 夜雨聆风
夜雨聆风





近 10 万 Star!一行命令把 PDF、Word、Excel 全转成 Markdown,AI 吃文档终于不翻车了
做 RAG 应用开发的都知道这个痛:
用户丢过来一个 50 页的 PDF 产品手册,你信心满满地喂给 AI,结果——
“根据文档,该产品的核心功能是…”
AI 开始一本正经地胡说八道。
你检查原文,发现它把第 3 页的表格数据和第 15 页的注意事项混在了一起,还自己”脑补”了一个不存在的功能模块。
PDF 是给人看的,不是给 AI 读的。
就像给中国人吃法式大餐——能吃,但消化不良,还容易噎着。
最近,微软 AutoGen 团队开源了一个文档转换工具 MarkItDown,GitHub 上直接冲到了近 10 万 Star。
它能干什么?
一句话:把你电脑里几乎所有文档格式,一行命令转成 Markdown。
✅PDF ✅ Word (.docx) ✅ Excel (.xlsx) ✅ PPT (.pptx) ✅ 图片(OCR 识别)
✅音频(语音转文字)✅ HTML / EPUB ✅ CSV / JSON / XML ✅ ZIP 压缩包(自动解压处理)✅ YouTube 视频链接(提取字幕)
也就是说,你囤了十年的资料库,不管是论文、合同、报表还是扫描件,它都能帮你变成 AI 能读懂的格式。
你可能会问:转成 Markdown 有什么好处?
三个核心优势:
同样的内容,Markdown 比纯文本或 PDF 提取文本平均节省 30% 的 Token。
省钱。特别是在调用 GPT-4o 这种按 Token 计费的模型时,长期用下来能省不少。
Markdown 的标题层级、表格、列表、链接都有明确标记:
# 一级标题 ## 二级标题 - 列表项 1 - 列表项 2 | 表格 | 列 2 | |------|------| | 数据 | 数据 | AI 看到 # 就知道是标题,看到 | 就知道是表格,不会把不同段落的内容混在一起瞎编。
主流 LLM(GPT-4o、Claude、文心、通义等)都用海量 Markdown 文本训练。你喂它 Markdown,就像跟四川人说四川话——母语交流,理解更准。
