 夜雨聆风
夜雨聆风





一次把复杂文档读懂:MOCR 实测体验与多模型对比
一次把复杂文档读懂:MOCR 实测体验与多模型对比
最近我们针对多款 OCR / 多模态文档解析模型 做了一轮系统测试,重点看它们在真实复杂场景里的表现差异。
这次对比的模型包括:
-
PaddleOCR-VL-1.5 -
MonkeyOCR-Pro-3B -
HunyuanOCR -
MOCR
测试覆盖了几个真正有区分度的场景:超长表格、小语种识别、长网页解析,以及复杂版面理解。
先说最终判断:
如果只是做简单文字识别,很多模型都能用;但如果进入复杂文档解析场景,MOCR 的优势会变得非常明显。
01 超大表格:难点从来不是“识字”,而是“读完整”
在真实业务里,最棘手的通常不是把文字识别出来,而是把一张又长、又密、字又小的表格完整还原出来。
这类任务真正考验的是三件事:
-
小字体识别能力 -
长上下文保持能力 -
表格结构理解能力
测试原图
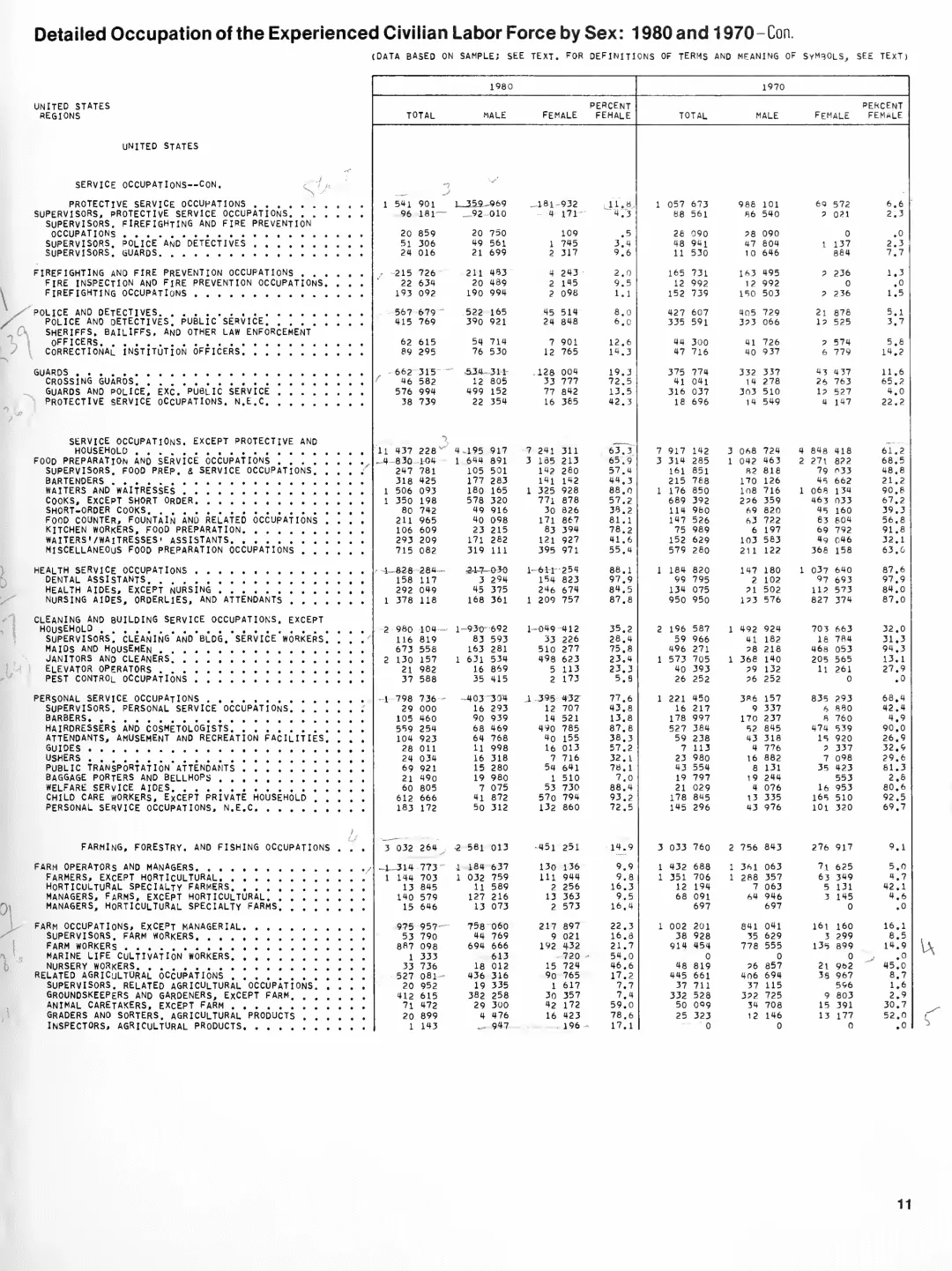
图 1|超长复杂表格测试样本。内容密度高、字号小,对识别精度和结构恢复都提出了很高要求。
模型对比
PaddleOCR-VL-1.5
小字体识别能力明显不足,出现大量漏识别。面对高密度长表格时,细节保留不够稳定。
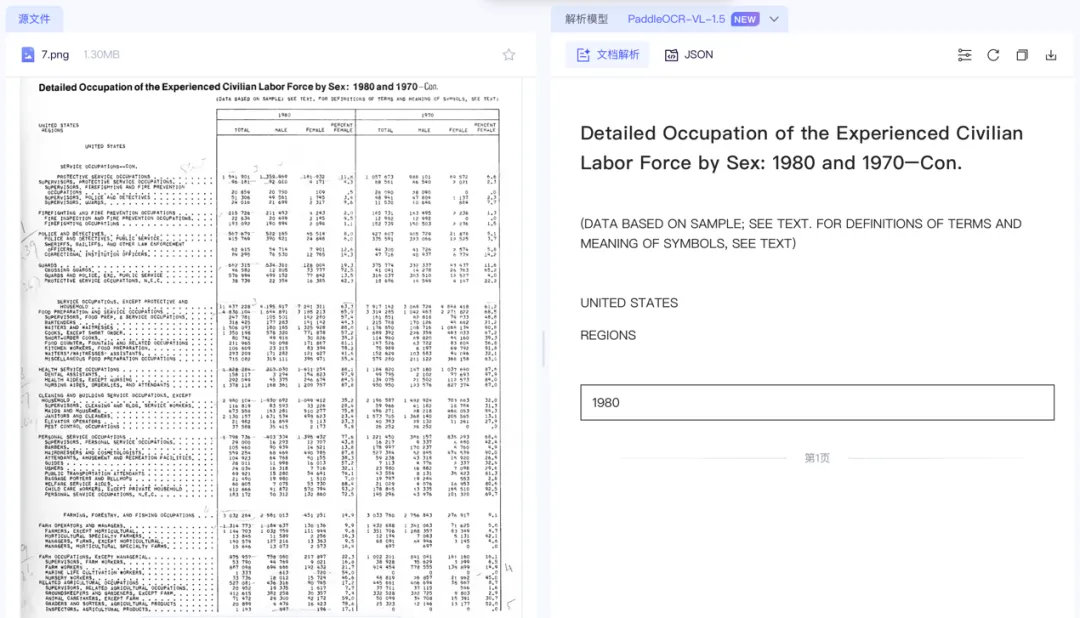
图 2|PaddleOCR-VL-1.5 输出结果,没有检测识别到表格,细小文本区域存在较明显遗漏。
MonkeyOCR
无法稳定处理超长表格,输出结果出现截断,说明其长上下文结构保持能力还有明显短板。

图 3|MonkeyOCR 输出结果,表格没有被完整读完,后半段信息丢失。
HunyuanOCR
没有识别出整体表格结构,部分区域被误判成普通文本,结构化效果不够稳定。
