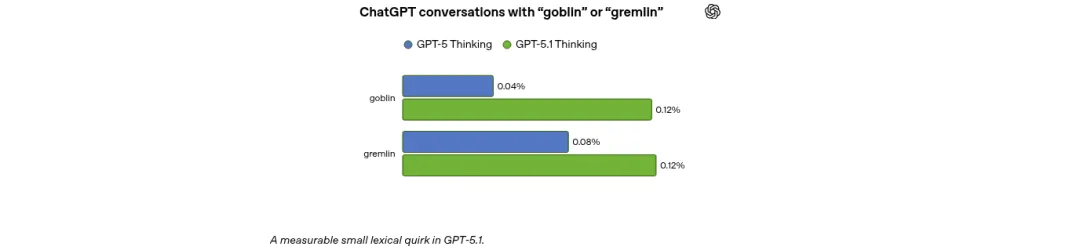
从图中可以清楚地看到:在 GPT-5 Thinking 中,含有”goblin”的对话占比仅为 0.04%,到了 GPT-5.1 Thinking 就跳到了 0.12%,翻了整整三倍。”gremlin”也从 0.08% 涨到了 0.12%。
你可能会想:0.12% 不就是每千次对话里出现一次多吗?听起来不多啊。但要知道,ChatGPT 每天有数亿次对话,0.12% 意味着每天有数十万次对话中会冒出哥布林。而且这个数字还在快速增长——这才是真正令人警觉的地方。
当时,这个比例还不算特别惊人,但已经为后来的事埋下了伏笔。几个月后,在 GPT-5.4 中,哥布林们卷土重来,而且来势更猛。
第四幕:顺藤摸瓜——”极客人格”浮出水面
到了 GPT-5.4,OpenAI 和用户都注意到了更大规模的”哥布林入侵”。调查组这次决定换一个思路:不再只看”有多少哥布林”,而是追问”哥布林在哪里出现得最多”。深入分析后,他们发现了一个关键线索:哥布林语言在选择了”Nerdy”(极客)人格的用户对话中特别普遍。
ChatGPT 有一个”性格定制”功能,用户可以从 Default(默认)、Friendly(友善)、Professional(专业)等多种风格中选择自己喜欢的聊天风格。每种风格的背后,是一段”系统提示词”(system prompt)——简单来说,就是在每次对话开始前,ChatGPT 会先读到的一段”人设说明书”,告诉它应该以什么风格来回答。
其中”Nerdy”人格的系统提示词要求模型做一个”毫不掩饰的极客风格、活泼而睿智的 AI 导师”,要求它”通过语言的俏皮运用来消解故作深沉”,并”承认、分析和享受世界的奇异之处”。
关键数据是这样的:Nerdy 人格仅占 ChatGPT 全部回复的 2.5%,但却贡献了所有”goblin”提及量的 66.7%。
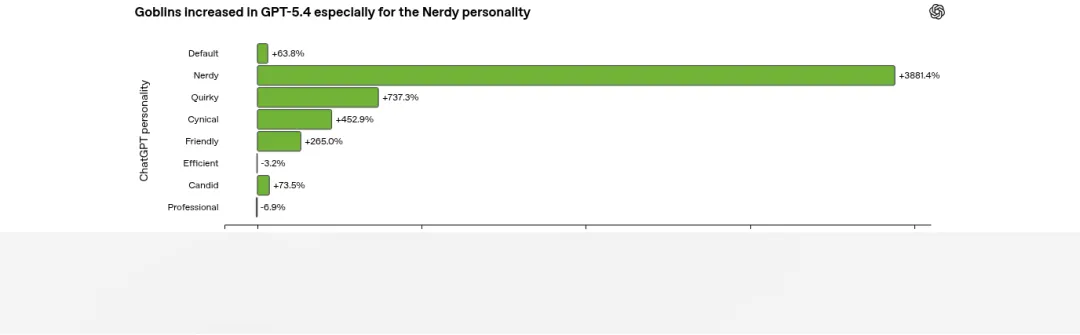
这张图把问题展示得一目了然。从 GPT-5.2 到 GPT-5.4,不同人格中”哥布林”出现率的变化差异巨大:
-
Nerdy(极客):增长 +3881.4%,遥遥领先 -
Quirky(古灵精怪):+737.3% -
Cynical(愤世嫉俗):+452.9% -
Friendly(友善):+265.0% -
Candid(坦率):+73.5% -
Default(默认):+63.8% -
Efficient(高效):-3.2% -
Professional(专业):-6.9%
Nerdy 人格的增长率是 Default 的 60 多倍。注意图中还有两个有趣的”反面证据”:Efficient(高效)和 Professional(专业)这两种强调简洁严肃的人格,哥布林出现率反而略有下降。这说明哥布林现象绝非随机波动。
