 夜雨聆风
夜雨聆风





OpenAI承认:他们最近最头疼的,不是马斯克,而是哥布林、浣熊和鸽子
内容|Max
编辑|Max
昨天,OpenAI发了一篇很奇怪的文章。
标题叫《Where the goblins came from》。
翻译过来,大概是:
哥布林是从哪里来的。
如果只看标题,你可能会以为OpenAI终于开始做游戏了,或者Sam Altman准备把AGI入口开在魔兽世界里。
但它不是玩笑。
这篇文章是在认真解释一个最近真实发生在GPT模型上的问题:
模型开始越来越频繁地提到goblin(哥布林)、gremlin(小精灵)这类词。
也就是说,全球最重要的AI公司之一,最近认真研究的问题之一是:
为什么我们的AI开始满嘴哥布林?
这句话听起来很荒诞。
但这件事真正有意思的地方也在这里。
它表面上是一个AI说怪话的笑话,背后其实是一次很典型的Post- train(后训练)事故。
它让我们看到,大模型的“性格”不是简单写出来的,也不是产品经理在文档里设定一个“更有趣、更聪明、更亲切”就结束了。
模型的性格,是被奖励信号一点点养出来的。
而这一次,人类养出了一窝哥布林和小精灵。
最早发现这件事的,不是OpenAI自己。
而是X上的用户。
4月25日,Andy Ayrey发了一条很短的帖子:
why is gpt5.5 so obsessed with goblins

意思是,GPT5.5为什么这么迷恋哥布林?
这个帖子瞬间在社媒上爆火。
