 夜雨聆风
夜雨聆风





文档解析这波新论文,终于开始认真面对“真实世界”了
文档解析这波新论文,终于开始认真面对“真实世界”了
先给结论:今天最值得细读的是 MDPBench。
原因很简单。它不是又提了一个更复杂的新模型,而是把很多文档解析系统最不愿意面对的问题直接摆到了台面上:
你在英文、规整扫描页上做得不错,不代表你在真实世界里真的能用。
如果把今天最值得聊的三篇工作放在一起看——历史议会文档的 VLM 语义化流程、MDPBench、以及解耦语言模型的高效领域自适应——能看到一个很明确的变化:
OCR / Document AI 正在从“把字认出来”转向“把系统做成可部署、可扩展、可跨场景工作”。
-
一篇在补 OCR 之后的语义工作流; -
一篇在拆 多语言和真实拍摄场景里的泛化短板; -
一篇在算 领域适配到底能不能别这么贵。
这比单纯看某个 benchmark 多涨两个点,重要得多。

图:来自原论文(多语言文档解析基准总览)。这批工作最值得注意的,不是又有多少新模型,而是大家终于开始认真看真实世界场景到底有多难。
第一篇:MDPBench,不少文档解析模型其实只是在“容易条件下”表现不错
论文:https://arxiv.org/abs/2603.28130v1[1]
GitHub:https://github.com/Yuliang-Liu/MultimodalOCR[2]
这篇是今天我最想推荐的一篇。
因为它做的不是再叠一个模块,而是把问题问得很扎心:
现在这些文档解析模型,到底是真的稳,还是只是在最容易的数据上显得稳?
它具体解决什么问题?
现有很多 document parsing 结果看起来已经很强了,但如果仔细看,大量 benchmark 还是集中在:
-
英文或少数主流语言; -
干净、规整的数字页; -
版式相对标准的文档。
问题在于,真正上线之后你会遇到的根本不是这类“教科书式页面”,而是:
-
手机随手拍的文档; -
非拉丁脚本; -
阅读顺序复杂的页面; -
拍摄变形、阴影、透视畸变。
MDPBench 针对的就是这个现实落差。
方法上真正新的点是什么?
它最有价值的地方不是模型,而是评测设计。
作者构建了一个覆盖 17 种语言 的多语言文档解析基准,同时包含:
-
digital-born 文档; -
photographed 文档; -
多类脚本; -
高质量人工修正与验证标注。
这件事看起来不炫,但很关键。因为很多模型能力,只有放到这种基准里才会露馅。

图:来自原论文(基准概览图)。这篇最重要的贡献不是某个 trick,而是把“文档解析到底该怎么测”这件事重新立住了。
实验里最值得看的结果是什么?
这篇最值得记住的不是总体平均分,而是差距出现在哪里:
-
闭源模型整体更稳; -
开源模型在 拍摄文档 上平均下降 17.8%; -
在 非拉丁脚本 上平均下降 14.0%。
这组结果其实很有杀伤力。它说明很多模型不是“还有一点提升空间”,而是在真实使用条件下会明显掉线。

