 夜雨聆风
夜雨聆风





一个 Prompt 跑11 小时, AI 交出了完整英语学习 App:10000 行代码,零人工
一个深夜,有人在终端敲下一条指令:「帮我做一个英语单词学习 App。」
然后关掉屏幕,去睡觉了。
11 个小时之后,一个功能完备的英语学习应用摆在面前——单词本、消消乐游戏、每日背诵、限时挑战、个性化目标设置,全都有。代码超过10,000 行,中间触发了1,000 多次Agent 调用,全程没有任何人工介入。
做到这件事的,是阿里千问刚发布的 Qwen3.7-Plus 和它驱动的 Hybrid-Agent 系统。
▲ 千问大模型知乎官方页面,展示 Qwen3.7-Plus 的核心定位:「想得深,看得懂,做得到」
这个 App 做到了什么程度?
先说结论:这不是那种跑个 hello world 就截图发推的 demo。
从官方公布的功能清单来看,这个英语单词学习 App 覆盖了主流语言学习应用的核心模块——
- 单词本管理
:添加、分类、标记掌握程度 - 单词消消乐
:趣味匹配消除游戏,把背单词变成闯关 - 每日背诵
:固定量级的每日任务 - 限时挑战
:计时模式,逼出瞬时记忆 - 目标与提醒
:可设定每日记忆目标、推送提醒
放到应用商店里,这就是一个能用的产品原型。功能深度不输早期版本的百词斩或扇贝。
关键在于:从第一行代码到最后一个测试用例,整个过程没有人碰过键盘。
Agent 在这 11 小时里干了什么?
很多人一听「AI 写代码」,脑子里浮现的场景是 Copilot 补全几行函数。但这次完全不同。
Qwen3.7-Plus 驱动的 Hybrid-Agent 跑通了完整的软件工程流水线——从需求分析到版本迭代,每一步它都自己接管。11 个小时里,Agent 自主完成了六个阶段的工作:
第一阶段:需求分析。Agent 根据一条简短的自然语言指令,自己拆解出功能模块、交互逻辑、技术选型,生成了结构化的需求文档。
第二阶段:代码编写。前端界面、后端逻辑、数据模型、游戏机制——Agent 按模块逐一实现,累计产出超过一万行代码。
第三阶段:环境搭建。自动安装依赖、配置运行环境、处理兼容性问题。遇到报错就自己查日志、改配置、重新来。
第四阶段:测试验证。这一步最能说明问题。Agent 不光写了单元测试,还做了GUI 自动化测试——模拟用户点击按钮、输入单词、验证界面状态。多个学习路径、不同难度级别、提醒触发逻辑,都覆盖到了。
第五阶段:文档同步。产品说明、README、使用指南,Agent 根据实际实现自动更新。
第六阶段:版本迭代。根据测试中发现的问题,Agent 自己回去改代码、重新测试、确认修复,走了不止一轮迭代。
整个过程的核心特征:自主决策。Agent 不是按照预设脚本一步步执行的流水线。当某个模块编译失败,它会读错误日志、定位问题、尝试修复方案;当测试用例没通过,它会回到源码做调整。这种”遇到问题 → 诊断 → 修复 → 验证”的闭环,在 11 小时里循环了上千次。
Qwen3.7-Plus 凭什么撑住 11 小时?
能让 Agent 连续稳定运行这么久,背后需要模型同时具备几种能力,而且每一种都不能太弱。