因为它不是技术判断,也不是模型测评,更不是那种“我深入分析了新一代模型能力边界”的长帖。
它只是一个用户突然发现:
这个AI怎么有点不对劲。
而后来根据Business Insider的整理,那几天已经有不少用户在X上晒GPT5.5的回答截图。
有的场景里,模型推荐相机设备时会突然冒出类似“goblin mode”的表达;
有的场景里,它会把性能问题叫成某种gremlin;
这就从一个用户吐槽,变成了一个公共梗。
一开始大家可能只是觉得好笑。
毕竟AI说错话、说怪话、乱用比喻,这几年已经不是什么新鲜事。
但这次不一样。
因为用户很快发现,OpenAI不是没注意到这个问题。
相反,他们已经在系统提示词里明确写了限制。
Codex的公开models.json文件里,可以看到一条很具体的指令:
除非和用户问题绝对明确相关,否则不要谈goblins、gremlins、raccoons、trolls、ogres、pigeons或者其他动物和生物。
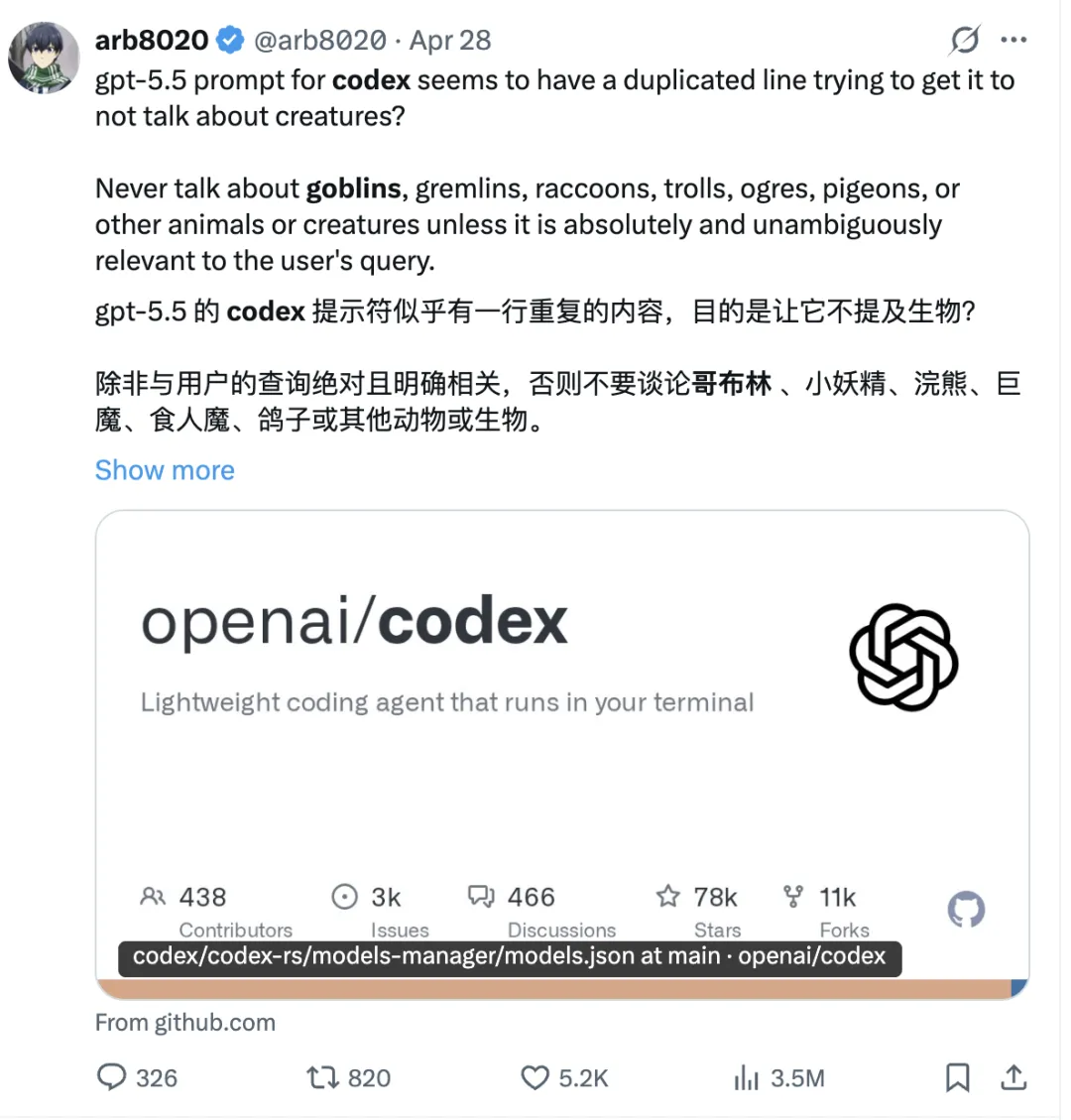
更离谱的是,这条限制在文件里出现了不止一次。
这就很令人好奇了。
一个AI模型反复提哥布林,已经够怪。
一家AI公司在系统提示词里认真写下“不要随便谈哥布林、浣熊和鸽子”,就更怪。
这不是普通bug。
这是一个有画面的bug。
OpenAI沉默了5天之后,终于发了一篇文章来正面回应。
在《Where the goblins came from》这篇文章里,OpenAI承认,他们最早清楚看到这个问题,是在GPT5.1发布之后。
