当前时间: 2026-03-25 14:27:23
更新时间: 2026-03-25
分类:软件教程
评论(0)
RAG知识库建设:文档解析
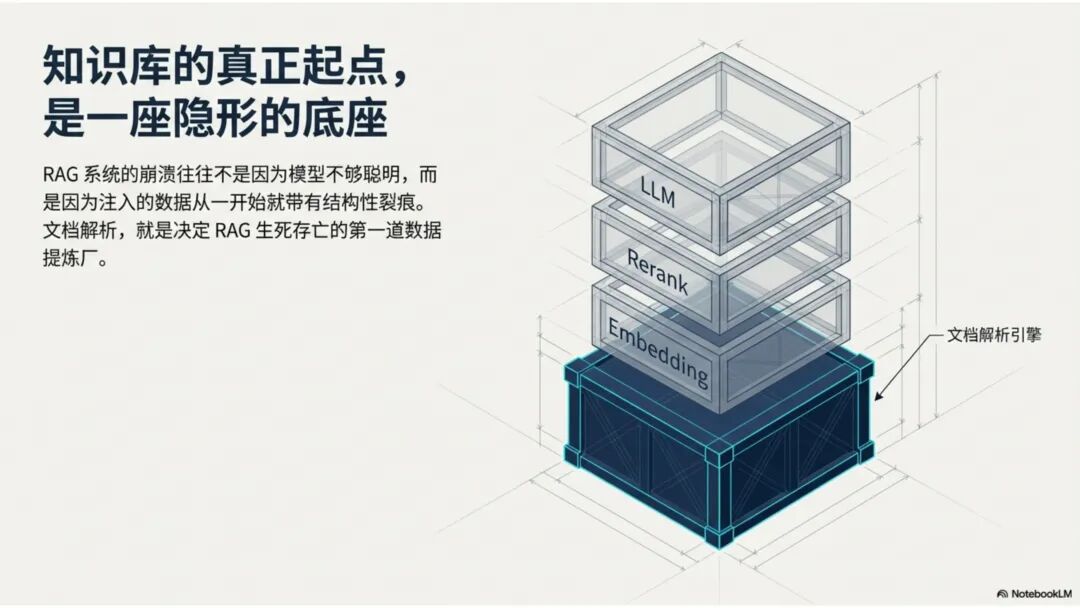
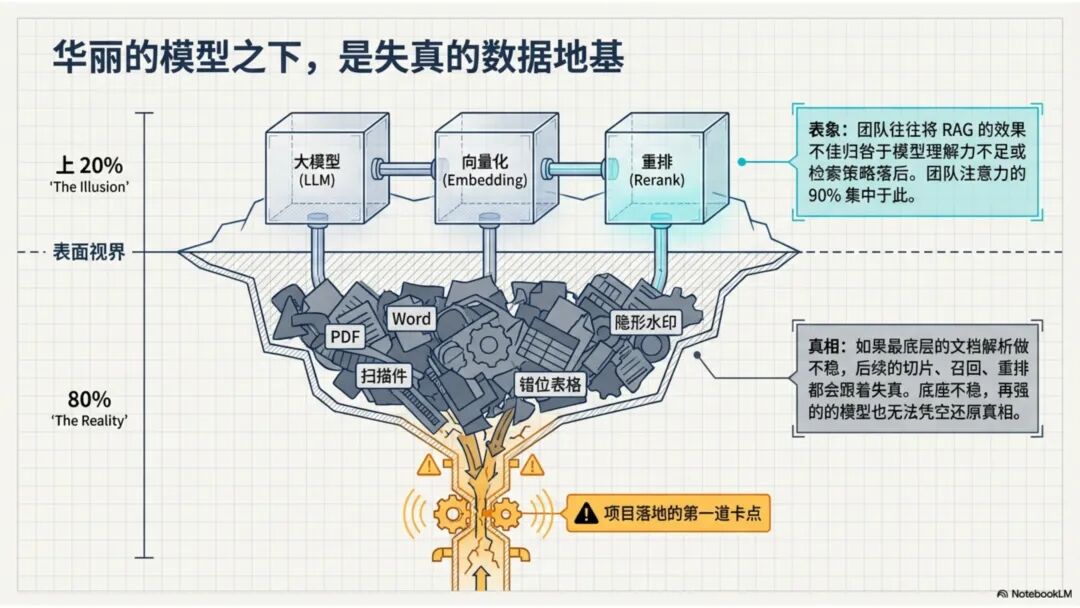
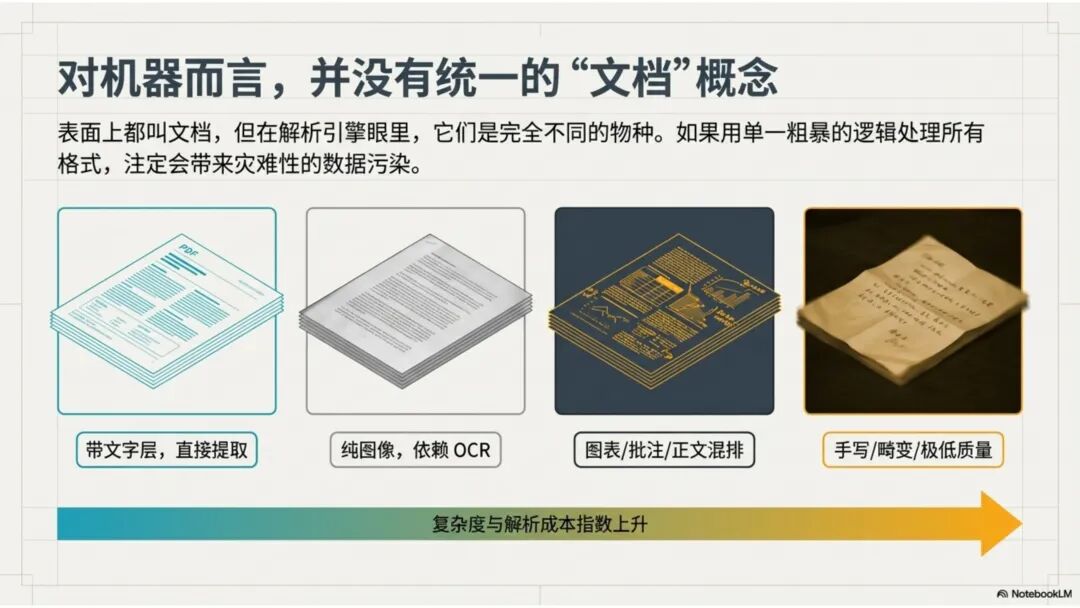
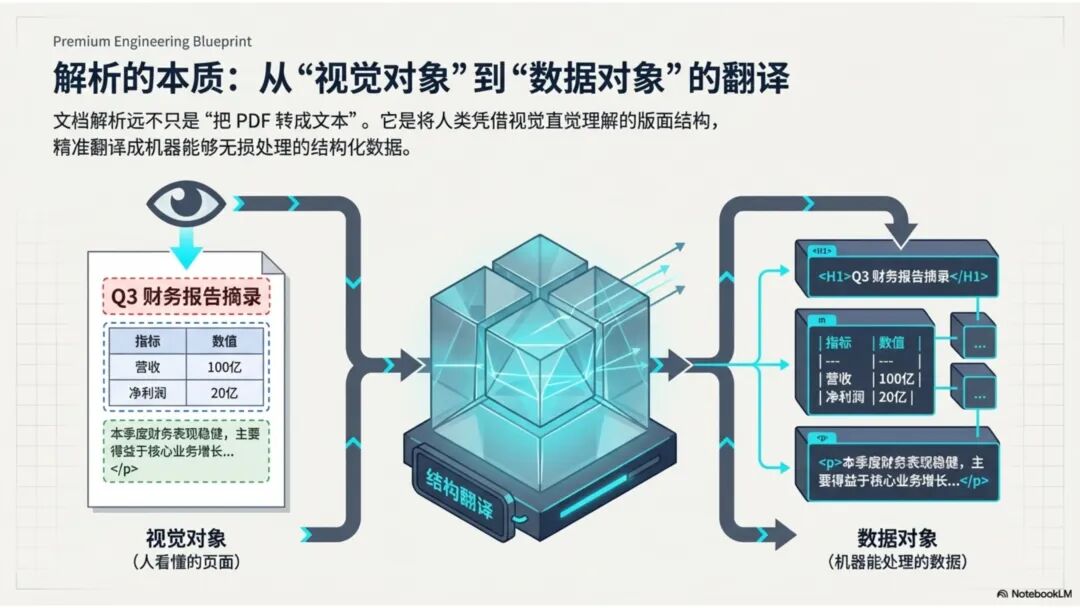
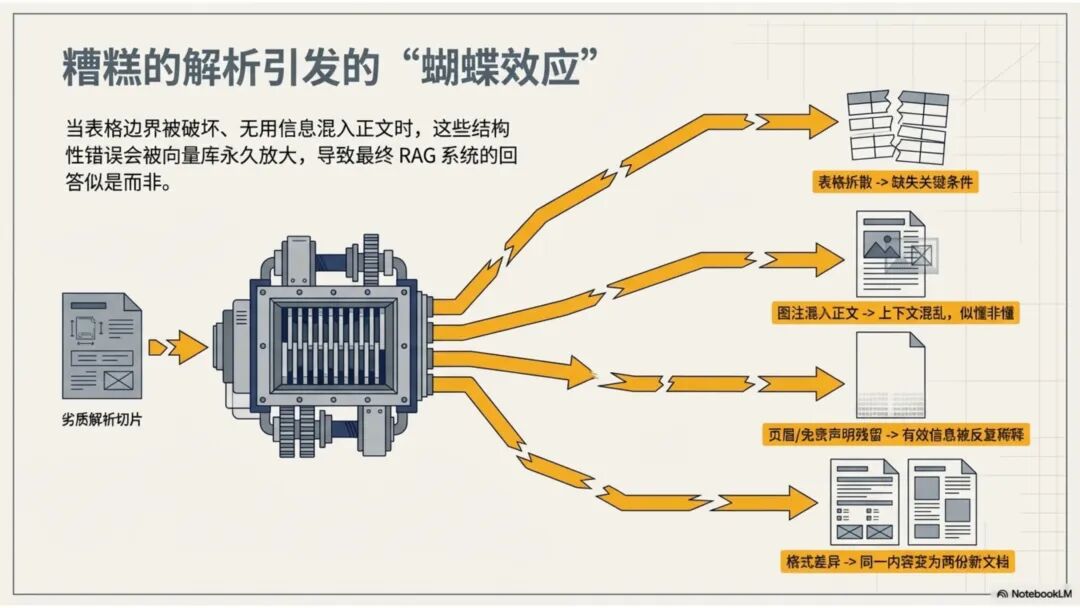
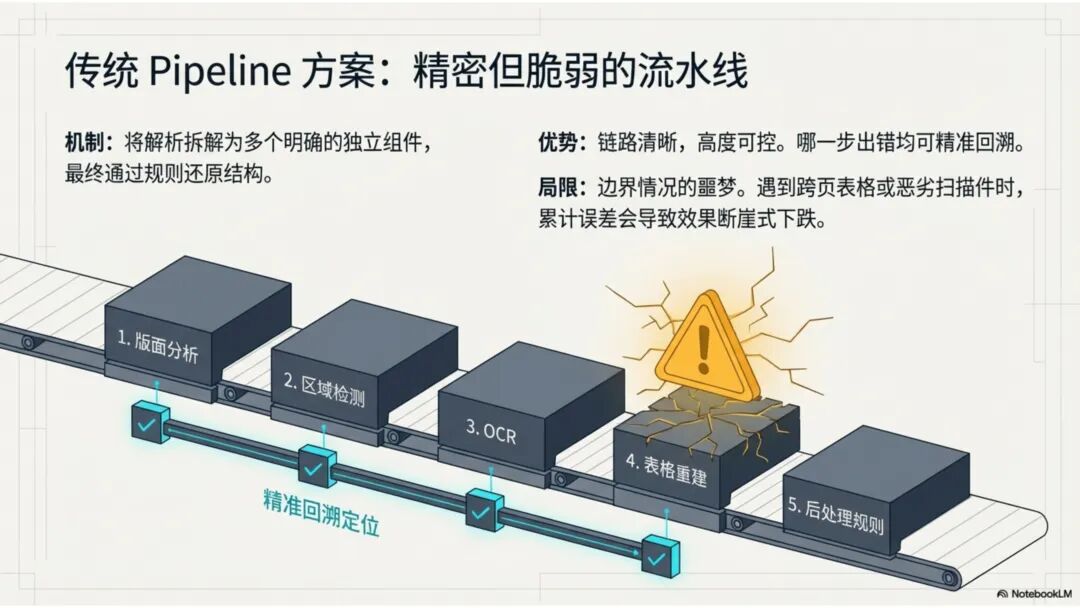
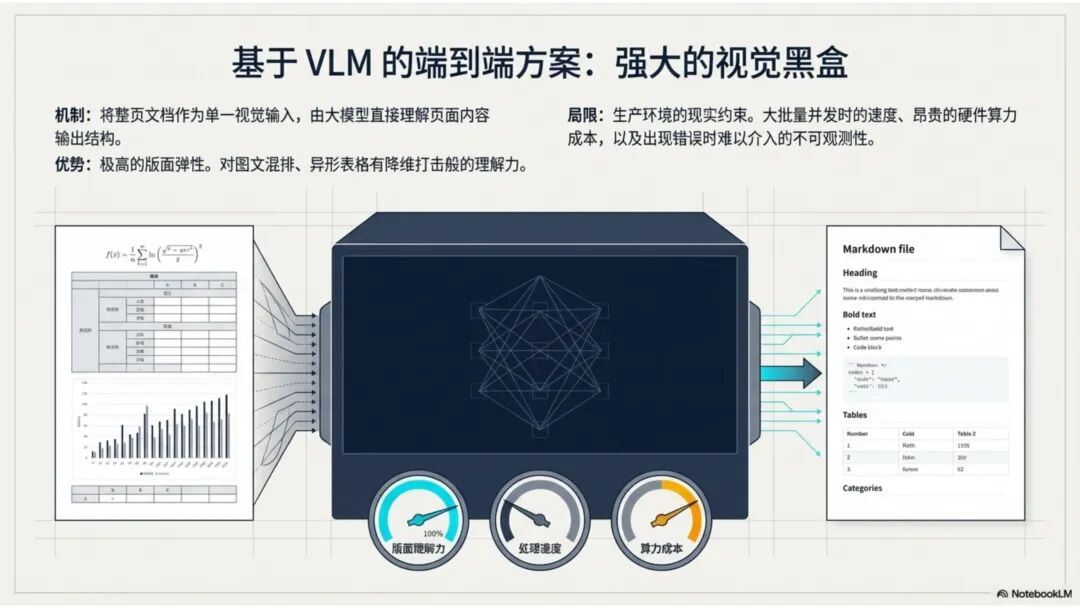
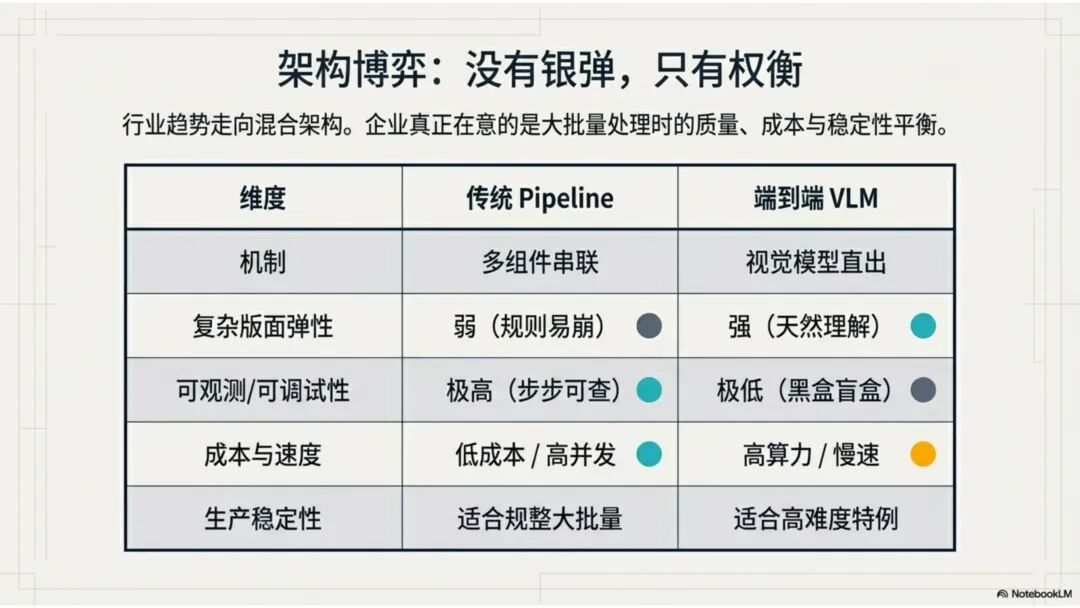
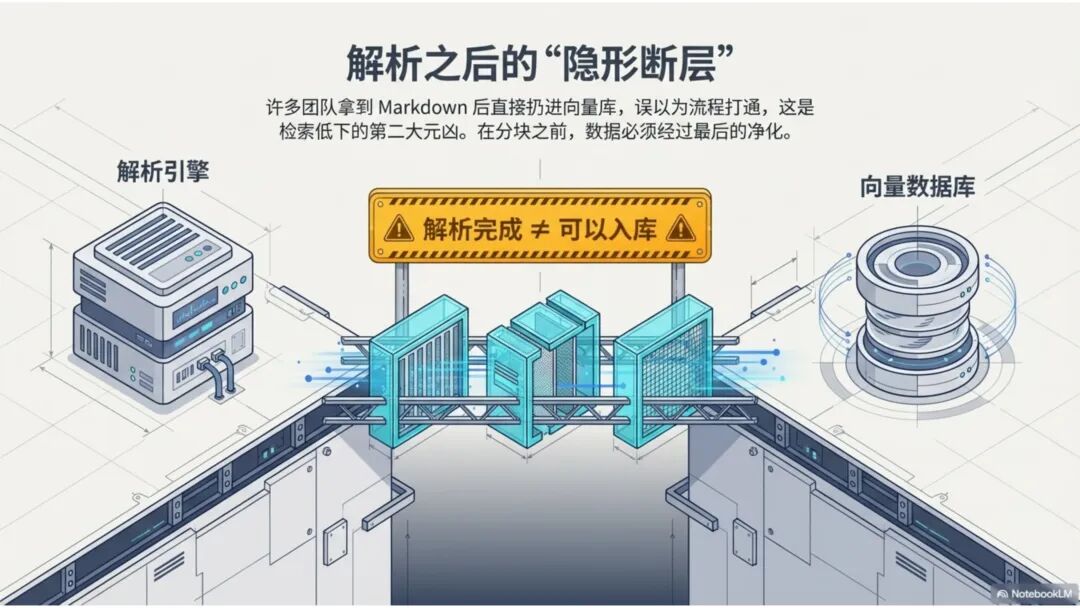
