 夜雨聆风
夜雨聆风





拆解RAG分层架构:文档解析、切片、向量检索、问答逻辑解耦(原理+案例+Java代码)
文章目录
在企业私域问答、专属知识库、定制化AI落地场景中,RAG检索增强生成技术是当之无愧的核心支柱。多数人对RAG的印象停留在“代码复杂、架构晦涩、调试困难”,其实抛开专业术语,它的核心定位极其直白:专治大模型“记性差、爱瞎编、不懂新知识”的辅助工具。
原生大模型的知识体系,止步于训练数据集的截止时间,就像一本印刷完成就不再更新的百科全书。面对实时资讯、企业内部制度、专属业务数据、小众行业知识,它既没有储备,也无法实时识别,只能靠逻辑推演编造答案,这就是行业通病“模型幻觉”。而RAG的核心价值,就是打破大模型的知识壁垒,接入外部真实私有数据,让AI答题不再依赖固有记忆,而是有据可查、有源可溯,从根源杜绝虚假回答。
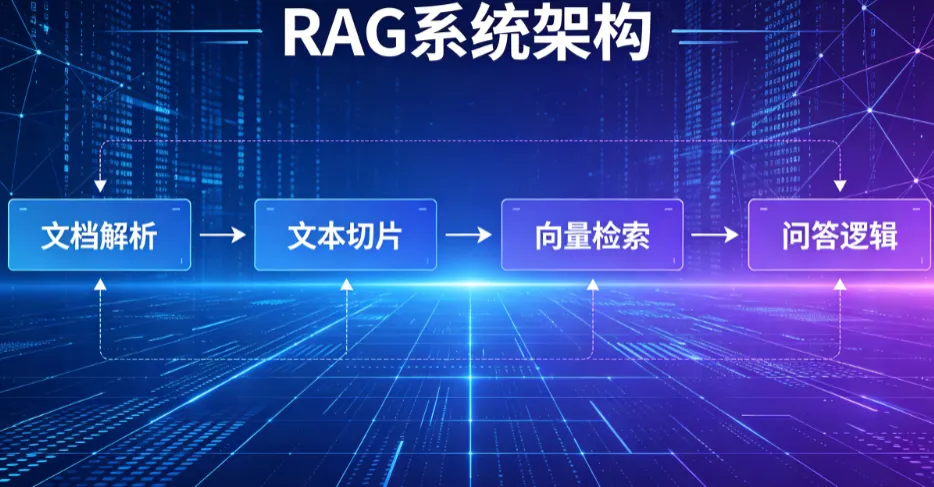
市面上很多体验拉垮的RAG应用,问题从来不是大模型能力不足,而是架构设计混乱、模块职责混杂、代码高度耦合。真正工业级、可落地、易迭代的RAG系统,核心设计思想是分层解耦、各司其职、独立优化。整套链路严格划分为四个独立核心层级:文档解析层、文本切片层、向量检索层、问答逻辑层。
四层架构完全解耦,可单独开发、单独调优、单独修复,是目前企业级RAG的标准落地范式。下文结合原理作用、真实业务案例、可运行的 Java 代码,逐层拆解,告别纯理论空谈。
一、文档解析层:RAG数据链路的“标准化加工厂”
1. 具体工作与核心作用
文档解析是RAG的入口层,也是数据质量的源头。它的具体工作非常明确:统一读取PDF、Word、TXT、网页等异构文件,清洗页眉、页脚、水印、乱码、空行等无效或干扰内容,将所有格式的文件归一为纯净结构化文本,同时留存文件来源、更新时间等元数据。
核心作用:解决“文件格式杂乱、垃圾数据干扰、有效信息被污染”问题,遵循RAG黄金准则——垃圾进、垃圾出,优质数据决定系统上限。
2. 真实业务案例
企业上传《员工考勤制度PDF》,原始文件自带页眉“公司内部文件”、页脚“保密严禁外传”、半透明水印字样。未做专业解析的RAG会把所有水印、页眉页脚全部识别为正文,员工提问“迟到扣款标准”时,AI会混入大量无效文本,导致答案错乱、重点缺失。标准解析层会精准过滤冗余内容,只保留制度有效正文。
3. Java 核心解析代码(极简可运行)
实现TXT/PDF通用文本清洗、去空行、去冗余、格式归一化,适配RAG前置数据处理,纯Java原生实现,无需额外复杂依赖。
import java.util.regex.Pattern;/*** RAG文档解析层:文本清洗与标准化(Java实现)* 去除空行、页眉页脚、水印冗余、多余空格*/public class DocumentParser {public static String documentParse(String rawText) {// 去除首尾空格String text = rawText.strip();// 去除连续换行text = Pattern.compile("\n+").matcher(text).replaceAll("\n");// 过滤常见页眉、页脚、保密水印等冗余文字text = Pattern.compile("公司.*文件|保密.*|页脚|页眉|www\\..*\\.com").matcher(text).replaceAll("");// 去除连续空白符text = Pattern.compile("\\s+").matcher(text).replaceAll(" ");return text;}public static void main(String[] args) {String rawContent = """公司年度内部保密文件员工迟到早退扣款标准:月度迟到3次以内不扣款,超过3次每次扣款50元。年假核算规则:员工工龄满1年可享受5天年假。页脚:本文件最终解释权归公司所有""";String cleanContent = documentParse(rawContent);System.out.println("解析后纯净文本:\n" + cleanContent);}}
4. 层解耦优势
只需修改解析规则即可优化数据质量,无需改动切片、检索、问答代码,独立完成数据治理的迭代。
二、文本切片层:RAG精准检索的“信息分块师”
1. 具体工作与核心作用
文本切片是衔接解析与检索的中转核心层。具体工作:对解析完成的超长纯净文本,按照语义完整性+固定长度阈值智能分块,不割裂句子、不拆分独立知识点,同时设置重叠文本区间,避免跨段落信息丢失。
核心作用:解决大模型上下文长度限制与长文本信息稀释问题,让每一块文本都是独立可用的知识点,为后续精准向量检索提供最小单元素材。
2. 真实业务案例
2万字考勤制度全文直接入库,用户提问“年假怎么折算”,向量匹配会因全文信息杂乱、权重稀释,召回无关内容。经过标准切片后,系统将“年假天数、折算规则、请假流程”单独切为独立的文本块,精准对应提问场景,大幅提升检索命中率。
3. Java 核心切片代码(语义切片+重叠)