Qwen3.7-Plus 的定位是多模态交互混合智能体(Multimodal Interactive Hybrid Agent),和纯文本旗舰 Qwen3.7-Max 形成互补。Max 主打超长上下文和深度推理,Plus 则专门为视觉 + 代码 + 执行的混合场景设计。
具体来说,这个”混合”体现在三个层面:
看得懂屏幕。ScreenSpot Pro 拿到 79.0 分,这个指标衡量的是模型对 GUI 界面元素的精确定位能力——你指着屏幕上一个按钮说”点这个”,模型能不能准确找到坐标。79 分意味着它在 GUI grounding 上已经达到前沿水平。这直接决定了 Agent 做 GUI 自动化测试时的可靠性。
写得出代码。Terminal-Bench 得分 70.3,接近纯文本旗舰 Max 的水平。在终端环境里执行复杂编码任务,Plus 没有因为加了视觉能力而牺牲代码生成质量。
在视觉理解的竞技场上也站得住。Vision Arena 排名全球前五、中国模型第一。BabyVision、MathVision 等多模态推理基准同样有显著提升。

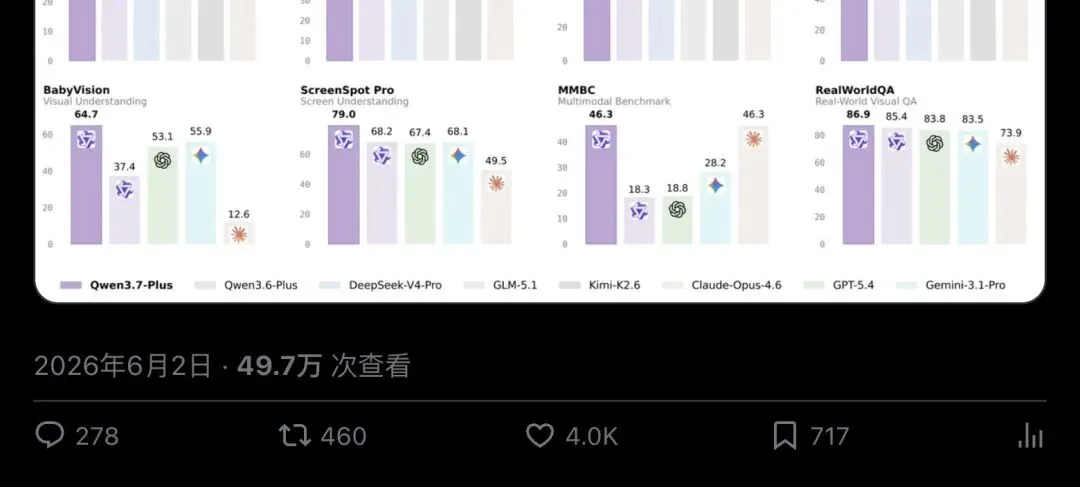
▲ Qwen 团队 X 官方发布帖,单条浏览量近 50 万,介绍 Qwen3.7-Plus 的多模态混合 Agent 能力
这三层能力叠在一起,才有了 Hybrid-Agent 的运行基础:Agent 截取屏幕 → 理解当前界面状态 → 决定下一步操作 → 生成代码或执行命令 → 再截屏验证结果。一个模型完成整个循环,不需要在视觉模型和语言模型之间做路由切换。
对开发者来说,这意味着架构复杂度大幅降低——你不需要拼接一个视觉理解模块加一个代码生成模块再加一个执行调度模块,一个 Qwen3.7-Plus 就够了。
▲ BuildFastWithAI 独立技术评测:「Alibaba’s GUI Agent Hits ScreenSpot Pro 79.0」,确认混合架构的实战优势
不止背单词:macOS Stocks 应用也被复刻了
为了证明 Hybrid-Agent 的能力不限于某个特定场景,千问团队还展示了另一个案例:高保真复刻 macOS 原生 Stocks 应用。
Agent 的工作流程更有意思——它先自主打开 macOS 原生的 Stocks 应用,通过截屏理解 UI 布局和交互逻辑,然后用SwiftUI从零编写了一个克隆版本,并接入了LongBridge真实行情 API。
最终验证:10 项核心功能——实时行情显示、股票切换、多周期 K 线、搜索、详情面板等——全部通过测试。
这个案例的说服力在于:它涉及原生桌面开发(SwiftUI)、真实第三方 API 对接、复杂 UI 还原,以及严格的功能验证。和英语 App 案例放在一起,说明 Hybrid-Agent 的泛化能力已经跨越了「Web 应用」和「桌面原生应用」两个领域。
想自己试试?Qoder 和 Qwen Code 已经就位
看到这里,开发者最关心的问题大概是:我能不能自己搭一个类似的 Agent?