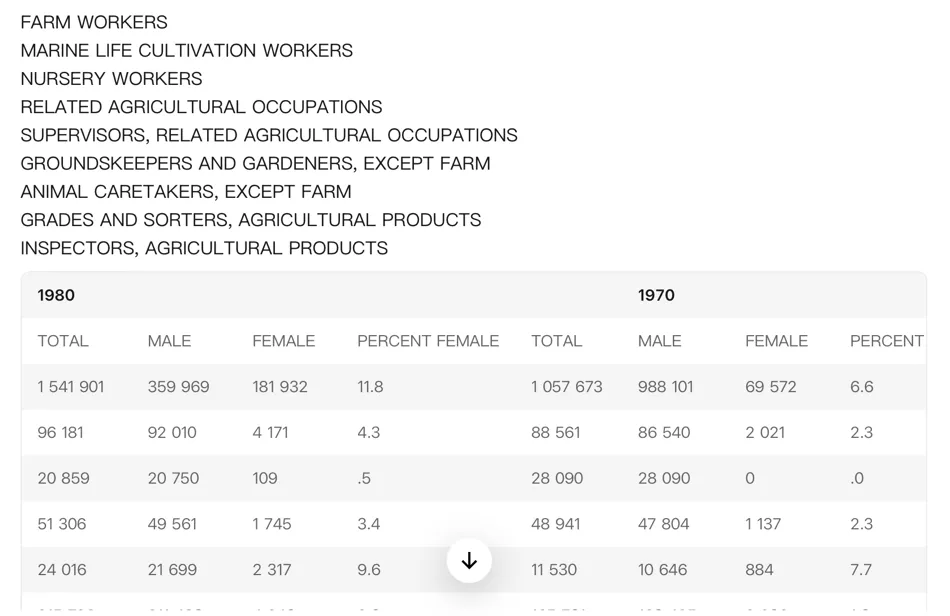
图 4|HunyuanOCR 输出结果,能读到部分内容,但整体结构理解不完整。
MOCR
表格结构完整保留,小字体也能较精准识别,整体内容基本无缺失,是真正意义上的“读完整”。
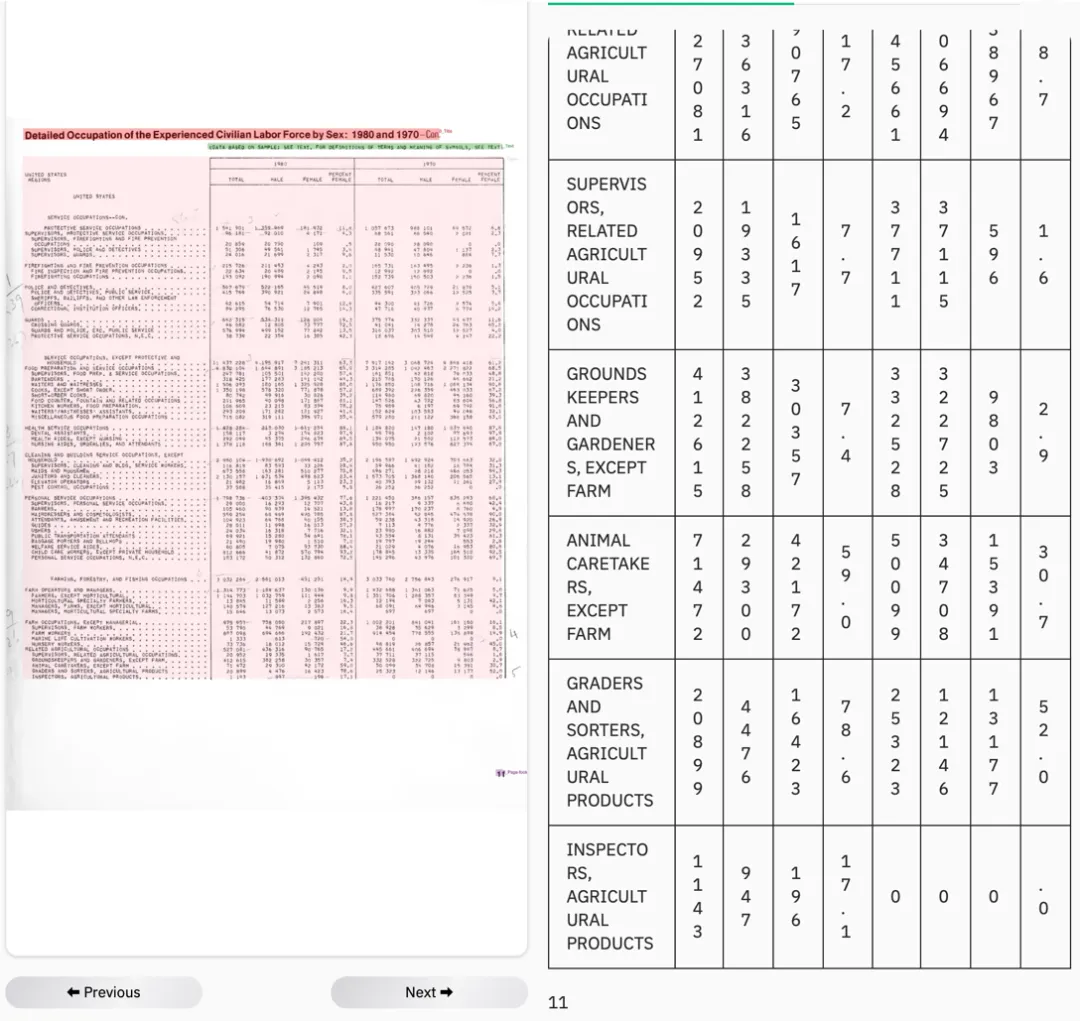
图 5|MOCR 输出结果,表格结构保持最好,信息完整度明显更高。
这一部分看下来,结论其实很清楚:只有 MOCR 真正完成了从“识别字符”到“读懂表格”的跨越。
02 小语种识别:真正拉开差距的是稳定性
很多 OCR 在中文、英文场景下表现还不错,但一进入小语种环境,问题就会迅速暴露出来。
这次我们选了 藏文 作为测试对象,重点观察两件事:
-
字能不能识别出来 -
版面区域能不能正确检测出来
测试原图

图 6|藏文测试样本。除了字符识别本身,还非常考验版面区域检测能力。