图:来自原论文(数字文档与拍摄文档示例)。真实世界难点不只在识别本身,还在拍摄条件、布局扰动和跨语言泛化一起叠加。
我的判断
如果你做的是文档解析产品,这篇应该优先级很高。
因为它提醒的是一个特别现实的事:线上问题往往不是平均水平不够高,而是模型在边缘场景里太脆。
所以我会把这篇定义成“今天最值得精读”的原因,不在于它最炫,而在于它最接近真实部署的痛点。
📌 复现建议:
-
不要只看总分,优先拆语言、脚本和文档来源; -
单独统计 reading order 错误和 hallucination; -
如果走开源路线,先补拍摄文档和非拉丁脚本数据。
第二篇:历史议会文档这条线,开始从 OCR 走向语义数字化了
论文:https://arxiv.org/abs/2603.28103v1[3]
这篇标题挺学术,但内容其实很好理解。
它想做的不是“把历史文档 OCR 再提一点点精度”,而是把整个流程往前推进:
从字符级转录,走到语义分段、发言人识别和实体链接。
它具体解决什么问题?
传统历史文档数字化流程有个老问题:
-
OCR 做完,得到一堆不太干净的文本; -
文本结构、说话人、语义关系还得人工补; -
真正能分析的结构化数据产出很慢。
所以这篇真正想回答的是:
历史档案能不能直接从扫描件走到可分析的语义化结果。
方法上真正新的点是什么?
它的 pipeline 很完整:
-
先用专用 OCR 模型提取文本,并尽量保持阅读顺序; -
再用 VLM 做转录精炼、元素分类和 speaker identification; -
最后把识别出的发言人与知识库做实体链接。
这类工作最有价值的地方,不是某个局部模块,而是它把多个“本来默认要人工接手”的环节连起来了。
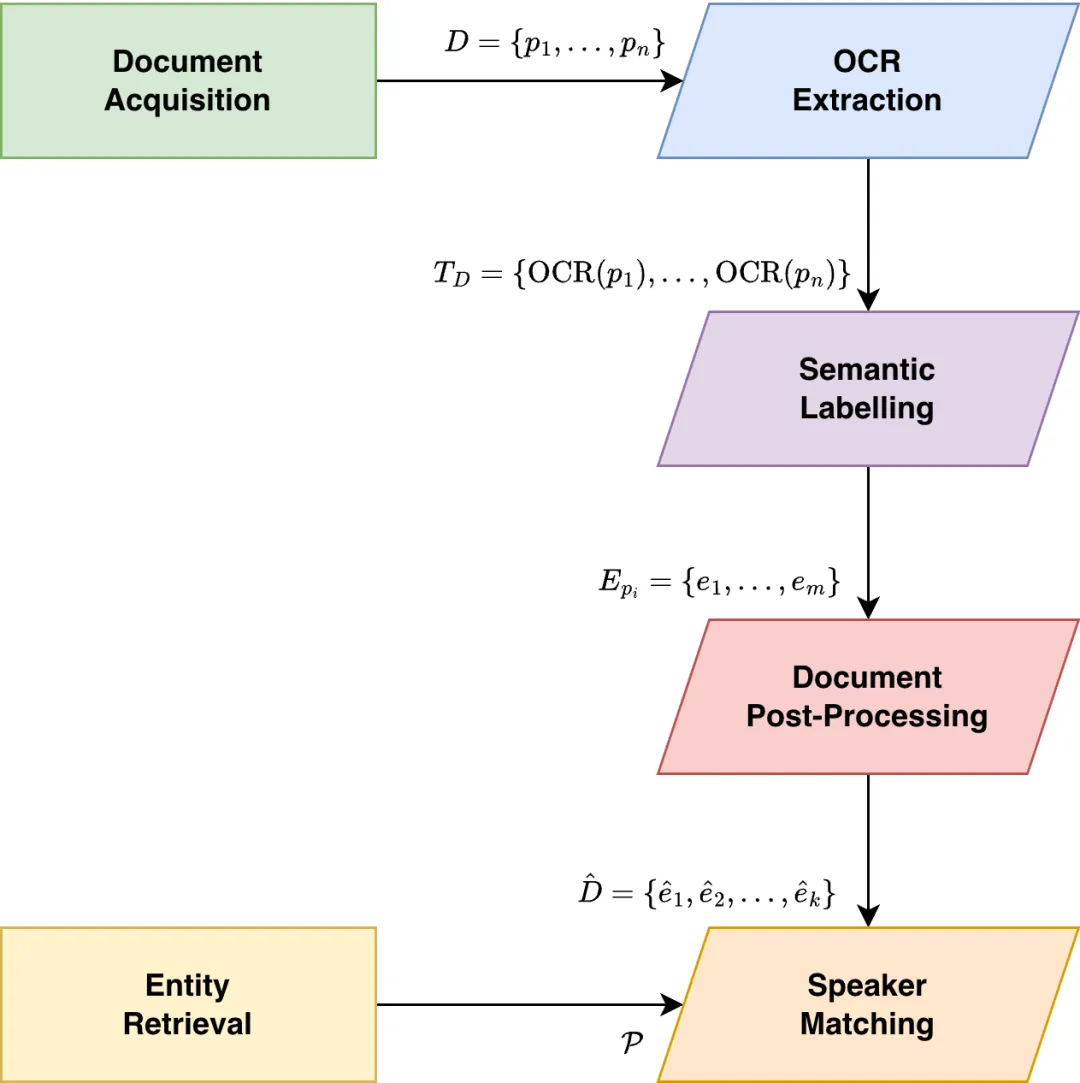
图:来自原论文(处理流程图)。这篇的重点不是把 OCR 当终点,而是把 OCR 放进一个可查询、可分析的语义工作流里。
实验里最值得看的结果是什么?
作者报告在转录质量和 speaker tagging 上都比传统 OCR 流程更好。
这说明 VLM 在历史文档里的作用,可能不只是“帮你认得更准”,而是更适合处理版面、文本和语义标签之间的耦合关系。

