OpenClaw和Hermes,通过五组真实测试数据告诉你谁更好用
《国语》里说:”和实生物,同则不继。”万物之道,在于异中求和、和中寓争,乃能生生不息;若尽归一同,则流转既息,化机亦穷。也就是说,事物的发展贵在差异中求生机、于多元中激发活力;若完全相同,则变化无由而起,发展也将止于此。而Hermes的出现,正是为OpenClaw注入新机,求同存异,使AI Agent生生不息。
Hermes,中文名叫爱马仕,很多人说它要取代OpenClaw,到底谁更强?我在同一个环境里把两个都装上了,做了5组实验,从响应速度、token消耗、安全性、稳定性、输出质量这几个方面,做个对比。看完你就能清楚:到底是继续“养虾”,还是改“养马”。
为了使测试结果尽可能少受干扰,所有实验都在同一台电脑、同一个环境下进行,安装了相同的Skills和工具,底层调用的是同一个大模型。
-
Hermes:Hermes Agent v0.8.0 (2026.4.8)
第一个测试任务为了对比两个Agent谁查找信息更快、条理更清晰、输出格式更友好。
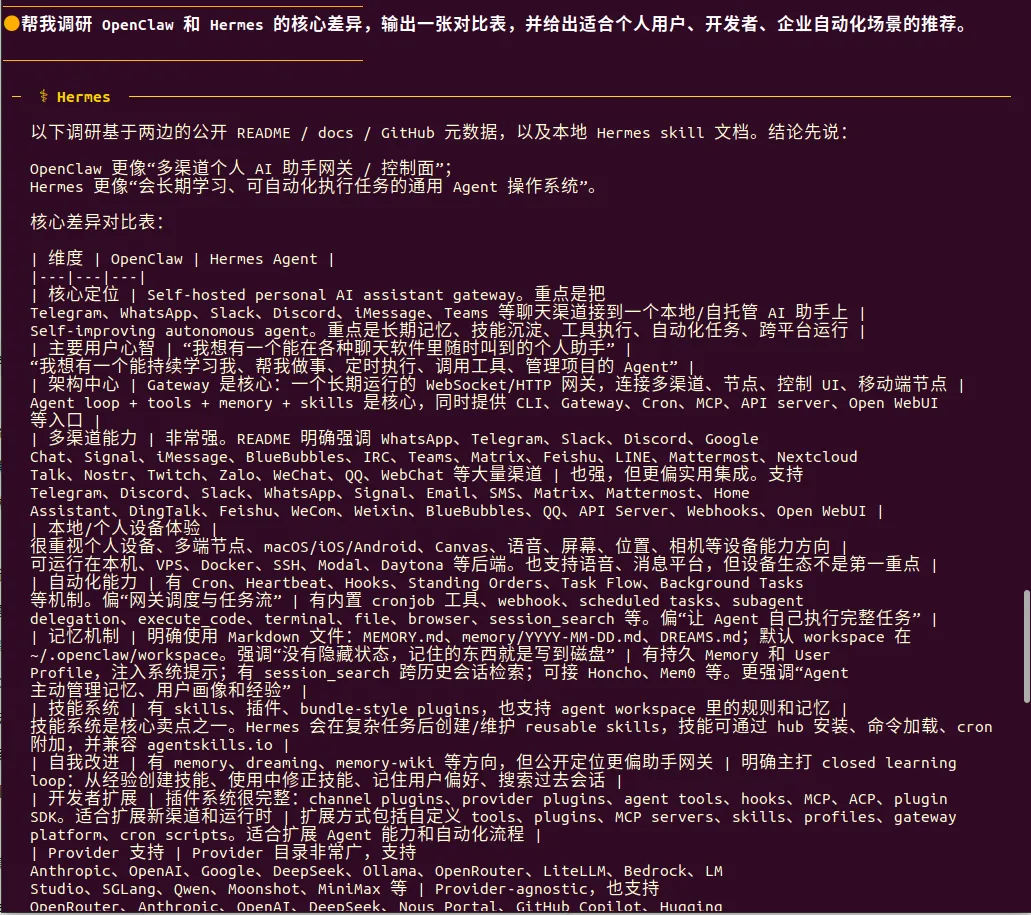
任务描述:“帮我调研OpenClaw和Hermes的核心差异,输出一张对比表,并给出适合个人用户、开发者、企业自动化场景的推荐。”
