 夜雨聆风
夜雨聆风





从PDF到办公文档,MarkItDown为何成了AI工作流的新入口?


PDF 直接输入大模型,表格和结构经常保不住;先经 MarkItDown 处理再交给模型,通常更容易保留标题、列表和表格。这个微软开源项目最近在 GitHub 上热度很高,也开始进入更多 RAG 和 Agent 团队的工具链。
一份 120 页的合同 PDF,直接交给 Claude,表格对齐和分栏识别往往不太稳定;先用 MarkItDown 转成 Markdown 再输入,结构通常会清楚不少。
这与 prompt 技巧无关。问题出在文档格式和大模型理解力之间,原本就存在一层错配。
过去一年,企业 AI 项目里最常被讨论的,是 RAG、知识库和 Agent。但有一个朴素的事实常被忽略:模型再强,也需要先读懂文档,才能真正投入工作。而办公场景中相当大比例的文档是 Word、Excel、PPT、PDF,这些格式没有一个是为大模型设计的。
最近,微软这款名为 MarkItDown的工具在 GitHub 上持续走热,仓库 star 已超过 10 万。它所做的事情并不复杂:将各种办公文档,统一转成大模型更容易读取的 Markdown。
这件事被严重低估,亲手做过 RAG 项目的人才看得清。文档预处理的难度,常常远超向量检索和 Rerank 这些”看起来更技术”的环节。
一份带嵌套表格的 Excel 财报,用 pandas.read_excel 读取后格式往往错乱;一份带双栏排版的学术 PDF,经 PyPDF2 解析后段落顺序容易错位;一份 PPT 中的关键数据存在于 SmartArt 图表之内,常规工具无法读取。
行业内处理这些问题的主流方案分为两派。
一派是商业 SaaS,例如 LlamaParse、Unstructured API。按页计费,单价在几分钱量级,高级档稍贵。中型企业知识库首次全量处理,账单可达数千美元量级。效果可观,但价格不菲,且需要将数据传出本地。
另一派是开源拼装方案。pdfplumber + python-docx + openpyxl + Pillow-OCR,每种格式一个库,接口各异,输出格式不一,维护成本居高不下。
MarkItDown 选择了第三条路径:一个库,覆盖所有格式,输出统一的 Markdown。
支持清单几乎涵盖办公环境中常见的所有文档类型:Office 全家桶(Word、Excel、PowerPoint)、PDF、HTML、各种纯文本(CSV、JSON、XML)、ZIP 压缩包、EPub 电子书。除此之外,图片走 OCR,音频走语音转文字,YouTube 链接也能直接拉字幕。