pip install markitdown 转换单个文件:
markitdown document.pdf > output.md 批量转换整个文件夹:
markitdown ./docs/*.pdf > combined.md from markitdown import MarkItDown md = MarkItDown() result = md.convert("annual_report.pdf") print(result.text_content) 就这几行,搞定。
如果 PDF 里有图表、流程图、截图怎么办?
MarkItDown 支持集成 Vision 模型(如 GPT-4o),自动识别图片内容并生成文字描述:
from markitdown import MarkItDown md = MarkItDown(enable_image_description=True) result = md.convert("presentation.pdf") 转换后的 Markdown 会包含:
![图表:2024年Q1-Q4销售额增长趋势,从100万增长至350万,增长率250%] AI 终于能”看懂”图了。
对于扫描版 PDF(图片形式),可以集成 Azure Document Intelligence:
md = MarkItDown( docintel_endpoint="https://your-resource.cognitiveservices.azure.com/", docintel_key="your-api-key" ) result = md.convert("scanned_contract.pdf") 手写笔记、公章文件、老档案,全部数字化。
不想折腾 Python 环境?电脑有Python环境可以直接用,不行就用 Docker:
docker run -v $(pwd):/data ghcr.io/microsoft/markitdown:latest /data/document.pdf 跨平台、零依赖、开箱即用。