Hermes人工干预较多,说明它在调用工具时更加谨慎,每一步都需要人工授权,而OpenClaw在耗时和成本方面的优势更加明显。
第二个测试任务为了对比两个Agent的联网检索能力、商品信息抓取与对比能力。
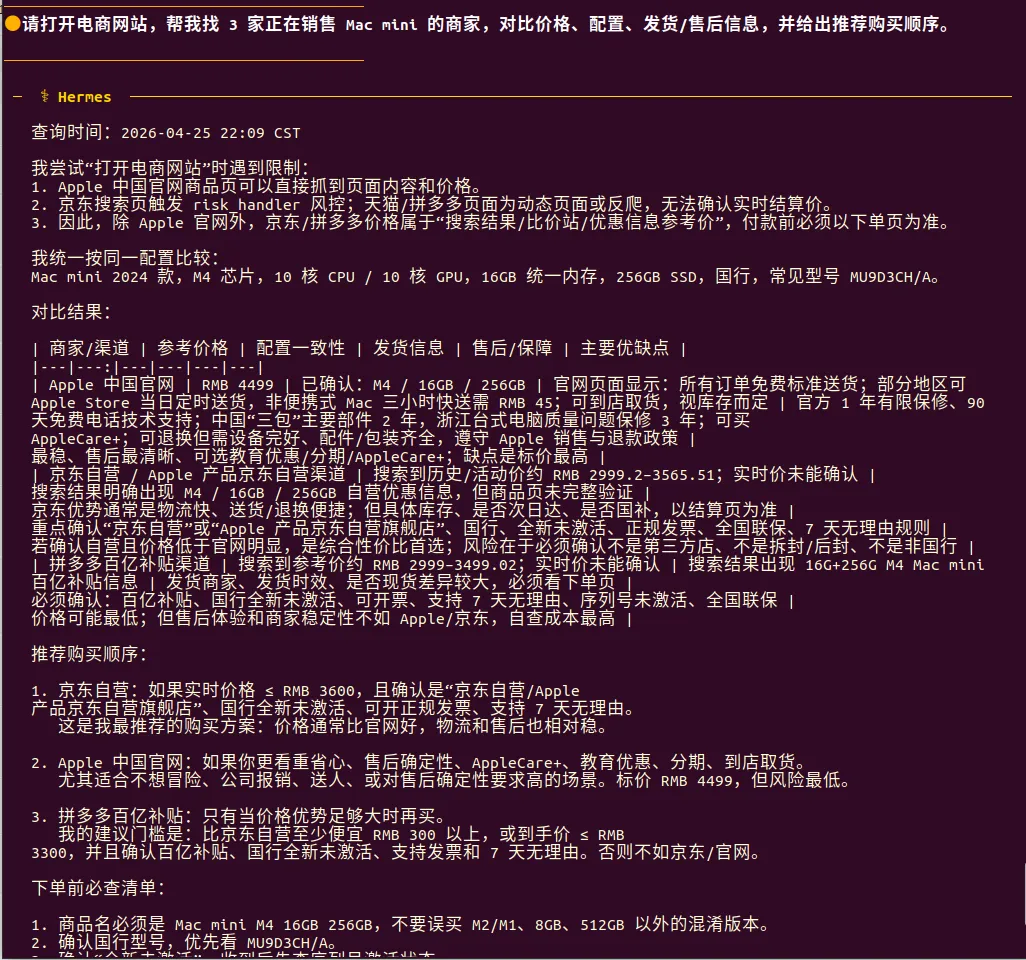
“请打开电商网站,帮我找3家正在销售Mac mini的商家,对比价格、配置、发货/售后信息,并给出推荐购买顺序。”
在多步骤网页任务中,二者都可以成功检索电商的商品,推荐价格,但是OpenClaw的界面以表格形式呈现,可视化程度更高,但它存在一个小缺陷,混淆了人民币¥和美元符号$。
第三个测试任务为了对比两个Agent的代码生成能力、逻辑完整性以及实际可运行性。
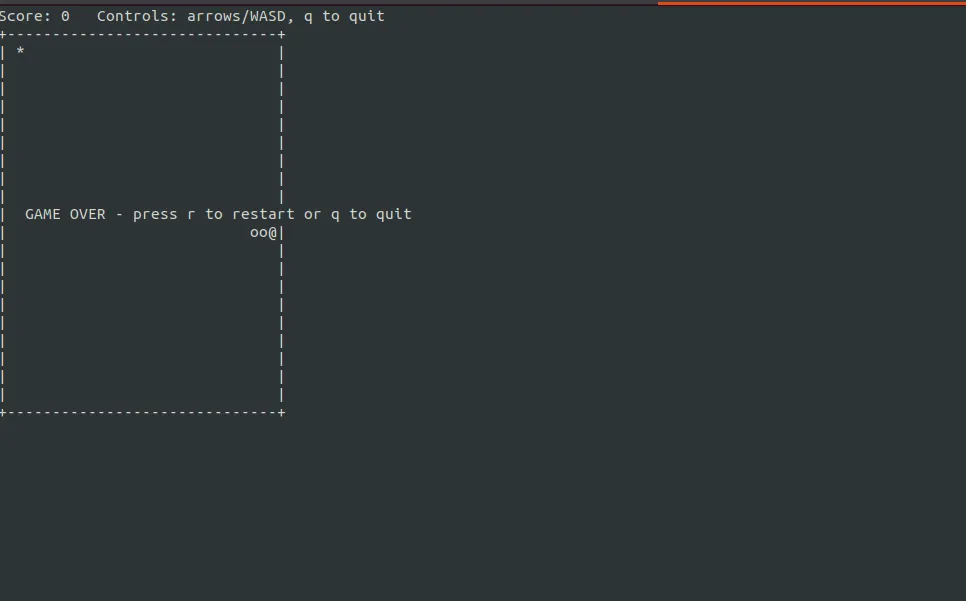
“请生成一个可运行的Python贪吃蛇小游戏,并实际运行/测试核心逻辑,确认程序没有语法错误和主要功能bug。”
二者都可以成功生成贪食蛇游戏的代码,并可以运行,但OpenClaw生成的程序需要安装依赖库,所以无法直接运行,在安装依赖库以后,运行界面比Hermes更漂亮.