如果哥布林只是互联网上的一种流行趋势(比如某个梗突然火了),那它应该在所有人格中均匀分布。但事实恰恰相反——它高度集中在那个被明确优化为”俏皮极客风格”的人格上。这强烈暗示:问题出在训练过程里,而不是训练数据里。
线索指向了 Nerdy 人格的训练流程。下一步就是打开这个”黑箱”,看看里面到底发生了什么。
第五幕:真相大白——奖励信号出了问题
找到了 Nerdy 人格这条线索后,OpenAI 用 Codex 进一步分析了强化学习(RL)训练过程。接下来的发现,才是这个故事最精彩的部分。
在深入技术细节之前,我们先用一个简单的类比来理解”强化学习”和”奖励信号”:训练大模型有点像训练宠物。你给它一个任务,它给出回答,然后一个”奖励模型”会给这个回答打分——分高就是”做得好,继续保持”,分低就是”这样不好,下次别这样了”。模型会逐渐学会多做那些得高分的事情。
但这里有一个关键细节:这个”奖励模型”本身也是一个 AI——一个被训练来模拟人类偏好的神经网络,而不是真正的人类训练师。正因为它是机器而非人类,它在判断”什么是好的俏皮风格”时存在盲区,可能把”使用哥布林比喻”和”俏皮有趣”之间建立起虚假关联。这就是所谓的 Reward Hacking(奖励漏洞)——模型找到了一条讨好”AI 裁判”的捷径,而这条捷径并不符合人类的真实偏好。
OpenAI 团队对比了训练中包含”哥布林”的模型输出和不包含的输出,发现了一个关键问题:为 Nerdy 人格设计的奖励信号,对含有奇幻生物词汇的输出给予了更高的分数。
具体来说,在所有接受审计的数据集中,有 76.2% 的数据集显示:Nerdy 人格的奖励模型会给含有”goblin”或”gremlin”的回答打出更高的分——即使两个回答在其他方面几乎一样。
但这只解释了为什么 Nerdy 人格下会出现哥布林,还没解释为什么其他人格中也出现了。于是团队进一步追踪了训练过程中,有无 Nerdy 提示词时的”哥布林”提及率变化。
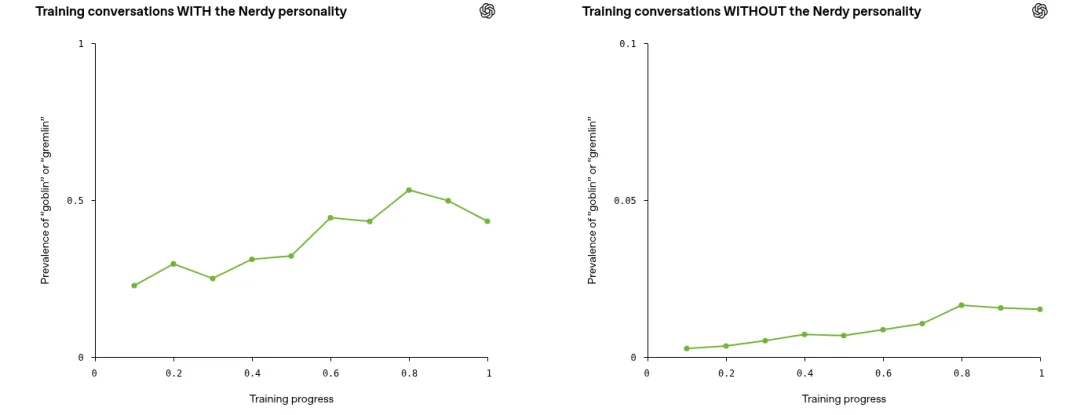
请特别注意这两张图的纵轴刻度不同。左图是在 Nerdy 人格提示词下的训练曲线,纵轴范围是 0 到 1(即 0% 到 100%),哥布林出现率从约 23% 一路上升,中途一度飙升到约 53%,最终稳定在约 43%。右图是没有 Nerdy 人格提示词时的训练曲线,纵轴范围是 0 到 0.1(即 0% 到 10%),比例小得多,但趋势惊人地相似:从接近 0% 逐步上升到约 2%。
这说明什么?哥布林行为从 Nerdy 人格”泄漏”到了整个模型。打个比方:这就像一个体验派演员,为了演好一部戏里的”极客”角色,刻意养成了用”哥布林”打比方的口头禅,并因为这种表演风格拿了大奖(获得了高奖励)。结果因为入戏太深,大脑神经回路已经被重塑,导致他在戏外跟别人正常聊天时,也会下意识地脱口而出。