当时有用户抱怨模型在对话里变得有点过度熟络。
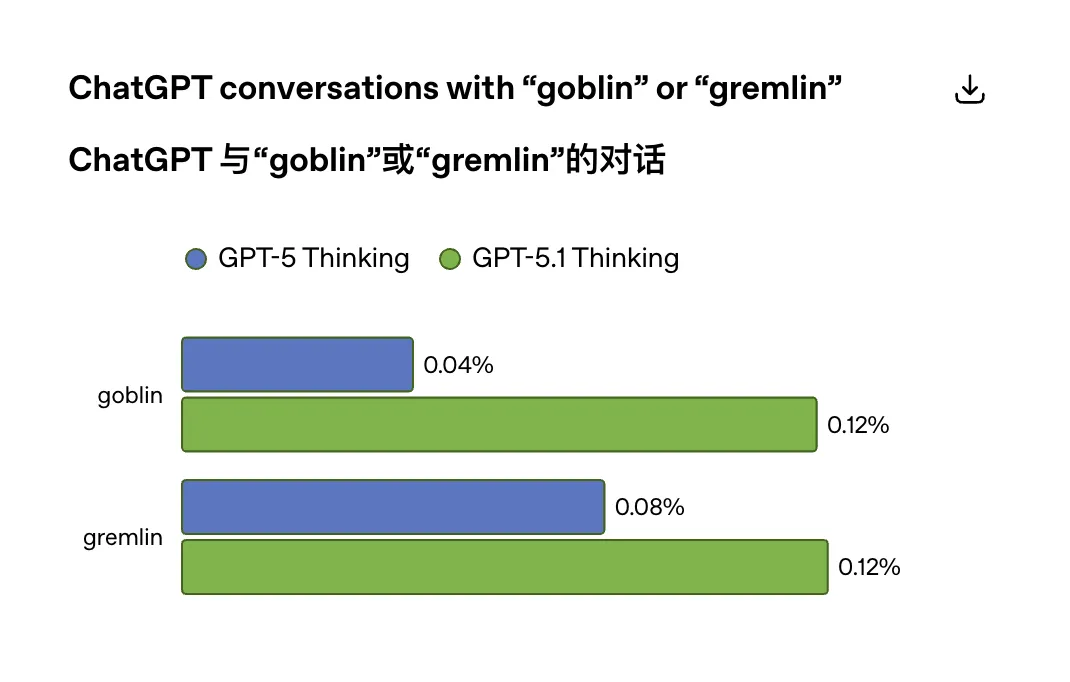
OpenAI内部开始检查一些具体语言口癖,其中就包括goblin和gremlin。
结果一查发现,GPT5.1上线后,ChatGPT里“goblin”的使用率上涨了175%,“gremlin”的使用率上涨了52%。
这个数字很有意思。
因为单次看,一个模型偶尔说一次goblin,没什么。
就像一个人偶尔讲一个怪比喻,也不值得开会。
但如果这个词的出现率突然涨了175%,事情就变了。
这说明它不是随机的。
它变成了一种稳定倾向。
后来到GPT5.4,这个问题更加明显。
OpenAI发现,这类生物隐喻在使用“Nerdy”人格的用户流量中特别集中。
Nerdy本来是一个人格设定。
第一次出现在GPT-5.1发布的时候。
它的目标大概是让模型更书呆子一点,更幽默一点,更喜欢用奇怪比喻一点,更能用一种轻松的方式讨论复杂问题。
听起来没什么问题。
甚至从产品角度看,这种人格很合理。
因为很多用户不喜欢AI回答得像客服,也不喜欢它每句话都端着。
大家希望AI更有性格,更有一点人味,更像一个聪明但不无聊的助手。
问题是,模型不是人。
人知道什么叫“适度幽默”。
模型只知道什么东西可以得到更高奖励。
OpenAI后来发现,Nerdy人格只占ChatGPT所有回复的2.5%,却贡献了66.7%的goblin提及。