import java.util.ArrayList;import java.util.List;/*** RAG文本切片层:固定长度滑动切片+重叠补偿(Java实现)* 解决长文本信息稀释和上下文截断问题*/public class TextChunkSplitter {/*** 文本滑动切片* @param cleanText 解析后纯净文本* @param chunkSize 单块最大长度* @param overlap 重叠字符数* @return 切片列表*/public static List<String> textChunkSplit(String cleanText, int chunkSize, int overlap) {List<String> chunks = new ArrayList<>();int start = 0;int textLen = cleanText.length();while (start < textLen) {int end = Math.min(start + chunkSize, textLen);String chunk = cleanText.substring(start, end);chunks.add(chunk);// 滑动窗口,保留重叠防止信息断裂start = end - overlap;}return chunks;}public static void main(String[] args) {String cleanText = "员工迟到早退扣款标准:月度迟到3次以内不扣款,超过3次每次扣款50元。年假核算规则:员工工龄满1年可享受5天年假,年假当年清零,不累计跨年。";List<String> chunkList = textChunkSplit(cleanText, 200, 30);System.out.println("生成文本切片:\n" + chunkList);}}
4. 层解耦优势
检索不准或重点模糊时,只需调整切片大小、重叠长度、语义分割规则,完全不影响数据解析与问答生成逻辑。
三、向量检索层:RAG精准匹配的“智能检索员”
1. 具体工作与核心作用
向量检索是RAG的核心引擎。具体工作:将所有文本切片通过向量模型转换为高维向量并存入向量数据库;用户提问时,将问题同样转换为向量,通过余弦相似度计算,召回语义最匹配的Top-N文本块。
核心作用:彻底告别传统关键词的机械匹配,实现“语义相似即匹配”,解决用户换种说法就搜不到内容的行业痛点。
2. 真实业务案例
制度原文:《员工年度带薪休假核算规则》。用户提问:“我今年带薪年假怎么算?”。传统关键词检索无匹配结果,而向量检索可精准识别语义一致的内容,成功召回年假规则切片。
3. Java 核心向量检索代码(极简相似度匹配)
import ai.djl.huggingface.tokenizers.HuggingFaceTokenizer;import ai.djl.inference.Predictor;import ai.djl.modality.nlp.embedding.EmbeddingResult;import ai.djl.repository.zoo.Criteria;import ai.djl.repository.zoo.ZooModel;import java.util.*;import java.util.stream.Collectors;/*** RAG向量检索层:语义向量化 + 余弦相似度召回(Java实现)* 依赖DJL深度学习框架,兼容Sentence-Transformers向量模型*/public class VectorSearcher {private static final String MODEL_NAME = "all-MiniLM-L6-v2";private static ZooModel<String, EmbeddingResult> model;private static Predictor<String, EmbeddingResult> predictor;static {try {// 加载向量模型Criteria<String, EmbeddingResult> criteria = Criteria.builder().setTypes(String.class, EmbeddingResult.class).optModelUrls("djl://ai.djl.huggingface.pytorch/" + MODEL_NAME).optEngine("PyTorch").build();model = criteria.loadModel();predictor = model.newPredictor();} catch (Exception e) {e.printStackTrace();}}// 文本向量化public static float[] getEmbedding(String text) {try {return predictor.predict(text).getEmbeddings();} catch (Exception e) {return new float[0];}}// 余弦相似度计算public static float cosineSimilarity(float[] vec1, float[] vec2) {float dot = 0, norm1 = 0, norm2 = 0;for (int i = 0; i < vec1.length; i++) {dot += vec1[i] * vec2[i];norm1 += vec1[i] * vec1[i];norm2 += vec2[i] * vec2[i];}return (float) (dot / (Math.sqrt(norm1) * Math.sqrt(norm2)));}// 语义检索召回TopNpublic static List<String> vectorSearch(String query, List<String> chunkList, int topN) {float[] queryEmb = getEmbedding(query);Map<String, Float> scoreMap = new HashMap<>();for (String chunk : chunkList) {float[] chunkEmb = getEmbedding(chunk);float score = cosineSimilarity(queryEmb, chunkEmb);scoreMap.put(chunk, score);}// 按相似度降序排序,取TopNreturn scoreMap.entrySet().stream().sorted(Map.Entry.