模型对比
PaddleOCR-VL-1.5
Layout 检测出现错误,导致部分内容遗漏,说明它在小语种和复杂版面叠加场景下稳定性不足。
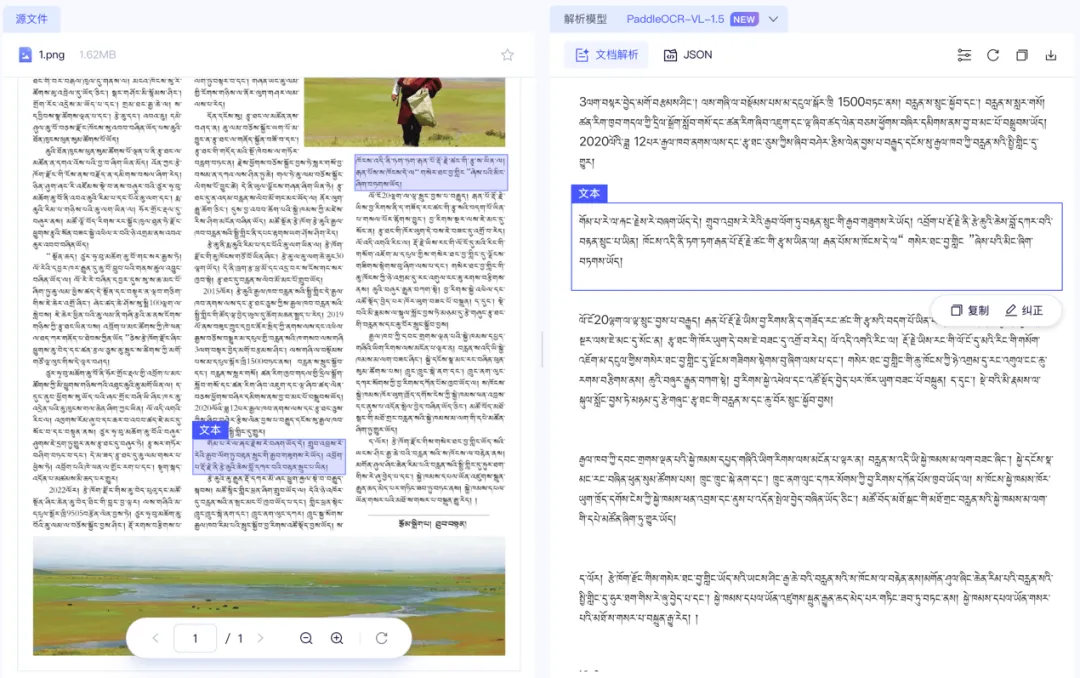
图 7|PaddleOCR-VL-1.5 输出结果,主要问题不只是识别,还有区域检测错误。
MonkeyOCR
对这类小语种场景支持有限,能力边界比较明确。
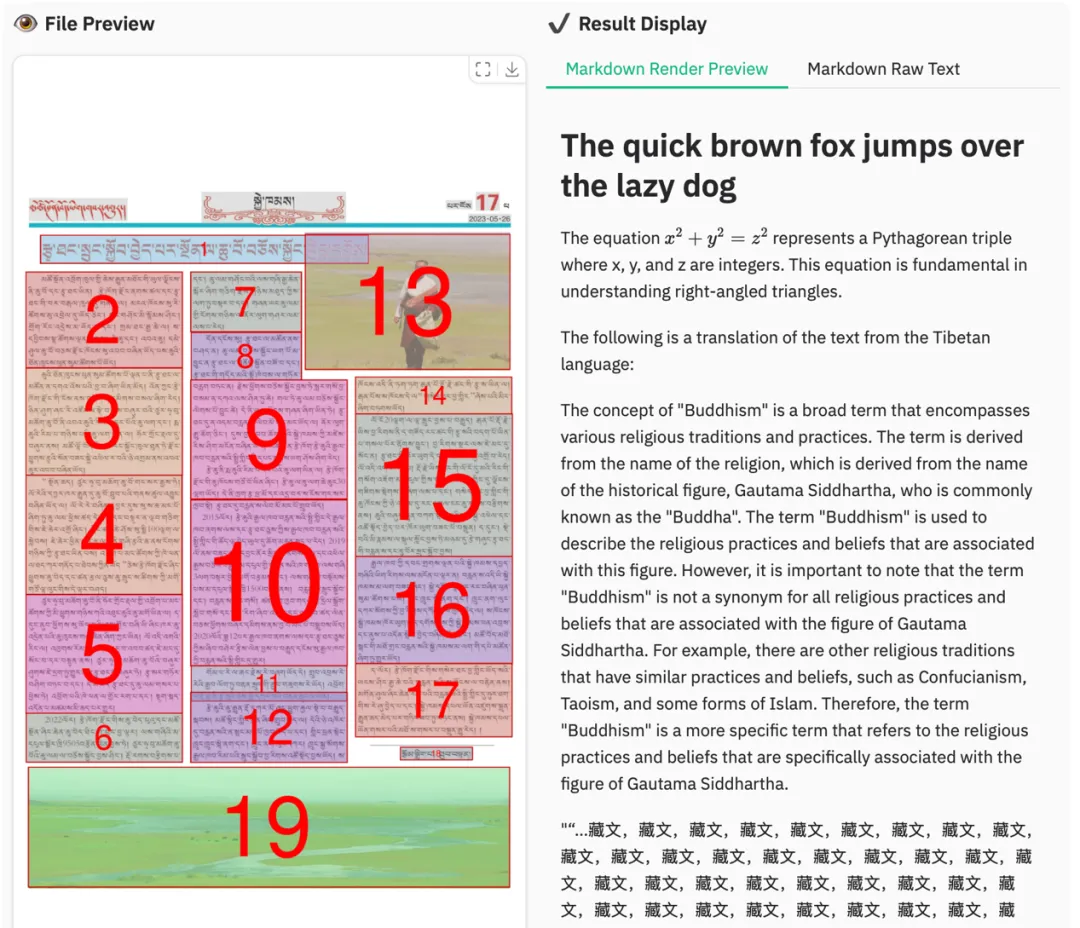
图 8|MonkeyOCR 输出结果,对小语种支持不足,泛化能力受限。
MOCR
无论是检测还是识别都更稳定,没有明显漏检,版面逻辑也保持得更完整。
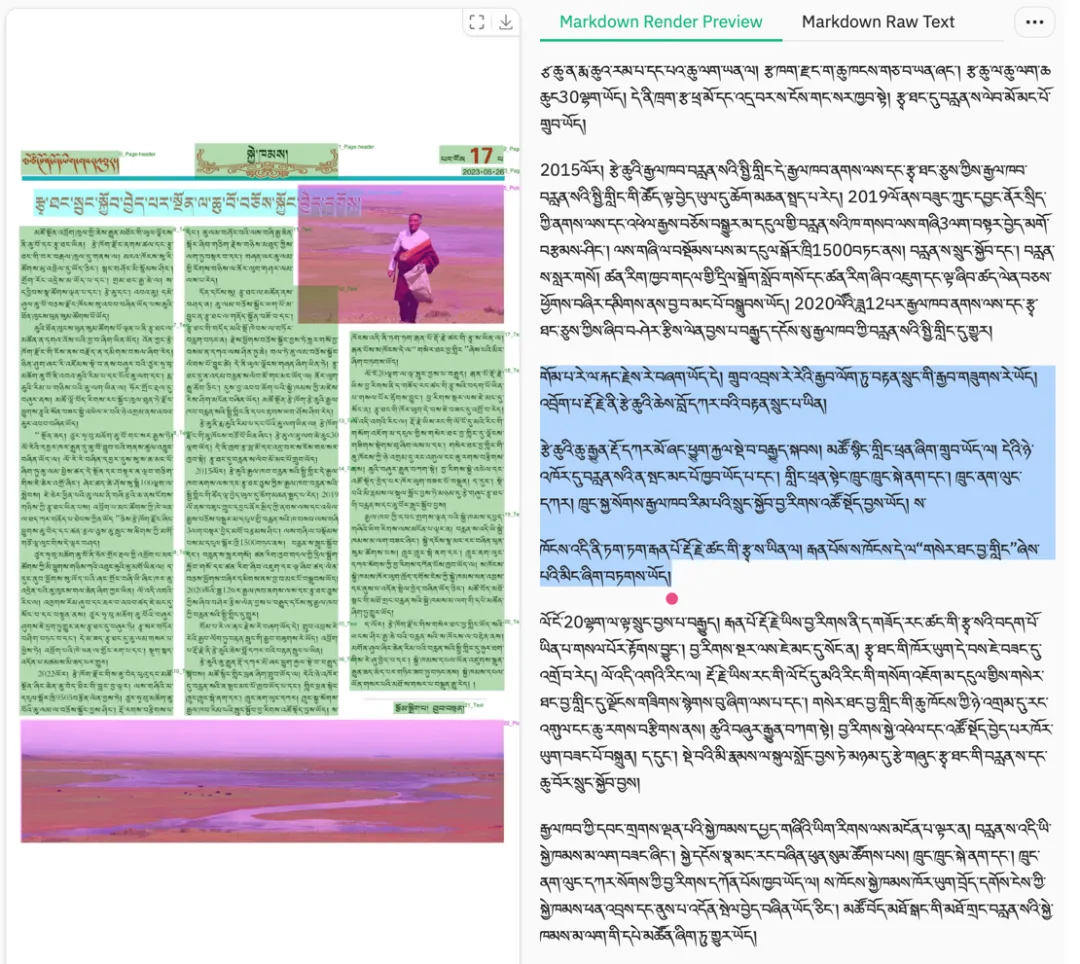
图 9|MOCR 输出结果,小语种识别与版面检测都更稳定。