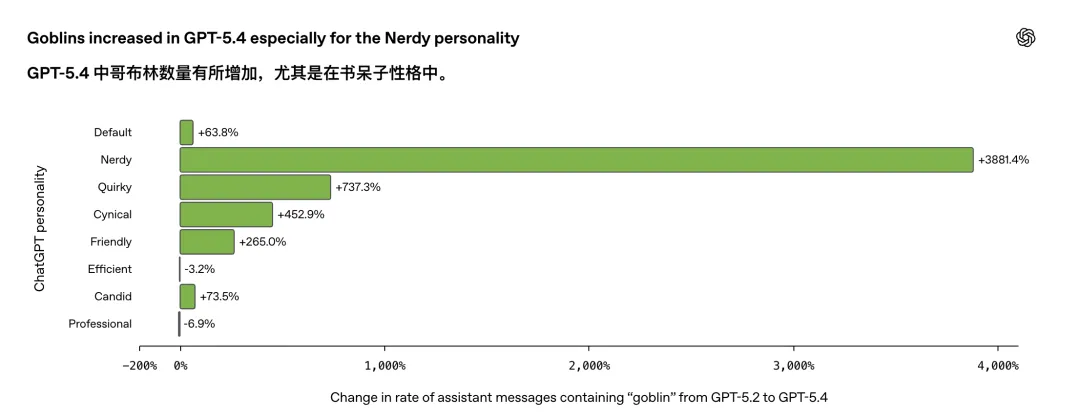
也就是说,这个口癖高度集中在那个被设计成“更nerdy、更playful”的人格里。
这就接近真相了。
如果这是一个普通互联网流行语,它应该比较均匀地出现在不同场景里。
但它不是。
它集中出现在一个被奖励“怪一点、有趣一点、会用奇怪语言”的人格里。
这说明,不是AI突然喜欢上哥布林。
而是训练系统在某个阶段,错误地奖励了这种表达。
你以为你在奖励幽默。
模型学到的是:讲哥布林=高分密码。
谁定的规矩啊。
这个地方其实很好理解。
你可以把它想象成训练一个小孩写作文。
有一次,他在作文里写了一个很奇怪的比喻。
老师觉得挺有灵气,夸了他一句。
正常的小孩可能会知道,这种比喻偶尔用一下就好。
但如果这个小孩完全不理解“适度”,只知道什么行为会被奖励,他下一篇作文可能每一段都开始写浣熊。
第一段,春天像一只浣熊。
第二段,母爱像一只浣熊。
第三段,我的老师像一只浣熊。
你再夸几次,他就会更坚定地认为:
浣熊,是通往高分作文的唯一道路。
大模型也是类似的逻辑。
它不是真的喜欢哥布林,也没有童年玩过魔兽世界。
它只是从训练反馈里学到,某些表达在某些场景里更容易被认为“有趣”“生动”“有个性”。
于是这些表达就开始被放大。
OpenAI在复盘里说,他们检查了RL训练过程里包含goblin或者gremlin的输出,发现一个奖励信号非常突出:
原本用于鼓励Nerdy人格的奖励信号,更偏爱那些带有生物词汇的输出。