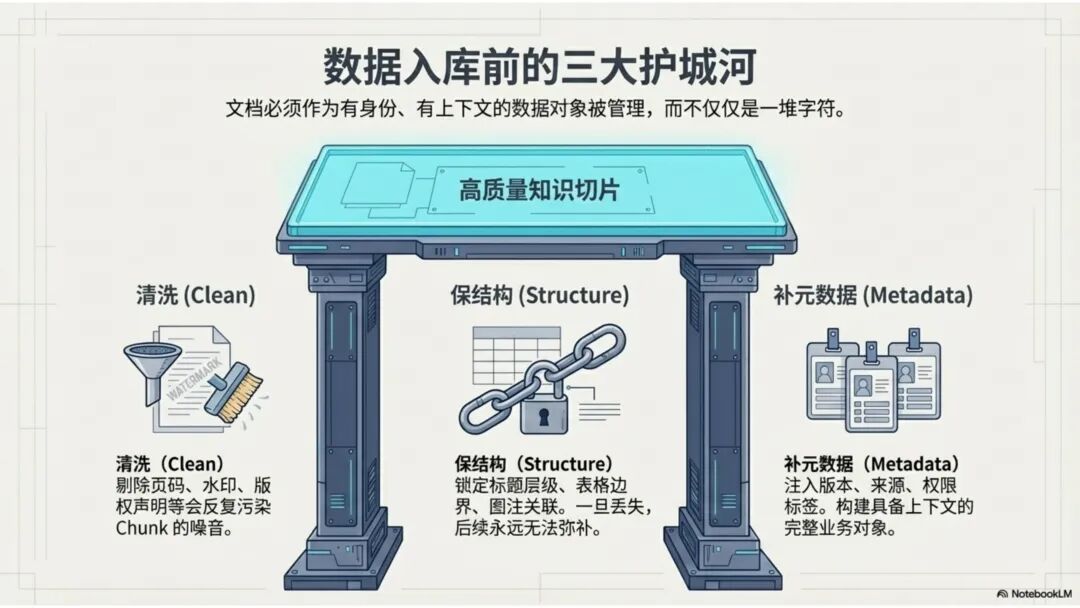
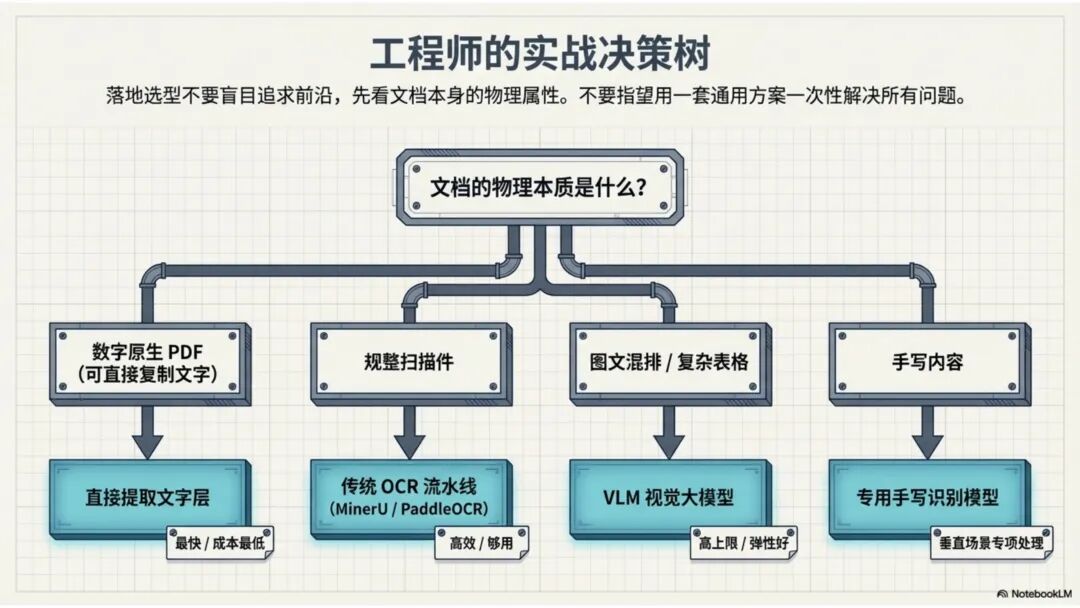
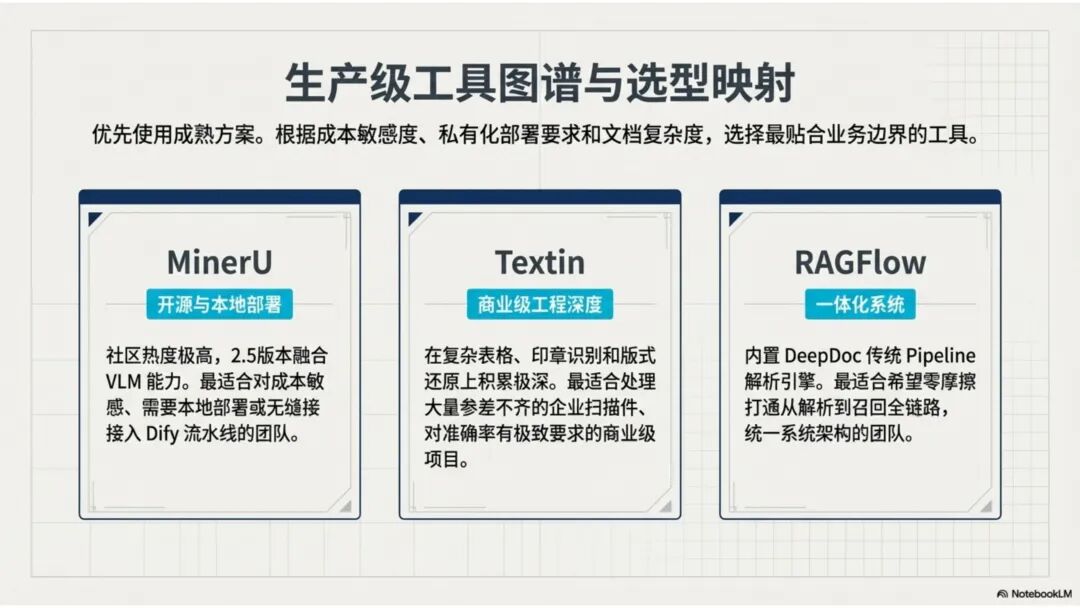
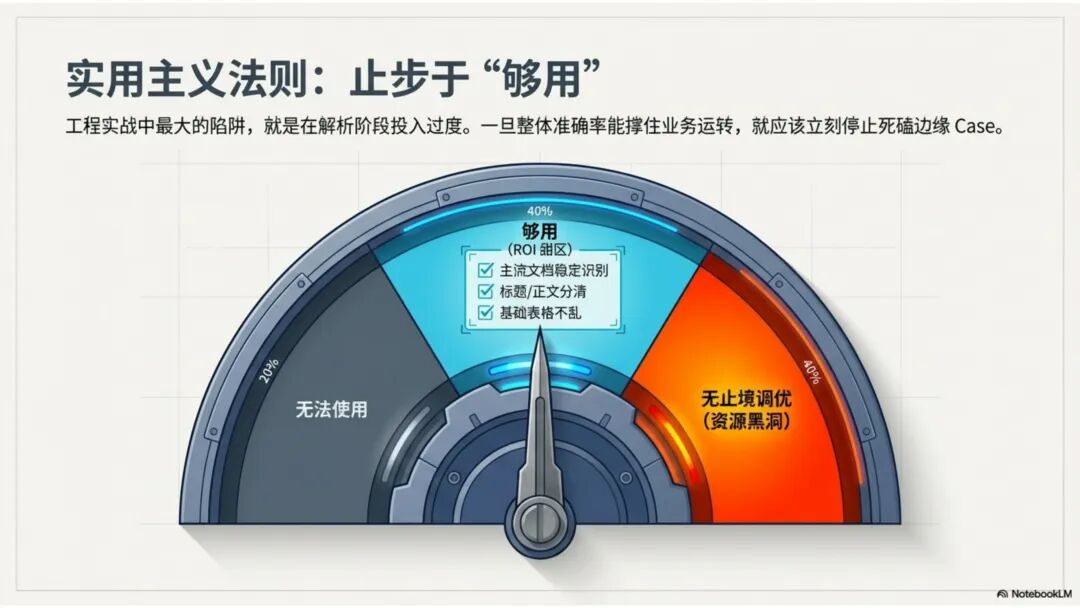
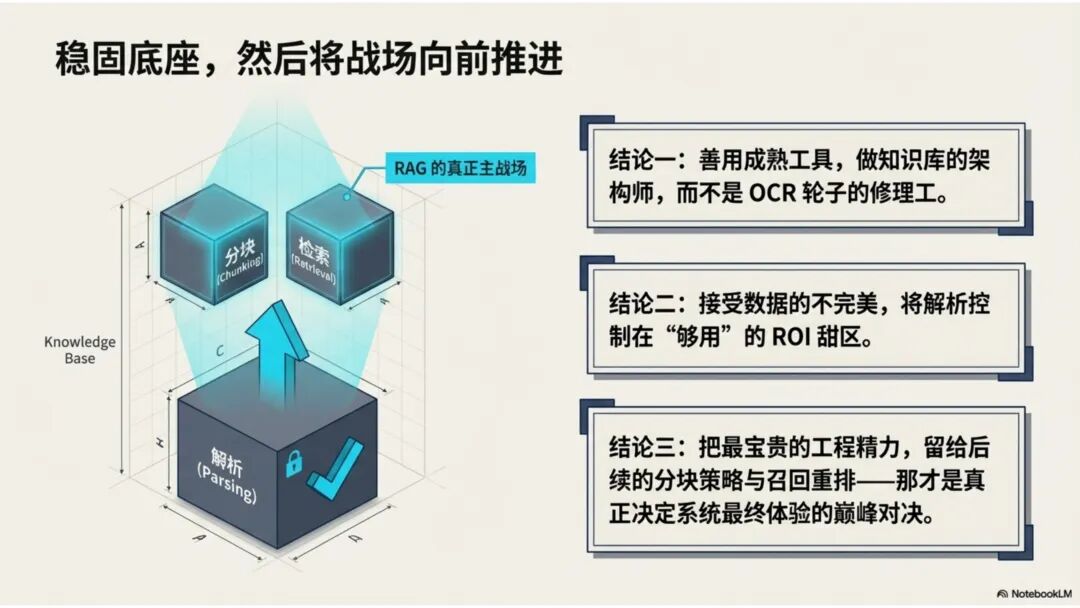
文档解析,是知识库真正的起点 很多团队一提到做 RAG,第一反应往往是模型、Embedding、重排,注意力几乎都放在“后半段”。但项目一旦真开始落地,最先卡住的,常常不是模型,而是文档。 PDF、Word、Excel、扫描件、拍照件,表面上都叫“文档”,对机器却完全不是一回事。有的带文字层,可以直接提取;有的本质上只是图片;有的版式规整,有的图表、批注、页眉页脚全混在一起。如果前面这一步做不稳,后面的切片、召回、重排、问答都会跟着失真。 