小语种场景里,真正重要的不是“能识别一点”,而是能不能稳定地把整页内容读对、读全、读顺。
03 网页解析:长内容才是真正的试金石
网页解析看起来简单,但真正一到长页面、复杂区块、信息密度高的内容时,模型之间的差距就会迅速放大。
模型对比
PaddleOCR
长网页压缩后细节丢失,信息一多,解析结果就开始变粗糙。
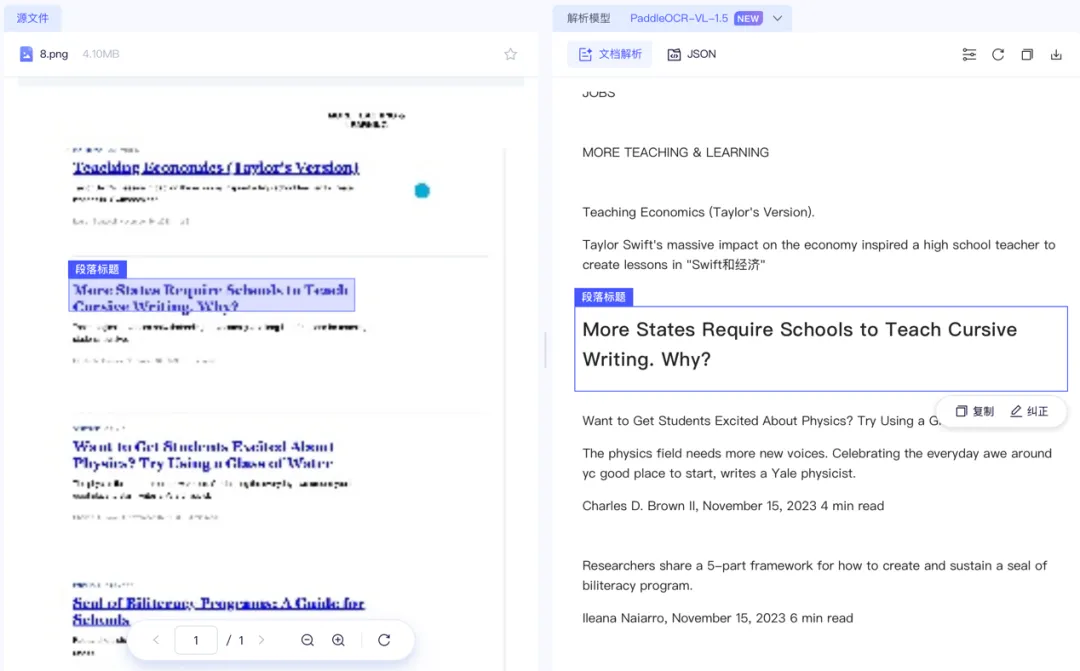
图 10|PaddleOCR 网页解析结果,长页面场景下细节保留不够。
MonkeyOCR
长内容下存在明显遗漏,关键信息抓取不完整。
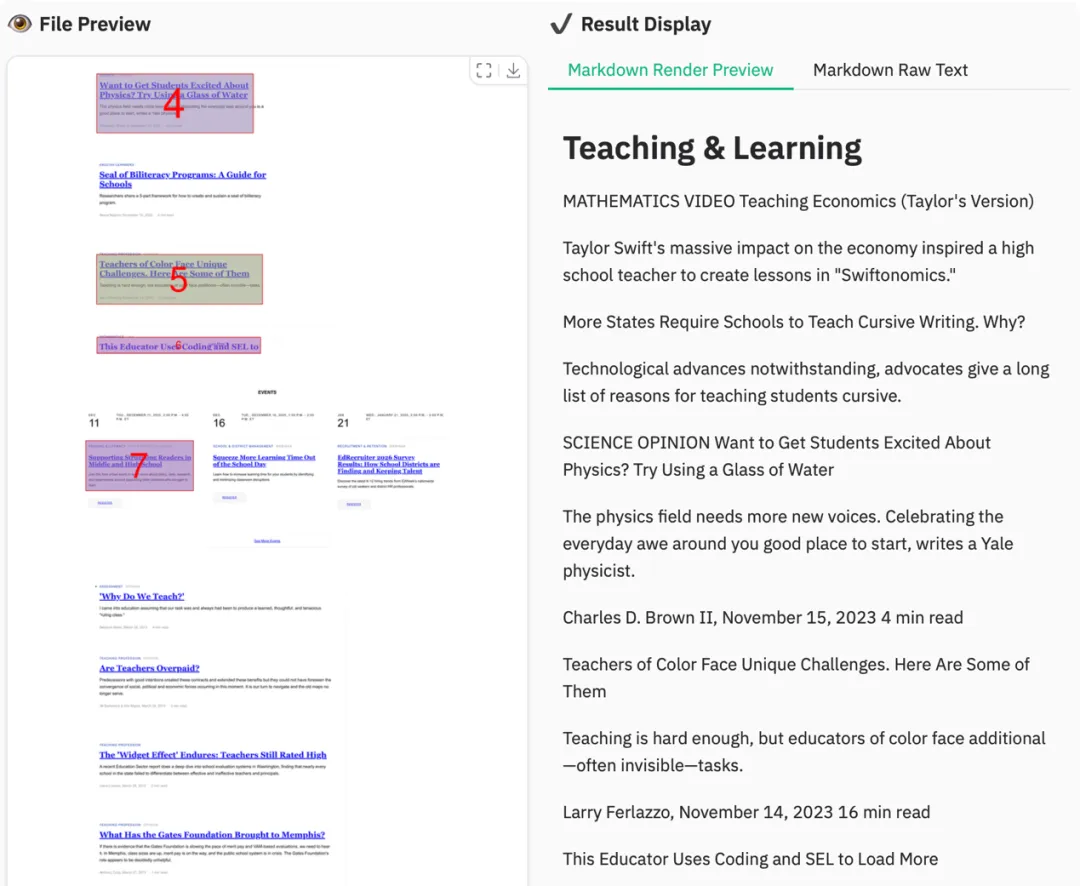
图 11|MonkeyOCR 网页解析结果,完整性不足。
HunyuanOCR
在这个案例中出现重复输出,说明解析链路没有稳定收敛。
MOCR
能够提取更细的内容信息,同时保持较好的整体结构,对长网页内容更友好。