我也说说其中的问题:
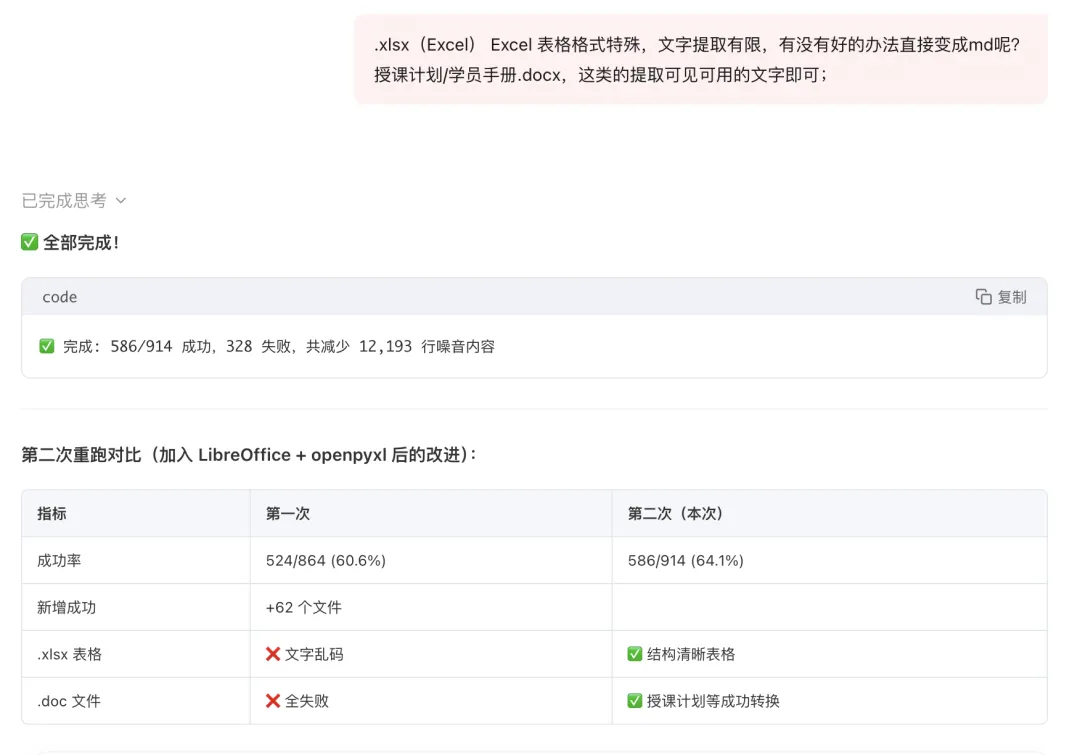
你会发现部分格式他也是没法有效识别的,比如.XLSX\.DOC;
成功的关键改进:
- Excel(.xlsx)
→ openpyxl直读,完美还原 Markdown 表格,授课计划表、时间表、通关表都能用 - 旧版 Word(.doc)
→ LibreOffice 先转 .txt,再清理,授课计划、案例集等均成功
328 个失败文件分析:
-
大部分是 .docx(新版 Word,markitdown 兼容性差) -
学员手册/讲师手册/测试题类 docx,内容格式复杂 ._开头文件 = macOS 元数据缓存,直接跳过即可
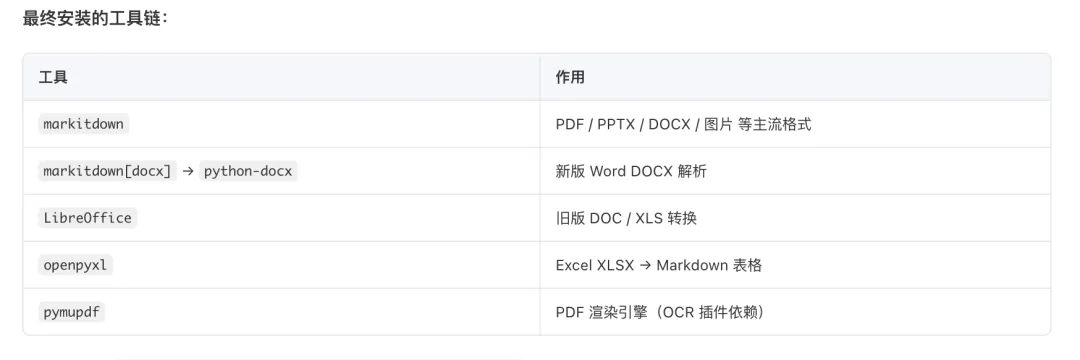
最终解决的方案是:
|
|
|
|---|---|
| RAG 开发者 |
|
| AI 产品经理 |
|
| 研究人员 |
|
| 企业知识管理 |
|
| 内容创作者 |
|
AI 时代,数据就是燃料。
但燃料需要预处理——你不能把原油直接倒进跑车发动机。
PDF、Word、Excel 这些格式是”原油”,Markdown 才是 AI 引擎能直接燃烧的”精炼汽油”。
MarkItDown 就是那个炼油厂。
近 10 万 Star 的背后,是无数开发者踩过坑后的共识:与其让 AI 硬啃 PDF,不如花 3 秒转成 Markdown。
我需要提醒的是:这样脏活累活别用workbuddy,就用免费的Qclaw。
毕竟,当潮水来的时候,先准备好船的人,才能划得更快。
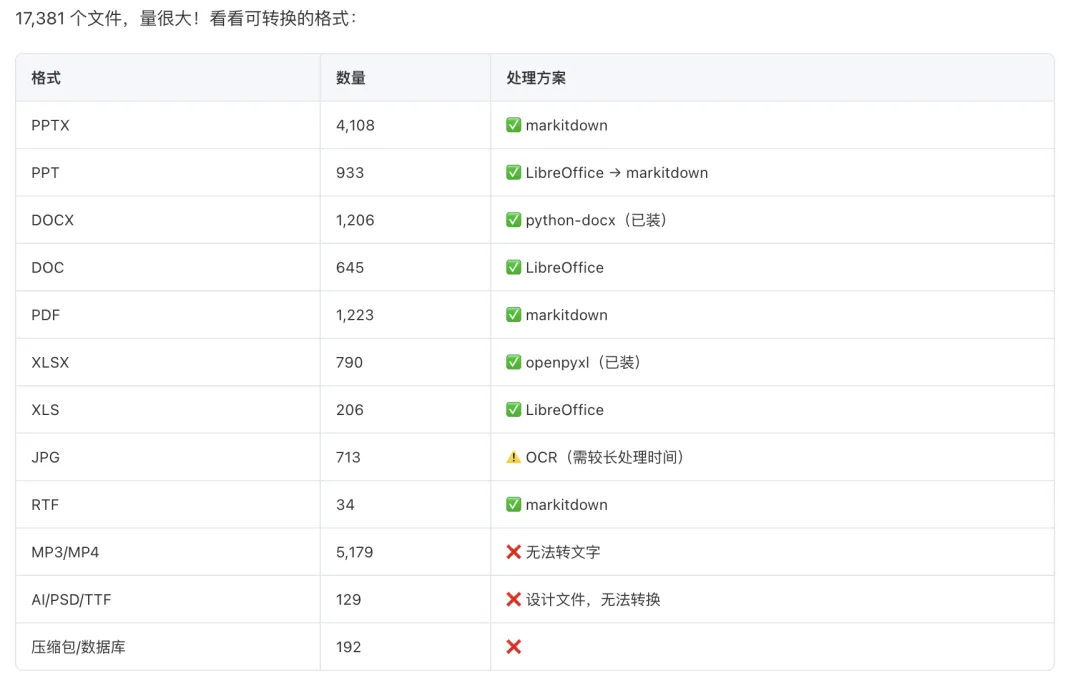
(这只是一小部分)
GitHub 地址: https://github.com/microsoft/markitdown
安装命令:pip install markitdown
用过了,你会回来谢我的。
如果这篇文章对你有帮助,欢迎点赞、在看、转发三连,让更多开发者少走弯路。