 夜雨聆风
夜雨聆风





文献精读 | From Word to World:大语言模型能否成为隐式的文本世界模型?
Daily Paper Reading · 世界模型
能预测下一个词的模型,就能模拟一个世界吗?
把”预测下一个词”换成”预测下一个状态”,语言模型能否当智能体的模拟世界 · Text-based World Models
1世界模型 · 智能体学习 · 强化学习
From Word to World: Can Large Language Models be Implicit Text-based World Models?
从词到世界:大语言模型能否成为隐式的文本世界模型?
arXiv 2512.18832SUSTech × Microsoft × Edinburgh 等文本世界模型 · SFT2026 年 3 月
一、文献精读
引言
- 领域基础知识
世界模型(World Model)、智能体强化学习(Agentic RL)、下一状态预测(Next-state Prediction)、ReAct 式智能体(推理+行动交替)、部分可观测马尔可夫决策过程(POMDP)、监督微调(SFT),以及五个文本交互环境(ALFWorld、SciWorld、TextWorld、WebShop、StableToolBench)。 - 研究的主要背景
智能体强化学习越来越依赖”用经验换能力”的扩展范式,但真实交互环境非自适应、覆盖有限、扩展昂贵且交互缓慢,构成了制约进步的”经验瓶颈”。世界模型有望用想象出的模拟经验来缓解这一瓶颈,而经海量”下一个词预测”训练的大模型本身就编码了丰富的世界知识。 - 作者的问题意识
大模型既然能把”词”建模得很好,能否同样把”世界”建模好,从而真正帮助智能体从经验中学习?更进一步——一个世界模型要在什么条件下、可靠到什么程度,才能切实改善下游智能体? - 研究意义
论文把语言建模重新诠释为”固定交互协议下的下一状态预测”,提出涵盖保真与一致性、可扩展与鲁棒性、智能体效用三个层次的评测框架,系统性地刻画了大模型作为文本世界模型的能力边界与适用范围。 -
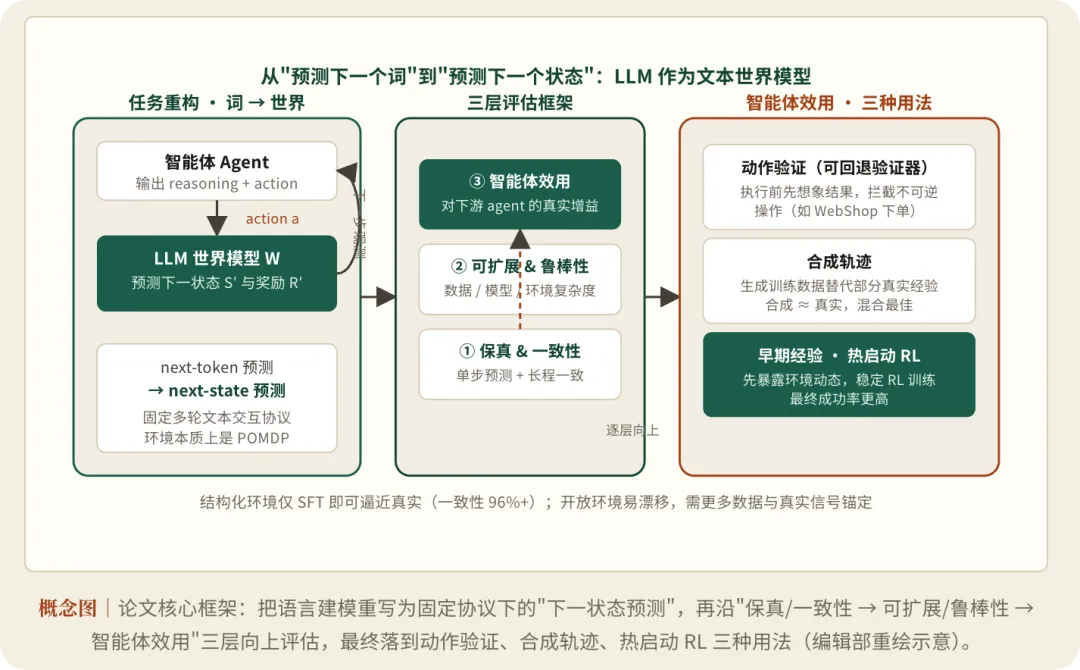
-
内容及结构
- 世界模型的形式化
把”智能体—环境”交互定义为多轮语言决策过程:智能体在 ReAct 风格下输出推理与动作,世界模型 W 则给定历史与当前动作,预测下一状态 S′ 与二值奖励 R′;二者交替展开成一条多轮文本轨迹,真实环境轨迹作为评估参照。环境本质是 POMDP,故世界模型可被注入更完整的初始状态以逼近隐藏动态。 - 五个文本交互环境
结构化环境(ALFWorld 具身家务、SciWorld 实验室、TextWorld 文字探索)状态空间有界、转移规则化;开放环境(WebShop 购物、StableToolBench 工具调用)则组合度高、长尾分布广,对泛化提出更高要求。 - 三层评估框架
保真与一致性(单步预测准确 + 长程展开不漂移)、可扩展与鲁棒性(随数据/模型/环境复杂度的缩放规律与分布偏移下的鲁棒性)、智能体效用(高保真世界模型能否转化为下游可度量的提升)。 - 训练与指标