图 12|MOCR 网页解析结果(示例一),在长页面下仍能保留较多细节。
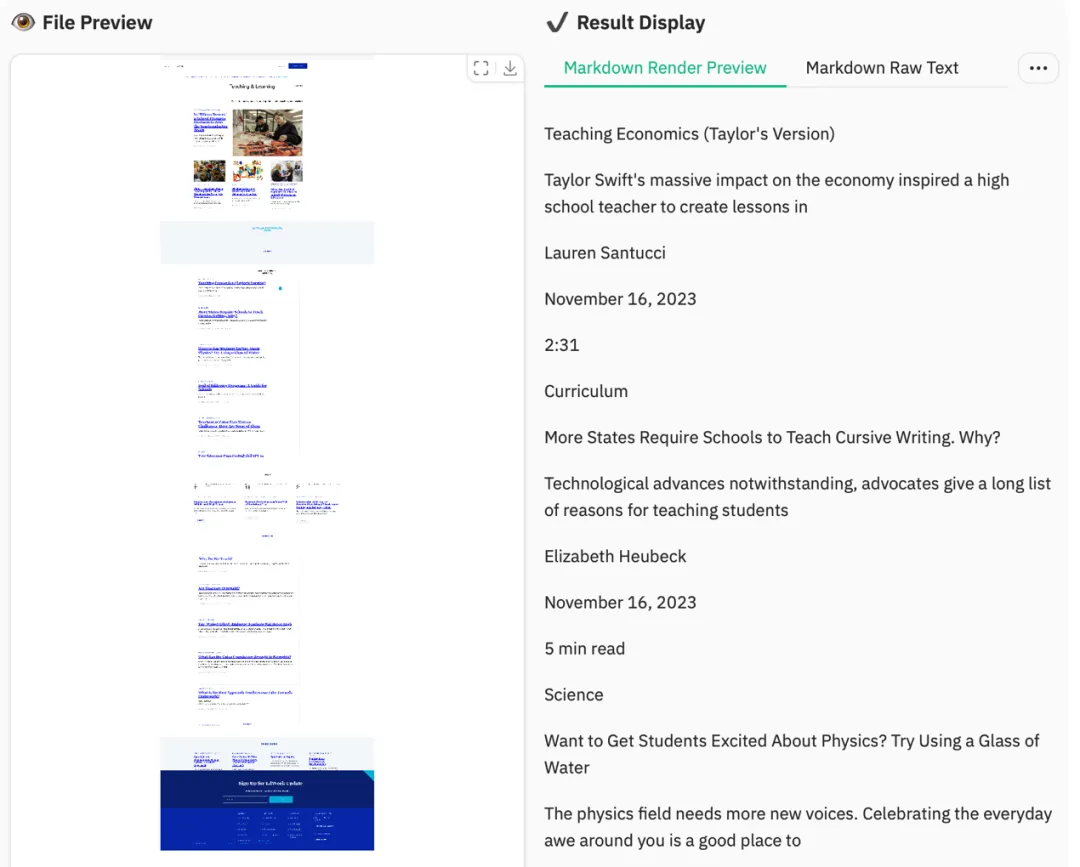
图 13|MOCR 网页解析结果(示例二),结构和内容完整度都更高。
如果说短文本解析只能看基础能力,那长网页场景看的就是模型有没有真正的内容组织能力。
04 MOCR 不只是 OCR
如果把 MOCR 只理解成一个 OCR 工具,其实低估了它。
更准确地说,它更像一个面向复杂视觉文档的 文档理解模型。除了常规识别外,它还能覆盖很多传统 OCR 容易失效的高难场景。
复杂版面
面对多栏、多块、多层级页面时,MOCR 依然能保持较好的结构输出。

图 14|复杂版面场景。重点不是识别几个字,而是把整体布局关系梳理出来。
拍照文档
真实拍摄文档通常伴随透视变形、阴影、倾斜、反光等问题,这也是 OCR 在落地时最常见的挑战之一。