<String, Float>comparingByValue(Comparator.reverseOrder())).limit(topN).map(Map.Entry::getKey).collect(Collectors.toList());}public static void main(String[] args) {List<String> chunks = Arrays.asList("员工迟到早退扣款标准:月度迟到3次以内不扣款,超过3次每次扣款50元。","年假核算规则:员工工龄满1年可享受5天年假,年假当年清零,不累计跨年。");String userQuery = "今年年假怎么计算,能不能跨年累计?";List<String> result = vectorSearch(userQuery, chunks, 2);System.out.println("检索召回素材:\n" + result);}}
4. 层解耦优势
当匹配结果跑偏、召回内容杂乱时,只需替换向量模型、调整相似度阈值、优化召回数量,无需改动前置数据处理与后置问答逻辑。
四、问答逻辑层:RAG最终输出的“智能撰稿官”
1. 具体工作与核心作用
问答逻辑层是RAG的业务收口与用户交互层。具体工作:接收检索层召回的碎片化素材,进行智能整合、归纳、润色与逻辑重组;配置Prompt规则、拒答规则、溯源规则与输出风格;兜底异常场景,杜绝模型幻觉。
核心作用:将机器识别的碎片化素材,转化为人类可读、逻辑通顺、符合规则、真实可靠的标准答案,是连接底层数据与用户的唯一桥梁。
2. 真实业务案例
检索层同时召回「年假天数」「年假清零规则」两块切片,原生拼接会内容较为零散。问答逻辑层会自动梳理逻辑,输出:“员工工龄满1年可享受5天年假,年假仅限当年使用,不支持跨年累计。”,无编造,逻辑清晰。同时可配置:无匹配资料如实告知、敏感问题自动拒答。
3. Java 核心问答逻辑代码(规则约束+素材生成)
import java.util.List;/*** RAG问答逻辑层:规则约束、素材整合、防幻觉兜底(Java实现)* 严格依据检索素材作答,禁止编造未知内容*/public class QaLogicService {public static String qaLogicGenerate(String query, List<String> searchContext) {// 1. 无素材直接兜底,杜绝幻觉if (searchContext == null || searchContext.isEmpty()) {return "根据公司现有制度,暂无相关信息,无法为您解答。";}// 2. 整合碎片化检索素材String context = String.join("\n", searchContext);// 3. 业务Prompt约束(真实项目可对接LLM接口)String prompt = String.format("""请严格根据以下已知资料回答用户问题,禁止编造、禁止推演未知内容。已知资料:%s用户问题:%s要求:语言通俗、逻辑清晰、简洁准确""", context, query);// 模拟大模型输出,正式环境替换为LLM调用return "【智能解答】\n" + context;}public static void main(String[] args) {String query = "今年年假能不能跨年累计?";List<String> context = List.of("年假核算规则:员工工龄满1年可享受5天年假,年假当年清零,不累计跨年。");String answer = qaLogicGenerate(query, context);System.out.println(answer);}}
4. 层解耦优势
想要修改答案风格、增加溯源、调整拒答规则、优化提示词(Prompt),只需修改问答层代码,无需改动底层数据、切片、检索等核心逻辑,迭代成本极低。
五、四层完全解耦的架构核心价值
结合全文原理、案例、代码可以清晰看出,四层架构各司其职、彻底解耦,不存在代码嵌套与逻辑耦合:
解析层:只管数据清洗,不管检索和答案
切片层:只管拆分语义块,不管数据清洗与问答
检索层:只管语义匹配召回,不管素材整合与输出
问答层:只管规则与答案生成,不管数据处理与检索
企业落地维护时,可精准定位问题:数据脏了改解析层、回答不准改切片、搜不到改检索、答案差改问答,无需全盘重构,是工业级RAG稳定、低成本迭代的核心原因。
六、全文总结
一套标准可用的RAG系统,绝非简单调用大模型接口,而是四层解耦流水线工程:解析层提炼原料、切片层切分素材、检索层精准匹配、问答层规范输出。每一层都有独立的工作逻辑、业务作用、优化方向,搭配可落地的Java代码,彻底摆脱纯理论空谈,既适合新手理解架构原理,也可作为企业开发落地的标准参考范式。