 夜雨聆风
夜雨聆风





中美AI博弈分水岭:DeepSeek-V4“中国心”
戍天九思原创第1185期
2026年4月24日,DeepSeek-V4预览版发布。这是国产大模型首次深度适配华为昇腾芯片,并完成从英伟达CUDA生态向华为CANN架构的底层迁移。

笔者认为,这是中国国产AI大模型的成人礼,也是中美AI博弈分道扬镳的历史拐点。海外舆论评价可概括为三个关键词:“鲸鱼回归”“价格屠夫”“中国心”。
一、DeepSeek-V4发布说明了什么?
DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。DeepSeek-V4的发布向世界传递出三个核心信号:
首先,中国心AI已进入全球第一梯队。V4-Pro在多项关键评测中,如代码生成(SWE-bench得分超80%)、数学推理(在AIME 2025等数学基准测试中得分87.5%,较R1升级版的70%大幅提升)和世界知识储备上,已经能够与GPT-5.5、Claude-Opus 4.6等西方顶级闭源模型正面抗衡,甚至在部分领域实现超越。这证明了中国团队不仅能做出世界级的大模型,更能在技术最前沿进行创新。
其次,AI竞争从“堆算力”转向“拼架构”。长期以来,AI能力的提升似乎与算力投入成正比。然而,DeepSeek-V4通过一系列架构创新,在同等甚至更低的算力成本下,实现了性能的飞跃。其推理成本仅为GPT-4 的约1/70,证明了算法效率的提升,可以弥补硬件制程上的差距,为全球AI发展提供了新的范式。
最后,也是最重要的一点,中国AI开始构建独立的技术生态。DeepSeek-V4没有选择在英伟达成熟的CUDA生态上继续“搭便车”,而是毅然决然地拥抱华为昇腾等国产芯片,完成了从底层算子到上层框架的全栈迁移。这标志着中国AI产业正从应用层创新,深入到基础设施层的自主可控,开始构建一套独立于美国技术体系之外的“第二生态”。
值得注意的是,DeepSeek在报告中保持了一贯的克制,坦承V4的能力水平落后GPT-5.4 xHigh及Gemini-3.1-Pro High的前沿表现,约3至6个月。这种坦诚背后,折射出一个关键信号:V4不是一次简单的能力越级,而是另起炉灶的重构。它回答的不是“能不能追上”,而是“在什么地基上追”。
二、重大创新:效率革命从何而来?
DeepSeek-V4最核心的创新,在于对注意力机制的结构性重塑。传统Transformer处理长文本的死穴是:序列长度加倍,注意力计算量呈平方级爆炸,KV缓存线性膨胀——这个瓶颈不破,百万token就只是论文里的数字。

