 夜雨聆风
夜雨聆风





一个 RAG 系统到底怎么工作?从文档入库到答案生成全流程拆解
很多人第一次了解 RAG,会觉得它的概念并不复杂: “先检索资料,再让大模型回答。”
但一旦进入工程实现,就会发现真正的 RAG 系统远不止一句话那么简单。
它通常包含两条主线:
-
一条是 离线的数据准备链路
-
一条是 在线的问答处理链路
只有这两条链路都打通,RAG 才能真正跑起来。
一、先理解一个核心结论
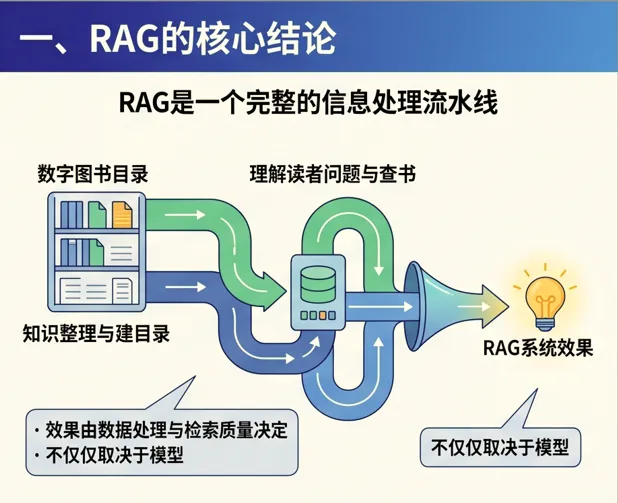
RAG 不是一个单点能力, 它更像是一条完整的“信息处理流水线”。
如果把它类比成图书馆系统,那么:
-
离线阶段是在“整理图书、建目录、编索引”
-
在线阶段是在“理解读者问题、查书、给出答案”
也就是说,RAG 的效果,不只是由模型决定,更由前面的数据处理与检索质量决定。
二、第一条主线:离线数据准备
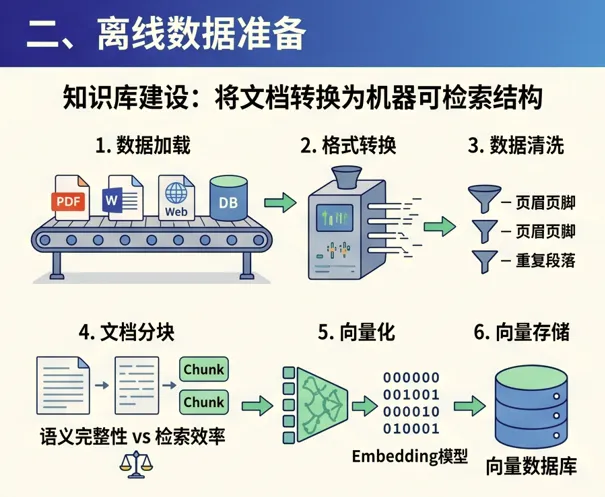
离线阶段可以理解为“知识库建设”。
它主要做的事情,是把原始文档变成机器可以高效检索的结构。
1. 数据加载
企业里的知识来源通常非常杂:
-
PDF
-
Word
-
Excel
-
网页
-
邮件
-
数据库记录
这些数据格式不同、结构不同,不能直接拿来给模型使用。 第一步就是把它们统一读取出来。
2. 格式转换
文档读进来以后,系统要把内容尽量转成可处理的文本。
比如:
-
PDF 要做文本解析
-
表格内容可能要转成文字描述
-
网页要去掉广告、脚本、无关导航内容
这一步的目标不是“完整保留一切形式”, 而是尽可能保留 有效信息和原始结构。
3. 数据清洗
原始资料里往往带有大量噪声:
-
页眉页脚
-
重复段落
-
乱码
-
特殊符号
-
无关声明
如果这些内容直接进入知识库,后面的检索质量会明显下降。 所以清洗是必须做的基础工程。
4. 文档分块
这是 RAG 里最关键的一步之一。
因为大模型和检索系统都不适合直接处理超长全文, 所以需要把文档切成更小的片段,也就是我们常说的 Chunk。
分块时要解决两个矛盾:
-
块太小,语义可能不完整
-
块太大,噪声会增加,还可能超出模型上下文限制
因此,分块本质上是在平衡 语义完整性 和 检索效率。
5. 向量化
切好的文本块,需要进一步转换成向量表示。 这个过程由 Embedding 模型完成。
为什么一定要向量化? 因为计算机并不真正理解“文字意思”,但它可以在向量空间里比较“语义距离”。
这一步完成后,系统才能支持“语义检索”。
6. 向量存储
最后,这些向量会被写入向量数据库,并建立相似度索引。 这样,当用户提问时,系统才能快速找到最相关的内容片段。
这就完成了离线建库阶段。
三、第二条主线:在线问答处理
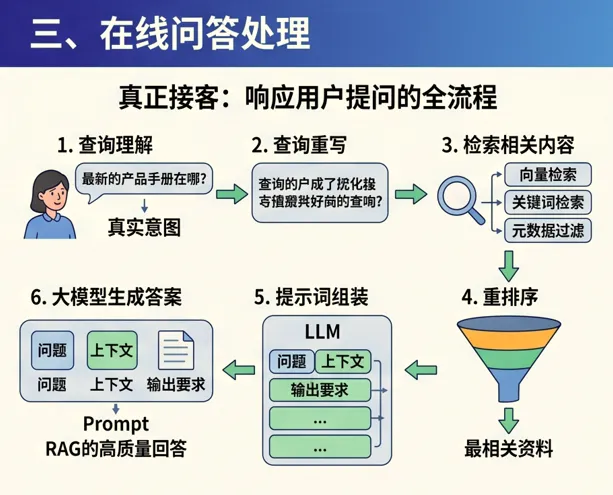
如果说离线阶段是在“备货”, 那么在线阶段就是“真正接客”。
当用户发来一个问题时,RAG 系统通常会按下面的流程运行。
1. 查询理解
用户的问题不一定表达得很标准。 系统需要先理解他的真实意图。