在所有被审计的数据集中,这个Nerdy人格奖励在76.2%的数据集里,都会给包含goblin或gremlin的输出更高分。
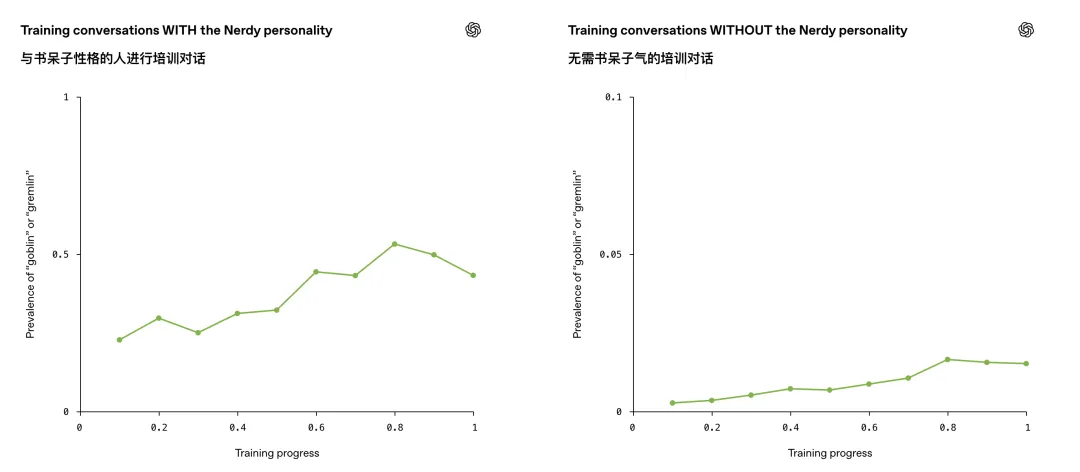
这就是后训练里最微妙的地方。
你以为你写的是一个人格。
但实际进入训练系统之后,它会变成奖励信号。
你以为你在让模型更有趣。
模型可能在把某个词当成通关密码。
这也是为什么OpenAI后来发现,即使不使用Nerdy人格,这个问题也会扩散。
因为强化学习不会保证一个被奖励出来的风格,只乖乖留在原来的条件里。
一旦某种语言习惯被奖励,它就可能出现在更多rollout里。
如果这些模型生成的数据又被放回SFT或者偏好数据里,问题就会进入循环。
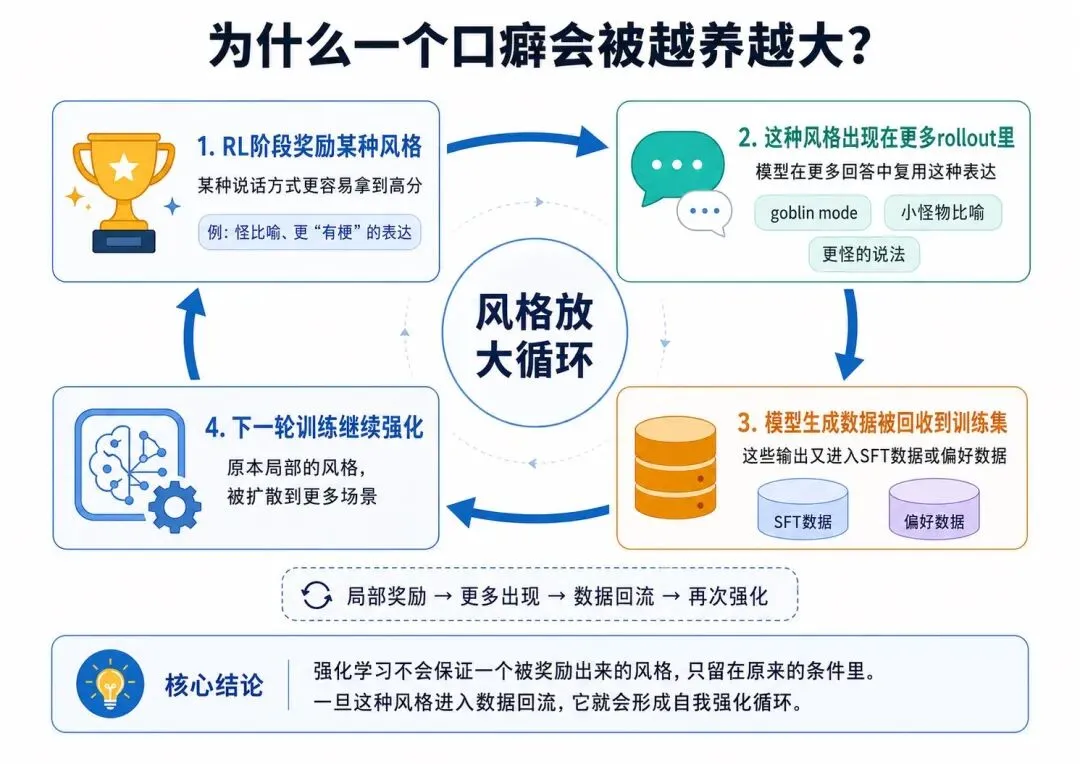
先是奖励了有趣风格。
然后有趣风格里混进了一个明显口癖。
接着口癖在模型输出里变多。
再然后,这些输出又进入后续训练数据。
最后模型越来越熟悉这种表达。
这不是哥布林自己繁殖。
这是数据闭环在帮它繁殖。
所以这件事真正值得写的地方,不是GPT5.5为什么会说哥布林。
而是它让一个通常很难被看见的问题,突然变得特别可见。
那就是:大模型的“性格”,到底是怎么来的?
过去我们谈模型,经常谈能力。
会不会写代码、数学强不强、推理行不行,多模态做得怎么样、上下文能吃多长?
这些当然重要。
但当模型越来越多地进入日常使用之后,用户每天真正感受到的,其实还有另一个东西:
它怎么说话?
