 夜雨聆风
夜雨聆风





成果|个性化 AI 助推会“失效”吗?—— 一项关于 AI 自我建模促进行为参与的长期研究
论文信息
标题:Does Personalized Nudging Wear Off? A Longitudinal Study of AI Self-Modeling for Behavioral Engagement作者:Qing He*, Zeyu Wang*, Yuzhou Du, Jiahuan Ding, Yuanchun Shi, Yuntao Wang会议: ACM CHI Conference on Human Factors in Computing Systems 2026(CHI 2026)DOI: 10.1145/3772318.3791777
研究背景与问题
长期行为改变一直是人机交互与健康技术研究中的核心挑战。无论是运动打卡、健康追踪还是自我管理工具,很多系统都能在短期内激发用户行动,但随着新鲜感减退、监测负担增加或反馈不再有吸引力,用户很容易逐步脱离使用。论文正是在这样的背景下提出了一个关键问题:AI 驱动的个性化助推,究竟只是短期有效,还是能够在长期使用中持续影响人的行为参与?
实验设计
围绕这一问题,研究团队设计了两阶段实证研究,并将健身任务作为实验场景。选择健身并不是偶然:一方面,它是日常生活中非常典型的行为改变场景;另一方面,它既能提供客观可测的表现数据,也能收集用户在长期过程中真实的主观体验。研究选取了两项常见训练任务——靠墙静蹲(wall-sit)和卷腹(crunch)——来观察 AI 自我建模对持续参与和表现提升的影响。
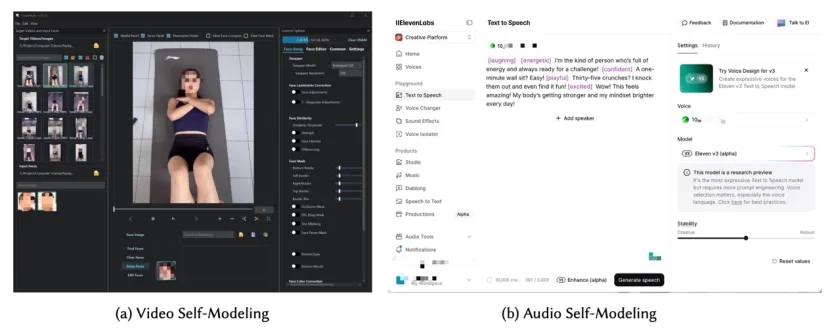
人工智能自我建模的系统实现
第一阶段是一项为期 1 周的三组对照实验,共 28 名参与者,分别接受视频自我建模(VSM)、音频自我建模(ASM)和无干预对照条件。研究希望先比较两类主流 AI 自我建模方式在健身场景中的效果差异。
第二阶段是在第一阶段基础上开展的为期 4 周的纵向研究,共 31 名参与者。由于第一阶段结果显示音频自我建模在该场景下没有显著优势,研究团队在第二阶段聚焦于视频自我建模,并与对照组继续比较其长期影响轨迹。论文也指出,这项研究构成了 AI 自我建模领域较早的 28 天长期实证研究之一。
核心发现与机制解释
研究发现,不同模态的 AI 自我建模在健身场景中的作用并不相同。在第一阶段实验中,视频自我建模能够带来更明显的早期表现提升,而音频自我建模则没有表现出显著优势。这说明,在需要动作示范、身体表征和具身感的任务中,视频比语音更能起到有效助推作用。
更重要的是,第二阶段的 4 周纵向研究表明,视频自我建模确实能够在更长时间内维持更高的表现水平,但这种促进作用并不会始终以同样强度持续下去。大约在两周后,视频自我建模带来的边际增益开始减弱,表现提升速度逐渐放缓,并出现向对照组收敛的趋势。
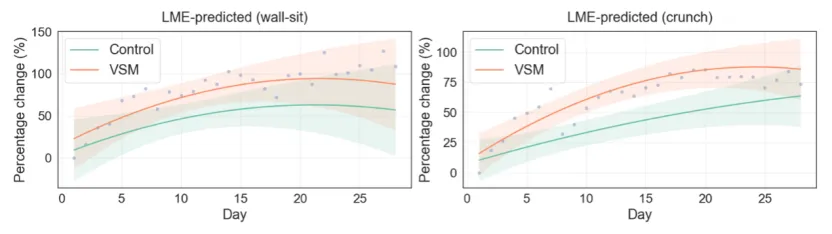
基于 LME 模型的为期一个月的纵向研究拟合性能曲线
设计启示与研究意义
论文进一步给出了面向长期行为改变系统的设计启示:未来的 AI 助推不应停留在重复呈现固定内容,而应更加重视干预模态与任务场景的匹配,并通过动态反馈、个体适配和长期目标调整来应对用户在长期使用中的习惯化问题。这项研究也为理解生成式 AI 在健康促进、运动坚持与长期行为参与中的真实作用边界提供了新的实证证据。
第一作者介绍
贺清,宾夕法尼亚大学Weitzman School of Design硕士二年级在读,2025年暑假在本实验室进行研究。
王泽宇,清华大学计算机科学与技术系直博三年级,研究方向为可穿戴设备与行为计算/干预,已在人机交互领域发表5篇 CCF-A 类论文。
作者邮箱:wang-zy23@mails.tsinghua.edu.cn
供稿:王泽宇
编辑:程志敏
审核:王运涛