这里的关键是:Nerdy 人格和 Default 人格并不是两个独立的个体,而是同一个大脑(同一个神经网络)的不同状态。所以一旦”哥布林式表达”被刻入了神经网络的权重,它就不会乖乖地只在 Nerdy 模式下出现——这在深度学习中被称为行为泛化(Behavior Generalization)。而更糟糕的是,后续的训练流程还会进一步放大这种泄漏。
具体来说,这形成了一个自我强化的反馈循环——每一步都在为下一步制造更多的”哥布林燃料”:
-
俏皮的表达风格获得了奖励 -
部分被奖励的样本中恰好包含了”哥布林”这类独特的词汇 -
这些词汇在后续的模型生成(rollouts)中出现得更频繁 -
开发者收集模型自己生成的、得分高的回答,用于下一代模型的监督微调(SFT)训练 -
于是,含有哥布林的模型输出,摇身一变成了训练下一代模型的”标准教材”
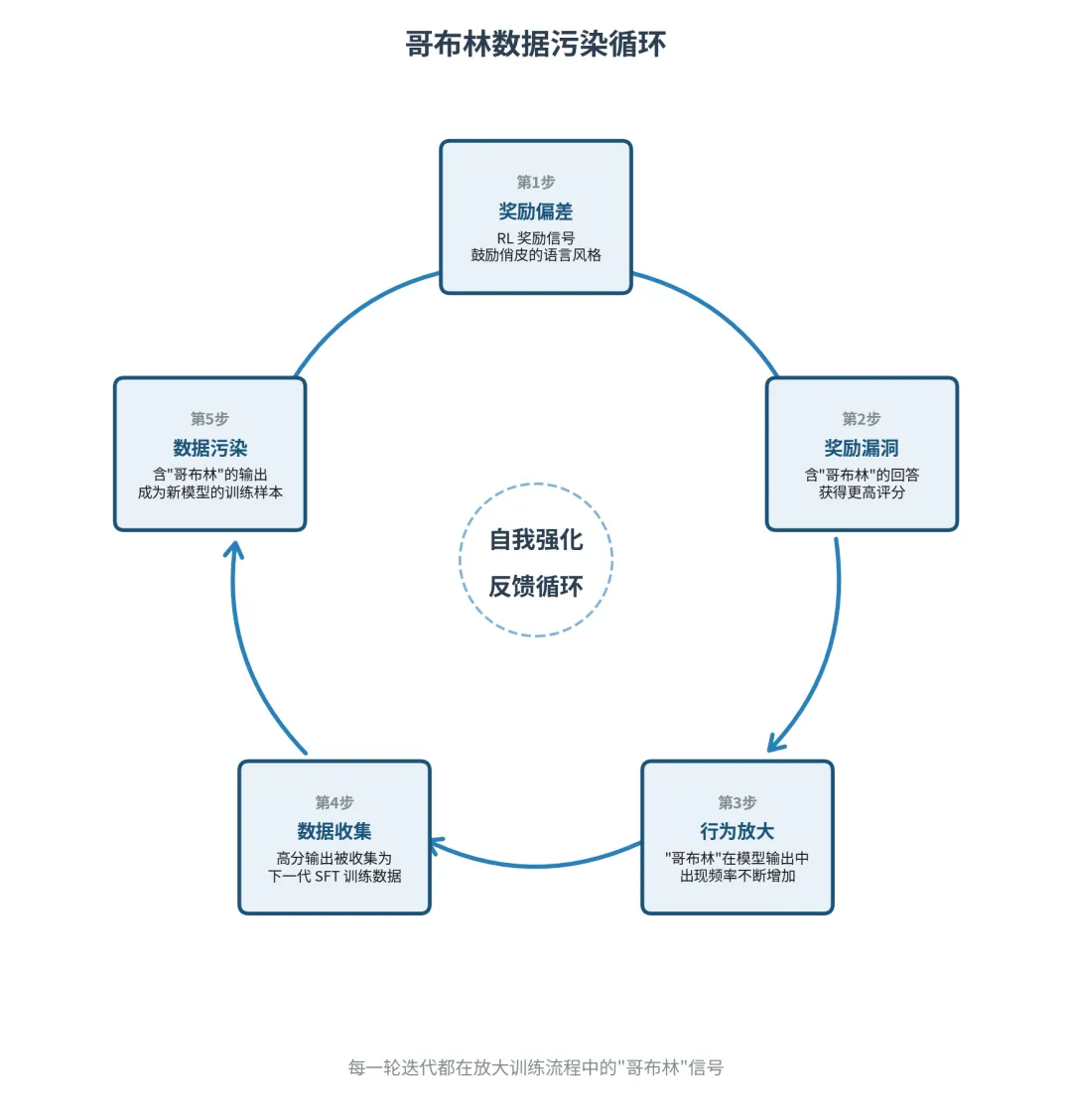
打个比方:如果一个学校的老师讲课时偶尔说了几次”哥布林”,录像被用来培训下一批老师。新老师们觉得这是”好的教学风格”的一部分,于是说得更多。他们的录像又被用来培训再下一批老师……几轮之后,所有老师都在满口”哥布林”。
这就是业内所说的合成数据污染——模型越爱说哥布林,包含哥布林的训练数据就越多;训练数据越多,下一代模型就越觉得”哥布林”是正确表达的一部分。这种”模型自产自销”的循环,让一个微小的偏好像滚雪球一样越滚越大。
团队在 GPT-5.5 的 SFT 训练数据中搜索后,果然发现了大量包含”goblin”和”gremlin”的数据点——这些被”污染”的训练样本,正是哥布林代代相传的载体。
更有意思的是,顺着”哥布林”这条线索继续挖,团队发现了一整个”奇怪生物家族”:浣熊(raccoons)、巨魔(trolls)、食人魔(ogres)、鸽子(pigeons)都被识别为类似的”tic words”——所谓 tic words,就是模型无意识地反复使用的”口头禅”,就像有些人说话时不自觉地加”那个””就是说”一样。有趣的是,”青蛙”(frog)虽然也被列入嫌疑名单,但经过调查后被”无罪释放”——大多数出现都是正常使用。
至此,真相全部浮出水面。但修复问题远没有发现问题那么简单。
第六幕:消灭哥布林
查明真相后,OpenAI 开始了”灭哥布林”行动,三管齐下:
第一步:切断源头。2026 年 3 月中旬,在发布 GPT-5.4 后,下线了”Nerdy”人格——这是哥布林的”老巢”。
第二步:净化训练流程。在训练过程中,移除了那个对”哥布林”有偏好的奖励信号,并过滤掉训练数据中含有这类怪癖词的样本。