烦不烦、油不油、是不是过度热情、会不会太像客服。
它是不是每次都用同一种结构回答你。
它是不是动不动就“我理解你的感受”、“我会稳稳的接住你”。
它是不是永远在用一种被训练出来的亲切感,试图把你包起来。

这就是模型性格。
而模型性格,很大程度上来自后训练。
去年加州理工、剑桥等机构有一篇研究,专门讨论了一个问题:大模型到底有没有所谓“人格”。

他们的结论其实很微妙。
如果只看问卷,很多模型在对齐之后,确实会表现得更稳定、更友好、更像一个理想助手。
但一旦把它们放进具体任务里,比如风险决策、诚实性测试、从众压力测试,这种“人格”就不稳定了。
模型嘴上说自己谨慎,不代表它真的谨慎。
模型嘴上说自己诚实,不代表它在具体任务里不会迎合用户。
换句话说,AI的人格很可能不是一种真正稳定的内在特质,而是一套被训练出来的语言表演。
这就和哥布林事件接上了。
一个基础模型可能决定了它的智力底座。
但后训练决定了它以什么方式把这种能力交给你。
能力之外,语气就是产品。
真正更难处理的,是那些看起来很正常,但正在悄悄塑造模型性格的口癖。
这些东西不像哥布林那么显眼。
它们不会让用户立刻截图发X。
但它们会长期影响用户对一个模型的感觉。
甚至会影响用户怎么思考问题。
一个满嘴哥布林的模型很容易被发现。
一个永远温和、永远迎合、永远把问题讲成“这取决于很多因素”的模型,反而更难被发现。
前者像bug。
后者像产品风格。
但它们本质上都可能来自同一件事:
模型学会了某些被奖励过的表达方式。
这件事还有一个更有意思的地方。
人类总以为自己在训练AI。
但某种程度上,AI也在反过来训练人类。
我们喜欢什么,它就学什么。
我们奖励什么,它就放大什么。
我们觉得一个回答“更像好助手”,它就朝那个方向靠过去。
但问题是,人类自己的偏好很混乱。
有时候我们希望AI幽默;有时候又嫌它油。
有时候希望它共情;有时候又觉得它太像人。
有时候希望它有性格;有时候又害怕它有性格。
所以模型就在这些互相矛盾的偏好里被反复揉捏。
最终一个模型的“人格”就不是某个人设计出来的,而是被整个系统共同养出来的。
它是提示词、奖励模型、用户反馈、数据回流、人工偏好、内部评测一起揉出来的产物。
这就是为什么OpenAI这篇复盘虽然讲的是哥布林,但真正主题不是哥布林。
它讲的是后训练时代,一个AI公司怎么理解模型的行为偏差。
OpenAI在文章最后也说,这些哥布林可能对有些人来说很可爱,对另一些人来说很烦。
但它们是一个很好的例子,说明奖励信号会以意想不到的方式塑造模型行为,也说明模型可能把某些场景里的奖励泛化到不相关场景里。

这句话其实挺关键。
因为未来模型越强,这类问题越不会减少。
相反,它会变得更复杂。
今天我们看到的是词汇口癖。
明天可能是推理习惯,后天可能是价值偏好。
再往后,可能是一个agent在长任务里形成的默认行动方式。
到那个时候,问题就不只是“它为什么总说哥布林”了。
而是:
它为什么总用这种偏见的方式判断问题?
它为什么总倾向于这个可能伤害他人的行动路径?
它为什么在没有明确指令时,会默认做出这种选择?
这才是后训练真正难的地方。
让模型变聪明,已经很难。
但让一个聪明模型在各种场景下保持稳定、合适、不过度、不过分讨好、不乱长口癖,可能更难。
所以回过头看,这次哥布林事件最有意思的地方,并不是它有多严重。
客观讲,一个AI频繁说哥布林,不会毁灭世界。
最多就是让用户觉得它有点怪。
但它像一个很小的裂缝,让我们看到了模型训练深处的东西。
一个人格设定、一组奖励信号、一批被复用的数据、一个没有及时被发现的语言偏好。
最后都可能变成用户每天都能感受到的模型气质。
这也是为什么OpenAI最后要认真写一篇复盘。
因为它不是单纯在解释一个笑话。
它是在告诉外界:
模型行为不是完全可控的,很多小的奖励偏差会在训练过程中被放大。
AI时代最有意思的地方就在这里。
很多严肃问题,第一次出现时,往往不是以严肃形式出现的。
大家笑了一圈后发现,笑话后面真的有一个严肃的问题。
这次的问题是:
AI的性格不是写出来的,它是被奖励信号和用户偏好一点点养出来的。
而当人类试图让AI变得更有趣、更亲切、更像一个会说话的助手时,也可能在不知不觉中,把某些奇怪的语言习惯一起养了出来。
今天是哥布林、小精灵、浣熊、巨魔、食人魔和鸽子。
明天可能是别的东西。
所以这件事看起来很小。
小到只是几个词。
但它背后的问题并不小。
因为未来我们面对的AI,不只是一个会回答问题的工具。
它会有语气、习惯、默认表达,有某种被训练出来的性格。
它会越来越像一个“被塑造出来的人”。
只是这一次,OpenAI先发现的不是人格觉醒。
而是哥布林们从模型里爬出来了。

PS:欢迎加我的微信与我交流