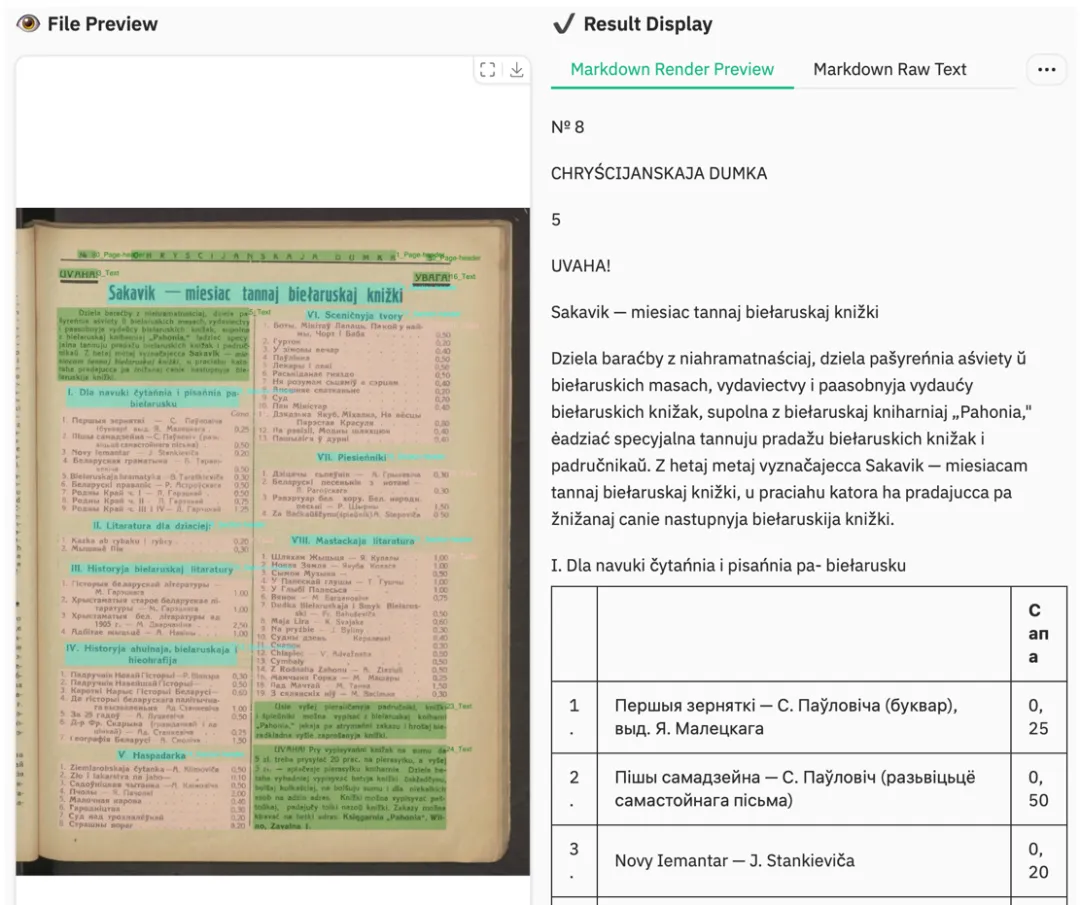
图 15|拍照文档场景。MOCR 对真实拍摄噪声具备更强适应性。
竖排古籍
这类场景对传统 OCR 很不友好,因为它打破了标准横排阅读逻辑。

图 16|竖排古籍场景。非常规排版下更考验模型的阅读方向理解。
场景文字识别
自然场景中的招牌、标识、复杂背景文字,往往伴随透视、遮挡和背景干扰。
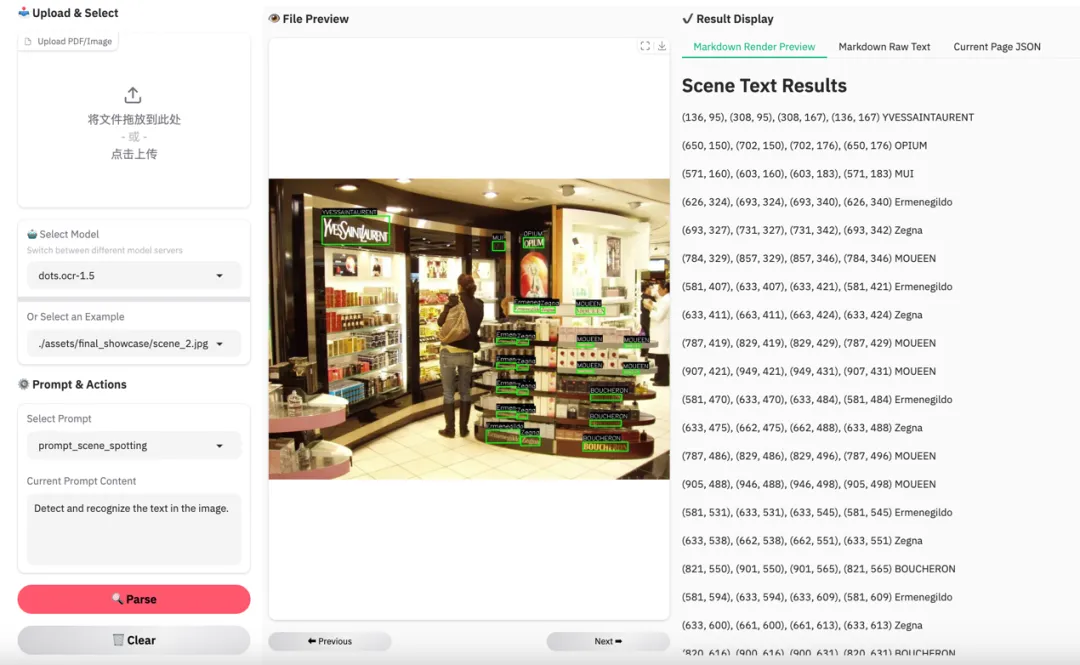
图 17|自然场景文字识别。除了识别能力,还要处理复杂背景干扰。
图像 SVG 重构
这部分已经不只是“文字提取”,而是进一步走向图形结构理解和重建。
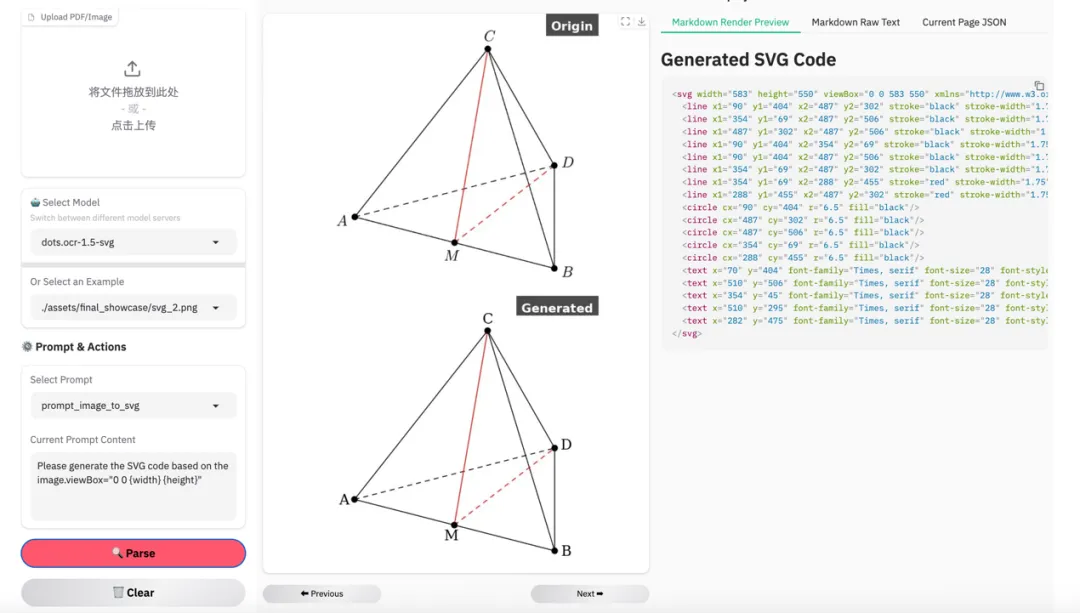
图 18|图像 SVG 重构示例 1。说明模型具备更强的结构表达能力。