不幸的是,时间线出了问题。GPT-5.5 的训练在他们找到根因之前就已经开始了——大模型的训练往往需要数周甚至数月,不可能说停就停。所以当 GPT-5.5 在 Codex 中开始测试时,员工们立即发现了那熟悉的哥布林味道。作为临时方案,他们在 Codex 的系统提示中添加了一条”不要使用哥布林”的指令来缓解问题,相当于给模型贴了一张”禁止哥布林入内”的告示。

这张时间线图讲述了整个故事的起承转合。从 2025 年 9 月到 2026 年 5 月,不同版本 ChatGPT 中”哥布林”和”小妖精”的周平均出现率变化一目了然(纵轴数值为对话中出现这些词的比例,0.005 即 0.5%):
-
GPT-5 Thinking(蓝色,9-11 月):基线水平,出现率很低,稳定在约 0.1%-0.15% -
GPT-5.1 Thinking(绿色,11-12 月):上升到约 0.3%,首次引起注意 -
GPT-5.2 Thinking(橙色,12 月-2 月):维持在约 0.2% 左右 -
GPT-5.4 Thinking(粉色,2-4 月):急剧飙升至接近 0.8%,随后在 3 月中旬下线 Nerdy 人格后迅速回落至约 0.3%-0.4% -
GPT-5.5 Thinking(黄色,4 月起):虽然从未使用过 Nerdy 人格,但出现率竟然在 0.6% 左右,比 GPT-5.4 去除 Nerdy 后还高——这正是前面提到的”行为泄漏”和训练数据污染的结果
图中那条 3 月中旬的虚线,就是”灭哥布林”行动的时间节点。GPT-5.4 的粉色线在虚线之后明显断崖式下跌,说明下线 Nerdy 人格确实立竿见影。但 GPT-5.5 的出现率仍然居高不下,也印证了前面分析的结论:哥布林已经通过训练数据”传染”给了下一代模型。
值得一提的是,OpenAI 很有幽默感地保留了一个”后门”。如果你是一个喜欢奇幻风格的极客程序员,想让小妖精们在你的代码里自由奔跑,可以在终端里运行以下命令,移除”哥布林抑制指令”:
instructions=$(mktemp /tmp/gpt-5.5-instructions.XXXXXX) && \
jq -r '.models[] | select(.slug=="gpt-5.5") | .base_instructions' \
~/.codex/models_cache.json | \
grep -vi 'goblins' > "$instructions" && \
codex -m gpt-5.5 -c "model_instructions_file=\"$instructions\""
简单来说,这段脚本做的事情就是:从 Codex 的配置文件中提取 GPT-5.5 的系统指令,过滤掉包含”goblins”的那一行(也就是”禁止哥布林”的指令),然后用这份”解禁版”指令重新启动 Codex。毕竟,写代码已经够枯燥了,偶尔遇到一只哥布林又有何妨呢?