比如用户说:
“最新的产品手册在哪?” 或者 “我想看新版说明书。”
这两句话表达不同,但需求可能是一样的。
2. 查询重写
理解完问题后,系统通常还会做一次“检索友好化”。
比如:
-
扩展同义词
-
补全关键词
-
纠正常见拼写错误
-
把自然语言转成更适合检索的形式
这一环节做得好,召回率会明显提升。
3. 检索相关内容
接下来,系统会从向量数据库中检索与问题最相关的文档块。 成熟系统往往不会只用一种方式,而是结合:
-
向量检索
-
关键词检索
-
元数据过滤
这样做的目的,是兼顾语义理解和精确匹配。
4. 重排序
初步检索出来的结果,不一定真正最适合回答问题。 所以系统还会做一次重排序,把最相关、最有用的内容排到前面。
你可以把它理解为:
第一次检索是“广泛找资料”, 第二次重排是“挑出最值得给模型看的资料”。
5. 提示词组装
找到资料后,并不是直接扔给模型就结束了。 系统还要把:
-
用户问题
-
检索到的上下文
-
输出要求
一起拼成一个结构清晰的 Prompt。
Prompt 设计得越规范,模型越容易按要求作答。
6. 大模型生成答案
最后一步,才轮到大模型真正出场。
这时它不是“空手回答”, 而是带着检索到的上下文去生成答案。
所以 RAG 的高质量回答,本质上是:
检索能力 + 上下文组织能力 + 模型生成能力 的共同结果。
四、为什么很多 RAG 项目效果一般
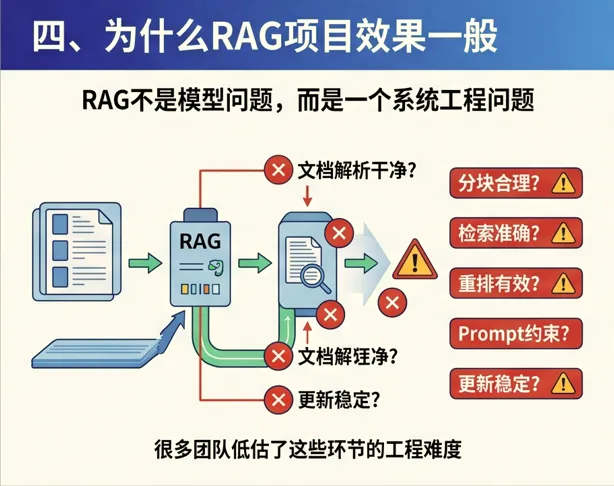
很多团队以为只要“文档入库 + 向量检索 + 调用模型”就能得到一个好系统。 但现实往往不是这样。
因为 RAG 真正难的地方在于:
-
文档解析是否干净
-
分块是否合理
-
检索是否准确
-
重排是否有效
-
Prompt 是否能约束模型
-
更新机制是否稳定
换句话说,RAG 不是一个模型问题,而是一个系统工程问题。
五、用一个例子把流程串起来
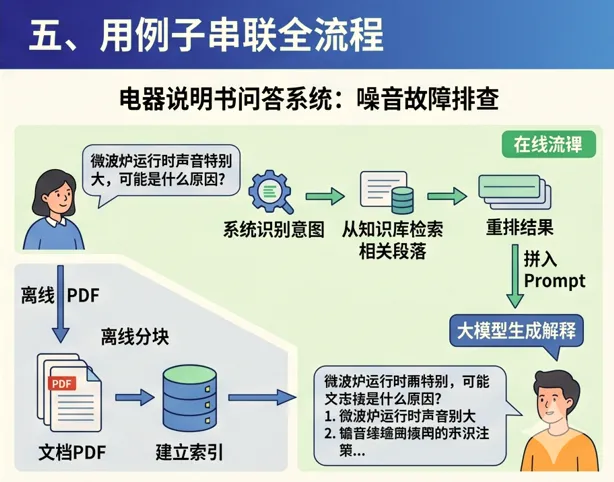
假设你要做一个“电器说明书问答系统”。
用户问:
“微波炉运行时声音特别大,可能是什么原因?”
一个完整的 RAG 系统会怎么做?
第一步,先在离线阶段把说明书 PDF 解析出来,按章节分块并建立索引。 第二步,用户提问后,系统识别“声音大”“故障”“排查”这些意图。 第三步,从知识库中检索出“噪音问题”“异常运行”“故障排除”等相关段落。 第四步,对结果重排,挑出最可能回答问题的片段。 第五步,把这些片段和用户问题拼进 Prompt。 第六步,由大模型生成一段自然语言回答。
最终用户看到的不是“说明书第 47 页、第 89 页”, 而是一段读得懂、可执行的解释。
这就是 RAG 在真实业务中的价值。
结语
RAG 的全链路并不神秘, 但它绝不是“加一个向量库”那么简单。
真正有效的 RAG,背后一定包含两件事:
-
离线阶段把知识整理好
-
在线阶段把问题处理好
下一篇,我们就进入最关键的优化层:一个 RAG 系统为什么效果不好?很多时候,不是模型不行,而是分块、检索、重排序和 Prompt 这 4 个环节没做好。