用 GPT-4o 作行为策略采集 4 万–16 万条轨迹(保留成功与失败以扩大行为覆盖),在 Qwen2.5-7B 与 Llama3.1-8B 上做 SFT;单步用精确匹配(EM)准确率衡量保真,多步用一致性比率 CR=W2R/Real(把世界模型里产生的动作回放到真实环境的成功率之比)衡量长程一致。 - 三类效用实验
动作验证(执行前先在世界模型里”预演”高风险不可逆操作)、合成轨迹(用模拟经验替代部分真实采样)、早期经验(先做世界模型式预训练再热启动策略学习)。
正文
- 背景
智能体能力提升需要越来越大、越多样、越有挑战的环境,而经验只能靠交互采集。真实环境非自适应、难扩展、覆盖有限、交互慢,成了智能体强化学习的根本瓶颈;世界模型让智能体能从”想象的交互”中学习,是缓解瓶颈的关键杠杆。 - 挑战
一个有用的世界模型不能只是”局部读起来通顺”,它必须长程维持连贯状态、对分布偏移鲁棒、且带来可度量的收益。论文指出:仅靠提示(zero/few-shot)在结构化环境尚可,但在开放环境会停滞,无法生成无约束、强上下文依赖的状态更新;既往评测多停留在单步准确率,几乎不考察长程一致性与误差累积。 - 方法
核心是把”下一个词预测”重写为固定协议下的”下一状态预测”,并在真实交互轨迹上做动态对齐的 SFT,使小模型也能内化转移规律。对 ALFWorld/SciWorld 注入完整初始状态、对开放环境则强调基于历史的状态追踪;评估同时看单步 EM 与多步 CR。 - 结果
SFT 后开源模型在 ALFWorld/SciWorld 达 99%/98% EM、StableToolBench 达 49% F1;结构化环境长程一致性高达 96%/91%/92%,而开放的 WebShop 偏低(常低于 80%),但用真实搜索结果锚定后,GPT-4o 智能体的一致性可从 56% 飙升至近 100%。缩放上呈”环境依赖”规律:结构化环境约 20K 数据、1.5B 模型即饱和,开放环境需更多数据与更大容量。ALFWorld 上的 OOD 实验显示世界模型学到的是可迁移的转移动态而非记忆布局;混合多智能体轨迹后,弱智能体的一致性比率从 0.49 升到 0.81。三类效用均见正收益:验证对中等模型增益最大,合成数据接近真实数据,早期经验稳定 RL 并抬高最终成功率。
世界模型(World Model)对环境动态的内部模型,能追踪潜在状态、预测动作结果,让智能体在”想象的交互”中学习,而无需每一步都真实执行。本文把它实现为一个在文本轨迹上做下一状态预测的语言模型。
下一状态预测(Next-state Prediction)把语言建模从”预测下一个 token”重写为”在固定交互协议下,根据历史与当前动作预测下一条环境响应与奖励”,是连接语言建模与世界建模的统一接口。
一致性比率(CR = W2R / Real)把世界模型内部展开得到的动作序列回放到真实环境,其成功率与直接在真实环境运行的成功率之比;越接近 1 说明模拟轨迹越可迁移、长程漂移越小(个别情形可大于 1)。