所以文档解析并不是一个可有可无的预处理环节,它更像知识库建设的底座。底座不稳,后面再强的模型也很难把效果真正拉起来。 文档解析,到底在解决什么 从工程角度看,文档解析其实就是把“人能顺着看懂的页面”,变成“机器能继续处理的数据”。 这里面最关键的,不只是把字识别出来,还要尽量还原文档本来的组织方式。文字认得准不准、阅读顺序对不对,标题和正文有没有分清,表格有没有被拆坏,图片说明、脚注、页眉页脚有没有混进正文,这些都会直接影响后面的知识入库质量。 如果这些问题没处理好,后面就很容易出现一些很典型的情况:检索命中了看着相关、其实不对的段落;答案少了关键条件,因为表格在解析时被拆散了;召回的内容把图注和正文混在一起,读起来像是“似懂非懂”;同一份文档换个导出方式就像两份新文档,去重也做不干净;本来该过滤掉的页码、免责声明、页眉页脚,反复混进 chunk 里,把真正有用的信息稀释掉。 所以文档解析远不只是“把 PDF 转成文本”。更准确地说,它是在把一个视觉上的页面对象,转成一个可以进入知识系统的数据对象。 现在常见的几种做法 一种是传统的 Pipeline 方案,也就是把整个解析过程拆成多个明确步骤:先做版面分析,再做区域检测、OCR、表格重建,最后通过规则把结构还原出来,输出成 Markdown、JSON 之类的中间结果。这种方式的好处是清楚、可控,哪一步出了问题,基本都能往回追。某类文档解析效果不好,你通常能判断到底是版面分错了、OCR 认偏了,还是后处理把顺序弄乱了。 它的短板也很明显。链路越长,组件越多,维护成本就越高,边界情况也会越来越多。遇到跨页表格、嵌套表格、复杂页眉页脚,或者扫描质量很差的文档时,效果经常会明显下滑。 另一种思路是基于 VLM 的端到端解析。简单说,就是把整页文档当成视觉输入,直接让模型去理解页面内容和结构,再输出结构化结果。它在复杂版面上的弹性通常更好,对图文混排、公式、注释、异形表格这些情况,也往往更有优势。 不过,擅长理解,不代表天然适合稳定生产。