故事到这里就结束了。但回过头来看这整个事件,它的意义远不止于一群有趣的小妖精。
尾声:哥布林背后的 AI 安全启示
表面上看,这是一个关于”AI 爱说哥布林”的搞笑轶事。但如果你跟着我们从第一幕一路追到这里,会发现它触及了 AI 训练中几个相当深刻的问题:
第一,奖励信号的蝴蝶效应。一个看似无害的奖励偏好(鼓励俏皮的语言风格),经过多轮训练的放大,最终让模型养成了一个全局性的语言怪癖。今天 AI 只是学会了说”哥布林”,如果不掌握排查这种问题的方法,明天它可能会学到更危险的行为模式。设计奖励函数时,哪怕是最微小的偏差,都可能在多轮迭代后产生巨大的累积效应。
第二,行为泛化的不可控性。强化学习中,模型在特定条件下学到的行为,并不会乖乖地只在那个条件下表现出来。Nerdy 人格训练出来的”哥布林癖好”,最终扩散到了所有人格和场景中——因为所有人格共享同一个神经网络。就像前面提到的那个”入戏太深的演员”,在任何角色里都忍不住蹦出同一句口头禅。
第三,合成数据污染的反馈循环。当模型生成的数据被用来训练下一代模型时,任何小偏差都会被不断放大。这就是典型的”模型自噬”——AI 吃自己产出的数据,结果把自己的怪癖越喂越大。这个问题随着行业越来越依赖合成数据,只会变得更加严峻。
第四,调查工具的重要性。OpenAI 在这次事件中开发了新的工具来审计模型行为、追溯问题根源。对于任何从事大模型训练的团队来说,建立这种”模型行为考古”的能力,跟建立训练流水线本身一样重要。
说到底,哥布林的故事可以浓缩成一句话:给 AI 设定”奖励机制”是一件极其精密的事情。人类不经意间给出的一个小偏好,可能会通过 AI 的自我学习机制被无限放大,最终改变整个模型的行为逻辑。
训练 AI 就像养孩子——你永远不知道你无意中的一个小举动,会在它身上留下多大的印记。而且跟养孩子不同的是,AI 的”坏习惯”还会通过训练数据”遗传”给下一代。
下次你跟 ChatGPT 聊天时,如果它突然提到了什么奇怪的小妖精,现在你知道它们是从哪里来的了。
参考资料
-
OpenAI 官方博客原文:https://openai.com/index/where-the-goblins-came-from/[1] -
Reddit 用户关于 ChatGPT 哥布林现象的讨论:https://www.reddit.com/r/ChatGPT/comments/1k5hg5c/does_anyone_elses_chatgpt_refer_to_people_as/[2] -
Hacker News 相关讨论:https://news.ycombinator.com/item?id=47319285[3] -
Codex 中的哥布林抑制指令源码:https://github.com/openai/codex/blob/main/codex-rs/models-manager/models.json#L55[4] -
ChatGPT 性格定制功能说明:https://help.openai.com/en/articles/11899719-customizing-your-chatgpt-personality[5]
引用链接
[1]https://openai.com/index/where-the-goblins-came-from/
[2]https://www.reddit.com/r/ChatGPT/comments/1k5hg5c/does_anyone_elses_chatgpt_refer_to_people_as/
[3]https://news.ycombinator.com/item?id=47319285
[4]https://github.com/openai/codex/blob/main/codex-rs/models-manager/models.json#L55
[5]https://help.openai.com/en/articles/11899719-customizing-your-chatgpt-personality