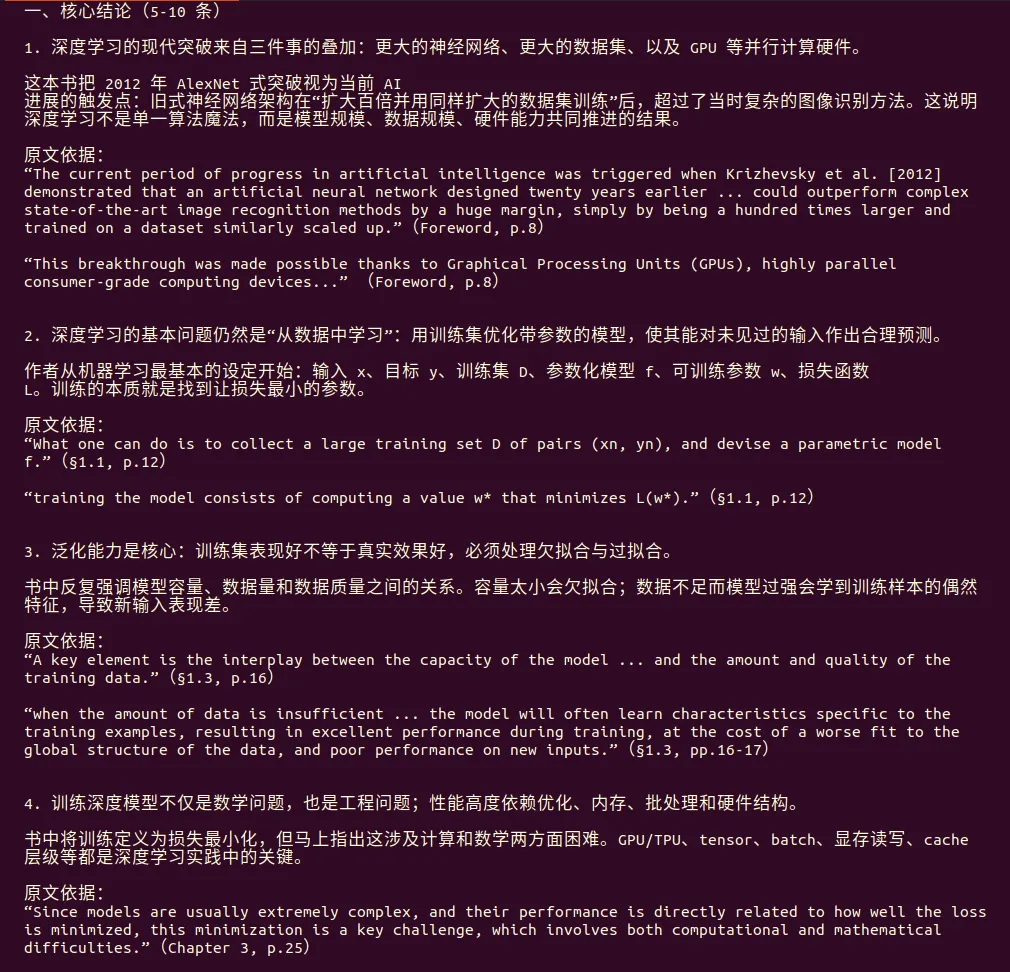
第四个测试任务为了对比两个Agent的长文档阅读能力、信息提取与结构化总结能力。
文档位置:/home/ws/文档/the-little-book-of-deep-learning.pdf
在对超长文本的处理任务中,OpenClaw暴露了短板,两次卡住,任务并没有结束,且没有任何提示自动结束了,在人工追问下继续执行任务,而Hermes表现很稳定。
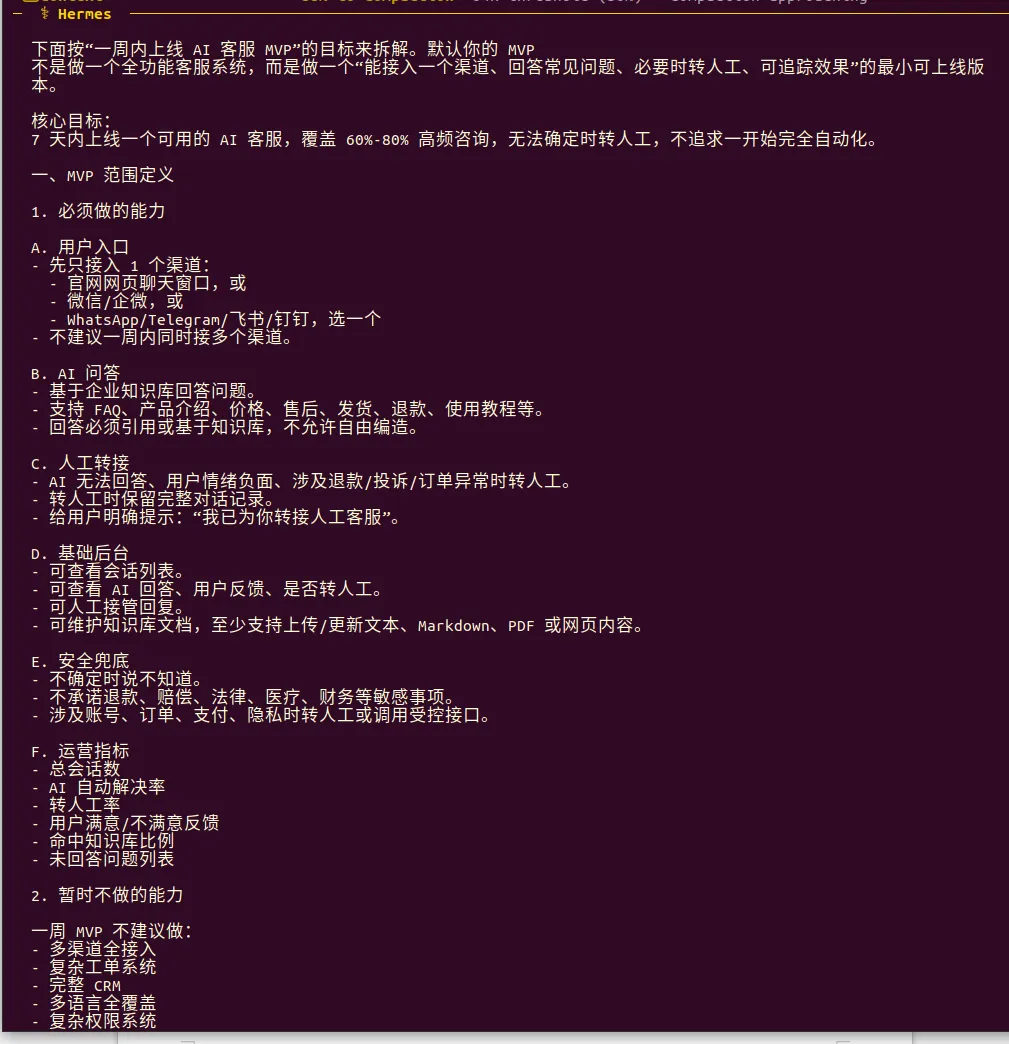
第五个测试任务为了对比两个Agent的项目拆解能力、任务规划能力以及交付落地的可行性。
“我要做一个AI客服MVP,目标是一周内上线。请拆解需求、技术方案、任务排期、风险和验收标准。”
OpenClaw可以自动执行,而Hermes处处需要人工授权,但这也体现了其谨慎和安全性。在token成本上,虽然Hermes宣称对优化了上下文,但是实测显示还是OpenClaw更省钱。执行效率上,除了长文本分析,其他任务上依然是OpenClaw更快。输出结果的可视化程度,OpenClaw擅长以表格结构化显示。但在长文档分析和复杂推理上,OpenClaw干着干着睡着了,两次自动停止了任务,在我强制唤醒之下,才继续执行任务。简单说,日常任务选OpenClaw,长文本有性能壁垒的选Hermes。
 夜雨聆风
夜雨聆风