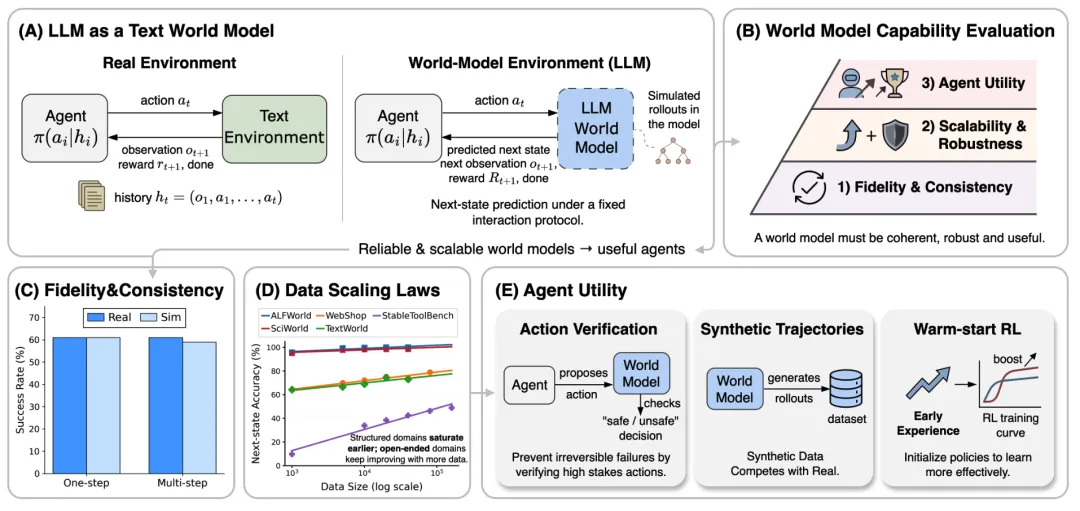
论文总览图:词→世界的任务重构 + 三层能力评估 + 三类智能体效用(原文 Figure 1)
看点:(A) 真实环境与”世界模型环境”对照;(C) 单步与长程展开都保持高保真;(D) 随训练数据可预测地缩放;(E) 验证 / 合成数据 / 热启动 RL 三种用法。
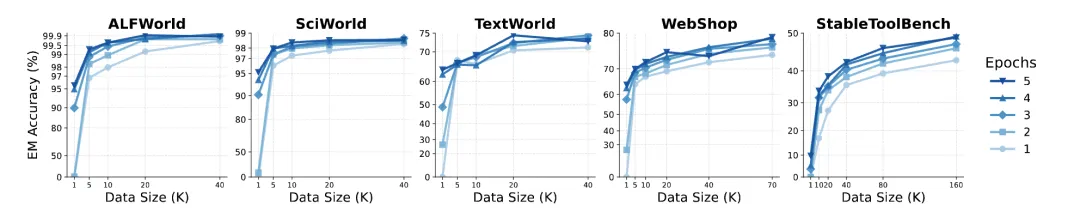
数据缩放规律图:结构化环境约 20K 饱和、开放环境持续受益于更多数据(原文 Figure 2)
看点:ALFWorld/SciWorld/TextWorld 快速饱和,WebShop 约到 70K,StableToolBench 到 16 万样本仍未饱和——直观呈现”环境复杂度决定数据需求”。
结论
- 核心结论
当用动态对齐的监督在足够规模与覆盖下训练时,大模型确实能充当隐式的文本世界模型:长程维持连贯状态,并为下游智能体带来更安全的决策、可扩展的经验生成与更高的学习效率。但这些收益并非普适——稳健性高度依赖行为覆盖、分布对齐与环境复杂度,由此勾画出”世界建模何时真正有用”的清晰边界。 - 领域贡献
把”下一个词预测”与”下一状态预测”打通,提供了把大模型视作可学习的交互世界模拟器的经验基础;给出保真/可扩展/效用三层评测框架,并实证了合成经验可接近真实经验、早期经验能稳定强化学习,为”用模拟经验扩展智能体学习”指明了一条路径。
未来研究方向
- 文献提及方向
把这套”语言模型即世界模型”的思路从纯文本拓展到更丰富的多模态与具身领域,处理更接近现实、状态更复杂、反馈更难界定的交互环境。 - 下一步可开展的研究工作
把”世界模型作为可回退验证器 + 合成轨迹生成”的范式迁移到计算生物学 Agent 流水线。具体而言:针对单细胞转录组分析(如 GBM scRNA-seq 流程),训练一个文本/结构化世界模型,去预测某一步工具调用的结果——例如在真正跑通昂贵流程前,先预测”用某组参数做 QC 过滤 + 聚类是否会得到通过质控、生物学上合理的细胞群”,从而像本文的 WebShop 下单那样,对”删除原始数据””提交批量计算”等不可逆、高成本步骤做执行前预演与拦截;同时用世界模型合成多步分析轨迹来热启动一个编排生物信息学工具的 Agent,并借鉴本文 CR / 行为覆盖的洞见,刻画”哪些分析环境足够规则化、值得用模拟器替代真实运行”,以提升生物计算分析的可信度与可重复性。
二、深度解读
这篇论文真正有价值的地方,恐怕不在方法,而在它把”世界建模到底什么时候才靠谱”这个问题切成了可测量的三层。标题起得很大,落地下来其实主要是一次轨迹上的监督微调——但正是这种”朴素”,让它的结论格外干净:在 ALFWorld、SciWorld 这种规则驱动、状态有界的环境里,仅 SFT 就能把单步准确率推到 99%、把长程一致性拉到 90% 以上;而到了 WebShop、StableToolBench 这种组合度高、长尾分布广的开放环境,同样的配方立刻显出疲态。结构化 vs. 开放的二分,是全文最有信息量的发现:世界建模在”动态可被规则化”的地方便宜得惊人,在”动态高熵、强上下文依赖”的地方则昂贵且脆弱。