答案是可以,而且路径已经很清晰。
Qoder是阿里推出的 Agentic Coding 平台,定位是「为真实软件而生的智能体编程平台」。它有两个核心模式:
- Editor 模式
:类似增强版 IDE,Agent 跟你并肩写代码 - Quest 模式
:把任务完整委托给 Agent,让它自主探索意图、并行执行、持续迭代
Quest 模式就是 11 小时案例的「产品化版本」——你描述需求,Agent 接管整个开发流程。目前 Qoder 已经支持 Qwen3.7 系列模型,Qwen3.7-Max 还有每日免费调用额度。平台同时提供 CLI 和 JetBrains 插件,跟现有工作流无缝衔接。
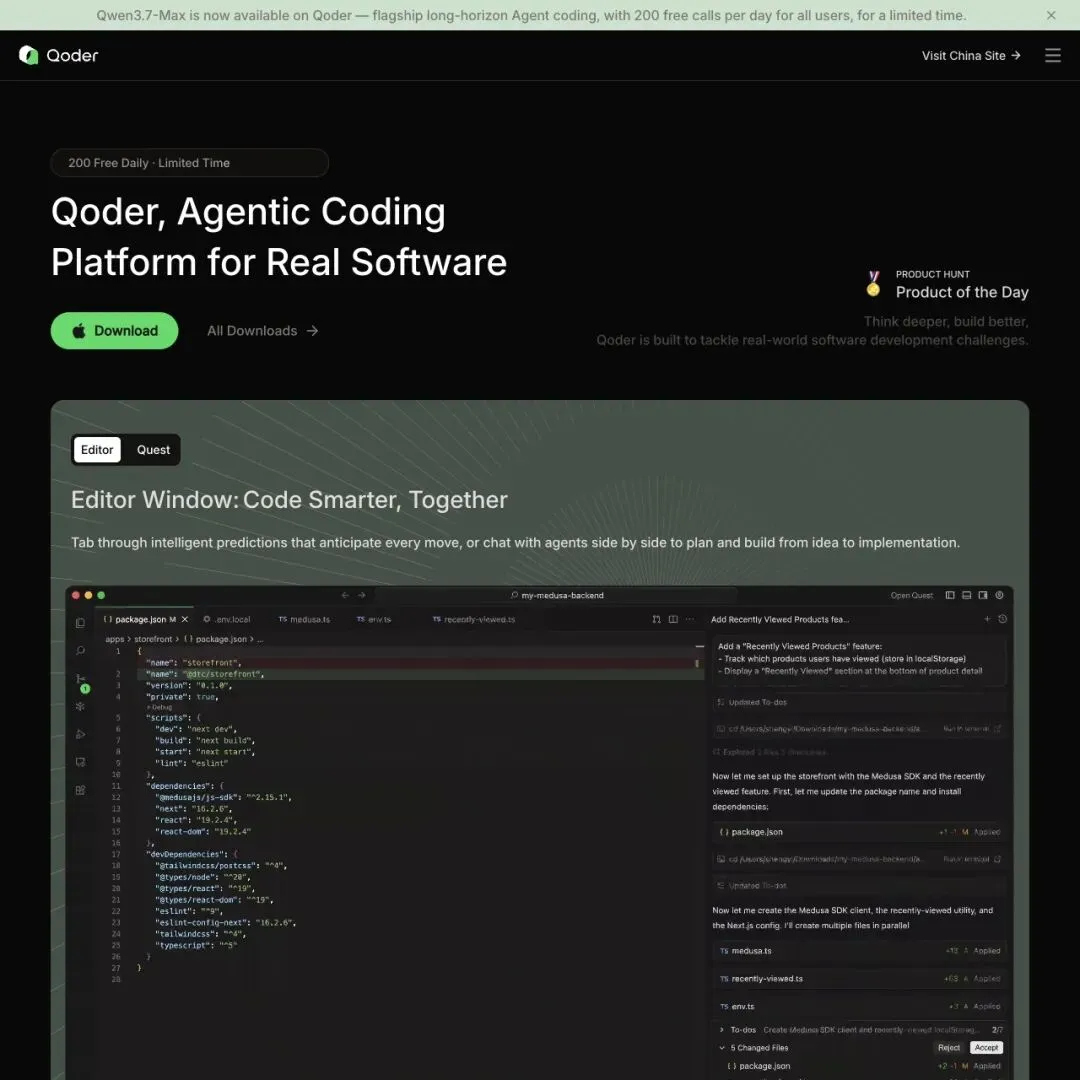
▲ Qoder 官网:Agentic Coding Platform for Real Software,Quest 模式支持长时程自主开发任务
如果更偏好开源和本地化方案,Qwen Code是一个专为 Qwen 模型优化的开源终端 Agent,支持 Auto-Memory、SubAgents、MCP 协议等特性,GitHub 上社区活跃度不错。
此外,Qwen3.7-Plus 已经通过阿里云百炼 / Model Studio API 开放调用,兼容 OpenAI 和 Anthropic 协议。这意味着你可以在 Claude Code、OpenClaw 等第三方框架里直接接入 Qwen3.7-Plus 作为底层模型——不绑定特定平台。
从”帮你补全代码”到”替你交付项目”
回看这个英语学习 App 的案例,最值得关注的变化藏在粒度里。
过去两年,AI 编程助手的主要能力停留在函数级别——补全一段代码、解释一个报错、重构一个方法。开发者仍然是整个工程的驾驶员,AI 是副驾驶。
Qwen3.7-Plus 的 Hybrid-Agent 演示把粒度推到了项目级别。一个完整的 App,从需求到交付,中间所有的技术决策、错误处理、质量验证,都由 Agent 自主完成。开发者的角色从「写代码的人」变成了「提需求的人」。
当然,要说这马上就能替代专业开发团队还为时过早——这毕竟是受控环境下的演示,完整的运行日志和源码还没有公开。但 11 小时、10,000 行代码、1,000 多次调用、完整的测试覆盖——这些数字指向的方向已经足够清晰。
AI Agent 正在从「辅助工具」向「独立执行者」的方向演进。而 Qwen3.7-Plus 证明了,至少在受控场景下,这条路已经走通了。