V4开创了一种全新的注意力机制,由CSA(压缩稀疏注意力)和HCA两种创新注意力层交错配置,在token维度进行压缩,结合DSA稀疏注意力共同作用。其核心思路是:用轻量级索引器先对所有token对做粗筛,快速估算相关性排序,再精选出需要完整计算的token集合。关键在于这套稀疏结构是可训练的——模型在训练过程中自己学出哪里需要高密度注意力,哪里可以稀疏。
结果是惊人的。在百万token上下文下,V4-Pro处理单个token所需算力仅为V3.2的27%,KV缓存仅占10%;V4-Flash更极端,算力压到10%,缓存仅7%。报告中的单位是等效FP8 FLOPs,而非低精度取巧,且V4的路由专家权重已使用FP4精度,报告特别指出未来硬件上FP4还可再高出三分之一的效率——天花板远未到来。
在后端训练上,V4采用Muon优化器、GRPO及KL散度修正的强化学习方法,将预训练的32K上下文扩展至1M。MoE架构进一步进化,每层384个专家、每次激活6个,采用Mega内核融合方案与Hyper-Connections残差连接。梁文锋署名的条件记忆(Engram)模块,将经典哈希N-gram嵌入现代化,提供近似O(1)的确定性知识查找,为动态推理与事实性记忆的结合开辟了新路径。
简而言之,V4告诉整个AI圈一件事:不用堆参数,不用买更多卡,仅靠对注意力机制和训练方式的重新发明,就能把百万token长文本的门槛踩到地板上。
三、难在另起炉灶:从CUDA到CANN的生死跨越
V4发布一再推迟的真正原因,是将训练框架从英伟达迁移到华为昇腾的工程挑战。2025年年中,DeepSeek曾经历一次较为严重的训练失败,核心症结正是芯片平台的重新适配。这条路径远比想象中复杂。
理解这种复杂性,需要回到V4的技术特征。万亿级参数规模的MoE架构虽然在理论上通过“按需激活专家”降低了单次推理计算量,但代价是对内存带宽、芯片间互联以及KV Cache管理系统能力提出了极端要求——算力压力从“纯计算”转向了“系统调度与通信”。
在英伟达生态内,这套问题有相对成熟的解法:通过NVLink与NVSwitch构建的高带宽互联,单节点GPU间带宽可达TB/s级别,数据在芯片间流动如同高速公路。但当DeepSeek试图将这套精密体系迁移至华为昇腾平台时,面对的是完全不同的硬件拓扑——受制于制程与SerDes IP能力,昇腾更多依赖光模块进行跨节点扩展,这种“以空间换带宽”的方案引入了更长的物理链路、信号延迟与同步开销。
软件层面的差距同样不可忽视。CANN框架在算子覆盖、自动并行、内核融合及分布式通信调度等方面的整体成熟度仍落后于CUDA生态,这意味着工程团队需要在大量底层细节上进行针对性优化,甚至手动重写关键算子。工程师们为此投入大量精力,不仅重写了核心代码,更完成了从CUDA到CANN的完整底层迁移。
但比技术迁移本身更具战略信号意义的是:DeepSeek此次并未给英伟达或AMD提供提前优化适配的机会,而是将早期访问权限独家开放给了国产芯片厂商。华为昇腾的名字,是和NVIDIA并列写在验证平台里的。这一选择表明,DeepSeek已不是在“兼容”国产芯片,而是在追求一种“原生”的深度绑定。
正如V4官方发布后引用荀子之言所自勉的那样:“不诱于誉,不恐于诽,率道而行,端然正己”——这既是对外界喧嚣的定力宣示,也是对这条艰难而必须的道路的自我确认。
四、战略意义:从“技术突围”到“规则重塑”
DeepSeek-V4的战略意义远超一款大模型的发布,它正在从三个层面重塑中美AI博弈的格局。
一是证明“非美算力路径”的可行性。DeepSeek-V4最重大的战略价值,在于首次证明完全基于国产算力可以训练出万亿参数、世界一流的大模型。这打破了“没有英伟达H100就做不出好模型”的行业迷信。华为昇腾、寒武纪等国产芯片通过V4的验证,获得了进入主流AI供应链的“入场券”。这不仅关乎技术自主,更关乎产业链安全——在中美科技脱钩风险加剧的背景下,一条不依赖美国芯片的AI产业链具有不可替代的战略价值。
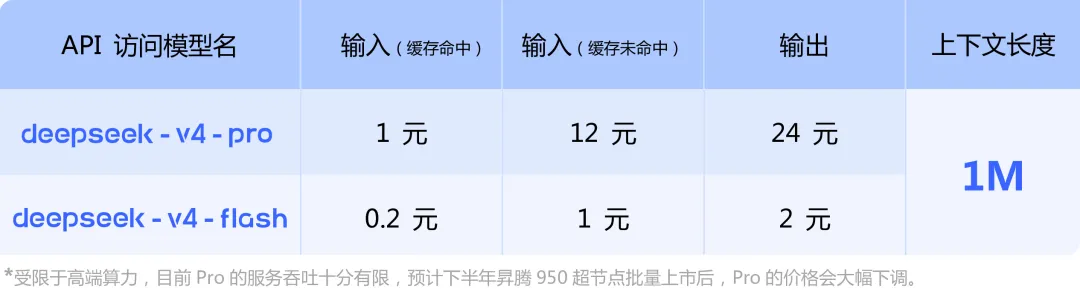
二是开源策略的“规则颠覆”。当OpenAI将最先进的模型能力锁在API之后、当Google将Gemini与云服务深度捆绑时,DeepSeek-V4的开源策略正在重新定义行业规则。它向全球开发者传递了一个信号:最先进的AI能力不必是昂贵的特权,而可以是普惠的基础设施。 这种“民主化”策略不仅赢得了开发者社区的好感,更在事实上构成了对闭源巨头的“价格战”压力。0.3美元/百万Token的定价,相比GPT-5.4的API成本具有数量级优势,将倒逼整个行业重新思考成本结构和商业模式。
三是从“模型竞争”到“系统竞争”的范式转换。DeepSeek-V4的成功标志着AI竞争正在从单纯的“模型性能比拼”转向“全栈系统效率竞争”。它不再追求在单一基准上超越对手,而是通过架构创新、工程优化和生态建设,在训练成本、推理效率、上下文长度、Agent能力等多个维度建立综合优势。这种“系统思维”恰恰是中国制造业的传统强项——不是在最尖端的技术点上硬碰硬,而是在产业链的整合效率和成本控制上形成护城河。
黄仁勋警告:出口管制正加速中国AI产业内部整合,如果 DeepSeek 这种中国顶尖大模型,以后首发跑在华为芯片上,对美国来说就是可怕的结果!
笔者认为,DeepSeek-V4的中国心,跳动的不仅是技术的脉搏,更是中华文明在数字时代自立自强的雄心。当未来回望2026年4月24日,这或许正是全球AI格局从“一超独霸”走向“两强并立”的历史转折点。
本公众号系列文章
《戍天九思代表作》