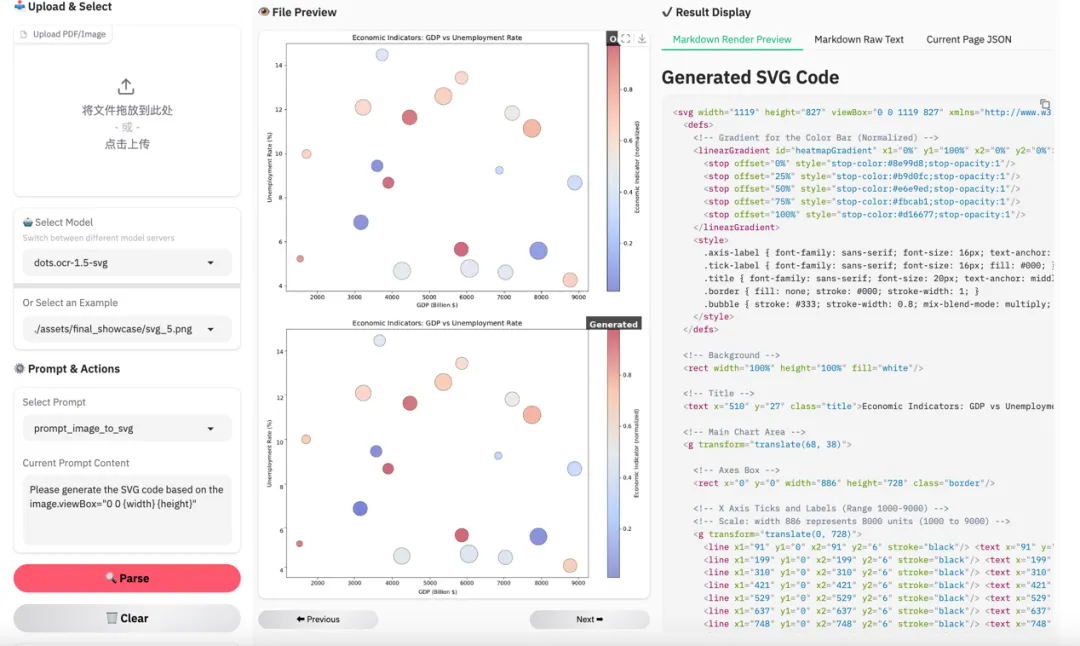
图 19|图像 SVG 重构示例 2。复杂图形元素也能较好还原。
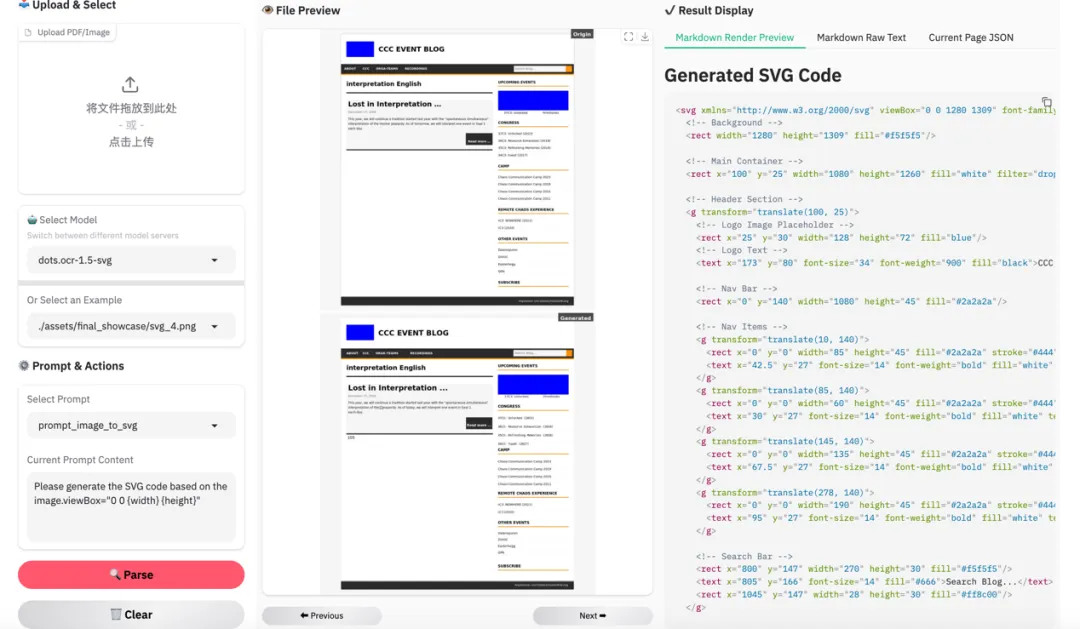
图 20|图像 SVG 重构示例 3。MOCR 的能力边界已经超出传统 OCR。
05 总结
这次测试给我的一个很明确的感受是:
OCR 的分水岭,已经不再只是识别率,而是理解力。
如果把 MOCR 的优势浓缩成三个关键词,我会选:
-
更完整:长表格、长网页不容易截断或漏内容 -
更稳定:小语种、复杂版面下结果波动更小 -
更理解文档:不仅识别文字,还能还原结构和逻辑
所以,与其说 MOCR 是一个 OCR 工具,不如说它更像一个真正面向复杂场景的文档理解模型。
对于表格抽取、网页结构化、拍照文档处理、多语种资料解析这类任务来说,这种差距并不是“小优化”,而是能不能真正落地使用的差别。