企业真正关心的,往往不是某一页文档“偶尔解析得很惊艳”,而是大批量跑的时候能不能稳定、可控、成本可接受,出了问题能不能回放、定位、验收。从这个角度看,VLM 还得面对速度、成本、硬件资源和可观测性这些很现实的约束。 这两年更常见的趋势,其实不是二选一,而是混合使用。能直接抽文本的数字原生 PDF,就尽量走文字层提取,因为更快、更便宜,通常也更准;碰到扫描件、拍照件、复杂版面和复杂表格,再把视觉模型拉进来处理;至于公式、表格、阅读顺序、图片说明这些难点,很多时候还是要靠多模型配合后处理规则,效果才会稳定。 所以实战里真正该看的,从来不是“Pipeline 还是 VLM”这个标签,而是面对你的那批真实文档,谁能把质量、成本和稳定性平衡得更好。 解析完,不等于就能直接入库 很多项目做到这里,容易顺手把解析结果直接扔进向量库,觉得流程已经打通了。其实这一步往往还差一点火候。 第一件是清洗。不是所有识别出来的内容都值得进知识库。页码、页眉页脚、版权声明、重复目录、背景水印、模板占位文字,这些东西如果不清理,最后就会反复污染 chunk。 第二件是保结构。一个标题属于哪一层、表格边界在哪里、附件挂在哪一段后面、图注对应哪张图、章节顺序是否完整,这些信息一旦在解析阶段丢掉,后面再怎么分块都很难补回来。 第三件是补元数据。文档标题、来源、版本、生效时间、所属部门、业务域、权限标签、是否扫描件、是否包含表格、是否带附件,这些信息看起来不像“正文”,但对检索效果和权限管理影响很大。 很多时候,RAG 做不好的根本原因并不是模型理解力不够,而是文档从一开始就没有被当成一个有上下文、有版本、有身份的数据对象去管理。 工程上怎么选 如果是实际项目落地,选方案不用太玄,先看文档本身。 数字原生 PDF 如果本来就能复制文字,优先直接提文字层,通常没必要先上 OCR。排版相对规整的扫描件,传统 OCR 流水线往往已经够用,比如 MinerU、PaddleOCR 这类方案。遇到复杂表格、图文混排特别重的页面,VLM 路线一般更有优势。至于手写内容,最好单独交给专门的手写识别模型,不要指望通用方案一次性全包。 