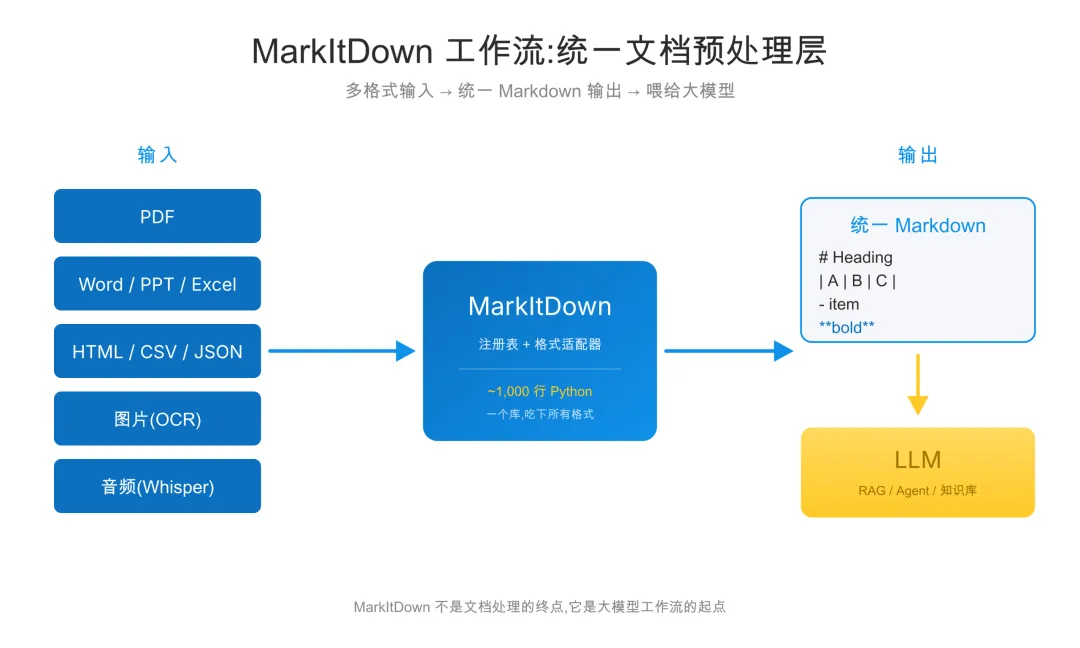
▲ MarkItDown 将多种文档格式统一转为 Markdown 后输入 LLM
过去两年,业界让模型读文档,试过纯文本、JSON、HTML,甚至直接输入原始字节流。但在很多实际工作流里,Markdown 往往是更省事的一种选择。理由可以分三层看。
第一层是结构保真。Markdown 用 # 表示层级,| 表示表格,- 表示列表。这些符号本身即是纯文本,token 成本极低,语义密度却极高。模型看到 ## 第三季度营收,能够立刻识别这是二级标题;看到 | 产品 | 销量 | 同比 |,能够立刻识别这是表格表头。
第二层是训练数据对齐。Markdown 本来就是开发者世界里很常见的格式。GitHub README、技术博客、问答社区里都能大量见到它,模型通常也更熟悉这种表达结构。
第三层是成本。同样一份 Word 文档,转成 HTML 或 JSON 往往会带入更多标签和字段;转成 Markdown 通常更克制。对上下文本来就紧张的长文场景,这种差别很实用。
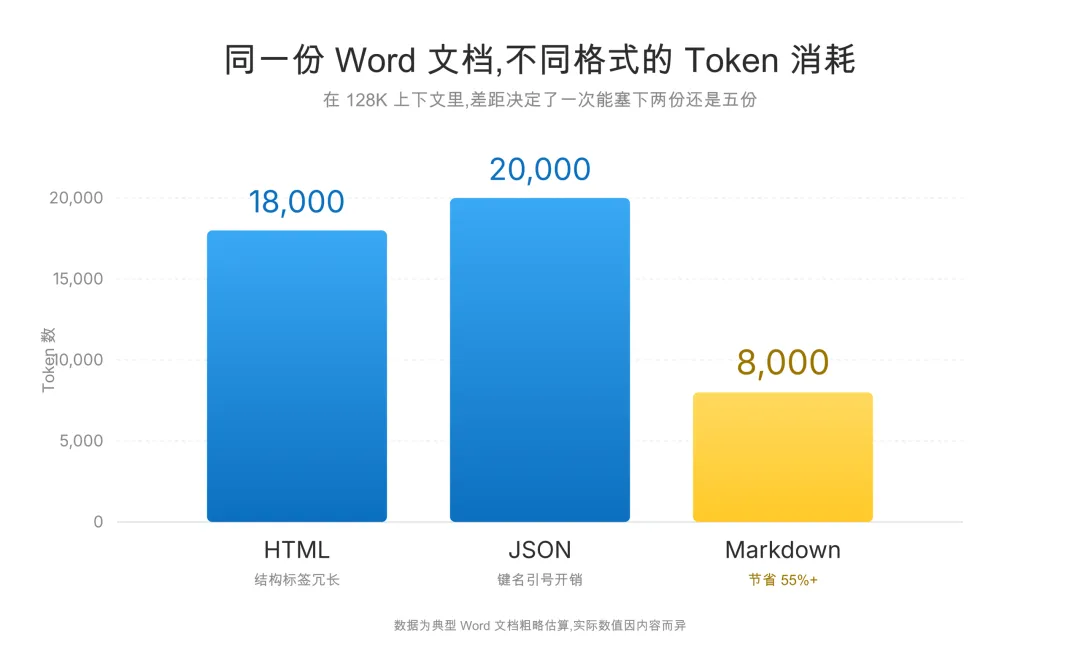
▲ 同一份 Word 文档转成不同格式的 token 消耗对比(示意)
把这三层放在一起看,就不难理解为什么很多团队会把 Markdown 当作文档进入模型前的一层中间格式。
场景一:企业知识库冷启动。一家公司要做内部 RAG,HR、财务、法务的历史文档存放在 SharePoint 中,Word 和 PDF 各半。过去的做法通常是每种格式各写一套解析脚本。换成 MarkItDown 之后,至少可以先把文档统一转成 Markdown,再进入切片和入库流程,少维护不少格式各异的解析逻辑。
场景二:财报 / 研报解读。分析师将 PDF 格式的季度财报输入 LLM,提问”研发费用环比变化”。若直接解析 PDF,表格容易乱码,模型给出的数字也容易错位。先经 MarkItDown 处理,至少能先把表格结构整理出来,后续提问时不至于一开始就丢行错位。
场景三:多媒体档案索引。一个媒体团队积累了上千份会议录音和讲座 PDF。借助 MarkItDown 的音频转录能力(通过 Whisper 类语音识别模型),音频先转文字,PDF 先转 Markdown,最终统一写入同一个向量库。一句自然语言查询,同时覆盖音视频和文档两种载体。
MarkItDown 不是全部答案,但它确实把大模型工作流最前面那一步做得更顺了。