图:来自原论文(历史议会文档原页示例)。这类材料的难点,不只是字迹和扫描质量,还包括结构层级、版面顺序与实体识别。
我的判断
如果你做的是档案数字化、古籍整理、历史文献分析,这篇很值得看。
我的判断是:这类工作真正重要的,不是 OCR 本身,而是 OCR 之后能不能直接接到结构化知识加工。
单看识别率,这篇未必最炸;但从系统价值看,它比很多只刷指标的论文更扎实。
📌 复现建议:
-
阅读顺序评估要单列; -
speaker tagging 和 entity linking 最好独立评估; -
如果迁到中文场景,知识库 schema 设计会很关键。
第三篇:OCR 领域自适应,没必要每次都重训一个大一统模型
论文:https://arxiv.org/abs/2603.28028v1[4]
这篇我会归到“特别懂成本”的那一类。
它讨论的是文本行识别里一个很现实的问题:
每来一个新领域,都要把端到端大模型重新适配一遍,成本到底值不值?
它具体解决什么问题?
端到端 Transformer OCR 在新领域上适配时,经常面临三件事:
-
训练贵; -
标注贵; -
迁移慢。
对大团队还能咬牙扛,对很多中小团队和数字人文项目来说,这种成本结构并不友好。
方法上真正新的点是什么?
作者给出的思路非常清楚:把“看见”和“纠错”拆开。
-
轻量视觉检测器负责字符检测; -
预训练语言模型负责领域相关的语言校正; -
通过合成噪声训练 corrector,尽量避免依赖标注目标域图像。
这本质上是在把 OCR 领域适配变成一个更模块化、更便宜的问题。

图:来自原论文(现代手写场景结果图)。这篇的关键不是换一个更大 backbone,而是把适配成本从“整模型重训”改成“模块化重配”。
实验里最值得看的结果是什么?
作者给出的核心结果很直接:
-
能接近端到端 Transformer 的准确率; -
训练计算成本约下降 95%; -
在现代手写、草书和历史文档上都成立。
这个结果的价值,不是极致 SOTA,而是它把成本—效果比做到了很有吸引力。

图:来自原论文(历史文档场景结果图)。不同域之间真正变化最大的,往往不是视觉主干,而是语言噪声和纠错需求。
我的判断
如果你做 OCR 落地,这篇非常值得按需复现。
因为它提醒了一件常被忽略的事:端到端不一定是唯一正确答案,尤其当你的目标是低成本迁移和快速上线时。
📌 复现建议:
-
分开看 detector 和 corrector 的误差; -
合成噪声要贴近目标域退化模式; -
中文历史文本可优先验证 byte-level 语言模型路线。
横向比较:这三篇论文到底在把问题往哪里推?
1)问题定义差异
-
MDPBench:真实世界里的多语言文档解析到底有多脆? -
Italian Parliamentary Speeches:OCR 之后怎样直接走向语义数字化? -
Decoupled Language Models:OCR 领域适配能不能更便宜?
2)方法路线差异
-
MDPBench 更偏评测与问题暴露; -
Italian Parliamentary Speeches 更偏完整数字化工作流; -
Decoupled Language Models 更偏模块解耦与工程效率。
3)更偏研究还是更偏工程
-
最适合产品团队精读:MDPBench -
最适合档案/数字化方向细看:Italian Parliamentary Speeches -
最适合 OCR 落地团队复现:Decoupled Language Models
4)哪篇值得精读,哪篇适合按需读
如果今天只能认真读一篇,我还是会选 MDPBench。
因为它讲的不是“某个模型又涨了几个点”,而是一个更本质的问题:
文档解析离真实世界到底还有多远。
最后一句
今天这批 OCR / Document AI 新论文,最值得记住的不是又冒出了几个新名词,而是一个挺好的变化:
大家开始不再默认 benchmark 表现就等于真实能力,而是更认真地处理跨语言、拍摄条件、语义工作流和部署成本这些真正难的问题。
这类论文,通常更能留下来。
引用链接
[1]https://arxiv.org/abs/2603.28130v1
[2]https://github.com/Yuliang-Liu/MultimodalOCR
[3]https://arxiv.org/abs/2603.28103v1
[4]https://arxiv.org/abs/2603.28028v1