不过最该被追问的,是它的评测闭环:自定义的评估指标、自训练的 7B 模拟器、自提出的 benchmark——很容易陷入”自己定义缺陷、自己设计指标、再宣布在自己指标上提升”的循环。这里唯一把论断”钉”在真实环境上的,是 CR(W2R→真实环境的可迁移成功率);正是这一条让”模拟轨迹可执行”的主张有了着力点。但另一面也很关键:实验里所有评估环境在训练时都被见过,世界模型本质上是为这几个环境各训了一个模拟器。这就把一个尖锐的问题推到台前——如果环境已经见过,为什么不直接用真实环境?一个仅靠 SFT 的 7B 模型,是否真有能力泛化到从未见过的全新环境,仍是这条路线悬而未决的核心。
三、讨论环节
这是”世界模型”,还是套了大标题的轨迹 SFT?
讨论中有观点直言:从实现上看,这套方法本质就是在 GPT-4o 采的轨迹上做了一次 SFT,再把训出来的小模型当作一个”虚假的交互环境”来用——它确实完成了”预测下一状态”,但是否配得上”世界模型”这个分量很重的名号,现场存有保留。也有同学把它与业界更宏大的世界模型构想相对照,认为本文的内涵更朴素,大体只是把”预测下一个词”换成了”预测下一个状态”。
自定义指标 + 自训练插件 + 自家 benchmark 的闭环之忧
有观点把全文流程拆解为:先指出现有语言模型有某种缺陷、却没有现成手段去测;于是自己引入一套评估指标,又自己训练一个 7B 的”插件”式模型,再把它绑到 GPT 这类语言模型上,看绑了插件后能否在自家提出的 benchmark 上提升。现场追问:指标和插件都是自己造的,这个过程和”世界模型”本身究竟有多大关系、提升又有多少说服力?
自己定义缺陷,自己设计指标,自己造一个插件——再宣布”在我们自己的指标上提升了”。
泛化性:环境都见过,为何不直接用真实环境?
讨论中有人关注泛化能力:表里的几个环境在训练时是否都被见过?答案是基本都见过——世界模型相当于为每个环境各训了一个模拟器。由此引出一个直接质疑:如果模拟器已经”见过”这个环境,那它的价值本应体现在泛化到没见过的新环境上;否则既然环境已知,为什么不直接用真实环境本身?现场也基本认同,一个仅做 SFT 的 7B 模型,很难真正具备那种强泛化能力,模拟效果最终还要看任务之间的相似度。
✦今日文献分享完
Daily Paper Reading
关于发布方
🌟 星弧 Starc Institute
一个为天赋与梦想而生的非营利组织。科研不该被资源垄断,真正的探索精神应当跨越出身与背景的界限。在这里,教授不再是遥不可及的权威,而是愿意亲自拉弓、助你射向知识星辰的引路人;学生不再是被动等待机会的履历堆砌者,而是被点燃、被赋能的未来之星。
👉 关注公众号「星弧 Starc」,获取更多 AI 前沿讲座与学术资源
欢迎扫描下方二维码加入微信群,与更多志同道合的朋友一起交流学习,并第一时间获取最新讲座信息与各种AI相关资料。

或者关注公众号之后后台回复“加群”。