实际使用并不复杂,但要看你处理的文档类型。若是常见办公文档,通常会先把对应依赖一起装上,例如:
$ pip install 'markitdown[all]'$ markitdown report.pdf > report.md
MarkItDown 出现之前,文档解析主要依赖各家自行搭建。它出现之后,这一环节至少多了一个很多人愿意先试的默认选项。
Python 社区中,围绕 MarkItDown 的封装和集成已经开始增多。对不少团队来说,它至少提供了一个比”每种格式自己拼一套解析链”更省事的起点。
从项目方向看,它和微软已有的 Office、Copilot 生态天然贴近。把 Office 文档更顺畅地送进 LLM,本来就是这家公司最有动力做的事情之一。
工程层面,MarkItDown 的设计同样克制。主干代码结构紧凑,采用插件化架构,新增一种文档格式只需要实现对应的适配器。仓库本身已经提供了示例插件包,社区开发者可以基于同一套接口继续扩展。
复杂 PDF 仍然是明显短板。扫描件 PDF 依赖 OCR,精度受图像质量影响极大;带公式的学术 PDF,数学符号还原能力有限;双栏、三栏及图文混排的杂志型 PDF,段落顺序偶尔出现错乱。这些问题 MarkItDown 并没有绕开,只是把常见能力收进了同一套接口里。
Excel 的多 Sheet 与合并单元格场景同样不够稳定。财务人员习惯在一张表中使用合并单元格进行视觉分组,转换为 Markdown table 之后,层级关系往往会被压平。这也是表格转 Markdown 一直难做的地方。
本地依赖同样不算轻量。MarkItDown 按功能划分可选安装组,图片 OCR、音频转录、PDF 解析等能力都需要额外安装对应的 Python 依赖,有些场景还会牵出进一步的环境配置。真正完整跑起来,前置准备并不算短。
MarkItDown 把入门门槛往下压了一截,但还远没到可以完全放心交付的程度。
对今天的 AI 工作流来说,Markdown 更像一种务实的中间层,还谈不上终局格式。它会不会走得更远,还要看两件事:大模型的上下文成本会不会继续下降,以及像微软这样的厂商会不会持续投入这一层基础能力。
但至少现在,做 RAG 和 AI 工作流的团队已经多了一个现实选择:在数据进入模型之前,先问一句,要不要让它过一次 MarkItDown。
参考资料
VocSeed●●
Digital Productivity. Career Intelligence.
— END —
VocSeed 专注于数字化创新、数字化转型和数字生产力
如果你对 AI 时代的新事物、新技术和新工具感兴趣,欢迎关注我们
↓