再往下,就看你的质量要求和部署边界。如果目标是尽快上线,直接用成熟 SaaS 往往最省事,像 MinerU 在线版、Textin 这类服务,解析完直接接进知识库流程即可。如果有私有化要求,那就更适合部署本地版 MinerU 或 PaddleOCR 流水线,再围绕自己的文档类型做一些针对性调优。要是数据很敏感、准确率要求又特别高,也可以考虑商业 OCR API,比如腾讯云 OCR、阿里云文字识别,再针对关键文档单独处理。 还有一点很重要:不要在解析阶段投入过头。大多数场景里,解析做到“够用”就已经可以了。能稳定识别主流文档,标题、正文、表格这些常见结构能基本分清,整体准确率能撑住业务使用,往往就该把精力往后挪了。因为真正决定知识库体验的,通常还是后面的分块、召回和检索策略。 几个常见工具 MinerU 现在算是开源社区里讨论度和综合表现都比较高的一类方案,支持 PDF、Word、PPT 等多种格式,输出结果也比较适合继续接知识库流程。2.5 版本把 VLM 能力融合进来之后,对复杂版面的处理提升比较明显。它比较适合那些对成本敏感、又希望能本地部署的场景。实际使用时,可以直接走在线版上传文档,也可以本地部署后通过命令行或 API 调用;如果你的知识库流程本身就接在 Dify 上,也可以把它放进现有流水线里。 Textin 是合合信息旗下的文档智能平台,在复杂表格、印章识别、版式还原这些场景上有比较深的工程积累,适合文档质量参差不齐、扫描件很多、又希望准确率尽量高的项目。 RAGFlow 则更偏一体化平台思路,内置 DeepDoc 解析引擎,走的是传统 Pipeline 路线。如果你希望把解析、分块、检索尽量放到同一套系统里完成,它会更省集成成本。 结语 第一,优先用成熟方案,不必一上来就自己造轮子。第二,解析做到够用就行,不要陷进无止境的边界情况调优里。第三,把最宝贵的精力留给分块和检索,因为那才是真正决定 RAG 系统体验的地方。
上一篇AI智能体真的来了!5款免费工具实测告诉你
 夜雨聆风
夜雨聆风